
Maison >Périphériques technologiques >IA >Concours de tests de framework de génération vidéo IA : Pika, Gen-2, ModelScope, SEINE, qui peut gagner ?
Concours de tests de framework de génération vidéo IA : Pika, Gen-2, ModelScope, SEINE, qui peut gagner ?

- 王林avant
- 2024-01-22 13:06:121119parcourir
La génération vidéo IA est l'un des domaines les plus en vogue récemment. Divers laboratoires universitaires, le géant de l'Internet AI Labs et des start-ups ont rejoint la piste de génération de vidéos IA. La sortie de modèles de génération vidéo tels que Pika, Gen-2, Show-1, VideoCrafter, ModelScope, SEINE, LaVie et VideoLDM est encore plus accrocheuse. v⁽ⁱ⁾
Vous devez être curieux de répondre aux questions suivantes :
- Quel modèle de génération vidéo est le meilleur ?
- Quelles sont les spécialités de chaque modèle ?
- Quels sont les problèmes qui méritent attention et doivent être résolus dans le domaine de la génération vidéo IA ?
À cette fin, nous avons lancé VBench, un « cadre d'évaluation complet pour les modèles de génération vidéo » conçu pour fournir aux utilisateurs des informations sur les avantages, les inconvénients et les caractéristiques des différents modèles vidéo. Grâce à VBench, les utilisateurs peuvent comprendre les points forts et les avantages des différents modèles vidéo.

- Papier : https://arxiv.org/abs/2311.17982
- Code : https://github.com/Vchitect/VBench
- Page Web : https ://vchitect.github.io/VBench-project/
- Titre de l'article : VBench : Suite de référence complète pour les modèles génératifs vidéo
VBench peut non seulement évaluer de manière complète et méticuleuse l'effet de génération vidéo, mais également fournir Évaluation cohérente de l'expérience sensorielle des personnes, économisant du temps et de l'énergie.
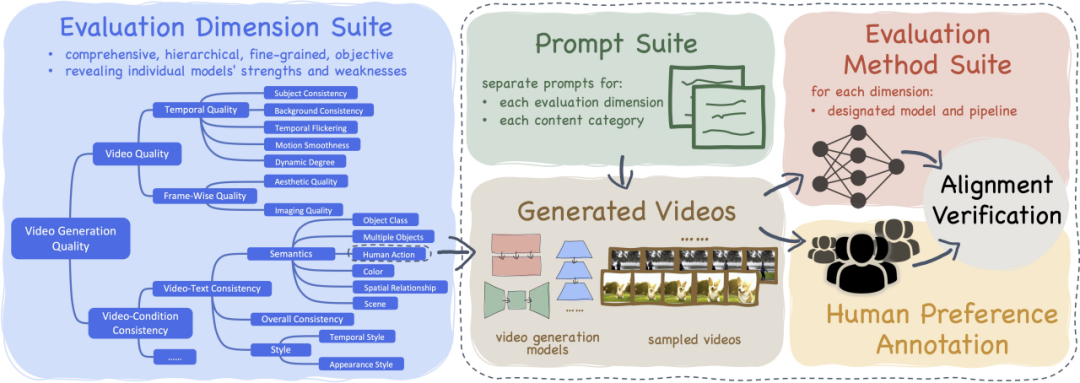
- VBench contient 16 dimensions d'évaluation superposées et découplées
- VBench a open source le système Prompt List pour l'évaluation de la génération vidéo Vincent
- Schéma d'évaluation VBench pour chaque dimension Aligné avec la perception humaine et évaluation
- VBench fournit des informations multi-perspectives pour faciliter l'exploration future de la génération vidéo IA

"VBench" - une suite complète de référence de "modèles de génération vidéo"

Modèle de génération vidéo IA - résultats de l'évaluation
Modèle de génération de vidéo IA open source
Les performances de chaque modèle de génération de vidéo IA open source sur VBench sont les suivantes.
