
Maison >Périphériques technologiques >IA >Exploration et application de la technologie de tri Baidu
Exploration et application de la technologie de tri Baidu

- 王林avant
- 2024-01-14 08:33:111410parcourir
1. Contexte
Tout d'abord, présentons le contexte commercial, le contexte des données et la stratégie algorithmique de base de la recommandation complète de flux d'informations de Baidu.
1. Recommandation complète du flux d'informations de Baidu

Le flux d'informations complet de Baidu comprend la page de liste du champ de recherche dans l'application Baidu et la forme de la page immersive, couvrant une variété de types de produits. Comme vous pouvez le voir sur l'image ci-dessus, les formats de contenu recommandés incluent des recommandations immersives similaires à celles de Douyin, ainsi que des recommandations à une et deux colonnes, similaires à la mise en page de Xiaohongshu Notes. Il existe également de nombreuses façons pour les utilisateurs d'interagir avec le contenu. Ils peuvent commenter, aimer et collecter du contenu sur la page de destination. Ils peuvent également accéder à la page de l'auteur pour afficher des informations pertinentes et interagir. La conception de l'ensemble du flux d'informations complet est très riche et diversifiée et peut répondre aux différents besoins et méthodes d'interaction des utilisateurs.
2. Contexte des données
Du point de vue de la modélisation, il existe trois défis principaux :
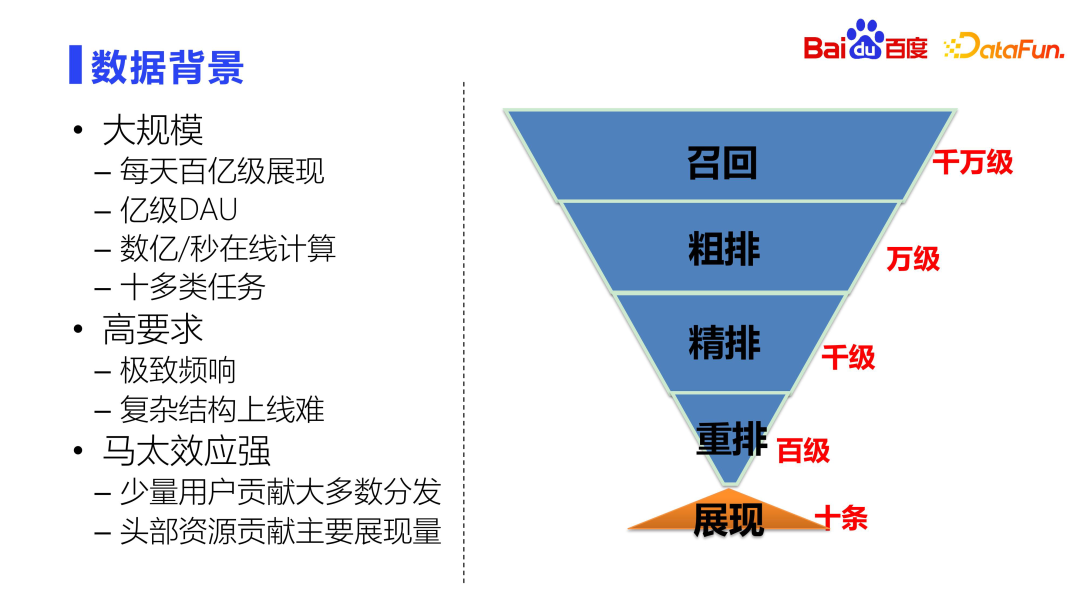
- Forte demande. Le temps de réponse requis de l'ensemble du système est très élevé. Les calculs de bout en bout sont en millisecondes. Si le temps prédéterminé est dépassé, un échec sera renvoyé. Cela crée également un autre problème, à savoir la difficulté de mettre en ligne des structures complexes.
- L'effet Matthew est fort. Du point de vue des échantillons de données, l'effet Matthew est très fort. Un petit nombre d'utilisateurs actifs les plus importants contribuent à la majeure partie du volume de distribution, et les ressources les plus populaires couvrent également la majeure partie du volume d'affichage. Que ce soit du côté des utilisateurs ou du côté des ressources, l’effet Matthew est très fort. Par conséquent, l’effet Matthew doit être atténué lors de la conception du système afin de rendre les recommandations plus équitables.
- 3. Stratégie d'algorithme de base Dans les scénarios de recherche de promotion dans l'ensemble du secteur, la conception des fonctionnalités utilise généralement une approche discrétisée pour garantir à la fois les effets de mémoire et de généralisation. Les fonctionnalités sont converties en codes uniques par hachage pour la discrétisation. Pour les utilisateurs principaux, une caractérisation fine est nécessaire pour obtenir une mémoire précise. Pour les utilisateurs rares à longue traîne qui représentent une proportion plus importante, un bon traitement de généralisation est nécessaire. De plus, la session joue un rôle très important dans la séquence de décision de clic et de consommation de l'utilisateur.
La conception du modèle doit équilibrer la distribution des données de la tête et de la longue queue pour garantir la précision et la capacité de généralisation. La conception des fonctionnalités en tient déjà compte, la conception du modèle doit donc également prendre en compte à la fois la généralisation et la précision. L'entonnoir de recommandation Baidu a des exigences de performances très strictes, il nécessite donc une conception conjointe de l'architecture et de la stratégie pour trouver un équilibre entre performances et effet. De plus, il est nécessaire d’équilibrer le débit élevé et la précision du modèle.
