
Maison >Périphériques technologiques >IA >Améliorez efficacement les capacités de détection : percez la détection de petites cibles au-dessus de 200 mètres
Améliorez efficacement les capacités de détection : percez la détection de petites cibles au-dessus de 200 mètres

- PHPzavant
- 2024-01-15 19:51:291039parcourir
Cet article est réimprimé avec l'autorisation du compte public Autonomous Driving Heart. Veuillez contacter la source pour la réimpression.
La détection d'objets 3D basée sur un nuage de points LiDAR a toujours été un problème très classique. Le monde universitaire et l'industrie ont proposé divers modèles pour améliorer la précision, la vitesse et la robustesse. Cependant, en raison de l'environnement extérieur complexe, les performances de la détection d'objets pour les nuages de points extérieurs ne sont pas très bonnes. Les nuages de points Lidar sont de nature clairsemée. Comment résoudre ce problème de manière ciblée ? L'article donne sa propre réponse : extraire des informations sur la base de l'agrégation d'informations de séries chronologiques.
1. Informations papier

2. Introduction

Cet article aborde un défi clé de la conduite autonome : créer avec précision une représentation tridimensionnelle de l'environnement environnant. Ceci est important pour la fiabilité et la sécurité des voitures autonomes. En particulier, les véhicules autonomes doivent être capables de reconnaître les objets environnants, tels que les véhicules et les piétons, et de déterminer avec précision leur emplacement, leur taille et leur orientation. En règle générale, les gens utilisent des réseaux de neurones profonds pour traiter les données LiDAR afin d'accomplir cette tâche.
La plupart de la littérature existante se concentre sur les méthodes mono-frame, c'est-à-dire utilisant des données numérisées par un capteur à la fois. Cette méthode fonctionne bien sur les benchmarks classiques avec des objets situés à des distances allant jusqu'à 75 mètres. Cependant, les nuages de points lidar sont par nature clairsemés, en particulier à longue distance. Par conséquent, le document indique que l’utilisation d’un seul balayage pour une détection à longue portée (par exemple jusqu’à 200 mètres) n’est pas suffisante. Cela signifie qu’une méthode de fusion multi-trames est nécessaire pour augmenter la densité du nuage de points et améliorer la précision de la mesure de distance. En enregistrant et en fusionnant les données de numérisation à partir de plusieurs pas de temps, des résultats de reconstruction de scène et de mesure de distance plus complets et plus précis peuvent être obtenus. De telles méthodes présentent une fiabilité et une robustesse plus élevées dans des tâches telles que la détection de cibles à longue distance et l'évitement d'obstacles. Par conséquent, la contribution de l'article est de proposer une méthode basée sur la fusion multi-trame
Pour résoudre ce problème, une méthode consiste à acquérir en continu des données d'analyse lidar via l'agrégation de nuages de points pour obtenir une entrée plus dense. Cependant, cette approche est coûteuse en termes de calcul et ne parvient pas à tirer pleinement parti de l’agrégation intra-réseau. Une alternative évidente consiste donc à adopter une approche récursive pour résoudre ce problème en accumulant progressivement des informations. Les méthodes récursives mettent continuellement à jour les informations au fil du temps, fournissant des résultats plus précis et plus complets. Avec les méthodes récursives, de grandes quantités de données d’entrée peuvent être traitées efficacement et sont plus efficaces sur le plan informatique. De cette façon, nous pouvons économiser des ressources informatiques tout en résolvant le problème.
L'article mentionne également d'autres techniques pour augmenter la portée de détection, telles que la convolution clairsemée, le module d'attention et la convolution 3D. Cependant, ces méthodes ignorent souvent les problèmes de compatibilité du matériel cible. Lors du déploiement et de la formation de réseaux neuronaux, le matériel utilisé peut varier considérablement en termes d'opérations prises en charge et de latence. Par exemple, le matériel cible tel que Nvidia Orin DLA ne prend souvent pas en charge des opérations telles que la convolution ou l'attention éparse. De plus, l’utilisation de couches telles que la convolution 3D peut ne pas être réalisable en raison des exigences de latence en temps réel. Par conséquent, l’utilisation d’opérations simples, telles que la convolution 2D, devient plus nécessaire.
