
Maison >développement back-end >Tutoriel Python >Comment utiliser Python pour entraîner l'IA à jouer au jeu Snake
Comment utiliser Python pour entraîner l'IA à jouer au jeu Snake

- PHPzavant
- 2024-01-23 08:39:061114parcourir
Ceci est un guide simple sur la façon d'utiliser l'apprentissage par renforcement pour entraîner une IA à jouer au jeu Snake. L'article montre étape par étape comment configurer un environnement de jeu personnalisé et utiliser la bibliothèque d'algorithmes Stable-Baselines3 standardisée par Python pour entraîner l'IA à jouer à Snake.
Dans ce projet, nous utilisons Stable-Baselines3, une bibliothèque standardisée qui fournit une implémentation facile à utiliser basée sur PyTorch d'algorithmes d'apprentissage par renforcement (RL).
Tout d’abord, configurez l’environnement. Il existe de nombreux environnements de jeu intégrés dans la bibliothèque Stable-Baselines. Nous utilisons ici une version modifiée du Snake classique, avec des murs entrecroisés supplémentaires au milieu.
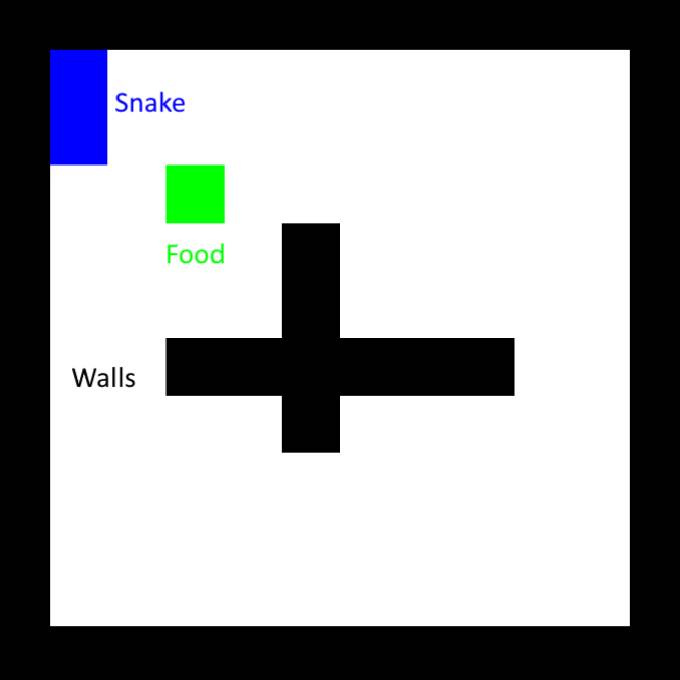
Un meilleur plan de récompense serait de récompenser uniquement les pas plus proches de la nourriture. Il faut être prudent ici, car le serpent ne peut encore qu'apprendre à marcher en cercle, recevoir une récompense lorsqu'il s'approche de la nourriture, puis se retourner et revenir. Pour éviter cela, nous devons également infliger une pénalité équivalente au fait de rester à l’écart de la nourriture, en d’autres termes, nous devons garantir que la récompense nette sur la boucle fermée est nulle. Nous devons également introduire une pénalité en cas de frappe sur un mur, car dans certains cas, un serpent choisira de heurter un mur pour se rapprocher de sa nourriture.
La plupart des algorithmes d'apprentissage automatique sont assez complexes et difficiles à mettre en œuvre. Heureusement, Stable-Baselines3 implémente déjà plusieurs algorithmes de pointe à notre disposition. Dans l’exemple, nous utiliserons l’optimisation de politique proximale (PPO). Bien que nous n'ayons pas besoin de connaître les détails du fonctionnement de l'algorithme (regardez cette vidéo explicative si vous êtes intéressé), nous devons avoir une compréhension de base de ce que sont ses hyperparamètres et de ce qu'ils font. Heureusement, PPO n'en a que quelques-uns, nous utiliserons ce qui suit :
learning_rate : définit l'ampleur des étapes de mise à jour des politiques, comme pour les autres scénarios d'apprentissage automatique. Un réglage trop élevé peut empêcher l’algorithme de trouver la bonne solution ou même le pousser dans une direction dont il ne pourra jamais se remettre. Un réglage trop bas rendra l'entraînement plus long. Une astuce courante consiste à utiliser une fonction de planification pour le régler pendant l'entraînement.
gamma : Facteur de remise pour les récompenses futures, compris entre 0 (seules les récompenses immédiates comptent) et 1 (les récompenses futures ont la même valeur que les récompenses immédiates). Afin de maintenir l'effet d'entraînement, il est préférable de le maintenir au-dessus de 0,9.
clip_range1+-clip_range : Fonctionnalité importante de PPO, elle existe pour garantir que le modèle ne change pas de manière significative pendant l'entraînement. Le réduire permet d’affiner le modèle lors des étapes de formation ultérieures.
ent_coef : Essentiellement, plus sa valeur est élevée, plus l'algorithme est encouragé à explorer différentes actions non optimales, ce qui peut aider le système à échapper aux maxima de récompense locaux.
