
Maison >Périphériques technologiques >IA >Google lance ASPIRE, un cadre de formation de modèles qui permet à l'IA de juger de manière indépendante la précision des résultats.
Google lance ASPIRE, un cadre de formation de modèles qui permet à l'IA de juger de manière indépendante la précision des résultats.

- 王林avant
- 2024-01-23 17:36:101231parcourir

Google a récemment publié un communiqué de presse annonçant le lancement du framework de formation ASPIRE, spécialement conçu pour les grands modèles de langage. Ce cadre vise à améliorer les capacités de prédiction sélective des modèles d’IA.
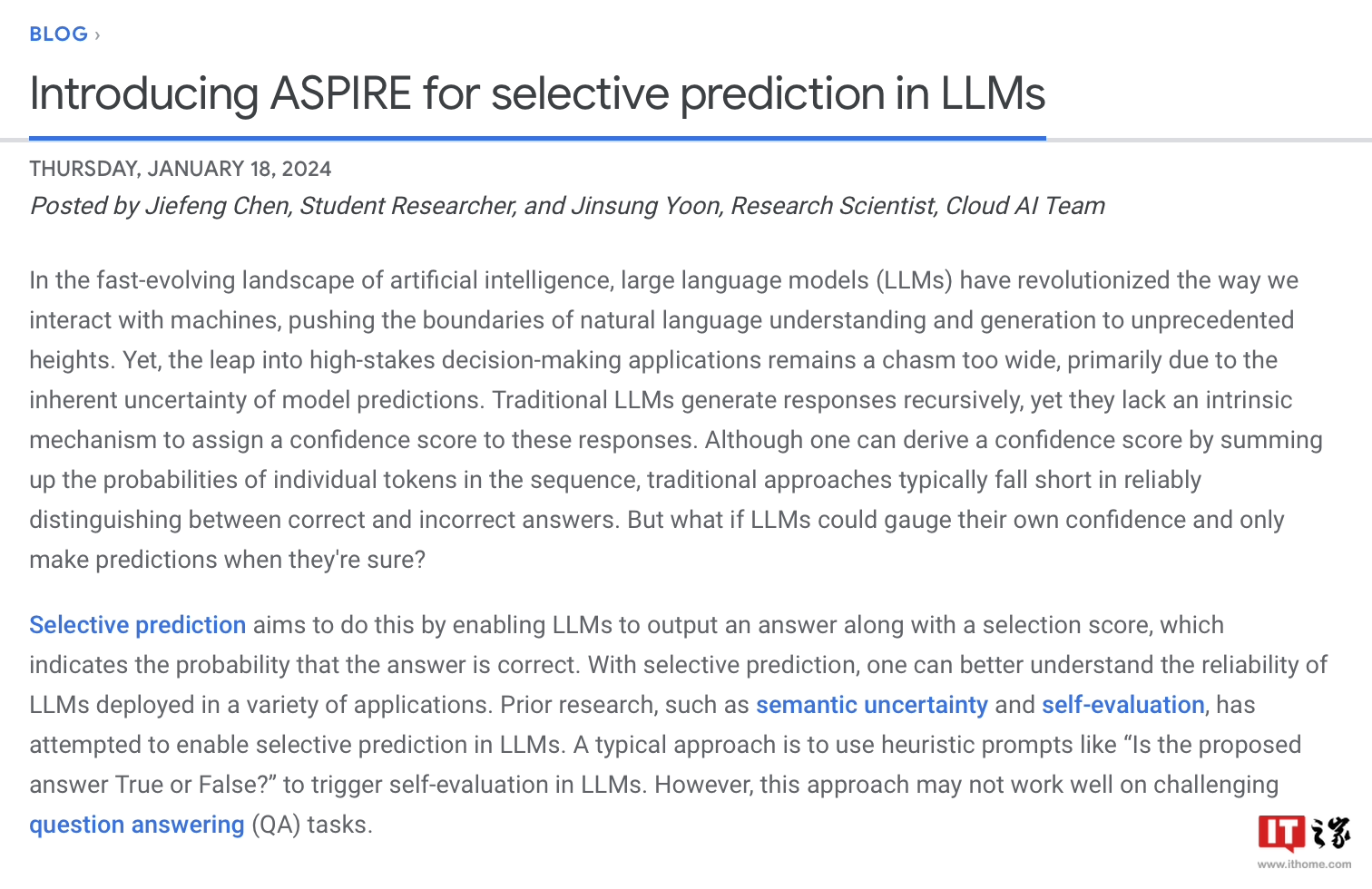
Google a mentionné que les grands modèles de langage se développent rapidement dans la compréhension du langage naturel et la génération de contenu, et ont été utilisés pour créer diverses applications innovantes, mais qu'il est toujours inapproprié de les appliquer à des situations décisionnelles à haut risque. Cela est dû à l'incertitude et à la possibilité d'« hallucinations » dans les prédictions du modèle. Par conséquent, Google a développé un cadre de formation ASPIRE, qui introduit un mécanisme de « crédibilité » dans une série de modèles. , chacune des réponses aura toutes un score de probabilité d'être correcte .