L'article propose un nouveau modèle récursif temporel, TimePillars, qui respecte l'ensemble des opérations prises en charge sur le matériel cible commun, s'appuie sur la convolution 2D, est basé sur une représentation d'entrée point-pilier (Pillar) et une unité récursive convolutive. La compensation d'auto-mouvement est appliquée aux états cachés des unités récurrentes à l'aide d'une convolution unique et d'un apprentissage auxiliaire. L'utilisation de tâches auxiliaires pour garantir l'exactitude de cette manipulation s'est avérée appropriée grâce à des études d'ablation. L'article étudie également le placement optimal du module récursif dans le pipeline et montre clairement que le placer entre l'épine dorsale du réseau et la tête de détection permet d'obtenir les meilleures performances. Sur le nouveau Zenseact Open Dataset (ZOD), l'article démontre l'efficacité de la méthode TimePillars. Par rapport aux lignes de base point et pilier à image unique et multi-images, TimePillars permet d'obtenir des améliorations significatives des performances d'évaluation, en particulier pour la détection à longue portée (jusqu'à 200 mètres) dans les catégories importantes de cyclistes et de piétons. Enfin, les TimePillars ont une latence nettement inférieure à celle des piliers multi-trames, ce qui les rend adaptés aux systèmes en temps réel.
Cet article propose un nouveau modèle récursif temporel appelé TimePillars pour résoudre la tâche de détection d'objets lidar 3D. Par rapport aux lignes de base à piliers ponctuels à image unique et multi-images, TimePillars démontre des performances nettement meilleures en matière de détection à longue portée et respecte l'ensemble des opérations prises en charge par le matériel cible commun. L’article compare également pour la première fois un modèle de détection d’objets lidar 3D sur le nouvel ensemble de données ouvert Zenseact. Cependant, les limites de l'article sont qu'il ne prend en compte que les données lidar, sans prendre en compte de manière exhaustive les autres entrées de capteurs, et que son approche est basée sur une base de référence unique et de pointe. Néanmoins, les auteurs estiment que leur cadre est général et que les améliorations futures de la base de référence entraîneront des améliorations globales des performances.
3. Méthode
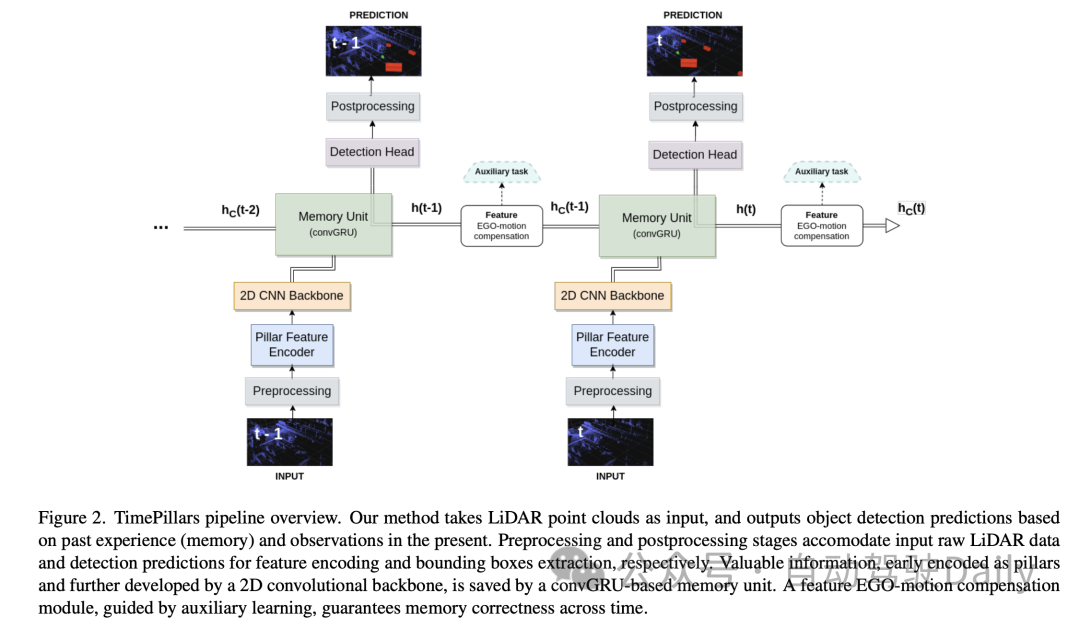
3.1 Prétraitement des entrées
Dans la partie "Prétraitement des entrées" de cet article, l'auteur utilise la technologie de "Pillarisation" pour traiter les données du nuage de points d'entrée. Cette méthode est différente de la voxélisation conventionnelle, qui segmente le nuage de points en structures en colonnes verticales uniquement dans la direction horizontale (axes x et y) tout en conservant une hauteur fixe dans la direction verticale (axe z). Cela maintient les dimensions d'entrée du réseau cohérentes et permet un traitement efficace à l'aide de convolutions 2D.