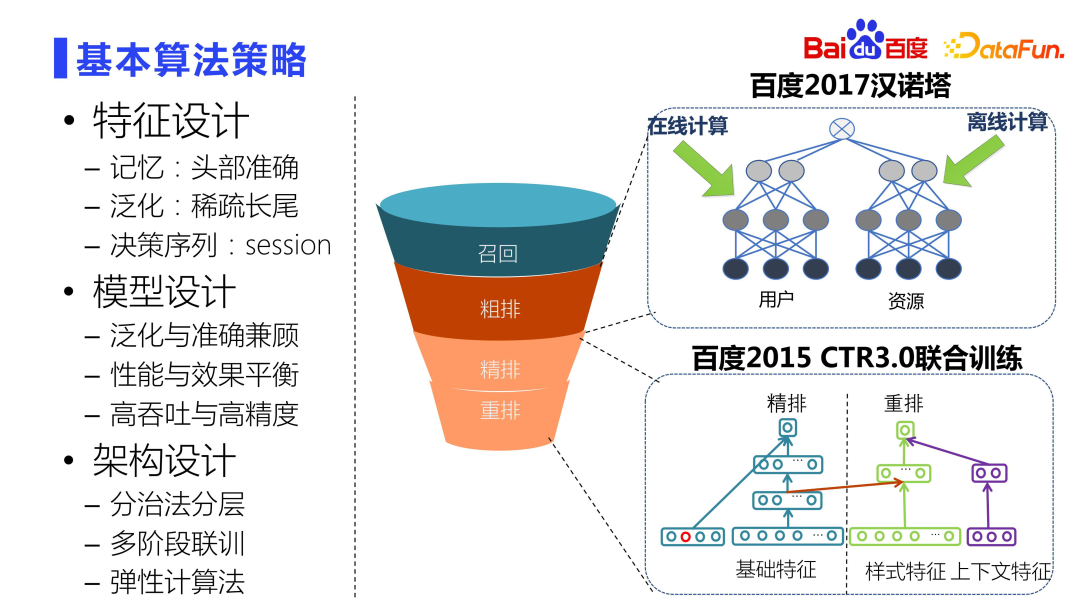 La conception de l'architecture doit être considérée de manière globale sous deux dimensions : la performance et l'effet. Un modèle ne peut pas gérer des dizaines de millions de bibliothèques de ressources, il doit donc être conçu en couches. L'idée centrale est la méthode diviser pour mieux régner. Il existe une corrélation entre chaque couche, un entraînement conjoint en plusieurs étapes est donc nécessaire pour améliorer l'efficacité entre les entonnoirs à plusieurs étapes. De plus, des méthodes de calcul élastiques doivent être adoptées pour pouvoir déployer des modèles complexes alors que les ressources restent quasiment inchangées.
La conception de l'architecture doit être considérée de manière globale sous deux dimensions : la performance et l'effet. Un modèle ne peut pas gérer des dizaines de millions de bibliothèques de ressources, il doit donc être conçu en couches. L'idée centrale est la méthode diviser pour mieux régner. Il existe une corrélation entre chaque couche, un entraînement conjoint en plusieurs étapes est donc nécessaire pour améliorer l'efficacité entre les entonnoirs à plusieurs étapes. De plus, des méthodes de calcul élastiques doivent être adoptées pour pouvoir déployer des modèles complexes alors que les ressources restent quasiment inchangées.
Le projet Tour de Hanoï à droite dans l'image ci-dessus implémente très intelligemment la modélisation de la séparation des utilisateurs et des ressources au niveau de l'aménagement approximatif. Il existe également une formation conjointe CTR3.0, qui réalise une formation conjointe à plusieurs niveaux et à plusieurs étapes. Par exemple, le classement fin est le modèle le plus complexe et le plus exquis de l'ensemble du système. La précision est assez élevée. La modélisation, le classement fin et le réarrangement de Wise sont étroitement liés. La méthode de formation conjointe que nous avons proposée sur la base de ces deux modèles a obtenu de très bons résultats en ligne.
Ensuite, nous le présenterons plus en détail sous les trois angles des fonctionnalités, des algorithmes et de l'architecture.
2. Caractéristiques
1. Processus de prise de décision d'interaction utilisateur-système
Les caractéristiques décrivent le processus de prise de décision d'interaction entre l'utilisateur et le système.
La figure suivante montre le diagramme matriciel d'interaction de relation spatio-temporelle utilisateur-ressource-scénario-état.
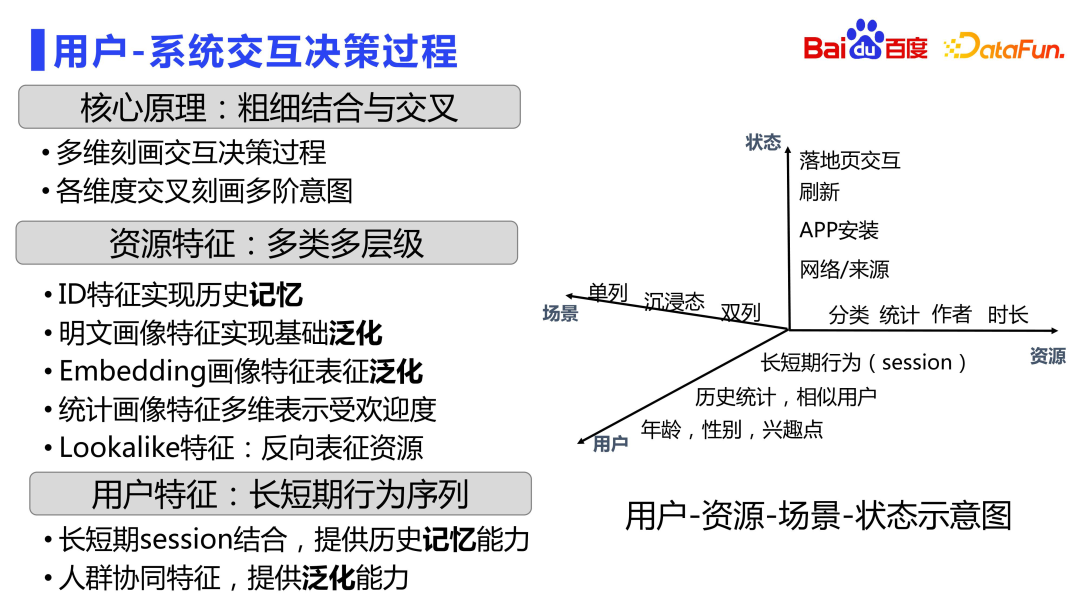
Divisez d'abord tous les signaux en quatre dimensions d'utilisateurs, de ressources, de scénarios et d'états, car nous voulons essentiellement modéliser la relation entre les utilisateurs et les ressources. Dans chaque dimension, diverses données de portrait peuvent être produites.
Du point de vue de l'utilisateur, les portraits les plus élémentaires de l'âge, du sexe et des points d'intérêt. Sur cette base, il y aura également des fonctionnalités plus fines, telles que les utilisateurs similaires et les comportements de préférences historiques des utilisateurs pour différents types de ressources. Les caractéristiques des sessions sont principalement des séquences comportementales à long et à court terme. Il existe de nombreux modèles de séquences dans l’industrie, je n’entrerai donc pas dans les détails ici. Mais quel que soit le type de modèle de séquence que vous créez, des fonctionnalités de session discrètes au niveau des fonctionnalités sont indispensables. Dans la publicité de recherche de Baidu, ce type de fonctionnalité de séquence à granularité fine a été introduit il y a plus de 10 ans, qui décrit soigneusement le comportement de clic, le comportement de consommation, etc. de l'utilisateur sur différents types de ressources dans différentes fenêtres temporelles.
