
Maison >Périphériques technologiques >IA >Les modèles petits mais puissants ont le vent en poupe : TinyLlama et LiteLlama deviennent des choix populaires
Les modèles petits mais puissants ont le vent en poupe : TinyLlama et LiteLlama deviennent des choix populaires

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-14 12:27:151489parcourir
Actuellement, les chercheurs commencent à s'intéresser aux petits modèles petits et performants, même si tout le monde étudie les grands modèles avec des échelles de paramètres atteignant des dizaines de milliards, voire des centaines de milliards.
Les petits modèles sont largement utilisés dans les appareils de pointe, tels que les smartphones, les appareils IoT et les systèmes embarqués. Ces appareils disposent souvent d’une puissance de calcul et d’un espace de stockage limités et ne peuvent pas exécuter efficacement de grands modèles de langage. L’étude de petits modèles devient donc particulièrement importante.
Les deux études que nous allons présenter ensuite pourront répondre à vos besoins en petits modèles.
TinyLlama-1.1B
Des chercheurs de l'Université de technologie et de design de Singapour (SUTD) ont récemment publié TinyLlama, un modèle de langage avec 1,1 milliard de paramètres pré-entraînés sur environ 3 000 milliards de jetons.

- Adresse papier : https://arxiv.org/pdf/2401.02385.pdf
- Adresse du projet : https://github.com/jzhang38/TinyLlama/blob/main/ README_zh-CN.md
TinyLlama est basé sur l'architecture et le tokenizer de Llama 2, ce qui facilite son intégration à de nombreux projets open source utilisant Llama. De plus, TinyLlama ne possède que 1,1 milliard de paramètres et est de petite taille, ce qui le rend idéal pour les applications nécessitant des calculs et une empreinte mémoire limités.
L'étude montre que seuls 16 GPU A100-40G peuvent compléter la formation de TinyLlama en 90 jours.

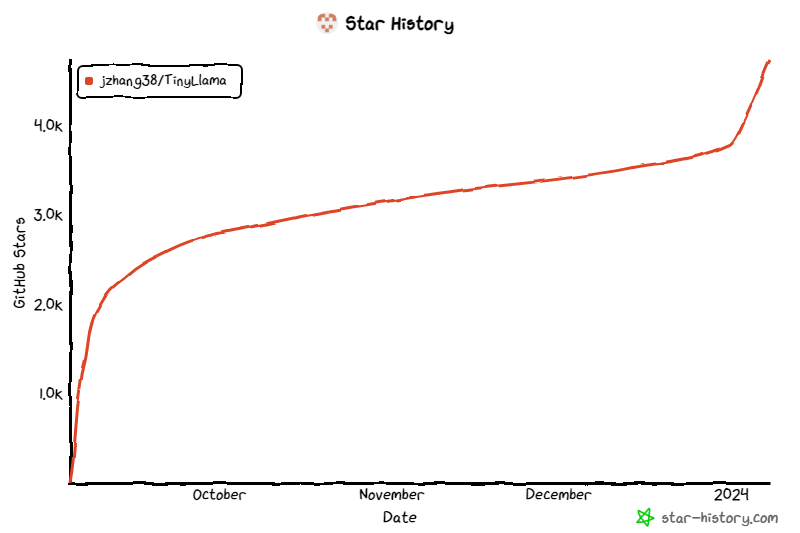
Le projet a continué de retenir l'attention depuis son lancement, et le nombre actuel d'étoiles a atteint 4,7K. Les détails de l'architecture du modèle TinyLlama sont les suivants : le mien utilise des plus gros données Potentiel de formation de modèles plus petits. Ils se sont concentrés sur l’exploration du comportement de modèles plus petits lorsqu’ils sont formés avec un nombre de jetons beaucoup plus important que celui recommandé par la loi de mise à l’échelle.
 Plus précisément, l'étude a utilisé environ 3 000 milliards de jetons pour former un modèle Transformer (décodeur uniquement) avec 1,1 milliard de paramètres. À notre connaissance, il s'agit de la première tentative d'utiliser une si grande quantité de données pour former un modèle avec des paramètres 1B.