Cependant, un problème avec la pilarisation est qu'elle produit de nombreuses colonnes vides, ce qui entraîne des données très clairsemées. Pour résoudre ce problème, l'article propose l'utilisation de la technologie de voxélisation dynamique. Cette technique évite d'avoir un nombre prédéfini de points pour chaque colonne, éliminant ainsi le besoin d'opérations de troncature ou de remplissage sur chaque colonne. Au lieu de cela, l'intégralité des données du nuage de points est traitée dans son ensemble pour correspondre au nombre total de points requis, fixé ici à 200 000 points. L'avantage de cette méthode de prétraitement est qu'elle minimise la perte d'informations et rend la représentation des données générées plus stable et cohérente.
3.2 Architecture du modèle
Ensuite, pour l'architecture du modèle, l'auteur a présenté en détail une architecture de réseau neuronal composée d'un encodeur de fonctionnalités pilier, d'une épine dorsale de réseau neuronal convolutif (CNN) 2D et d'une tête de détection.
- Pillar Feature Encoder : cette partie mappe le tenseur d'entrée prétraité dans une pseudo-image Bird's Eye View (BEV). Après avoir utilisé la voxélisation dynamique, le PointNet simplifié est ajusté en conséquence. L'entrée est traitée par convolution 1D, normalisation par lots et fonction d'activation ReLU, ce qui donne un tenseur de forme , où représente le nombre de canaux. Avant la couche finale de dispersion maximale, une mise en commun maximale est appliquée aux canaux, formant un espace de forme latent . Puisque le tenseur initial est codé comme , qui devient après la couche précédente, l'opération de pooling maximum est supprimée.
- Backbone : Utilisation de l'architecture de base CNN 2D proposée dans l'article en colonnes original en raison de son efficacité en profondeur supérieure. L'espace latent est réduit à l'aide de trois blocs de sous-échantillonnage (Conv2D-BN-ReLU) et restauré à l'aide de trois blocs de suréchantillonnage et d'une convolution transposée, avec une forme de sortie de .
- Memory Unit : modélisez la mémoire du système comme un réseau neuronal récurrent (RNN), en utilisant spécifiquement le GRU convolutif (convGRU), qui est la version convolutive de Gated Recurrent Unit. L’avantage du GRU convolutif est qu’il évite le problème du gradient de disparition et améliore l’efficacité tout en conservant les caractéristiques des données spatiales. Comparé à d'autres options telles que LSTM, GRU a moins de paramètres entraînables en raison de son plus petit nombre de portes et peut être considéré comme une technique de régularisation de la mémoire (réduisant la complexité des états cachés). En fusionnant des opérations de nature similaire, le nombre de couches convolutives requises est réduit, ce qui rend l'unité plus efficace.
- Tête de détection : Une simple modification du SSD (Single Shot MultiBox Detector). Le concept de base du SSD est conservé, c'est-à-dire un passage unique sans proposition de région, mais l'utilisation de boîtes d'ancrage est éliminée. La production directe de prédictions pour chaque cellule de la grille, bien que perdant la capacité de détection multi-objets des cellules, évite les ajustements fastidieux et souvent imprécis des paramètres de la boîte d'ancrage et simplifie le processus d'inférence. La couche linéaire gère les sorties respectives de la régression de classification et de localisation (position, taille et angle). Seule la taille utilise une fonction d'activation (ReLU) pour éviter de prendre des valeurs négatives. De plus, contrairement à la littérature connexe, cet article évite le problème de la régression angulaire directe en prédisant indépendamment les composantes sinus et cosinus de la direction de conduite du véhicule et en en extrayant les angles.