Dans la dimension ressource, il y aura également des fonctionnalités de type ID pour enregistrer l'état de la ressource elle-même, qui est dominée par la mémoire. Il existe également des fonctionnalités de portrait en texte brut pour obtenir des capacités de généralisation de base. En plus des fonctionnalités à gros grain, il y aura également des fonctionnalités de ressources plus détaillées, telles que l'intégration de fonctionnalités de portrait, qui sont produites sur la base de modèles pré-entraînés tels que la multimodalité et une modélisation plus détaillée de la relation entre les ressources dans l'intégration discrète. espace. Il existe également des caractéristiques de portrait statistique qui décrivent la performance a posteriori des ressources dans diverses circonstances. En plus des fonctionnalités similaires, les utilisateurs peuvent caractériser les ressources de manière inverse pour améliorer la précision.
En termes de dimensions de scène, il existe différentes caractéristiques de scène telles que des colonnes simples, immersives et doubles.
Les utilisateurs consomment les informations du flux différemment selon les états. Par exemple, le statut d'actualisation, le type de réseau d'où il provient et le formulaire d'interaction sur la page de destination affecteront la prise de décision future de l'utilisateur, de sorte que les caractéristiques seront également décrites à partir de la dimension de statut.
Décrit de manière complète le processus de prise de décision de l'interaction utilisateur-système à travers les quatre dimensions de l'utilisateur, de la ressource, du statut et du scénario. Dans de nombreux cas, des combinaisons entre plusieurs dimensions sont également réalisées.
2. Principe de conception de fonctionnalités discrètes
Ensuite, nous présenterons le principe de conception de fonctionnalités discrètes.
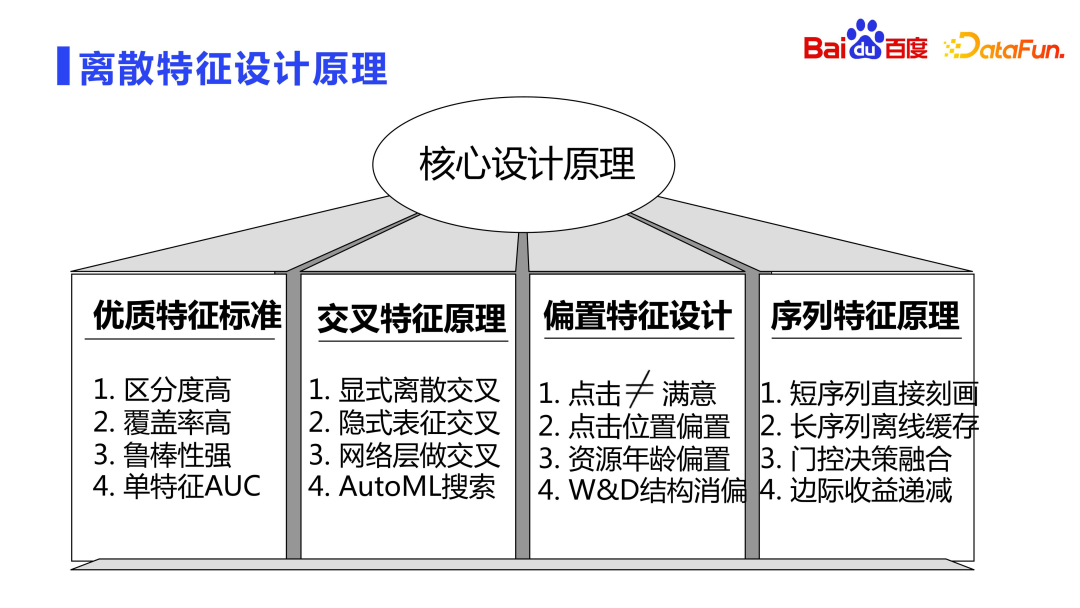
Les fonctionnalités de haute qualité ont généralement trois caractéristiques : une discrimination élevée, une couverture élevée et une forte robustesse.
- Haute discrimination : Après avoir ajouté des fonctionnalités, le postérieur est très différent. Par exemple, pour un échantillon qui ajoute la fonctionnalité a, l'écart entre le taux de clics postérieur et le taux de clics postérieur qui n'atteint pas la fonctionnalité a est très grand.
- Couverture élevée : Si la couverture des fonctionnalités ajoutées dans l'ensemble de l'échantillon n'est que de quelques dix millièmes ou cent millièmes, alors même si les fonctionnalités sont très distinguables, il y a une forte probabilité qu'elles n'aient pas effet.
- Forte robustesse : la répartition des fonctionnalités elles-mêmes doit être relativement stable et ne peut pas évoluer de manière très drastique dans le temps.
En plus des trois critères ci-dessus, un jugement de l'AUC d'une seule caractéristique peut également être effectué. Par exemple, utilisez uniquement une certaine fonctionnalité pour entraîner le modèle et voir la relation entre la fonctionnalité et la cible. Vous pouvez également supprimer une certaine fonctionnalité et voir la modification de l'AUC après avoir manqué la fonctionnalité.
Sur la base des principes de conception ci-dessus, nous nous concentrerons sur trois types de fonctionnalités importantes : les fonctionnalités de croisement, de biais et de séquence.
- En termes de fonctionnalités croisées, il existe des centaines de travaux connexes dans l'industrie. En pratique, il s'avère qu'aucun type de croisement de fonctionnalités implicites ne peut remplacer complètement le croisement de fonctionnalités explicites. supprimez toutes les fonctionnalités croisées et utilisez uniquement la représentation implicite pour le faire. L'intersection explicite de fonctionnalités peut décrire des informations pertinentes que l'intersection implicite de fonctionnalités ne peut pas exprimer. Bien sûr, si vous allez plus loin, vous pouvez utiliser AutoML pour rechercher automatiquement l'espace de combinaison de fonctionnalités possible. Par conséquent, en pratique, le croisement entre fonctionnalités se fait principalement par un croisement de fonctionnalités explicite et complété par un croisement de fonctionnalités implicite.
-
La fonctionnalité de biais signifie que les clics des utilisateurs ne sont pas synonymes de satisfaction des utilisateurs, car il existe divers biais dans l'affichage des ressources. Par exemple, le plus courant est le biais de position. Les ressources affichées dans l'en-tête sont naturellement biaisées. . Plus susceptible d'être cliqué. Il existe également un biais du système : le système donne la priorité à montrer ce qu'il pense être le meilleur, mais ce n'est pas nécessairement le meilleur. Par exemple, les ressources nouvellement publiées peuvent être désavantagées en raison du manque d'informations postérieures.
