
Maison >Périphériques technologiques >IA >Le MoE et Mamba collaborent pour adapter les modèles d'espace d'état à des milliards de paramètres
Le MoE et Mamba collaborent pour adapter les modèles d'espace d'état à des milliards de paramètres

- 王林avant
- 2024-01-23 18:00:141138parcourir
State Space Model (SSM) est une technologie qui a beaucoup attiré l'attention et est considérée comme une alternative à Transformer. Par rapport à Transformer, SSM peut réaliser un raisonnement temporel linéaire lors du traitement de tâches contextuelles longues, et dispose d'une formation parallèle et d'excellentes performances. En particulier, Mamba, qui est basé sur une conception SSM sélective et sensible au matériel, a montré des performances exceptionnelles et est devenu l'une des alternatives puissantes à l'architecture Transformer basée sur l'attention.
Récemment, les chercheurs explorent également la combinaison de SSM et Mamba avec d'autres méthodes pour créer des architectures plus puissantes. Par exemple, Machine Heart a rapporté un jour que « Mamba peut remplacer Transformer, mais ils peuvent également être utilisés en combinaison ».
Récemment, une équipe de recherche polonaise a découvert que si le SSM est combiné avec un système expert hybride (MoE/Mixture of Experts), le SSM peut atteindre une expansion à grande échelle. MoE est une technologie couramment utilisée pour étendre Transformer. Par exemple, le récent modèle Mixtral utilise cette technologie. Veuillez vous référer à l'article Heart of the Machine.
Le résultat de recherche donné par cette équipe de recherche polonaise est MoE-Mamba, un modèle qui combine Mamba et une couche experte hybride.

Adresse papier : https://arxiv.org/pdf/2401.04081.pdf
MoE-Mamba peut améliorer l'efficacité du SSM et du MoE en même temps. Et l’équipe a également constaté que le MoE-Mamba se comportait de manière prévisible lorsque le nombre d’experts variait.
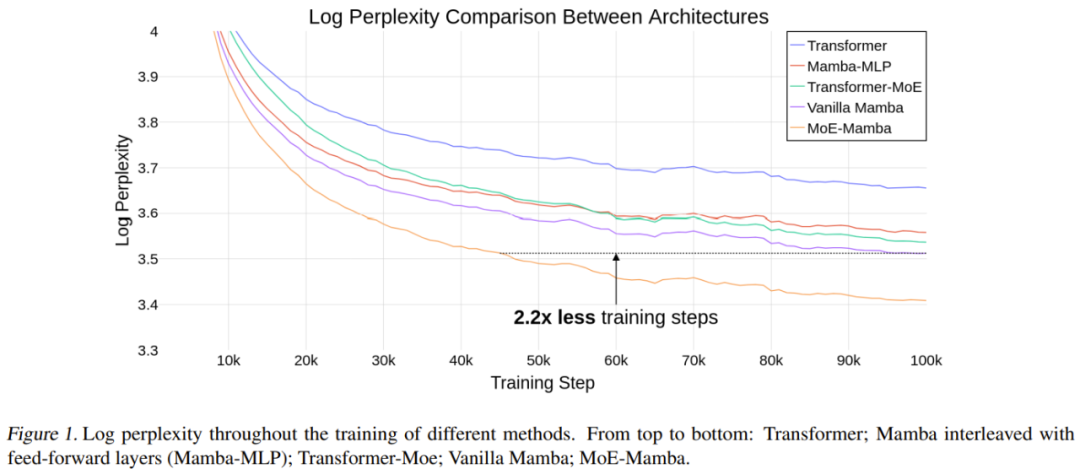
L'équipe a mené des démonstrations expérimentales et les résultats ont montré que par rapport à Mamba, MoE-Mamba nécessitait 2,2 fois moins d'étapes de formation avec les mêmes exigences de performances, démontrant les performances de la nouvelle méthode par rapport aux avantages potentiels de Transformer et Transformer-MoE. Ces résultats préliminaires laissent également entrevoir une direction de recherche prometteuse : le SSM pourrait être extensible à des dizaines de milliards de paramètres.
Recherche connexe
State Space Model
State Space Model (SSM) est un type d'architecture utilisé pour la modélisation de séquences. Les idées de ces modèles proviennent du domaine de la cybernétique et peuvent être considérées comme une combinaison de RNN et de CNN. Bien qu’ils présentent des avantages considérables, ils présentent également certains problèmes qui les empêchent de devenir l’architecture dominante pour les tâches de modélisation linguistique. Cependant, de récentes percées en recherche ont permis au SSM profond de s'adapter à des milliards de paramètres tout en conservant l'efficacité informatique et de solides performances.