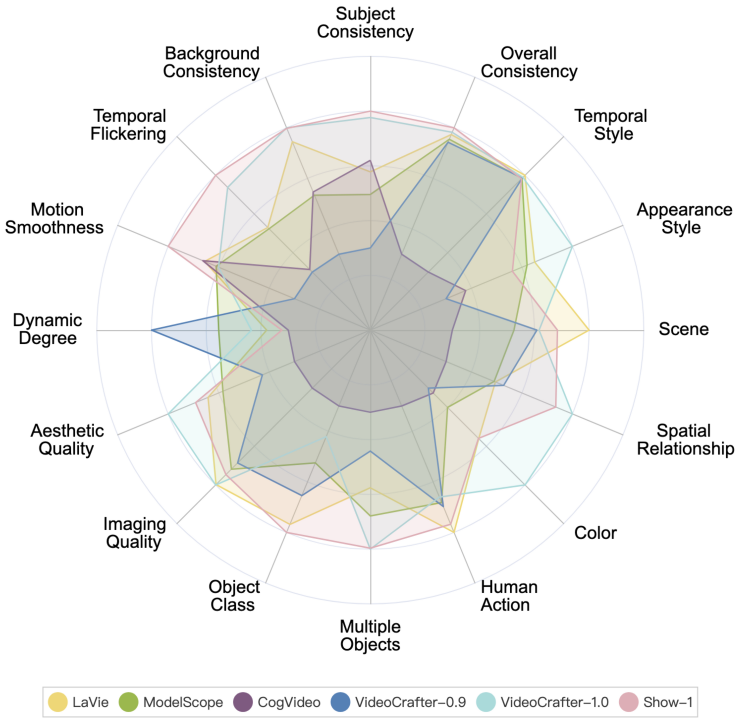
Les performances de divers modèles de génération de vidéo IA open source sur VBench. Dans le graphique radar, nous avons normalisé les résultats pour chaque dimension entre 0,3 et 0,8 afin de visualiser la comparaison plus clairement.
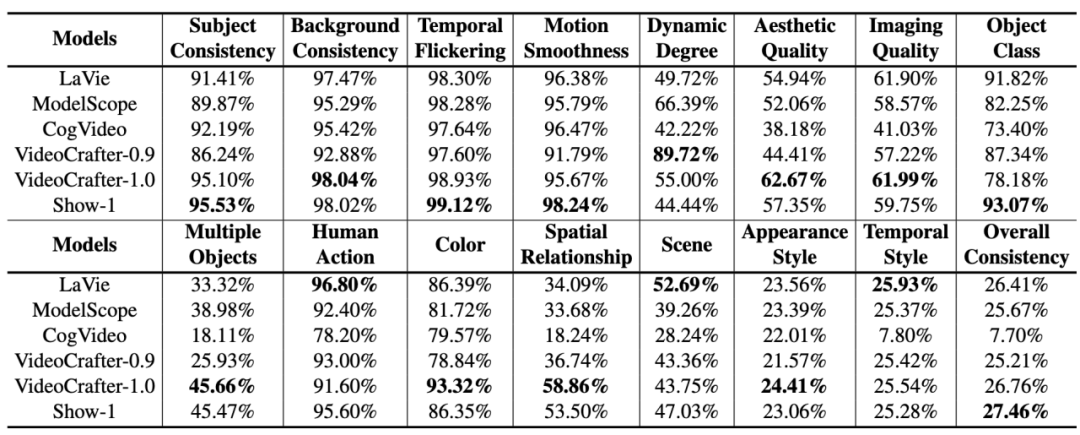
Les performances de divers modèles de génération de vidéo IA open source sur VBench.
Parmi les 6 modèles ci-dessus, on peut voir que VideoCrafter-1.0 et Show-1 ont des avantages relatifs dans la plupart des dimensions.
Modèles de génération vidéo de startups
VBench fournit actuellement les résultats d'évaluation de deux modèles de startup, Gen-2 et Pika.