3.3 Compensation des caractéristiques d'ego-mouvement
Dans cette partie de l'article, l'auteur explique comment traiter les caractéristiques d'état caché produites par le GRU convolutif, qui sont représentées par le système de coordonnées de l'image précédente. S'il est stocké directement et utilisé pour calculer la prochaine prédiction, une inadéquation spatiale se produira en raison du mouvement de l'ego.
Pour la conversion, différentes techniques peuvent être appliquées. Idéalement, les données corrigées seraient introduites dans le réseau plutôt que transformées au sein du réseau. Cependant, ce n’est pas l’approche proposée dans l’article, car elle nécessite de réinitialiser les états cachés à chaque étape du processus d’inférence, de transformer les nuages de points précédents et de les propager à travers le réseau. Non seulement cela est inefficace, mais cela va à l’encontre de l’objectif de l’utilisation des RNN. Par conséquent, dans un contexte de boucle, la compensation doit être effectuée au niveau des fonctionnalités. Cela rend la solution hypothétique plus efficace, mais rend également le problème plus complexe. Les méthodes d'interpolation traditionnelles peuvent être utilisées pour obtenir des caractéristiques dans des systèmes de coordonnées transformés.
En revanche, inspiré des travaux de Chen et al., l'article propose d'utiliser des opérations de convolution et des tâches auxiliaires pour effectuer des transformations. Compte tenu des détails limités des travaux susmentionnés, l'article propose une solution personnalisée à ce problème.
L'approche adoptée par le document consiste à fournir au réseau les informations nécessaires pour effectuer la transformation des fonctionnalités via une couche convolutive supplémentaire. La matrice de transformation relative entre deux images consécutives est d'abord calculée, c'est-à-dire les opérations nécessaires pour réussir la transformation des caractéristiques. Ensuite, les informations 2D (partie rotation et translation) en sont extraites :
Cette simplification évite les principales constantes matricielles et fonctionne dans le domaine 2D (pseudo-image), réduisant les 16 valeurs à 6. La matrice est ensuite aplatie et agrandie pour épouser la forme des éléments cachés à compenser. La première dimension représente le nombre d'images à convertir. Cette représentation permet de concaténer chaque pilier potentiel dans la dimension canal de l'entité cachée.
Enfin, les caractéristiques de l'état caché sont introduites dans une couche convolutive 2D, adaptée au processus de transformation. Un aspect clé à noter est que réaliser une convolution ne garantit pas que la transformation aura lieu. La concaténation des canaux fournit simplement au réseau des informations supplémentaires sur la manière dont la transformation peut être effectuée. Dans ce cas, le recours à l’apprentissage assisté est approprié. Lors de la formation, un objectif d'apprentissage supplémentaire (transformation de coordonnées) est ajouté en parallèle à l'objectif principal (détection d'objets). Une tâche auxiliaire est conçue dont le but est de guider le réseau à travers le processus de transformation sous supervision pour garantir l'exactitude de la compensation. La tâche auxiliaire est limitée au processus de formation. Une fois que le réseau apprend à transformer correctement les fonctionnalités, il perd son applicabilité. Par conséquent, cette tâche n’est pas prise en compte lors de l’inférence. Dans la section suivante, d’autres expériences seront menées pour comparer l’impact.