Mamba
Mamba est un modèle construit sur SSM, qui peut atteindre une vitesse d'inférence temporelle linéaire (pour la longueur du contexte), et il réalise également un processus de formation efficace grâce à une conception sensible au matériel. Mamba utilise une approche d'analyse parallèle efficace qui atténue l'impact de la séquentialité des boucles, tandis que les opérations GPU fusionnées éliminent le besoin d'implémenter un état étendu. Les états intermédiaires nécessaires à la rétropropagation ne sont pas enregistrés mais sont recalculés lors du passage en arrière, réduisant ainsi les besoins en mémoire. L'avantage de Mamba sur le mécanisme d'attention est particulièrement significatif dans la phase d'inférence car non seulement il réduit la complexité de calcul, mais aussi l'utilisation de la mémoire ne dépend pas de la longueur du contexte.
Mamba peut résoudre le compromis fondamental entre l'efficience et l'efficacité des modèles de séquence, ce qui met en évidence l'importance de la compression d'état. Un modèle efficace doit nécessiter un petit état, et l'état requis par un modèle efficace doit contenir toutes les informations clés du contexte. Contrairement à d'autres SSM qui nécessitent une invariance temporelle et d'entrée, Mamba introduit un mécanisme de sélection qui contrôle la manière dont les informations se propagent le long de la dimension de la séquence. Ce choix de conception a été inspiré par une compréhension intuitive de tâches de synthèse de premier ordre telles que la réplication sélective et l'induction, permettant au modèle de discerner et de conserver les informations critiques tout en filtrant les informations non pertinentes.
Des recherches ont montré que Mamba a la capacité d'utiliser efficacement des contextes plus longs (jusqu'à 1 million de jetons), et à mesure que la longueur du contexte augmente, la perplexité préalable à l'entraînement s'améliorera également. Le modèle Mamba est composé de blocs Mamba empilés et a obtenu de très bons résultats dans de nombreux domaines différents tels que la PNL, la génomique, l'audio, etc. Ses performances sont comparables et dépassent le modèle Transformer existant. Par conséquent, Mamba est devenu un modèle candidat solide pour le modèle général de modélisation de séquence. Veuillez vous référer à "Un débit cinq fois supérieur, des performances complètes entourent Transformer : la nouvelle architecture Mamba fait exploser le cercle de l'IA". Les techniques d'experts mixtes (MoE) peuvent augmenter considérablement le nombre de paramètres du modèle sans affecter les FLOP requis pour l'inférence et la formation du modèle. MoE a été proposé pour la première fois par Jacobs et al. en 1991 et a commencé à être utilisé pour les tâches de PNL en 2017 par Shazeer et al.
MoE a un avantage : les activations sont très rares - pour chaque token traité, seule une petite partie des paramètres du modèle est utilisée. En raison de ses exigences informatiques, la couche avant du Transformer est devenue une cible standard pour plusieurs techniques MoE.
La communauté des chercheurs a proposé diverses méthodes pour résoudre le problème central du MoE, qui est le processus d'attribution de jetons aux experts, également connu sous le nom de processus de routage. Il existe actuellement deux algorithmes de routage de base : Token Choice et Expert Choice. Le premier achemine chaque jeton vers un certain nombre (K) d'experts, tandis que le second achemine un nombre fixe de jetons vers chaque expert.Fedus et al. ont proposé Switch dans l'article de 2022 "Switch transformers: Scaling to trillionparameter models with simple and efficient sparsity", qui est une architecture Token Choice qui achemine chaque jeton vers un seul expert ( K=1), et ils ont utilisé cette méthode pour étendre avec succès la taille des paramètres de Transformer à 1,6 billion. Cette équipe polonaise a également utilisé cette conception du MoE dans ses expériences.
Récemment, MoE a également commencé à entrer dans la communauté open source, comme OpenMoE.
Adresse du projet : https://github.com/XueFuzhao/OpenMoE
Il convient particulièrement de mentionner que le Mixtral 8×7B open source de Mistral a des performances comparables à LLaMa 2 70B, tout en nécessitant des calculs d'inférence. Le budget est seulement environ un sixième de cette dernière.