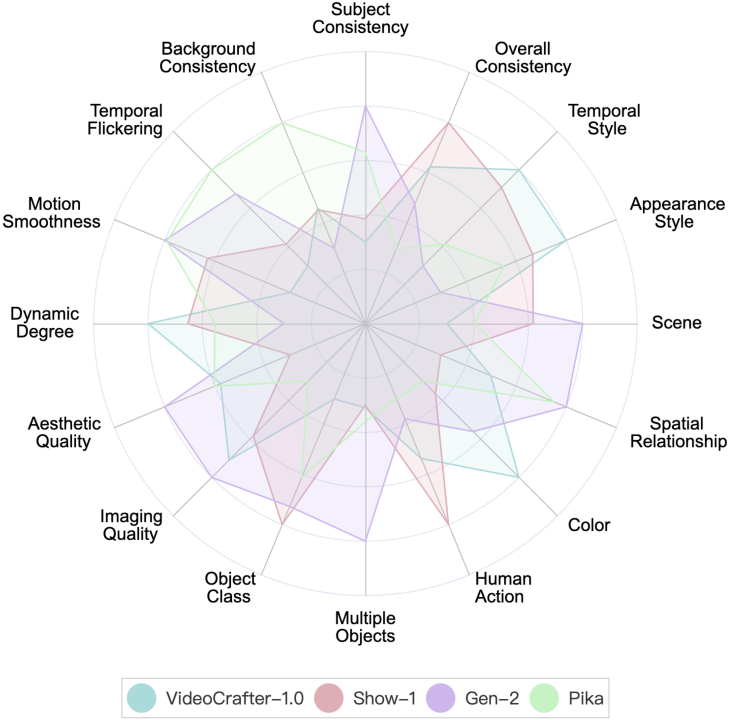
Performance de Gen-2 et Pika sur VBench. Dans le graphique radar, afin de visualiser la comparaison plus clairement, nous avons ajouté VideoCrafter-1.0 et Show-1 comme références et normalisé les résultats d'évaluation de chaque dimension entre 0,3 et 0,8.
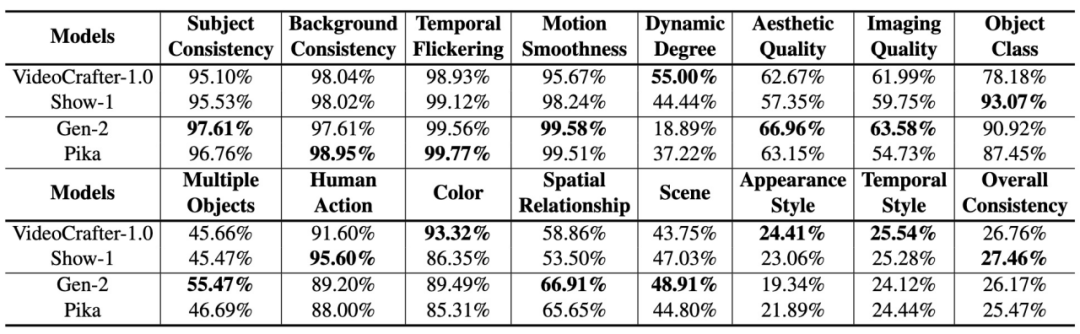
Performance de Gen-2 et Pika sur VBench. Nous incluons les résultats numériques de VideoCrafter-1.0 et Show-1 comme référence.
On peut voir que Gen-2 et Pika présentent des avantages évidents en termes de qualité vidéo (qualité vidéo), tels que la cohérence temporelle (cohérence temporelle) et la qualité d'image unique (qualité esthétique et qualité d'imagerie). En termes de cohérence sémantique avec les invites de saisie de l'utilisateur (telles que l'action humaine et le style d'apparence), les modèles open source à dimensions partielles seront meilleurs.