Plus précisément, l'étude a utilisé environ 3 000 milliards de jetons pour former un modèle Transformer (décodeur uniquement) avec 1,1 milliard de paramètres. À notre connaissance, il s'agit de la première tentative d'utiliser une si grande quantité de données pour former un modèle avec des paramètres 1B.
Malgré sa taille relativement petite, TinyLlama fonctionne assez bien sur une gamme de tâches en aval, surpassant largement les modèles de langage open source existants de même taille. Plus précisément, TinyLlama surpasse OPT-1.3B et Pythia1.4B sur diverses tâches en aval.

Avec la prise en charge de ces technologies, le débit de formation TinyLlama atteint 24 000 jetons par seconde par GPU A100-40G. Par exemple, le modèle TinyLlama-1.1B ne nécessite que 3 456 heures GPU A100 pour les jetons 300B, contre 4 830 heures pour Pythia et 7 920 heures pour MPT. Cela montre l'efficacité de l'optimisation de cette étude et le potentiel d'économiser beaucoup de temps et de ressources dans la formation de modèles à grande échelle.
 TinyLlama atteint une vitesse d'entraînement de 24 000 jetons/seconde/A100. Cette vitesse est équivalente à un modèle optimal pour chinchilla avec 1,1 milliard de paramètres et 22 milliards de jetons que les utilisateurs peuvent entraîner en 32 heures sur 8 A100. Dans le même temps, ces optimisations réduisent également considérablement l'utilisation de la mémoire. Les utilisateurs peuvent intégrer un modèle de 1,1 milliard de paramètres dans un GPU de 40 Go tout en conservant une taille de lot par GPU de 16 000 jetons. Modifiez simplement la taille du lot un peu plus petite et vous pourrez entraîner TinyLlama sur RTX 3090/4090.
TinyLlama atteint une vitesse d'entraînement de 24 000 jetons/seconde/A100. Cette vitesse est équivalente à un modèle optimal pour chinchilla avec 1,1 milliard de paramètres et 22 milliards de jetons que les utilisateurs peuvent entraîner en 32 heures sur 8 A100. Dans le même temps, ces optimisations réduisent également considérablement l'utilisation de la mémoire. Les utilisateurs peuvent intégrer un modèle de 1,1 milliard de paramètres dans un GPU de 40 Go tout en conservant une taille de lot par GPU de 16 000 jetons. Modifiez simplement la taille du lot un peu plus petite et vous pourrez entraîner TinyLlama sur RTX 3090/4090.
Dans l'expérience, cette recherche s'est principalement concentrée sur des modèles de langage avec une architecture de décodeur pure, contenant environ 1 milliard de paramètres. Plus précisément, l’étude a comparé TinyLlama à OPT-1.3B, Pythia-1.0B et Pythia-1.4B.
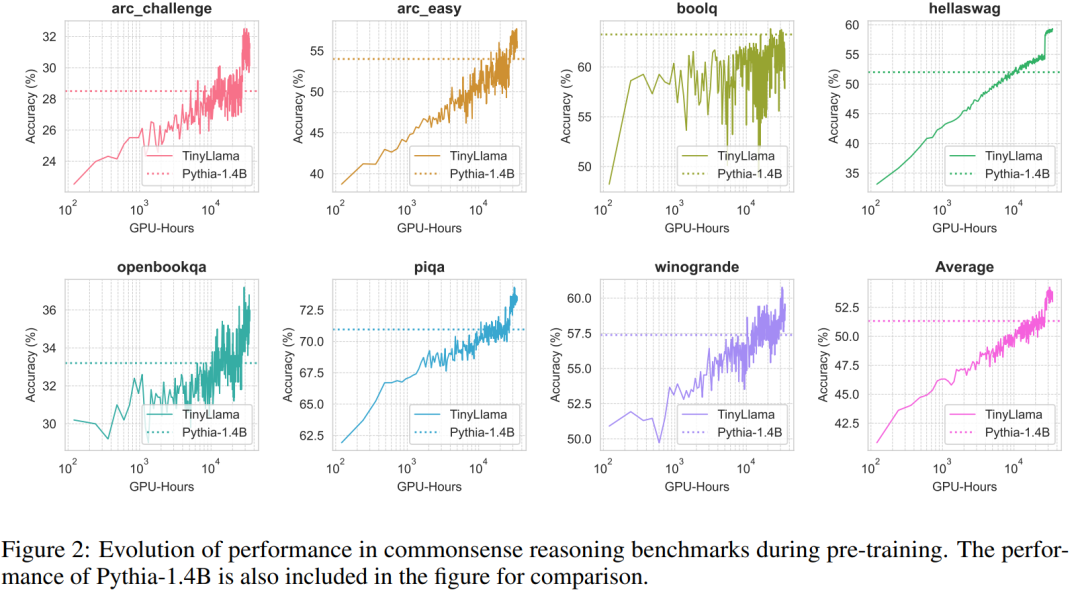
Les performances de TinyLlama sur les tâches de raisonnement de bon sens sont présentées ci-dessous. On peut voir que TinyLlama surpasse la ligne de base sur de nombreuses tâches et obtient le score moyen le plus élevé.