De manière générale, commencez simplement par les hyperparamètres par défaut.
Les prochaines étapes consistent à s'entraîner pour certaines étapes prédéterminées, puis à voir par vous-même les performances de l'algorithme, puis à recommencer avec les nouveaux paramètres possibles qui fonctionnent le mieux. Ici, nous traçons les récompenses pour différentes durées de formation.
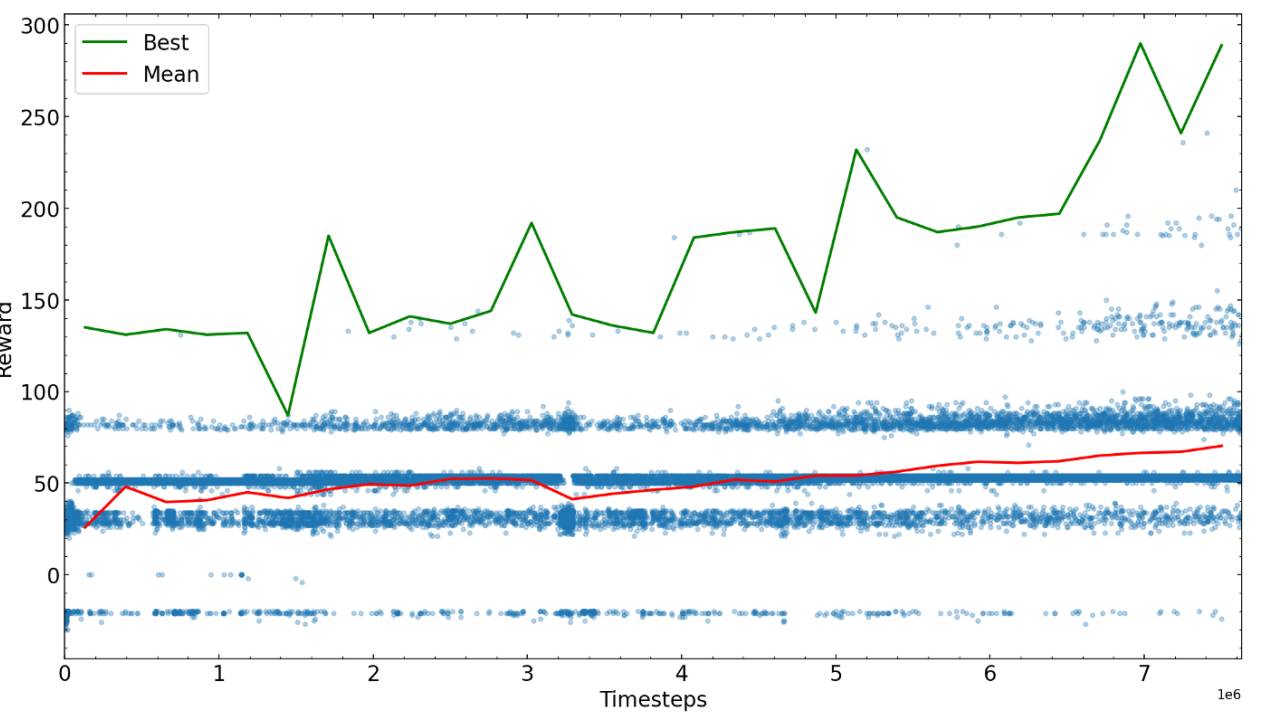
Après suffisamment d'étapes, l'algorithme d'entraînement du serpent converge vers une certaine valeur de récompense, vous pouvez terminer l'entraînement ou essayer d'affiner les paramètres et continuer l'entraînement.
Les étapes d'entraînement requises pour atteindre la récompense maximale possible dépendent fortement du problème, du système de récompense et des hyperparamètres, il est donc recommandé d'optimiser avant d'entraîner l'algorithme. À la fin de l'exemple de formation de l'IA pour jouer au jeu Snake, nous avons constaté que l'IA était capable de trouver de la nourriture dans le labyrinthe et d'éviter d'entrer en collision avec la queue.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Top 10 des algorithmes d'apprentissage automatique que vous devez connaître
- Les deux domaines de recherche de l'intelligence artificielle sont
- Quelle est la relation entre l'intelligence artificielle, l'apprentissage automatique et l'apprentissage profond ?
- Comment s'appelle l'assistant d'intelligence artificielle de Honor ?
- Intelligence artificielle (IA), apprentissage automatique (ML) et apprentissage profond (DL) : quelle est la différence ?