Modèle de génération vidéo VS modèle de génération d'image
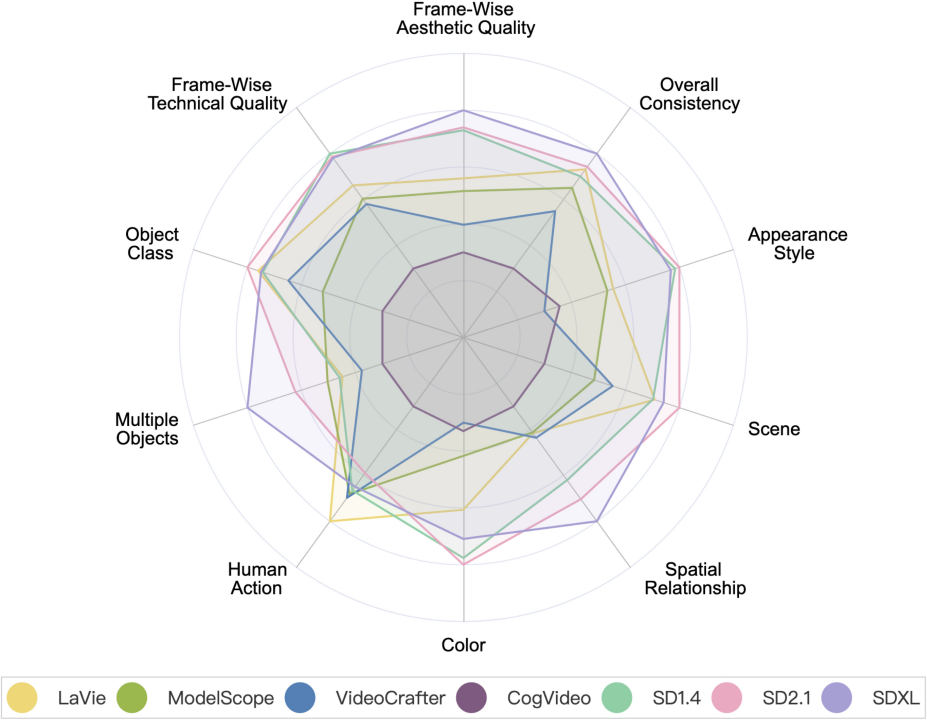
Modèle de génération vidéo VS modèle de génération d'image. Parmi eux, SD1.4, SD2.1 et SDXL sont des modèles de génération d'images.
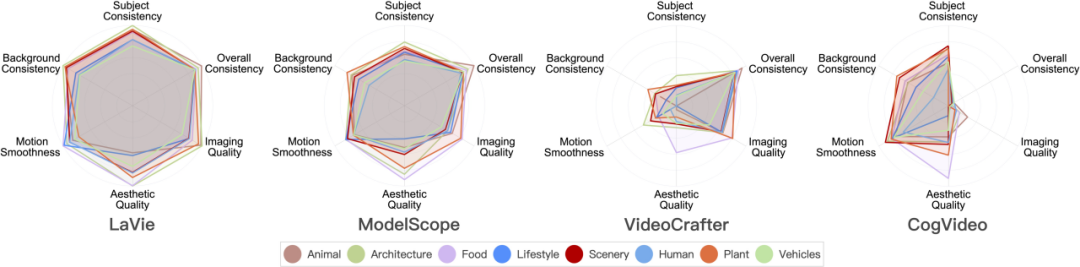
Performance du modèle de génération vidéo sur 8 catégories de scènes majeures
Voici les résultats d'évaluation de différents modèles sur 8 catégories différentes.
VBench est désormais open source et peut être installé en un clic
À l'heure actuelle, VBench est entièrement open source et prend en charge l'installation en un clic. Tout le monde est invité à jouer, tester les modèles qui vous intéressent et travailler ensemble pour promouvoir le développement de la communauté de génération vidéo.



Adresse open source : https://github.com/Vchitect/VBench
Nous avons également open source une série de Prompt Listes : https ://github.com/Vchitect/VBench/tree/master/prompts, contient des benchmarks pour l'évaluation dans différentes dimensions de capacités, ainsi que des benchmarks d'évaluation sur différents contenus de scénarios.
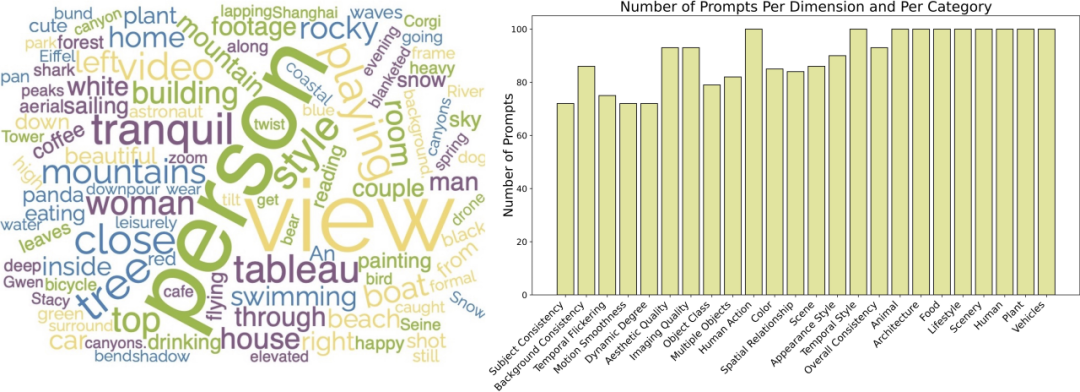
Le nuage de mots à gauche montre la répartition des mots à haute fréquence dans nos suites d'invites, et l'image de droite montre les statistiques du nombre d'invites dans différentes dimensions et catégories.