Il existe une structure très classique pour les fonctionnalités biaisées, qui est la structure Wide&Deep proposée par Google. Diverses fonctionnalités biaisées sont généralement placées du côté Wide, qui peuvent être recadrées directement en ligne grâce à cette méthode de tri par ordre partiel pour y parvenir. estimation impartiale. - La dernière est la fonctionnalité de séquence, qui est un type très important de fonctionnalité personnalisée par l'utilisateur. La tendance actuelle dans l'industrie consiste à modéliser de très longues séquences. Dans des expériences spécifiques, on constatera que la surcharge de stockage des longues séquences est généralement très importante. Comme mentionné dans l’article précédent, nous devons parvenir à un compromis entre performance et effet. Les séquences longues peuvent être précalculées hors ligne et les séquences courtes peuvent être calculées en ligne et en temps réel. Nous combinons donc souvent les deux méthodes. Le réseau de contrôle est utilisé pour décider si l'utilisateur préfère actuellement des séquences courtes ou des séquences longues pour équilibrer les intérêts à long terme et les intérêts à court terme. Dans le même temps, il convient de noter qu’à mesure que la séquence s’allonge, ses rendements marginaux diminuent.
3. Système de fonctionnalités optimisé de l'entonnoir de recommandation
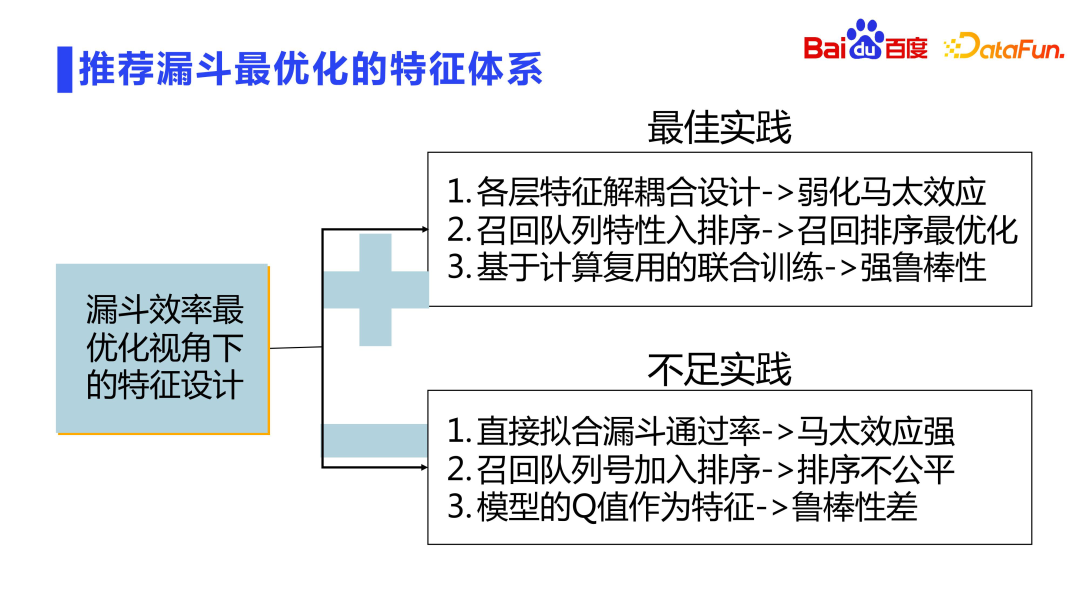
L'ensemble de l'entonnoir de recommandation est conçu en couches, et chaque couche est filtrée et tronquée. Comment obtenir une efficacité maximale dans une conception en couches avec troncature de filtre ? Comme mentionné précédemment, nous effectuerons une formation conjointe des modèles. De plus, des conceptions associées peuvent également être réalisées dans la dimension de la conception des fonctionnalités. Il y a aussi quelques problèmes ici :
- Tout d'abord, afin d'améliorer le taux de réussite de l'entonnoir, le rappel et le tri grossier sont directement adaptés à la notation du tri fin ou au tri fin, ce qui conduira à un renforcement supplémentaire de l'effet Matthew. À l'heure actuelle, le modèle de rappel/tri approximatif n'est pas le comportement de l'utilisateur qui pilote le processus d'apprentissage, mais l'entonnoir d'adaptation. Ce n’est pas le résultat que nous souhaitons. L'approche correcte consiste à recommander la conception de découplage de chaque couche du modèle d'entonnoir, plutôt que d'ajuster directement la couche inférieure de l'entonnoir.
- Le deuxième aspect est le tri grossier, qui est théoriquement plus proche du rappel et équivaut essentiellement au débouché du rappel unifié. Par conséquent, au niveau du tri grossier, davantage de signaux de rappel peuvent être introduits, tels que des signaux de vote de foule pour des recommandations collaboratives, des chemins d'index de graphiques, etc., afin que le tri grossier puisse être optimisé conjointement avec la file d'attente de rappel, de sorte que l'efficacité du rappel des ressources entrant dans le tri fin peuvent être optimisées.
- Le troisième est la réutilisation des calculs, qui peut améliorer la robustesse du modèle tout en réduisant la quantité de calcul. Il convient de noter ici qu'il existe souvent des modèles en cascade. Le modèle de deuxième niveau utilise les scores du modèle de premier niveau comme caractéristiques. Cette approche est très risquée car la valeur finale estimée du modèle est une distribution instable. Si la valeur du modèle de premier niveau est directement utilisée comme fonctionnalité, le modèle de niveau inférieur sera fortement couplé, provoquant une instabilité du système.
3. Algorithme
Ensuite, nous présenterons la conception de l'algorithme de base.
1. Modèle de tri d'un point de vue système
Tout d'abord, examinons le modèle de tri des recommandations. Il est généralement admis que le classement fin est le modèle le plus précis du système de recommandation. Il existe une opinion dans l'industrie selon laquelle la mise en page grossière est liée à la mise en page fine et peut être apprise à partir de la mise en page fine. Cependant, dans la pratique, il a été constaté que la mise en page grossière ne peut pas être directement apprise à partir de la mise en page fine, ce qui peut poser de nombreux problèmes.