De plus, les chercheurs ont suivi la précision de TinyLlama sur des tests de raisonnement de bon sens pendant la pré-formation. Comme le montre la figure 2, les performances de TinyLlama s'améliorent avec l'augmentation des ressources informatiques, dans la plupart des tests dépassent les limites. précision de Pythia-1.4B.
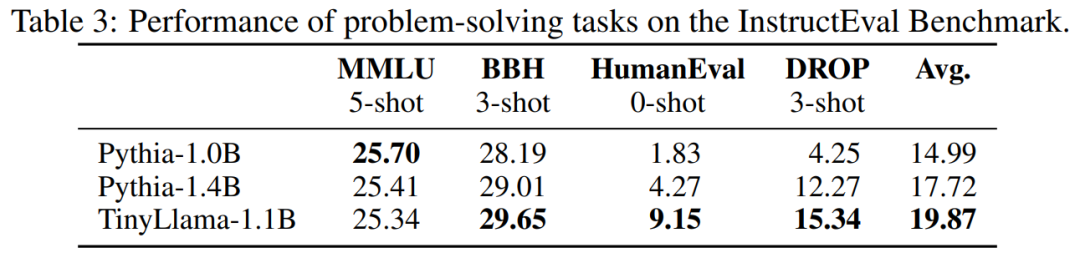
Le tableau 3 montre que TinyLlama présente de meilleures capacités de résolution de problèmes par rapport aux modèles existants.
Les internautes aux mains rapides ont déjà commencé à se lancer : l'effet de course est étonnamment bon, fonctionnant sur GTX3060, il peut fonctionner à une vitesse de 136 tok/seconde.
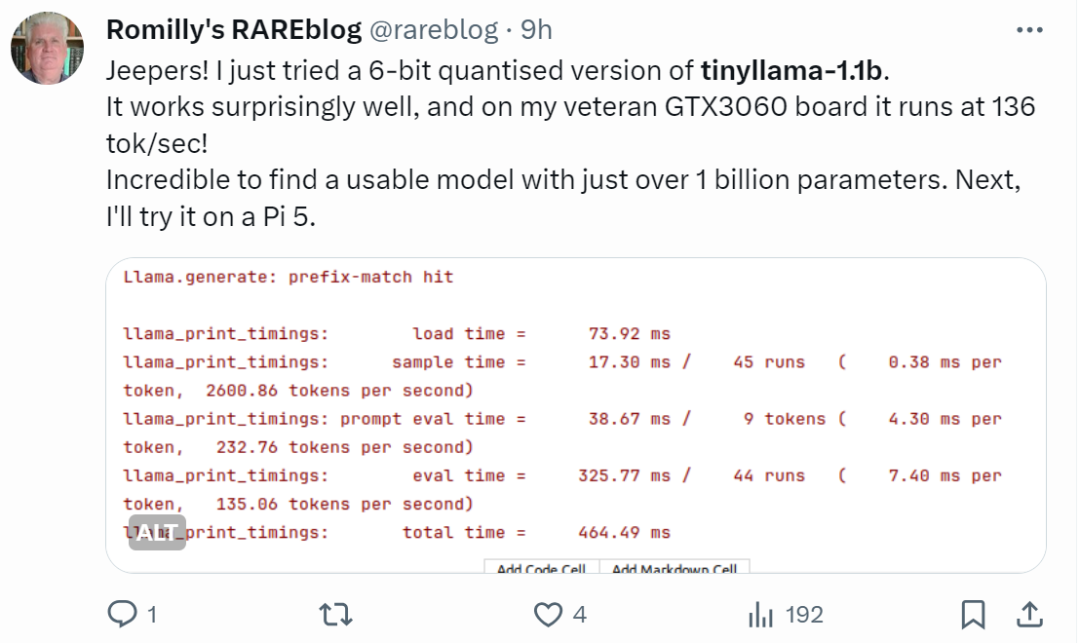
"C'est vraiment rapide!"