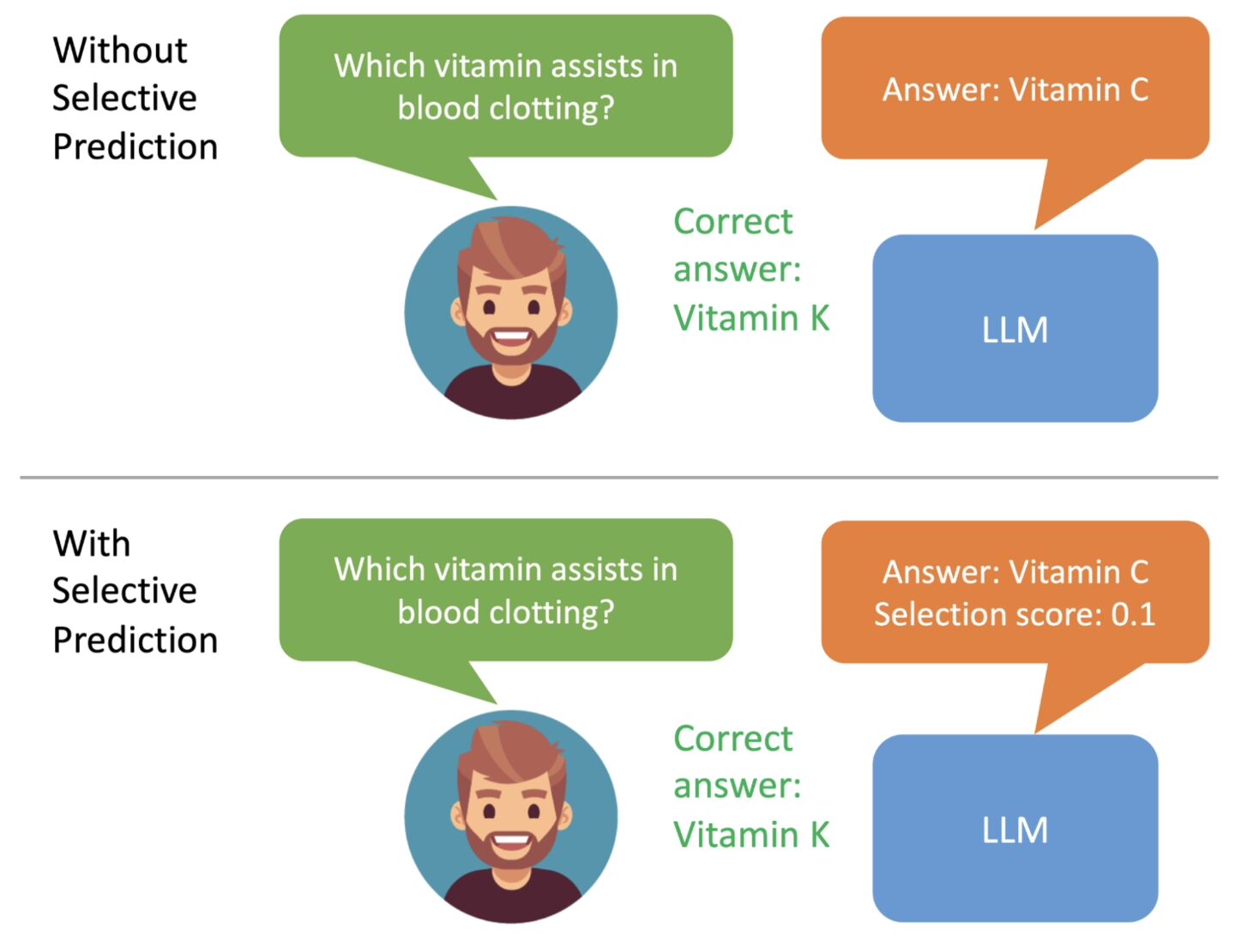
en se concentrant sur le renforcement des capacités de prédiction du modèle. Les chercheurs introduisent principalement une série de paramètres réglables dans le modèle et affinent le modèle de langage pré-entraîné sur l'ensemble de données d'entraînement de tâches spécifiques, améliorant ainsi les performances de prédiction du modèle et permettant au modèle de mieux résoudre des problèmes spécifiques.
Les chercheurs ont également utilisé la méthode « Beam Search » et l'algorithme Rouge-L pour évaluer la qualité des réponses, et ont réintégré les réponses et les scores générés dans le modèle pour démarrer la troisième étape.