Architecture du modèle
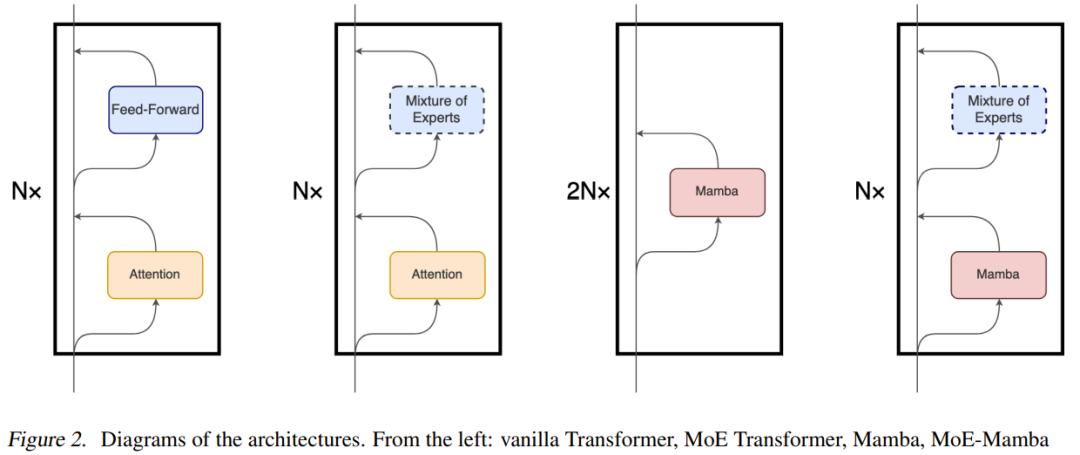
Bien que le principal mécanisme sous-jacent de Mamba soit assez différent du mécanisme d'attention utilisé dans Transformer, Mamba conserve la structure de haut niveau basée sur des modules du modèle Transformer. En utilisant ce paradigme, une ou plusieurs couches de modules identiques sont empilées les unes sur les autres et la sortie de chaque couche est ajoutée à un flux résiduel, voir Figure 2. La valeur finale de ce flux résiduel est ensuite utilisée pour prédire le prochain jeton pour la tâche de modélisation du langage.
MoE-Mamba profite de la compatibilité de ces deux architectures. Comme le montre la figure 2, dans MoE-Mamba, chaque couche Mamba d'intervalle est remplacée par une couche de rétroaction MoE basée sur Switch.
Cependant, l'équipe a également remarqué que cette conception est quelque peu similaire à la conception de "Mamba : modélisation de séquences temporelles linéaires avec des espaces d'états sélectifs" ; cette dernière empile alternativement des couches Mamba et des couches feedforward, mais le résultat est le même. Le modèle est légèrement inférieur au simple Mamba. Cette conception est désignée sous le nom de Mamba-MLP sur la figure 1.
MoE-Mamba sépare le traitement inconditionnel de chaque jeton effectué par la couche Mamba et le traitement conditionnel effectué par la couche MoE ; le traitement inconditionnel peut intégrer efficacement l'ensemble du contexte de la séquence dans une représentation interne, tandis que le traitement conditionnel Le traitement peut faire appel aux experts les plus pertinents pour chaque jeton. Cette idée d'alternance de traitement conditionnel et inconditionnel a été appliquée dans certains modèles basés sur MoE, mais ils alternent généralement les couches de base et de rétroaction MoE.
Configuration de la formation
L'équipe a comparé 5 configurations différentes : Basic Transformer, Mamba, Mamba-MLP, MoE et MoE-Mamba.
Dans la plupart des Transformers, la couche de rétroaction contient 8 dm² de paramètres, tandis que le papier Mamba rend Mamba plus petit (environ 6 dm²), de sorte que le nombre de paramètres de deux couches Mamba est le même qu'une couche de rétroaction et une couche d'attention. le même. Pour obtenir à peu près le même nombre de paramètres actifs par jeton dans Mamba et le nouveau modèle, l'équipe a réduit la taille de chaque couche avancée experte à 6 dm². À l'exception des couches d'intégration et de désintégration, tous les modèles utilisent environ 26 millions de paramètres par jeton. Le processus de formation utilise 6,5 milliards de jetons et le nombre d'étapes de formation est de 100 000.
L'ensemble de données utilisé pour la formation est l'ensemble de données anglais C4, et la tâche est de prédire le prochain jeton. Le texte est tokenisé à l'aide du tokenizer GPT2. Le tableau 3 donne la liste complète des hyperparamètres.
Résultats
Le tableau 1 donne les résultats de l'entraînement. MoE-Mamba fonctionne nettement mieux que le modèle Mamba classique.