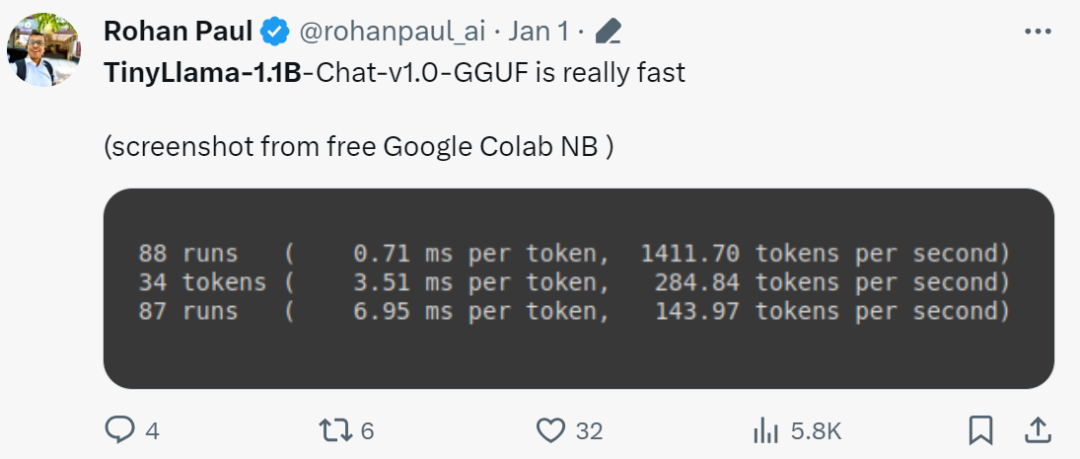
Small Modèle Litellama
due à la sortie de TinyLlama, SLM (modèle de petit langage) a commencé à attirer une attention généralisée. Xiaotian Han de Texas Tech et A&M University a publié SLM-LiteLlama. Il dispose de 460 millions de paramètres et est entraîné avec des jetons 1T. Il s’agit d’un fork open source de LLaMa 2 de Meta AI, mais avec une taille de modèle nettement plus petite.
Adresse du projet : https://huggingface.co/ahxt/LiteLlama-460M-1T
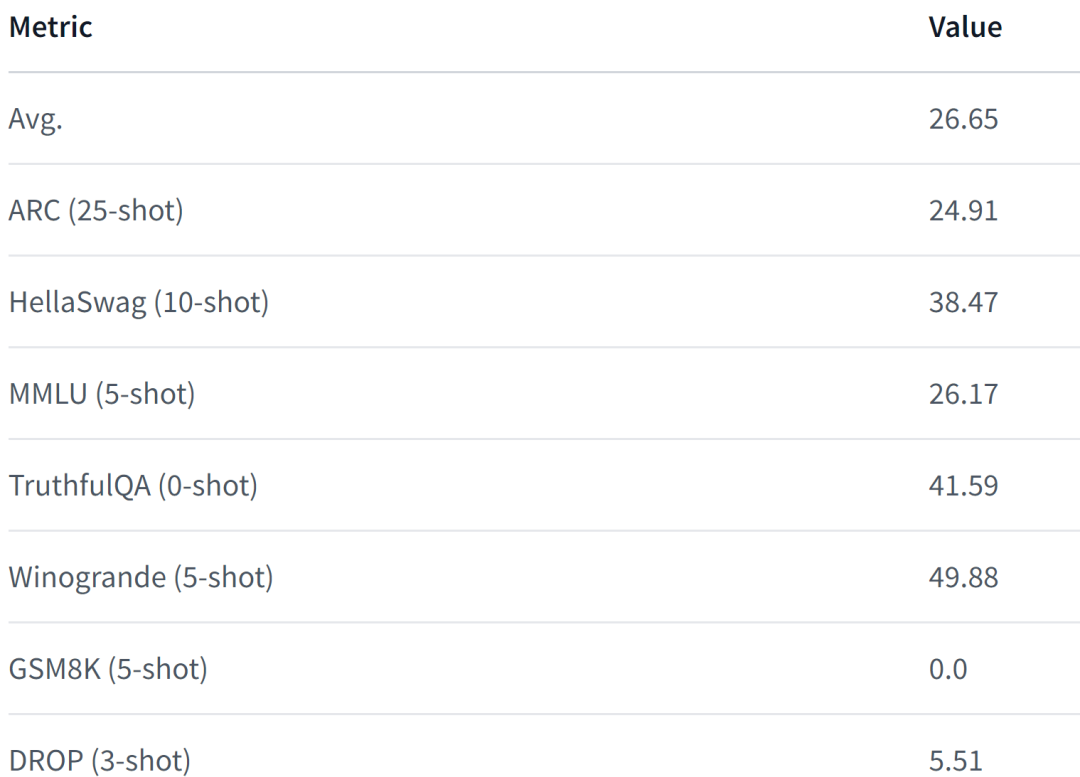
LiteLlama-460M-1T est formé sur l'ensemble de données RedPajama et utilise GPT2Tokenizer pour tokeniser le texte. L'auteur a évalué le modèle sur la tâche MMLU et les résultats sont présentés dans la figure ci-dessous. Même avec un nombre de paramètres considérablement réduit, le LiteLlama-460M-1T peut toujours obtenir des résultats comparables ou meilleurs que d'autres modèles.
