
Maison >Périphériques technologiques >IA >Le moment Swin du modèle visuel Mamba, l'Académie chinoise des sciences, Huawei et d'autres ont lancé VMamba
Le moment Swin du modèle visuel Mamba, l'Académie chinoise des sciences, Huawei et d'autres ont lancé VMamba

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-22 15:21:111149parcourir
La position de Transformer dans le domaine des grands modèles est inébranlable. Cependant, à mesure que l'échelle du modèle s'étend et que la longueur de la séquence augmente, les limites de l'architecture Transformer traditionnelle commencent à devenir apparentes. Heureusement, l’avènement de Mamba change rapidement cette situation. Ses performances exceptionnelles ont immédiatement fait sensation dans la communauté IA. L’émergence de Mamba a apporté d’énormes avancées dans la formation de modèles et le traitement de séquences à grande échelle. Ses avantages se répandent rapidement dans la communauté de l’IA, apportant de grands espoirs pour les recherches et applications futures.
Jeudi dernier, l'introduction de Vision Mamba (Vim) a démontré son grand potentiel pour devenir l'épine dorsale de la prochaine génération du modèle visuel de base. Un jour plus tard, des chercheurs de l'Académie chinoise des sciences, de Huawei et du laboratoire Pengcheng ont proposé VMamba : Un modèle visuel de Mamba avec un champ récepteur global et une complexité linéaire. Cette œuvre marque le moment Swin du modèle visuel Mamba.

- Titre de l'article : VMamba : Visual State Space Model
- Adresse de l'article : https://arxiv.org/abs/2401.10166
- Adresse du code : https://github .com/MzeroMiko/VMamba
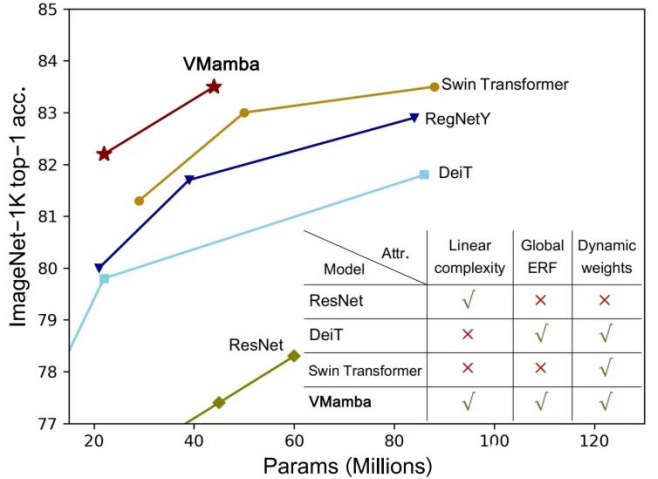
CNN et Visual Transformer (ViT) sont actuellement les deux modèles visuels de base les plus courants. Bien que CNN ait une complexité linéaire, ViT possède des capacités d’ajustement de données plus puissantes, mais au prix d’une complexité informatique plus élevée. Les chercheurs pensent que ViT a une forte capacité d’ajustement car il possède un champ récepteur global et des poids dynamiques. Inspirés par le modèle Mamba, les chercheurs ont conçu un modèle qui possède à la fois d'excellentes propriétés en complexité linéaire, à savoir le Visual State Space Model (VMamba). Des expériences approfondies ont prouvé que VMamba fonctionne bien dans diverses tâches visuelles. Comme le montre la figure ci-dessous, VMamba-S atteint une précision de 83,5 % sur ImageNet-1K, soit 3,2 % de plus que Vim-S et 0,5 % de plus que Swin-S.
Introduction à la méthode

La clé du succès de VMamba réside dans l'adoption du modèle S6, conçu à l'origine pour résoudre des tâches de traitement du langage naturel (NLP). Contrairement au mécanisme d'attention de ViT, le modèle S6 réduit efficacement la complexité quadratique à la linéarité en interagissant avec chaque élément du vecteur 1D avec les informations d'analyse précédente. Cette interaction rend VMamba plus efficace lors du traitement de données à grande échelle. Par conséquent, l’introduction du modèle S6 a posé une base solide pour le succès de VMamba.
Cependant, étant donné que les signaux visuels (tels que les images) ne sont pas naturellement ordonnés comme les séquences de texte, la méthode d'analyse des données dans S6 ne peut pas être directement appliquée aux signaux visuels. À cette fin, les chercheurs ont conçu un mécanisme d’analyse Cross-Scan. Le module Cross-Scan (CSM) adopte une stratégie d'analyse à quatre voies, c'est-à-dire une analyse simultanée à partir des quatre coins de la carte des caractéristiques (voir la figure ci-dessus). Cette stratégie garantit que chaque élément de la fonctionnalité intègre les informations provenant de tous les autres emplacements dans des directions différentes, formant ainsi un champ récepteur global sans augmenter la complexité de calcul linéaire.