Le but de cette étape est de permettre au modèle d'apprendre à « juger par lui-même l'exactitude de la réponse de sortie », de sorte que lorsque le grand modèle de langage génère la réponse, il attachera également le score de probabilité correct de la réponse.
Les chercheurs de Google ont utilisé trois ensembles de données de questions et réponses, CoQA, TriviaQA et SQuAD, pour vérifier les résultats du cadre de formation ASPIRE. On dit que « le petit modèle OPT-2.7B ajusté par ASPIRE surpasse de loin le plus grand OPT- ». Modèle 30B." Les résultats expérimentaux montrent également qu’avec des ajustements appropriés, même un petit modèle de langage peut surpasser un grand modèle de langage dans certains scénarios.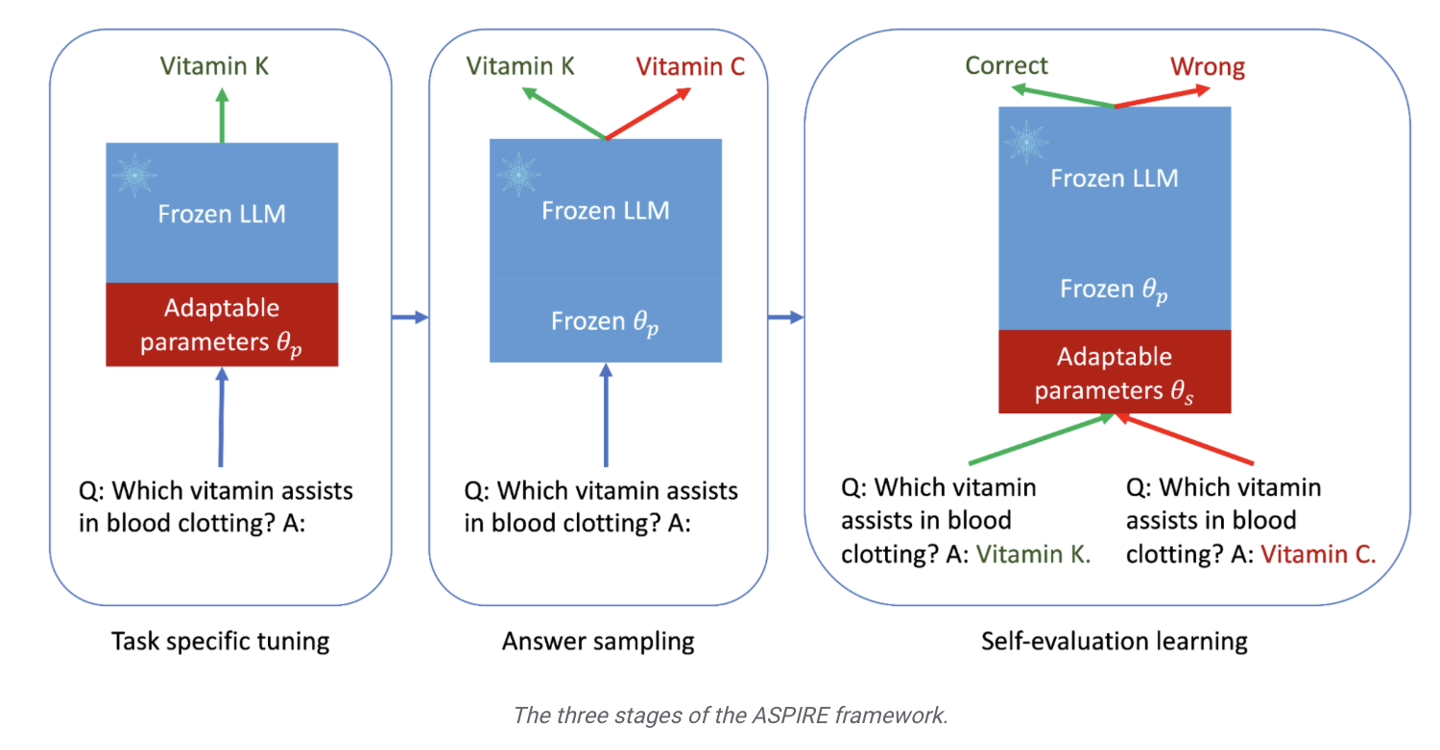
La formation au framework ASPIRE peut améliorer considérablement la précision de sortie des grands modèles de langage, et que même des modèles plus petits peuvent faire des prédictions « précises et sûres » après un réglage fin.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelle est la différence entre les classements Baidu et Google ?
- Comment faire apparaître la barre d'attributs AI
- Correction : erreur 429 de trop de demandes de Google Chrome [résolu]
- Utilisez de grands modèles de langage pour vous « entraîner » ! Les nouveaux produits d'Amazon n'ont pas de nouvelles fonctionnalités d'IA, mais ils prédisent qu'Alexa fera de grands progrès cette année
- Pourquoi Google Chrome ne parvient-il pas à ouvrir les pages Web ?