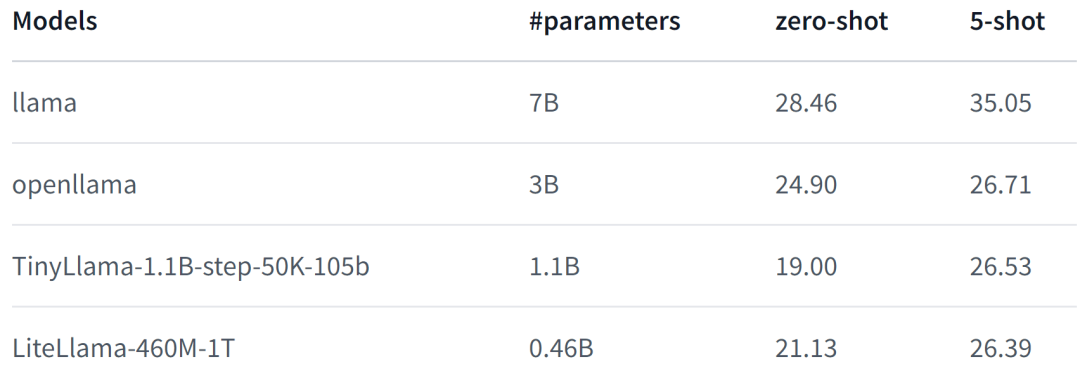
Voici les performances du modèle. Pour plus de détails, veuillez vous référer à :
https://www.php.cn/link/05ec1d748d9e3bbc975a057f7cd02fb6
. 
Face à l'échelle, LiteLlama a été considérablement réduit et certains internautes sont curieux de savoir s'il peut fonctionner avec 4 Go de mémoire. Si vous aussi vous voulez savoir, pourquoi ne pas essayer vous-même.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce que le service sysmain ?
- Qu'est-ce que le modèle de données utilisant la structure arborescente ?
- Quel est le modèle de couleur utilisé par les écrans d'ordinateur ?
- À quelle couche du modèle osi la fonction de sélection de chemin est-elle terminée ?
- Comment copier un modèle dans un autre fichier dans 3dmax