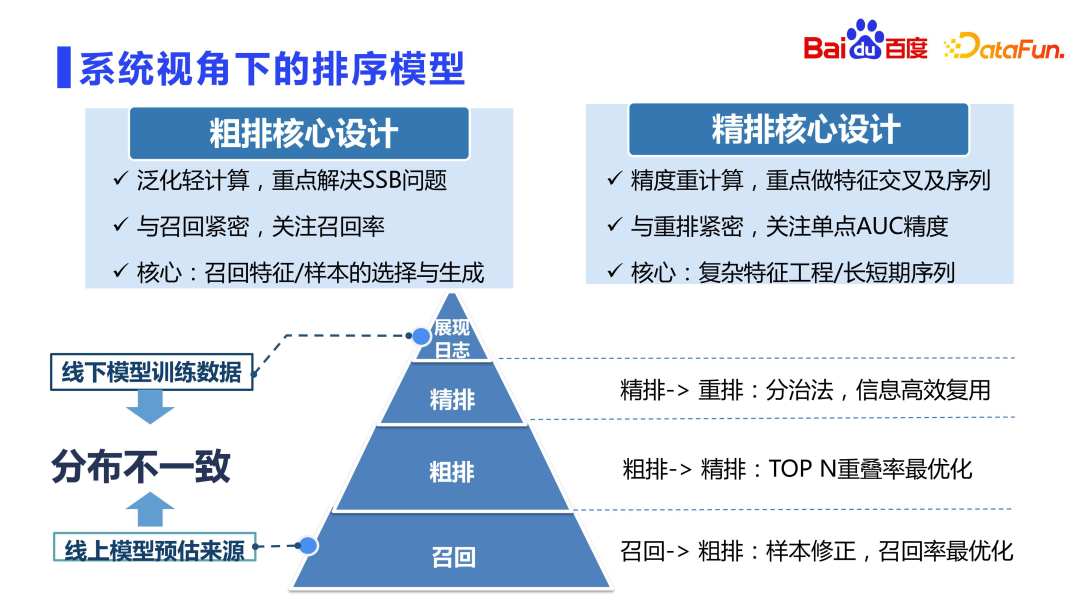
Comme vous pouvez le voir sur la photo ci-dessus, le positionnement du tri grossier et du tri fin est différent. D'une manière générale, les échantillons d'apprentissage pour le tri grossier sont les mêmes que les échantillons pour le tri fin, qui sont également des échantillons d'affichage. Chaque fois que des dizaines de milliers de candidats sont rappelés pour un classement approximatif, plus de 99 % des ressources ne sont pas affichées, et le modèle n'utilise qu'une dizaine de ressources qui sont finalement affichées pour la formation, ce qui brise l'indépendance. distribution identique, la répartition des modèles hors ligne varie considérablement. Cette situation est la plus grave en matière de rappel, car les ensembles de candidats au rappel sont des millions, des dizaines de millions, voire des centaines de millions, et la plupart des résultats finaux renvoyés ne sont pas affichés. Le tri approximatif est également relativement grave, car l'ensemble des candidats est généralement présent. les dizaines de milliers. Le tri fin est relativement meilleur. Après avoir passé par l'entonnoir à deux niveaux de rappel et de tri grossier, la qualité de base des ressources est principalement assurée. Par conséquent, le problème de l'incohérence de la distribution hors ligne dans le classement fin n'est pas si grave, et il n'est pas nécessaire de trop considérer le problème du biais de sélection d'échantillon (SSB). En même temps, parce que l'ensemble des candidats est petit, des calculs lourds peuvent être effectués. être effectué. Le classement fin se concentre sur l'intersection des caractéristiques, la modélisation des séquences, etc.
Cependant, le niveau de tri grossier ne peut pas être directement appris à partir du tri fin, ni être directement recalculé de la même manière que le tri fin, car le montant du calcul est des dizaines de fois supérieur à celui du tri fin si vous utilisez directement le tri fin. Le concept de conception est que les machines en ligne sont complètement insupportables, donc une configuration approximative nécessite un haut degré de compétence pour équilibrer les performances et l'effet. L'objectif de l'itération de tri grossier est différent du tri fin, et il résout principalement des problèmes tels que le biais de sélection des échantillons et l'optimisation de la file d'attente de rappel. Le tri grossier étant étroitement lié au rappel, une plus grande attention est portée à la qualité moyenne de milliers de ressources renvoyées au tri fin plutôt qu'à la relation de tri précis. Le classement fin est plus étroitement lié au réarrangement et se concentre davantage sur la précision de l'AUC d'un seul point.
Par conséquent, dans la conception d'un classement approximatif, il s'agit davantage de la sélection et de la génération d'échantillons, ainsi que de la conception de fonctionnalités et de réseaux de généralisation. La conception raffinée peut réaliser des fonctionnalités d'intersection complexes à plusieurs ordres, une modélisation de séquences ultra longues, etc.
2. Généralisation des DNN discrets à très grande échelle
L'introduction précédente se situe au niveau macro.
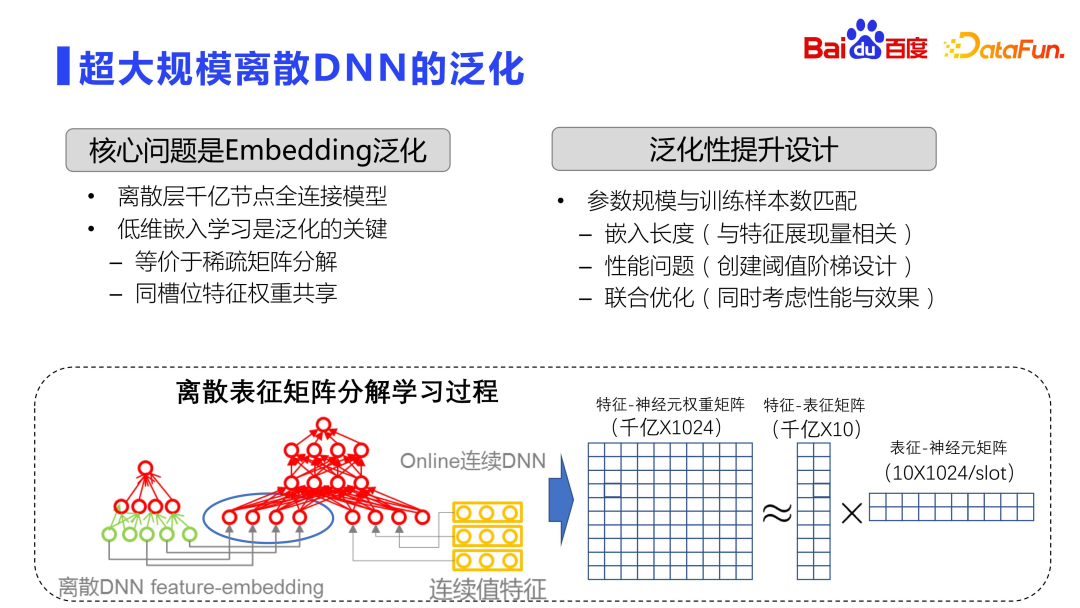
Plus précisément en ce qui concerne le processus de formation des modèles, la tendance actuelle dans l'industrie est d'utiliser des DNN discrets à très grande échelle, et le problème de généralisation sera plus grave. Parce que le DNN discret à très grande échelle, via la couche d'intégration, remplit principalement la fonction de mémoire. Voir la figure ci-dessus. L'ensemble de l'espace d'intégration est une très grande matrice, comportant généralement des centaines de milliards ou des milliards de lignes et 1 000 colonnes. Par conséquent, la formation des modèles est entièrement distribuée, avec des dizaines, voire des centaines de GPU effectuant une formation distribuée.