VBench est-il précis ?
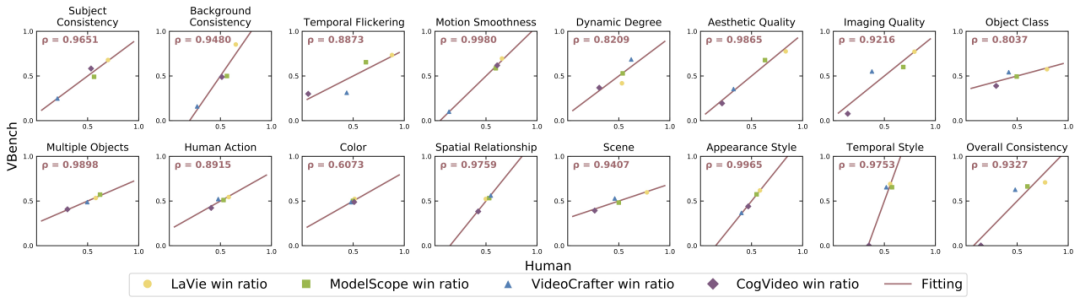
Pour chaque dimension, nous avons calculé la corrélation entre les résultats de l'évaluation VBench et les résultats de l'évaluation manuelle afin de vérifier la cohérence de notre méthode avec la perception humaine. Dans la figure ci-dessous, l'axe horizontal représente les résultats de l'évaluation manuelle dans différentes dimensions, et l'axe vertical montre les résultats de l'évaluation automatique de la méthode VBench. On peut voir que notre méthode est fortement alignée sur la perception humaine dans toutes les dimensions.
VBench apporte la réflexion à la génération de vidéos IA
VBench peut non seulement évaluer les modèles existants, mais plus important encore, il peut également découvrir divers problèmes qui peuvent exister dans différents modèles pour fournir des conseils pour l'IA future. Le développement de la génération vidéo fournit des informations précieuses.
"Cohérence temporelle" et "Dynamique vidéo" : ne choisissez pas l'un ou l'autre, mais améliorez les deux
Nous avons constaté que la cohérence temporelle (telle que la cohérence du sujet, la cohérence de l'arrière-plan, la fluidité du mouvement) et vidéo Il existe une certaine relation de compromis entre l'amplitude du mouvement (degré dynamique). Par exemple, Show-1 et VideoCrafter-1.0 ont obtenu de très bons résultats en termes de cohérence d'arrière-plan et de fluidité des actions, mais ont obtenu des résultats inférieurs en termes de dynamique. Cela peut être dû au fait que la génération d'images « immobiles » est plus susceptible d'apparaître « dans le timing » ; Très cohérent." VideoCrafter-0.9, en revanche, est plus faible sur la dimension liée à la cohérence temporelle, mais obtient un score élevé sur le degré dynamique.
Cela montre qu'il est en effet difficile d'atteindre en même temps une « cohérence temporelle » et un « niveau dynamique plus élevé » ; à l'avenir, nous ne devrions pas nous concentrer uniquement sur l'amélioration d'un aspect, mais améliorer la « cohérence temporelle » et la « vidéo ». qualité" en même temps. Degré dynamique" ces deux aspects, cela a du sens.
Évaluez par contenu de scène pour explorer le potentiel de chaque modèle
Certains modèles présentent de grandes différences de performances dans différentes catégories. Par exemple, en termes de qualité esthétique (Aesthetic Quality), CogVideo est dans "Food". La catégorie « » a obtenu de bons résultats, mais a obtenu des résultats inférieurs dans la catégorie « LifeStyle ». Si les données d'entraînement sont ajustées, la qualité esthétique de CogVideo dans les catégories « LifeStyle » peut-elle être améliorée, améliorant ainsi la qualité esthétique vidéo globale du modèle ?