4. Expériences
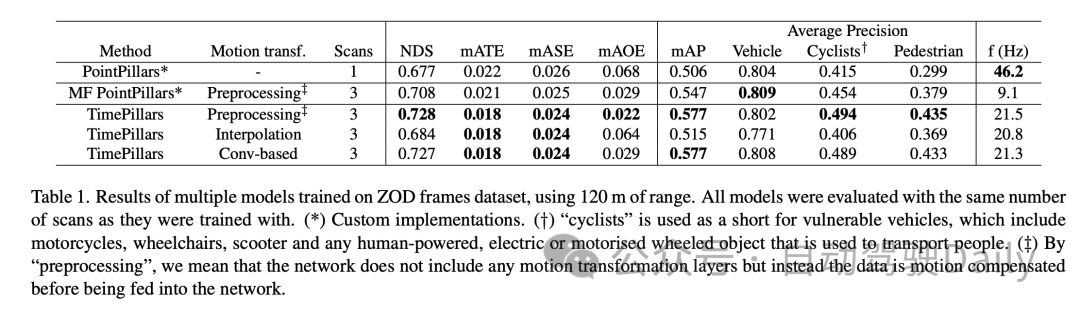
Les résultats expérimentaux montrent que le modèle TimePillars fonctionne bien lors du traitement de l'ensemble de données de trame Zenseact Open Dataset (ZOD), en particulier lors du traitement de plages allant jusqu'à 120 mètres. Ces résultats mettent en évidence les différences de performances de TimePillars selon différentes méthodes de transformation de mouvement et les comparent avec d'autres méthodes.
Après avoir comparé le modèle de base PointPillars et les PointPillars multi-frame (MF), on peut constater que TimePillars a obtenu des améliorations significatives dans plusieurs indicateurs de performance clés. En particulier sur le score de détection NuScenes (NDS), TimePillars affiche un score global plus élevé, reflétant ses avantages en termes de performances de détection et de précision de positionnement. De plus, TimePillars a également atteint des valeurs inférieures en termes d'erreur de conversion moyenne (mATE), d'erreur d'échelle moyenne (mASE) et d'erreur d'orientation moyenne (mAOE), ce qui indique qu'il est plus précis dans la précision de positionnement et l'estimation de l'orientation. Il convient de noter en particulier que les différentes implémentations de TimePillars en termes de conversion de mouvement ont un impact significatif sur les performances. Lors de l'utilisation d'une transformation de mouvement basée sur la convolution (Conv-based), TimePillars fonctionne particulièrement bien sur NDS, mATE, mASE et mAOE, prouvant l'efficacité de cette méthode en matière de compensation de mouvement et d'amélioration de la précision de détection. En revanche, TimePillars utilisant la méthode d'interpolation surpasse également le modèle de base, mais est inférieur à la méthode de convolution pour certains indicateurs. Les résultats de précision moyenne (mAP) montrent que TimePillars fonctionne bien dans la détection des catégories de véhicules, de cyclistes et de piétons, en particulier lorsqu'il s'agit de catégories plus difficiles telles que les cyclistes et les piétons, son amélioration des performances est plus significative. Du point de vue de la fréquence de traitement (f (Hz)), bien que les TimePillars ne soient pas aussi rapides que les PointPillars à image unique, ils sont plus rapides que les PointPillars à images multiples tout en conservant des performances de détection élevées. Cela montre que TimePillars peut effectuer efficacement une détection longue distance et une compensation de mouvement tout en maintenant un traitement en temps réel. En d’autres termes, le modèle TimePillars présente des avantages significatifs en matière de détection longue distance, de compensation de mouvement et de vitesse de traitement, en particulier lors du traitement de données multi-images et de l’utilisation d’une technologie de conversion de mouvement basée sur la convolution. Ces résultats mettent en évidence le potentiel d’application de TimePillars dans le domaine de la détection d’objets lidar 3D pour les véhicules autonomes.

Les résultats expérimentaux ci-dessus montrent que le modèle TimePillars fonctionne parfaitement en termes de performances de détection d'objets dans différentes plages de distance, en particulier par rapport au modèle de référence PointPillars. Ces résultats sont répartis en trois plages de détection principales : 0 à 50 mètres, 50 à 100 mètres et au-dessus de 100 mètres.