Théoriquement, pour une matrice aussi grande, des calculs violents ne seront pas effectués directement, mais des opérations similaires à la décomposition matricielle seront utilisées. Bien entendu, cette décomposition matricielle est différente de la décomposition matricielle SVD standard. La décomposition matricielle ici apprend d'abord la représentation de faible dimension et réduit la quantité de calcul et de stockage grâce au partage des paramètres entre les emplacements, c'est-à-dire qu'elle est décomposée en deux matrices le processus d’apprentissage. La première est la matrice de caractéristiques et de représentation, qui apprendra la relation entre la caractéristique et l'intégration de faible dimension. Cette intégration est très faible, et une intégration d'une dizaine de dimensions est généralement sélectionnée. L'autre est l'intégration et la matrice de neurones, et les poids entre chaque emplacement sont partagés. De cette façon, le volume de stockage est réduit et l'effet est amélioré.
L'apprentissage par intégration de faible dimension est la clé pour optimiser la capacité de généralisation du DNN hors ligne. Cela équivaut à effectuer une décomposition matricielle clairsemée. Par conséquent, la clé pour améliorer la capacité de généralisation de l'ensemble du modèle réside dans la façon de créer le paramètre. L'échelle et le numéro d'échantillon correspondent mieux.
Optimiser sous plusieurs aspects :
- Tout d'abord, du point de vue de l'intégration, car la quantité d'affichage des différentes fonctionnalités est très différente et la quantité d'affichage de certaines fonctionnalités est très élevée, comme la tête ressources , Les utilisateurs principaux peuvent utiliser des dimensions d'intégration plus longues. C'est l'idée commune des dimensions d'intégration dynamiques, c'est-à-dire que plus les dimensions d'intégration sont affichées de manière complète. Bien sûr, si vous voulez être plus sophistiqué, vous pouvez utiliser autoML et d'autres méthodes pour effectuer un apprentissage par renforcement et rechercher automatiquement la longueur d'intégration optimale.
- Le deuxième aspect est le seuil de création. Étant donné que différentes ressources ont des quantités d'affichage différentes, il faut également prendre en compte le moment où créer des représentations intégrées pour les fonctionnalités.
3. Problème de surapprentissage
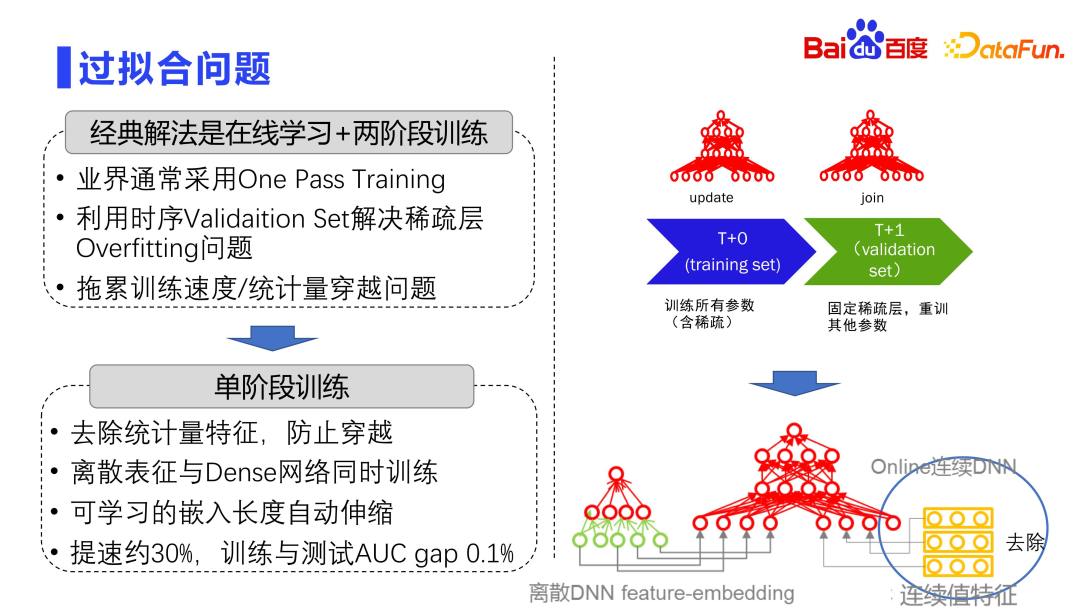
L'industrie adopte généralement une méthode de formation en deux étapes pour résister au surapprentissage. L'ensemble du modèle se compose de deux couches, l'une est une grande couche matricielle discrète et l'autre est une petite couche de paramètres dense. La couche matricielle discrète est très facile à surajuster, c'est pourquoi la pratique industrielle utilise généralement la formation One Pass, c'est-à-dire l'apprentissage en ligne, où toutes les données sont transmises, et la formation par lots n'est pas effectuée comme dans le monde universitaire.
De plus, l'industrie utilise généralement un ensemble de validation de synchronisation pour résoudre le problème de surapprentissage des couches clairsemées. Divisez l'ensemble des données d'entraînement en plusieurs Deltas, T0, T1, T2 et T3, en fonction de la dimension temporelle. Chaque formation est corrigée avec la couche de paramètres discrets formée il y a quelques heures, puis les données Delta suivantes sont utilisées pour affiner le réseau dense. Autrement dit, en corrigeant la couche clairsemée et en recyclant d'autres paramètres, le problème de surajustement du modèle peut être atténué.
Cette approche posera également un autre problème, car la formation est divisée, et les paramètres discrets au temps T0 doivent être corrigés à chaque fois, puis l'étape de jointure est recyclée au temps t+1, ce qui fera baisser le toute la formation. La vitesse apporte des défis d'évolutivité. Par conséquent, ces dernières années, une formation en une seule étape a été adoptée, c'est-à-dire que la couche de représentation discrète et la couche de réseau dense sont mises à jour simultanément dans un Delta. Il existe également un problème avec la formation en une seule étape, car en plus d'intégrer des fonctionnalités, le modèle entier possède également de nombreuses fonctionnalités à valeur continue. Ces fonctionnalités à valeur continue compteront les clics d'affichage de chaque fonctionnalité discrète. risque de croisement de données. Par conséquent, dans la pratique réelle, la première étape consistera à supprimer les caractéristiques des statistiques, et la deuxième étape consistera à former le réseau dense avec la représentation discrète, en utilisant une méthode de formation en une seule étape. De plus, toute la longueur intégrée est automatiquement évolutive. Grâce à cette série de méthodes, la formation du modèle peut être accélérée d'environ 30 %. La pratique montre que le degré de surapprentissage de cette méthode est très faible et que la différence entre l'AUC de la formation et celle des tests est de 1/1000 ou moins.