Cela nous indique également que lors de l'évaluation d'un modèle de génération vidéo, nous devons considérer les performances du modèle dans différentes catégories ou sujets, explorer la limite supérieure du modèle dans une certaine dimension de capacité, puis améliorer de manière ciblée le " catégories de scènes à la traîne.
Catégories à mouvement complexe : mauvaises performances spatio-temporelles
Les catégories à forte complexité spatiale ont de faibles scores dans la dimension qualité esthétique. Par exemple, la catégorie « LifeStyle » a des exigences relativement élevées en matière de disposition d'éléments complexes dans l'espace, et la catégorie « Humain » pose des défis en raison de la génération de structures articulées.
Pour les catégories au timing complexe, comme la catégorie « Humain » qui implique généralement des actions complexes et la catégorie « Véhicule » qui se déplace souvent plus rapidement, leurs scores sont relativement faibles dans toutes les dimensions testées. Cela montre que le modèle actuel présente encore certaines lacunes dans le traitement de la modélisation temporelle. Les limitations de la modélisation temporelle peuvent conduire à un flou et une distorsion spatiale, entraînant une qualité vidéo insatisfaisante à la fois dans le temps et dans l'espace.
Difficile de générer des catégories : il y a peu d'avantages à augmenter la quantité de données
Nous avons effectué des statistiques sur l'ensemble de données vidéo couramment utilisé WebVid-10M et avons constaté qu'environ 26 % des données sont liées à "Humain". La proportion la plus élevée parmi les huit catégories que nous avons comptées. Cependant, dans les résultats de l'évaluation, la catégorie « Humain » était l'une des moins performantes parmi les huit catégories.
Cela montre que pour une catégorie complexe comme « Humain », la simple augmentation de la quantité de données peut ne pas apporter d'améliorations significatives aux performances. Une méthode potentielle consiste à guider l'apprentissage du modèle en introduisant des connaissances ou des contrôles préalables liés à l'« humain », tels que les squelettes, etc.
Millions d'ensembles de données : privilégiez l'amélioration de la qualité des données plutôt que le volume des données
Bien que la catégorie "Alimentation" ne représente que 11 % dans WebVid-10M, elle occupe presque toujours le meilleur classement dans l'évaluation Qualité esthétique score. Nous avons donc analysé plus en détail les performances de qualité esthétique de différentes catégories de contenu dans l'ensemble de données WebVid-10M et avons constaté que la catégorie « Alimentation » a également le score esthétique le plus élevé dans WebVid-10M.
Cela signifie que sur la base de millions de données, filtrer/améliorer la qualité des données est plus utile que d'augmenter la quantité de données.
Possibilité d'amélioration : Générer avec précision plusieurs objets et la relation entre les objets
Le modèle de génération vidéo actuel est en "Objets multiples" et "Relation spatiale" En termes de performances, il ne peut toujours pas rattraper son retard avec des modèles de génération d'images (notamment SDXL), ce qui souligne l'importance d'améliorer les capacités de combinaison. La capacité dite de combinaison fait référence à la capacité du modèle à afficher avec précision plusieurs objets lors de la génération vidéo, ainsi qu'aux relations spatiales et interactives entre eux.
Les méthodes potentielles pour résoudre ce problème peuvent inclure :
- Étiquetage des données : construire un ensemble de données vidéo pour fournir des descriptions claires de plusieurs objets dans la vidéo, ainsi que des descriptions des relations de position spatiale et des relations d'interaction entre objets .
- Ajoutez des modes/modules intermédiaires pendant le processus de génération vidéo pour aider à contrôler la combinaison et la position spatiale des objets.
- L'utilisation d'un meilleur encodeur de texte (Text Encoder) aura également un plus grand impact sur la capacité de génération combinée du modèle.
- Courbe pour sauver le pays : confier le problème de la « combinaison d'objets » que T2V ne peut pas bien faire à T2I, et générer des vidéos via T2I+I2V. Cette approche peut également être efficace pour de nombreux autres problèmes liés à la génération vidéo.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Vidéo originale du site Web php chinois : Résumé des cours de la série de formations PHP sur le bien-être public « Dragon Babu » !
- quel logiciel est ai
- Que signifie l'échec du démarrage du gestionnaire de démarrage Windows ?
- Quel dossier est BaiduNetDisk ?
- Comment définir des effets de fondu entrant et sortant pour les vidéos dans Premiere