
Maison >Périphériques technologiques >IA >Explorez les principes et les scénarios d'application de la reconnaissance OCR
Explorez les principes et les scénarios d'application de la reconnaissance OCR

- 王林avant
- 2024-01-14 22:36:051378parcourir

Labs Introduction
Dans la vie quotidienne, l'extraction de captures d'écran et les questions de recherche de photos sont largement utilisées dans la technologie OCR (Optical Character Recognition), qui est une technologie très importante dans le domaine de la reconnaissance de texte
Partie 01, Qu'est-ce que l'OCR
OCR (Optical Character Recognition) est une méthode de reconnaissance de texte informatique qui utilise la technologie optique et informatique pour convertir des images de texte imprimées ou manuscrites en un format de texte précis et lisible, pour ordinateur reconnaissance et candidature. La technologie de reconnaissance OCR est de plus en plus largement utilisée dans diverses industries de la vie moderne. C'est la technologie clé pour saisir rapidement du contenu textuel dans l'ordinateur
Partie 02, Principe de la technologie OCR
Principaux points de. Technologie OCR Il existe deux écoles d'OCR traditionnelle et d'OCR d'apprentissage profond.
Au début du développement de la technologie OCR, les techniciens utilisaient des technologies de traitement d'image telles que la binarisation, l'analyse de domaine connecté et l'analyse de projection, combinées à l'apprentissage automatique statistique (comme Adaboost et SVM) pour extraire le contenu du texte de l'image, ce qui nous l'avons unifié. Il est classé comme OCR traditionnel. Sa principale caractéristique est qu'il s'appuie sur des opérations complexes de prétraitement des données pour corriger et réduire le bruit sur l'image. L'importance de l'adaptabilité aux scènes complexes ne peut être ignorée. L'adaptabilité est une capacité essentielle dans un environnement changeant. Une personne dotée d’une bonne capacité d’adaptation peut s’adapter à de nouvelles situations et exigences, s’adapter rapidement aux changements et trouver des solutions aux problèmes. L'adaptabilité est également l'un des facteurs clés de réussite dans la vie personnelle et professionnelle. Par conséquent, nous devons nous efforcer de cultiver et d’améliorer notre capacité d’adaptation pour faire face à un monde en évolution avec une précision et une rapidité de réponse médiocres.
Grâce au développement continu de la technologie de l'IA, la technologie OCR basée sur l'apprentissage profond de bout en bout a progressivement mûri. L'avantage de cette méthode est qu'elle n'a pas besoin d'introduire explicitement le lien de coupe de texte dans l'image avant. -étape de traitement, mais convertit la reconnaissance de texte en apprentissage de séquence Problème, l'intégration de la segmentation de texte dans l'apprentissage en profondeur est d'une grande importance pour l'amélioration de la technologie OCR et l'orientation future du développement.
2.1 Processus de reconnaissance OCR traditionnel
L'organigramme de traitement de la technologie OCR traditionnelle est le suivant :