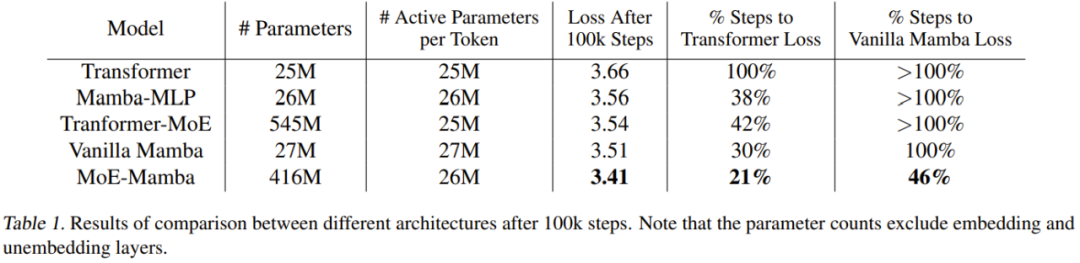
Il est à noter que MoE-Mamba atteint le même niveau de résultats que le Mamba ordinaire dans seulement 46% des étapes d'entraînement. Étant donné que le taux d'apprentissage est ajusté pour le Mamba ordinaire, on peut s'attendre à ce que si le processus de formation est optimisé pour MoE-Mamba, MoE-Mamba fonctionnera mieux.
Étude sur l'ablation
Pour évaluer si Mamba évolue bien à mesure que le nombre d'experts augmente, les chercheurs ont comparé des modèles utilisant différents nombres d'experts.
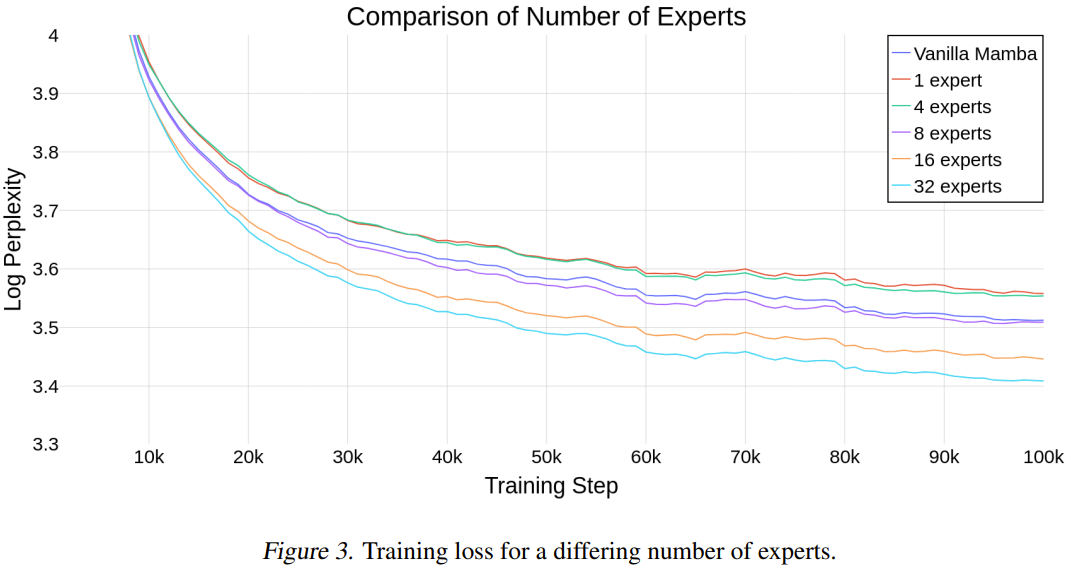
La figure 3 montre les étapes de la formation lors de l'utilisation de différents nombres d'experts.
Le tableau 2 donne les résultats après 100 000 pas.
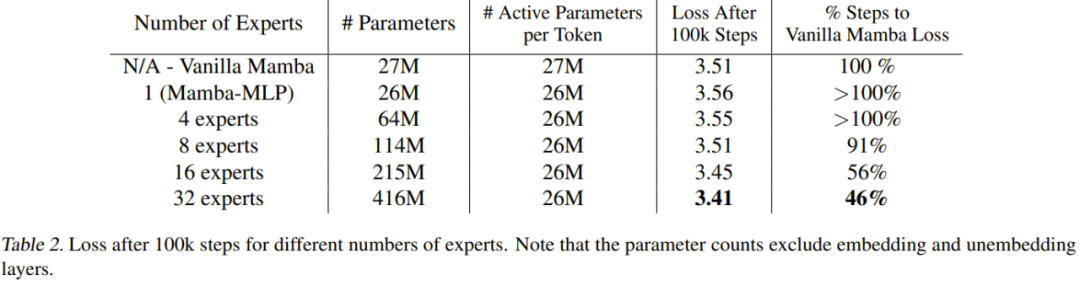
Ces résultats montrent que la méthode nouvellement proposée s'adapte bien au nombre d'experts. Si le nombre d'experts est de 8 ou plus, les performances finales du nouveau modèle sont meilleures que celles du Mamba normal. Étant donné que Mamba-MLP est pire que Mamba classique, on peut s'attendre à ce que le MoE-Mamba utilisant un petit nombre d'experts obtienne de moins bons résultats que Mamba. La nouvelle méthode a donné les meilleurs résultats lorsque le nombre d’experts était de 32.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!