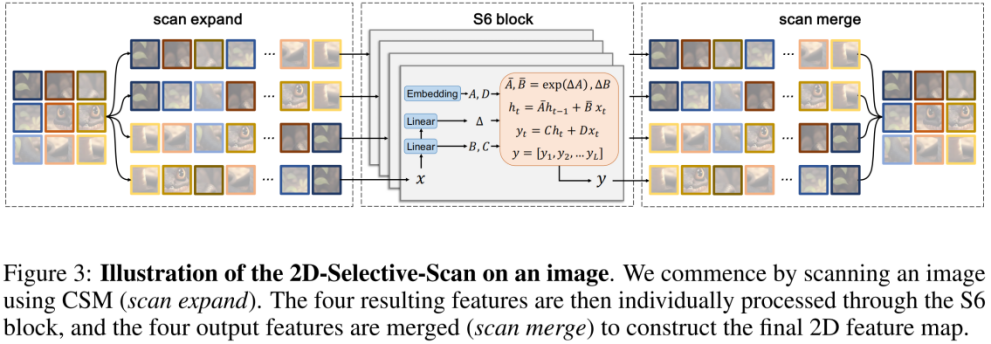
Basé sur CSM, l'auteur a conçu le module 2D-selective-scan (SS2D). Comme le montre la figure ci-dessus, SS2D se compose de trois étapes :
- scan expand aplatit une entité 2D en un vecteur 1D dans 4 directions différentes (supérieur gauche, inférieur droit, inférieur gauche, supérieur droit).
- Le bloc S6 envoie indépendamment les 4 vecteurs 1D obtenus à l'étape précédente à l'opération S6. La fusion par numérisation fusionne les 4 vecteurs 1D résultants en une sortie de fonctionnalité 2D.
L'image ci-dessus est le schéma de structure VMamba proposé dans cet article. Le cadre global de VMamba est similaire au modèle visuel traditionnel. La principale différence réside dans les opérateurs utilisés dans le module de base (bloc VSS). Le bloc VSS utilise l'opération de balayage sélectif 2D présentée ci-dessus, à savoir SS2D. SS2D garantit que VMamba atteint le 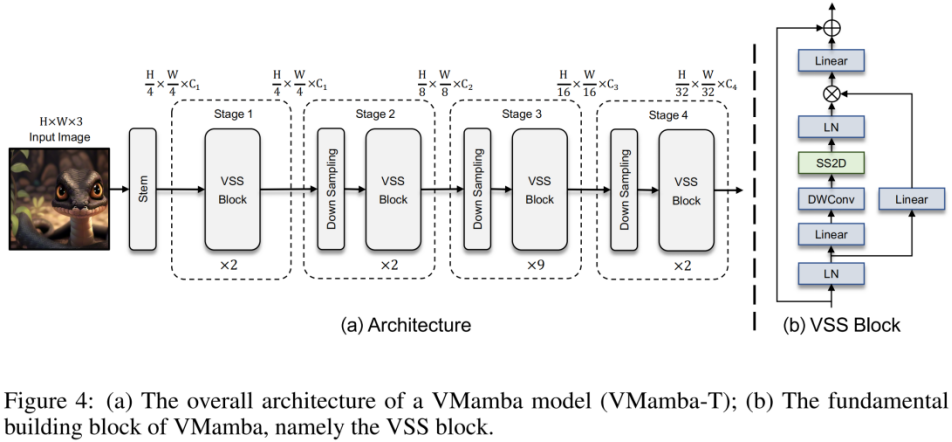 champ réceptif global au prix de la
champ réceptif global au prix de la
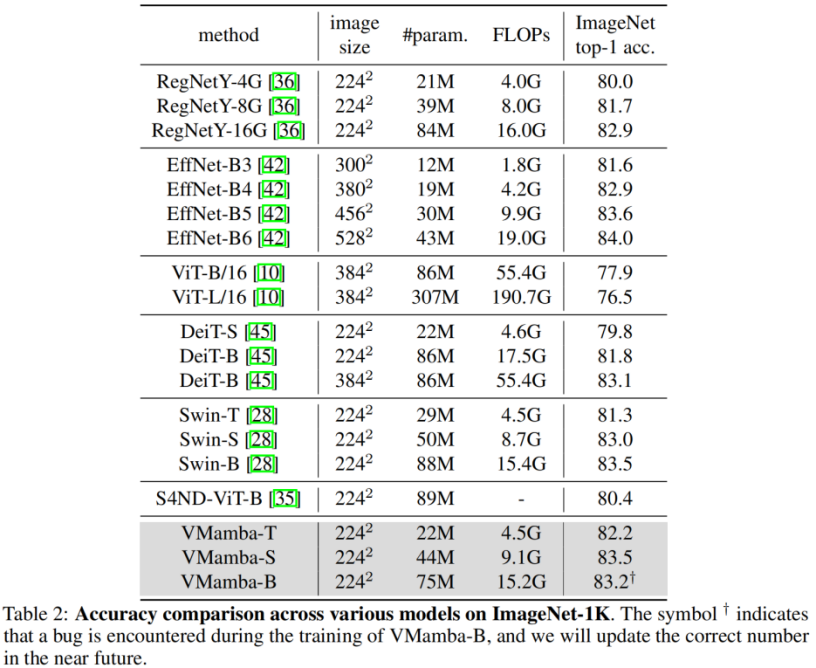
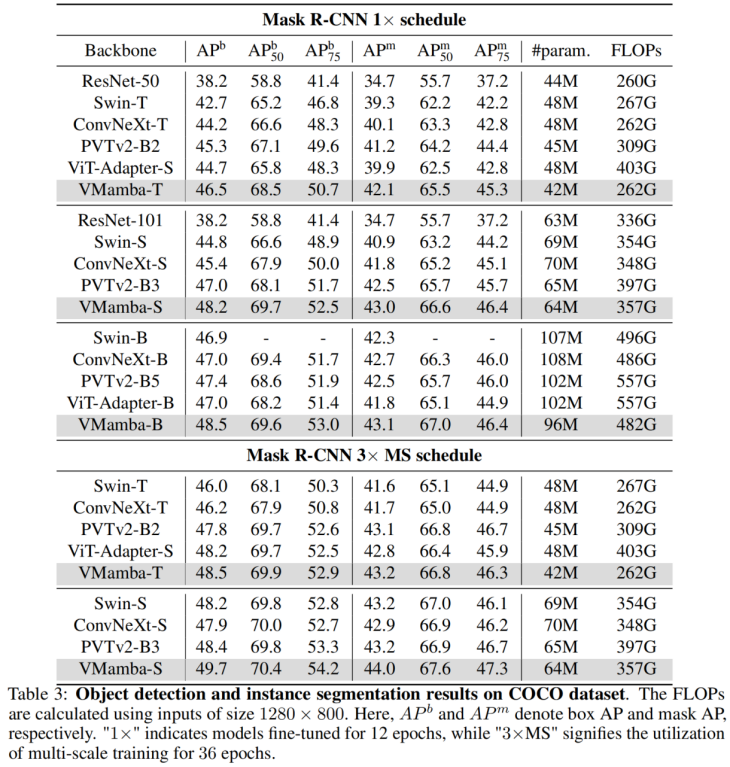