Tout d'abord, le score de détection NuScenes (NDS) et la précision moyenne (mAP) sont les indicateurs de performance globaux. TimePillars surpasse PointPillars sur les deux mesures, affichant des capacités de détection et une précision de positionnement globalement supérieures. Plus précisément, le NDS de TimePillars est de 0,723, ce qui est beaucoup plus élevé que le 0,657 de PointPillars en termes de mAP, TimePillars dépasse également de manière significative le 0,475 de PointPillars avec 0,570 ;
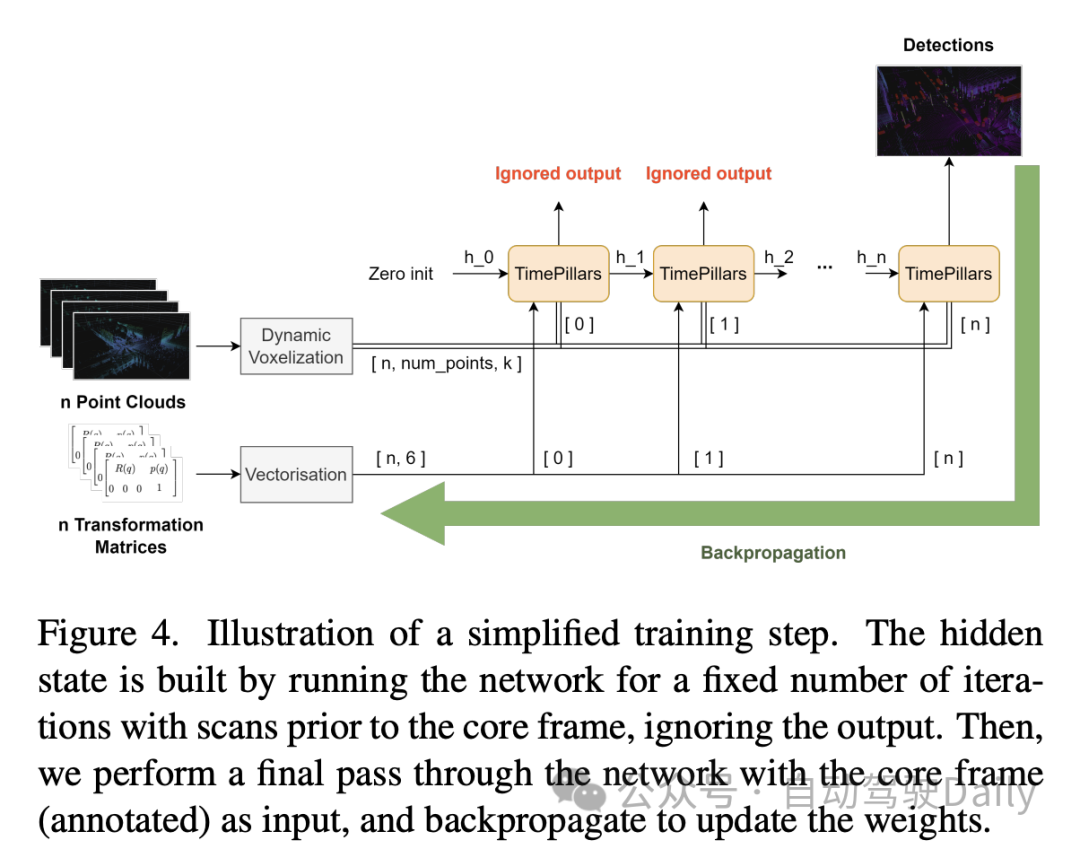
Dans la comparaison des performances dans différentes plages de distance, on peut voir que TimePillars est plus performant dans chaque plage. Pour la catégorie des véhicules, la précision de détection de TimePillars dans les plages de 0 à 50 mètres, de 50 à 100 mètres et de plus de 100 mètres est respectivement de 0,884, 0,776 et 0,591, qui sont toutes supérieures aux performances de PointPillars dans la même plage. Cela montre que TimePillars a une plus grande précision dans la détection des véhicules, à la fois à courte et à longue distance. TimePillars a également démontré de meilleures performances de détection lorsqu'il s'agit de véhicules vulnérables (tels que les motos, les fauteuils roulants, les scooters électriques, etc.). Surtout dans une portée de plus de 100 mètres, la précision de détection de TimePillars est de 0,178, tandis que PointPillars n'est que de 0,036, ce qui montre des avantages significatifs dans la détection longue distance. Pour la détection des piétons, TimePillars a également montré de meilleures performances, notamment dans la plage de 50 à 100 mètres, avec une précision de détection de 0,350, tandis que PointPillars n'était que de 0,211. Même à des distances plus longues (plus de 100 mètres), TimePillars atteint toujours un certain niveau de détection (précision de 0,032), tandis que PointPillars effectue zéro à cette distance.