: Après l'appareil , il entre dans la phase de prétraitement. Puisqu'il existe des facteurs interférents dans divers supports de texte, tels que la douceur et la qualité d'impression du papier, la lumière et l'obscurité de l'écran, etc., qui provoqueront une distorsion du texte, il est nécessaire d'effectuer méthodes de prétraitement telles que le réglage de la luminosité, l'amélioration de l'image et le filtrage du bruit sur l'image.
Positionnement de zone de texte: Pour le positionnement et l'extraction de zones de texte, les méthodes incluent principalement la détection de domaine connecté et la détection MSER.
Correction du texte et de l'image: Correction du texte incliné pour garantir l'horizontalité. Les méthodes de correction incluent principalement la correction horizontale et la correction de perspective.
Segmentation d'un seul mot en lignes et colonnes: La reconnaissance de texte traditionnelle est basée sur la reconnaissance d'un seul caractère, et la méthode de segmentation utilise principalement les contours de domaines connectés et la découpe par projection verticale.
Reconnaissance de caractères de classificateur: utilisez des algorithmes d'extraction de caractéristiques tels que HOG et Sift pour extraire les informations vectorielles des caractères, et utilisez les algorithmes SVM, la régression logistique, les machines vectorielles de support, etc. pour la formation.
Post-traitement: Étant donné que la classification du classificateur n'est pas nécessairement complètement correcte, ou qu'il y a des erreurs dans le processus de découpe des caractères, elle doit être basée sur des modèles de langage statistiques (tels que les chaînes de Markov cachées, HMM) ou des règles d'extraction artificielles Concevez un modèle de règles de langage pour effectuer une correction d'erreur sémantique sur les résultats de texte. 2.2 OCR d'apprentissage profond
Images
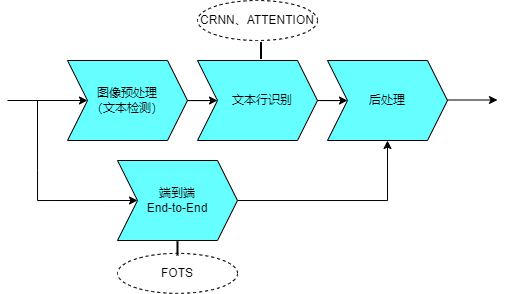 L'algorithme OCR d'apprentissage profond grand public actuel modélise séparément les deux étapes de la détection et de la reconnaissance de texte.
L'algorithme OCR d'apprentissage profond grand public actuel modélise séparément les deux étapes de la détection et de la reconnaissance de texte.
La détection de texte peut être divisée en méthodes basées sur la régression et sur la segmentation. Les méthodes de régression incluent des algorithmes tels que CTPN, Textbox et EAST, qui peuvent détecter le texte directionnel dans les images, mais seront affectés par les irrégularités dans la zone de texte. Les méthodes de segmentation telles que l'algorithme PSENet peuvent gérer du texte de différentes formes et tailles, mais un texte plus proche est sujet à des problèmes de collage. Différentes méthodes ont leurs propres avantages et inconvénients
L'étape de reconnaissance de texte utilise principalement deux technologies majeures, CRNN et ATTENTION, pour transformer la reconnaissance de texte en un problème d'apprentissage de séquence. Les deux technologies utilisent le réseau CNN+RNN dans leur étape d'apprentissage des fonctionnalités. Structure, la différence réside dans la couche de sortie finale (couche de traduction), c'est-à-dire comment convertir les informations sur les caractéristiques de séquence apprises par le réseau en résultat de reconnaissance final.
De plus, il existe un dernier algorithme de bout en bout qui intègre directement la détection et la reconnaissance de texte dans un modèle de réseau unique pour l'apprentissage. Par exemple, des algorithmes tels que FOTS et Mask TextSpotter. Comparé aux méthodes indépendantes de détection et de reconnaissance de texte, cet algorithme a une vitesse de reconnaissance plus rapide mais une précision relative plus faible.
Technologie de reconnaissance par apprentissage profond par intelligence artificielle
|
La stabilité globale à plusieurs étapes est médiocre | Après une optimisation de bout en bout, la stabilité du système a été considérablement améliorée |
|
Reconnaissance Précision |
Les scénarios traditionnels avec de petits échantillons ont une faible précision. avantages |
La précision est plus élevée plus le degré de fusion est profond, la précision diminue progressivement |
Reconnaissance |
Vitesse |
Reconnaissance. est plus lent |
|
Scénario L'importance de l'adaptabilité ne peut être ignorée. L'adaptabilité est une capacité essentielle dans un environnement changeant. Une personne dotée d'une bonne capacité d'adaptation peut s'adapter à de nouvelles situations et exigences, s'adapter rapidement aux changements et trouver des solutions aux problèmes. L'adaptabilité est également l'un des facteurs clés de réussite dans la vie personnelle et professionnelle. Par conséquent, nous devons nous efforcer de cultiver et d'améliorer notre adaptabilité pour faire face à un monde en constante évolution |
faible, adapté aux formats d'impression standard |
fort, compatible avec des scénarios complexes, dépendant de la formation du modèle |
Anti-interférence |
Faibles exigences plus élevées pour les images d'entrée |
Forte, dépendante de la formation du modèle |
Partie 03, OCR commune indicateurs d'évaluation
Taux de rappel : fait référence au rapport entre le nombre de caractères correctement reconnus par le système OCR et le nombre réel de caractères. Il est utilisé pour mesurer si le système a manqué la reconnaissance de certains caractères. Plus la valeur est élevée, meilleure est la capacité du système à couvrir les caractères.
Taux de précision : fait référence au rapport entre le nombre de caractères correctement reconnus par le système OCR et le nombre total de caractères reconnus par le système. Il est utilisé pour mesurer combien de résultats de reconnaissance du système sont vraiment corrects. Plus la valeur est élevée, meilleurs sont les résultats de la reconnaissance.
Valeur F1 : Un indicateur d'évaluation qui combine rappel et précision. La valeur F1 est comprise entre 0 et 1. Plus la valeur est élevée, meilleur est l'équilibre entre précision et rappel atteint par le système.
Average Edit Distance (Average Edit Distance) est un indicateur utilisé pour évaluer le degré de différence entre les résultats de la reconnaissance OCR et le texte réel
Partie 04, Application et Outlook
OCR sous forme de texte reconnaissance L'une des principales branches du domaine, il existe encore un large espace de recherche et de développement à l'avenir. En termes de précision de la reconnaissance, il est toujours urgent d'étudier une technologie de traitement d'image plus intelligente et des modèles d'apprentissage profond plus puissants ; cela nécessite que la reconnaissance soit plus universelle en couvrant plusieurs langues et polices, et améliore la capacité d'adaptation à des scènes complexes ; en reconnaissance en temps réel D'autre part, nous recherchons davantage de points d'application combinés avec la technologie de réalité virtuelle et la technologie de réalité augmentée, tels que la traduction AR, la correction automatique des erreurs et la correction des données texte, etc.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment installer et configurer tesseract-ocr 4.00 sous Windows ?
- Quelle est la fonction du logiciel ocr
- La compréhension du langage naturel est un domaine d'application important de l'intelligence artificielle. Quel est son objectif ?
- Comment utiliser PHP pour la reconnaissance OCR et la reconnaissance de texte ?
- Utilisez la technologie OCR pour identifier automatiquement divers codes de vérification, et l'outil est open source