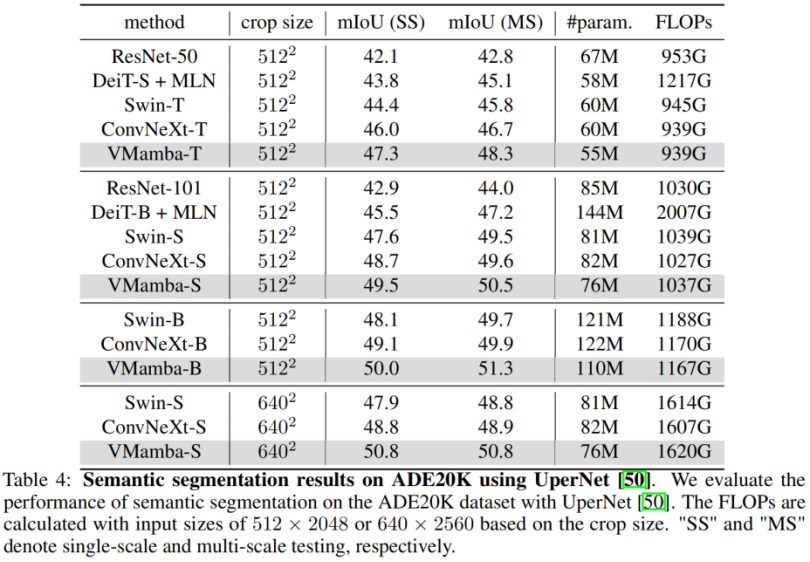
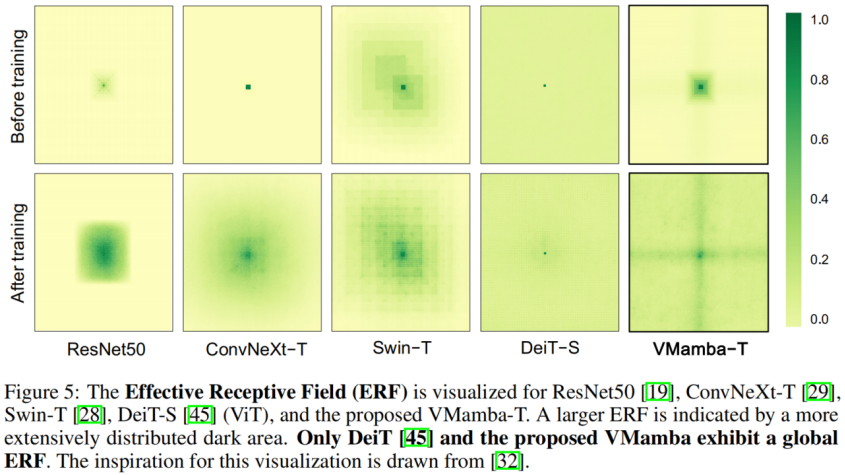
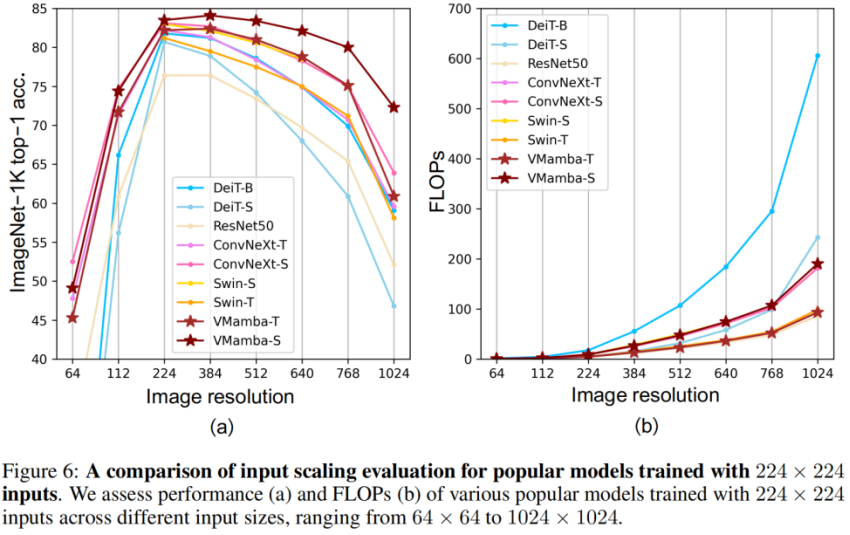
. Classification ImageNet Il n'est pas difficile de voir que sous des quantités de paramètres et des FLOP similaires : Ces résultats sont bien supérieurs au modèle Vision Mamba (Vim), vérifiant pleinement le potentiel de VMamba. Détection de cible COCO Sur l'ensemble de données COOCO, VMamba maintient également d'excellentes performances : dans le cas d'un réglage fin de 12 époques, VMamba-T/S/B ont respectivement atteint 46,5%/ 48,2 %/48,5 % mAP, dépassant Swin-T/S/B de 3,8 %/3,6 %/1,6 % mAP et dépassant ConvNeXt-T/S/B de 2,3 %/2,8 %/1,5 % mAP. Ces résultats vérifient que VMamba fonctionne pleinement dans les expériences visuelles en aval, démontrant son potentiel à remplacer les modèles visuels de base traditionnels. Segmentation sémantique ADE20K Sur ADE20K, VMamba a également montré d'excellentes performances. Le modèle VMamba-T atteint 47,3 % mIoU à une résolution de 512 × 512, un score qui surpasse tous les concurrents, notamment ResNet, DeiT, Swin et ConvNeXt. Cet avantage peut toujours être conservé sous le modèle VMamba-S/B. Champ récepteur efficace VMamba a un champ récepteur efficace global, et seul DeiT parmi d'autres modèles possède cette fonctionnalité. Cependant, il convient de noter que le coût de DeiT est une complexité quadratique, tandis que VMamaba est une complexité linéaire. Mise à l'échelle de l'échelle d'entrée Enfin, attendons avec impatience que davantage de modèles de vision basés sur Mamba soient proposés, aux côtés des CNN et des ViT, pour fournir une troisième option pour les modèles de vision de base. Résultats expérimentaux
Expérience d'analyse
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quel est le modèle de boîte CSS ?
- Décrivez brièvement quelle est l'unité de stockage des données dans un ordinateur ?
- Comment utiliser vlookup d'Excel pour faire correspondre plusieurs colonnes de données à la fois
- Que dois-je faire si le texte WPS ne parvient pas à ouvrir la source de données ?
- Quel est le processus de conversion d'un diagramme e-r en un modèle de données relationnel ?