Ces résultats expérimentaux mettent en évidence les performances supérieures de TimePillars dans la gestion des tâches de détection d'objets dans différentes plages de distance. Que ce soit à courte distance ou à longue distance, plus difficile, les TimePillars fournissent des résultats de détection plus précis et plus fiables, essentiels à la sécurité et à l'efficacité des véhicules autonomes.
5. Discussion

Tout d'abord, le principal avantage du modèle TimePillars est son efficacité pour la détection d'objets à longue distance. En adoptant la voxélisation dynamique et la structure convolutive GRU, le modèle est mieux à même de gérer des données lidar clairsemées, en particulier dans la détection d'objets longue distance. Ceci est essentiel pour l’exploitation sûre des véhicules autonomes dans des environnements routiers complexes et changeants. De plus, le modèle affiche également de bonnes performances en termes de vitesse de traitement, essentielle pour les applications temps réel. D'autre part, TimePillars adopte une méthode basée sur la convolution pour la compensation de mouvement, ce qui constitue une amélioration majeure par rapport aux méthodes traditionnelles. Cette approche garantit l'exactitude de la transformation grâce à des tâches auxiliaires lors de la formation, améliorant ainsi la précision du modèle lors de la manipulation d'objets en mouvement.
Cependant, la recherche de cet article présente également certaines limites. Premièrement, même si TimePillars gère bien la détection d'objets distants, cette augmentation des performances peut se faire au détriment d'une certaine vitesse de traitement. Bien que la vitesse du modèle soit toujours adaptée aux applications en temps réel, elle reste néanmoins inférieure à celle des méthodes à image unique. De plus, l’article se concentre principalement sur les données LiDAR et ne prend pas en compte d’autres entrées de capteurs, telles que les caméras ou les radars, ce qui peut limiter l’application du modèle dans des environnements multi-capteurs plus complexes.
C'est-à-dire que TimePillars a montré des avantages significatifs dans la détection d'objets lidar 3D pour les véhicules autonomes, notamment dans la détection longue distance et la compensation de mouvement. Malgré le léger compromis en termes de vitesse de traitement et les limites du traitement des données multi-capteurs, TimePillars représente toujours une avancée importante dans ce domaine.
6. Conclusion
Ce travail montre qu'il est préférable de considérer les données passées des capteurs plutôt que d'utiliser uniquement les informations actuelles. L’accès aux informations précédentes sur l’environnement de conduite peut faire face à la nature clairsemée des nuages de points lidar et conduire à des prédictions plus précises. Nous démontrons que les réseaux récurrents sont un moyen approprié pour atteindre ce dernier objectif. Donner de la mémoire au système conduit à une solution plus robuste par rapport aux méthodes d'agrégation de nuages de points qui créent des représentations de données plus denses grâce à un traitement approfondi. Notre méthode proposée, TimePillars, implémente un moyen de résoudre le problème récursif. En ajoutant simplement trois couches convolutives supplémentaires au processus d'inférence, nous démontrons que les éléments de base du réseau sont suffisants pour obtenir des résultats significatifs et garantir que les spécifications existantes en matière d'efficacité et d'intégration matérielle sont respectées. Au meilleur de nos connaissances, ce travail fournit les premiers résultats de référence pour la tâche de détection d'objets 3D sur le nouvel ensemble de données ouvert Zenseact. Nous espérons que notre travail pourra contribuer à des routes plus sûres et plus durables à l’avenir.

Lien original : https://mp.weixin.qq.com/s/94JQcvGXFWfjlDCT77gjlA
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Un article sur les systèmes décisionnels de conduite autonome
- Technologie de conduite autonome et pratique de système de transport intelligent implémentées en Java
- Problème de suivi multi-cibles dans la technologie de détection de cibles
- Tout diffuser ? 3DifFusionDet : le modèle de diffusion entre dans la détection de cibles 3D LV fusion !
- Tesla innove une fois de plus dans la technologie de conduite autonome : introduisant l'affichage de scènes 3D pour améliorer les fonctions d'aide au stationnement