
Maison >Périphériques technologiques >IA >Analyse des méthodes d'apprentissage des réseaux de neurones artificiels en apprentissage profond
Analyse des méthodes d'apprentissage des réseaux de neurones artificiels en apprentissage profond

- PHPzavant
- 2024-01-23 08:57:131277parcourir
Le deep learning est une branche de l'apprentissage automatique conçue pour simuler les capacités du cerveau en matière de traitement de données. Il résout les problèmes en créant des modèles de réseaux neuronaux artificiels qui permettent aux machines d’apprendre sans supervision. Cette approche permet aux machines d'extraire et de comprendre automatiquement des modèles et des fonctionnalités complexes. Grâce au deep learning, les machines peuvent apprendre à partir de grandes quantités de données et fournir des prédictions et des décisions très précises. Cela a permis à l’apprentissage profond de connaître de grands succès dans des domaines tels que la vision par ordinateur, le traitement du langage naturel et la reconnaissance vocale.
Pour comprendre le fonctionnement des réseaux neuronaux, considérons la transmission des impulsions dans les neurones. Une fois les données reçues de la dendrite terminale, elles sont pondérées (multipliées par w) dans le noyau, puis transmises le long de l'axone et connectées à une autre cellule nerveuse. Les axones (x) sont la sortie d'un neurone et deviennent l'entrée d'un autre neurone, assurant ainsi le transfert d'informations entre les nerfs.
Afin de modéliser et de s'entraîner sur l'ordinateur, nous devons comprendre l'algorithme de l'opération et obtenir le résultat en saisissant la commande.
Ici, nous l'exprimons par les mathématiques, comme suit :
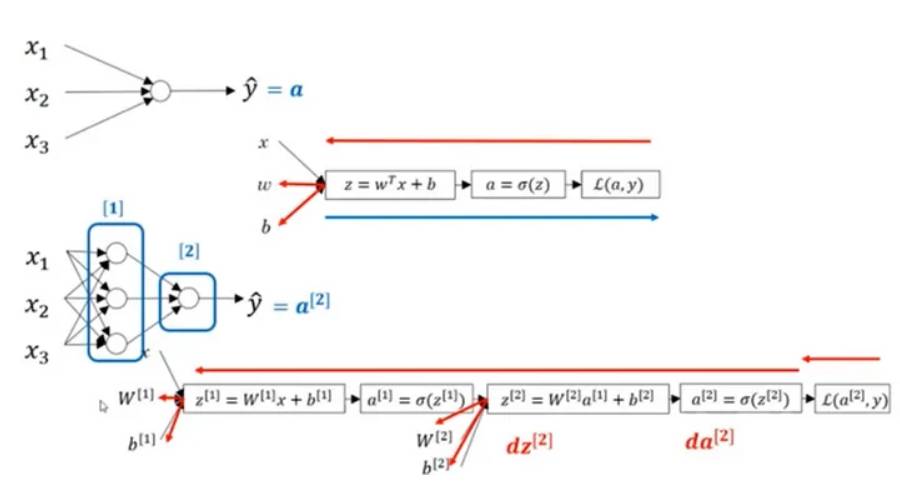
Dans la figure ci-dessus, un réseau neuronal à 2 couches est représenté, qui contient une couche cachée de 4 neurones et une couche de sortie contenant un seul neurone. Il convient de noter que le nombre de couches d'entrée n'affecte pas le fonctionnement du réseau neuronal. Le nombre de neurones dans ces couches et le nombre de valeurs d'entrée sont représentés par les paramètres w et b. Plus précisément, l’entrée de la couche cachée est x et l’entrée de la couche de sortie est la valeur de a.
Tangente hyperbolique, ReLU, Leaky ReLU et d'autres fonctions peuvent remplacer la sigmoïde en tant que fonction d'activation différentiable et être utilisées dans la couche, et les poids sont mis à jour via l'opération dérivée en rétropropagation.
La fonction d'activation ReLU est largement utilisée dans l'apprentissage profond. Puisque les parties de la fonction ReLU inférieures à 0 ne sont pas différenciables, elles n'apprennent pas pendant l'entraînement. La fonction d'activation Leaky ReLU résout ce problème. Elle est différenciable en parties inférieures à 0 et apprendra dans tous les cas. Cela rend Leaky ReLU plus efficace que ReLU dans certains scénarios.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce qu'un algorithme de réseau de neurones artificiels ?
- Le mécanisme de « plantation d'herbe » de Xiaohongshu est décrypté pour la première fois : comment la technologie du système d'apprentissage profond à grande échelle est appliquée
- Faire évoluer l'apprentissage profond sphérique vers des données d'entrée haute résolution
- Formation personnalisée de modèles d'apprentissage profond à l'aide de techniques d'apprentissage par transfert
- Introduction aux modèles d'apprentissage profond en langage Java