IV. Architecture
Ensuite, je présenterai mes réflexions et mes expériences sur la conception architecturale.
1. Principe de conception en couches du système
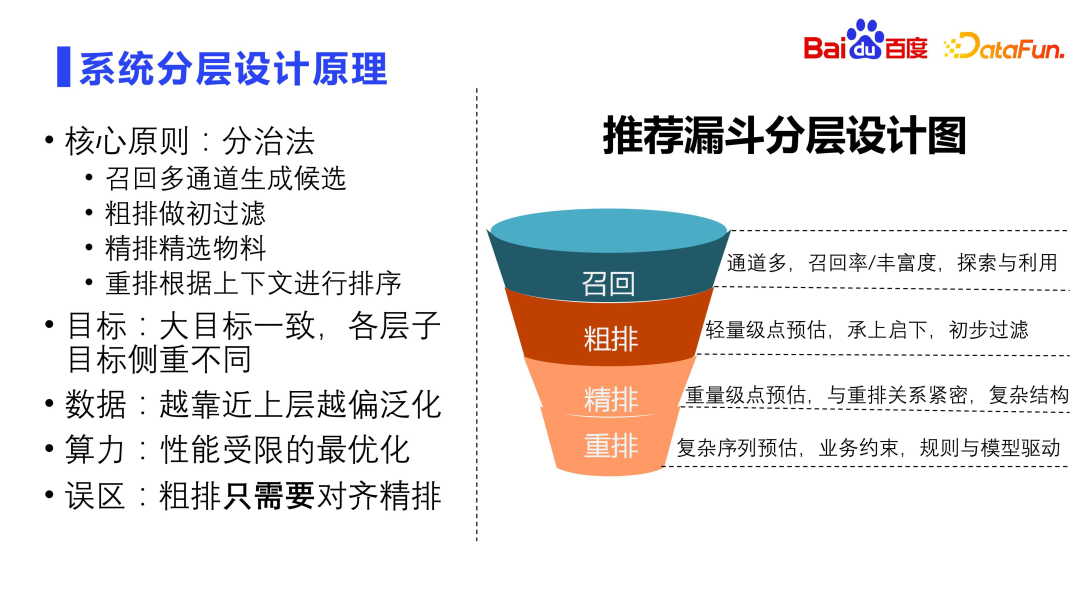
Le principe de base de la conception du système est la méthode diviser pour régner. Le rappel nécessite plusieurs canaux. L'objectif principal est d'améliorer le taux de rappel et la richesse des ressources de rappel. Dans le même temps, le rappel doit également prendre en compte les questions d'exploration et d'utilisation, qui constituent la garantie fondamentale de l'effet de recommandation. Le tri grossier est la première couche de filtrage, principalement pour l'estimation ponctuelle légère, reliant le précédent et le suivant. Le classement précis implique généralement des calculs et des prédictions lourds. Il est étroitement lié au réarrangement. Il utilise généralement des structures très complexes et fait également l'objet de recherches industrielles. Le réarrangement est la dernière couche. Le réarrangement est spécifique aux utilisateurs et détermine la séquence d'affichage finale. Sur la base des résultats du classement précis, le contexte est pris en compte et une prédiction de séquence complexe est effectuée, c'est-à-dire un tri par liste. La réorganisation doit prendre en compte de nombreuses contraintes métier. Elle contient de nombreuses règles, notamment la rupture, le LCN, la sortie, etc. Il s'agit d'un module piloté à la fois par des règles et des modèles.
Les objectifs de chaque couche du système de recommandation sont fondamentalement les mêmes, mais l'objectif de chaque couche est différent. Le rappel et le classement approximatif se concentrent sur la généralisation et le taux de rappel, le classement fin se concentre sur la précision de l'AUC en un seul point et le réarrangement se concentre sur l'optimisation globale de la séquence. Du point de vue des données, plus le rappel est proche d'un tri grossier, plus il est général, et plus le tri fin et le réarrangement sont proches, plus la précision est requise. Plus la source de rappel est proche, plus la limitation des performances est importante, car plus il y a de ressources candidates, plus la complexité de calcul est grande. Il est faux de croire que le tri grossier doit uniquement être aligné sur le tri fin. Le tri grossier doit tenir compte de la cohérence avec le tri fin, mais il ne peut pas uniquement être aligné sur le tri fin. Si vous ne faites rien pour le tri grossier et que vous vous contentez d'aligner et de trier finement, cela provoquera également un effet cheval très sérieux. Parce qu'un classement précis n'est pas la vérité fondamentale, le comportement des utilisateurs l'est. Vous devez bien apprendre le comportement des utilisateurs, pas apprendre un classement précis. C'est un conseil très important.
2. Entraînement conjoint modèle en plusieurs étapes
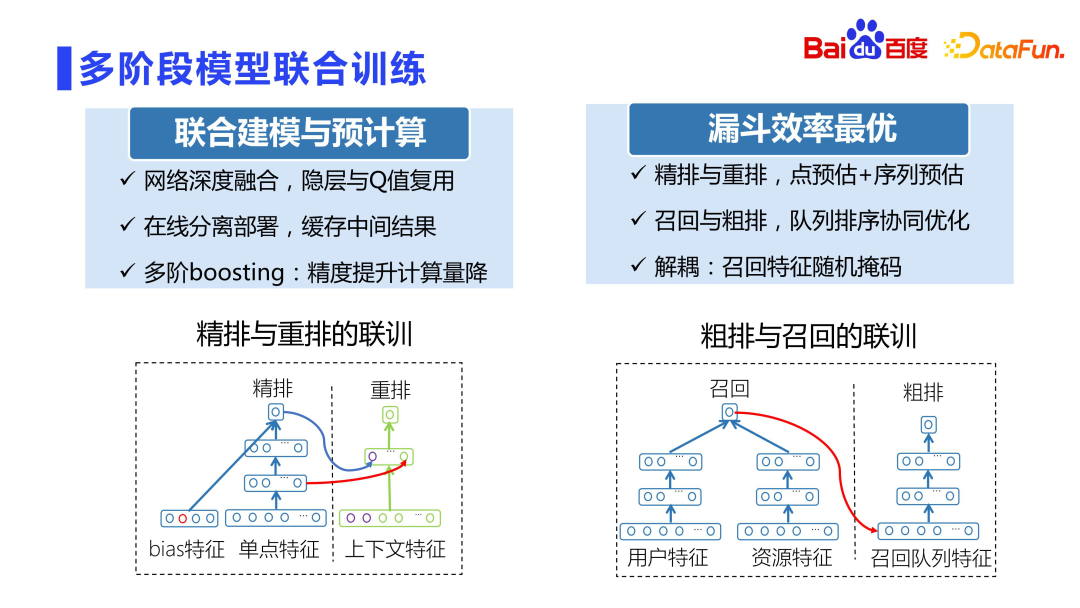
La relation entre le classement fin et le réarrangement est très étroite Dans les premières années, le réarrangement était directement entraîné en utilisant les scores du classement fin. , c'est couplé C'est très sérieux. Par contre, utiliser une notation précise directement pour la formation peut facilement provoquer des fluctuations en ligne.
Le projet de formation conjoint Baidu Fengchao CTR 3.0 de classement fin et de réarrangement utilise très intelligemment des modèles pour s'entraîner simultanément afin d'éviter le problème du couplage de notation. Ce projet utilise la couche cachée et la notation interne du sous-réseau de classement fin comme caractéristiques du sous-réseau de réarrangement. Ensuite, les sous-réseaux de classement fin et de réarrangement sont séparés et déployés dans leurs modules respectifs. D'une part, les résultats intermédiaires peuvent être bien réutilisés sans le problème de fluctuation provoqué par le couplage de notation. Dans le même temps, la précision du réarrangement sera améliorée d'un centile. C’est également l’un des sous-projets qui a reçu la plus haute distinction de Baidu cette année-là.
De plus, veuillez noter que ce projet n'est pas ESSM. ESSM est une modélisation CTCVR et une modélisation multi-objectifs, et la formation conjointe CTR3.0 résout principalement le problème du couplage de notation et de la précision du modèle de réarrangement.
De plus, le rappel et le tri grossier doivent être découplés, car de nouvelles files d'attente s'ajoutent, ce qui peut ne pas être juste pour les nouvelles files d'attente. Par conséquent, une méthode de masque aléatoire est proposée, c'est-à-dire masquer aléatoirement certaines caractéristiques afin que le degré de couplage ne soit pas si fort.
3. Réseau de routage clairsemé
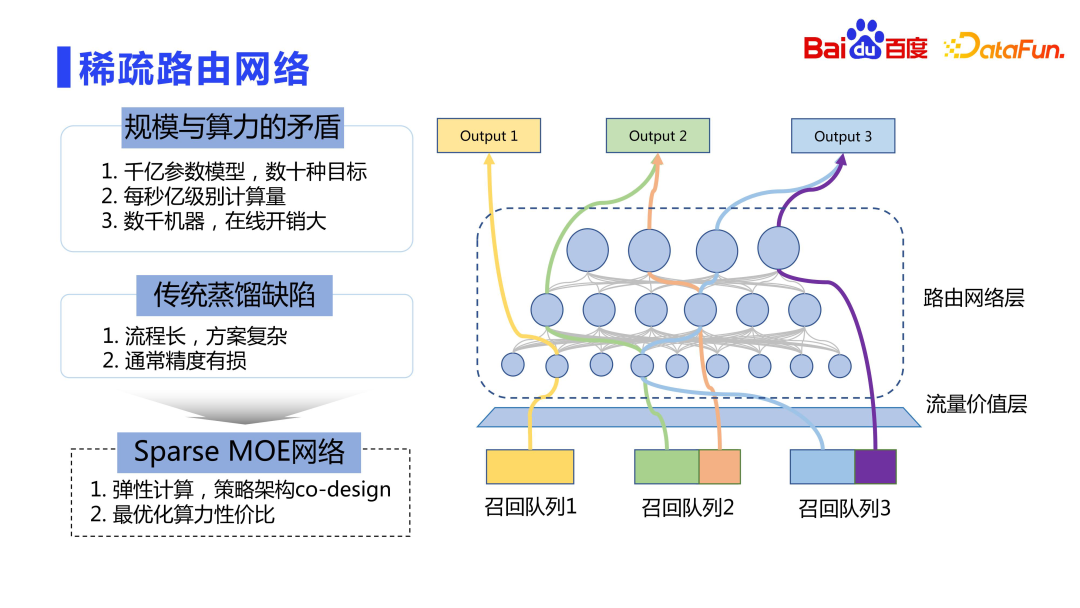
Enfin, regardons le processus de déploiement en ligne. L'échelle des paramètres du modèle est de l'ordre de centaines de milliards à des milliards, et il existe de nombreuses cibles. Le déploiement direct en ligne est très coûteux, et nous ne pouvons pas seulement considérer l'effet sans considérer les performances. Une meilleure méthode est le calcul élastique, similaire à l'idée du Sparse MOE.
Rough file d'attente a accès à de nombreuses files d'attente, avec des dizaines voire des centaines de files d'attente. La valeur en ligne (LTV) de ces files d'attente est différente. La couche de valeur du trafic calcule la valeur des différentes files d'attente de rappel en fonction de la durée des clics en ligne. L'idée centrale est que plus la contribution globale de la file d'attente de rappel est importante, plus les calculs peuvent être complexes. Cela permet à une puissance de calcul limitée de servir un trafic de plus grande valeur. Par conséquent, nous n'avons pas utilisé la méthode de distillation traditionnelle, mais avons adopté une idée similaire à Sparse MOE pour le calcul élastique, c'est-à-dire la conception conjointe d'une stratégie et d'une architecture, afin que différentes files d'attente de rappel puissent utiliser le réseau de ressources le plus approprié pour le calcul. .
5. Plans d'avenir
Comme nous le savons tous, nous sommes désormais entrés dans l'ère des grands modèles LLM. L'exploration par Baidu du système de recommandation de nouvelle génération basé sur le grand modèle de langage LLM sera menée sous trois aspects.

Le premier aspect est de faire évoluer le modèle de la prédiction de base à la capacité de prendre des décisions. Par exemple, des problèmes importants tels que l'exploration efficace des ressources classiques de démarrage à froid, le retour immersif de recommandations de séquences et la chaîne de prise de décision de la recherche à la recommandation peuvent tous être résolus à l'aide de grands modèles.
Le deuxième aspect va de la discrimination à la génération. Désormais, l'ensemble du modèle est discriminatif. À l'avenir, nous explorerons les méthodes de recommandation génératives, telles que la génération automatique de raisons de recommandation, l'amélioration automatique des données à longue traîne en fonction des invites et la génération générative. modèle de récupération.
Le troisième aspect va de la boîte noire à la boîte blanche. Dans le système de recommandation traditionnel, les gens disent souvent que le réseau neuronal est une alchimie et qu'il est possible d'explorer dans la direction de la boîte blanche. des tâches importantes à venir. Par exemple, sur la base de la cause et de l'effet, nous pouvons explorer les raisons des transitions d'état du comportement des utilisateurs, effectuer de meilleures estimations impartiales en termes d'équité des recommandations et permettre une meilleure adaptation de scène dans les scénarios d'apprentissage automatique multitâches.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!