
Maison >Périphériques technologiques >IA >Application du modèle de classement des recommandations interdomaines d'apprentissage par transfert continu dans le système de recommandation Taobao
Application du modèle de classement des recommandations interdomaines d'apprentissage par transfert continu dans le système de recommandation Taobao

- PHPzavant
- 2023-05-13 14:04:061623parcourir
Cet article explore comment mettre en œuvre un modèle de recommandation interdomaine dans le cadre de l'apprentissage continu dans l'industrie et propose un nouveau paradigme de recommandation interdomaine d'apprentissage par transfert continu, en utilisant les résultats de représentation de couche intermédiaire de la source pré-entraînée en continu. modèle de domaine comme domaine cible Grâce aux connaissances supplémentaires du modèle, un module adaptateur léger a été conçu pour réaliser la migration des connaissances inter-domaines et a obtenu des résultats commerciaux significatifs dans le classement des produits recommandés.
Contexte
Ces dernières années, avec l'application de modèles profonds, l'effet de recommandation des systèmes de recommandation dans l'industrie a été considérablement amélioré. Avec l'optimisation continue des modèles, la structure du modèle et les changements de fonctionnalités ont été optimisés uniquement en s'appuyant. sur les données au sein de la scène est plus difficile. Sur les plateformes de commerce électronique à grande échelle comme Taobao, afin de répondre aux divers besoins des différents utilisateurs, il existe une série de scénarios de recommandation de différentes tailles, tels que la recommandation de flux d'informations (vous l'aimerez peut-être sur la page d'accueil), les bons produits , recommandations post-achat et collecte Ces scénarios partagent le système de produits Taobao, mais il existe des différences significatives dans les pools de sélection de produits spécifiques, les utilisateurs principaux et les objectifs commerciaux, et l'échelle des différents scénarios varie considérablement. Notre scénario « Bons produits » est un scénario de guide d'achat pour les produits sélectionnés par Taobao. Par rapport à la recommandation de flux d'informations, à la recherche principale et à d'autres scénarios, l'échelle est relativement petite. Par conséquent, comment utiliser l'apprentissage par transfert, la recommandation inter-domaines et autres. Les méthodes pour améliorer l'effet du modèle ont toujours été l'un des points clés de l'optimisation d'un bon modèle de tri des marchandises. Bien que les produits et les utilisateurs dans les différents scénarios commerciaux de Taobao se chevauchent, en raison des différences significatives entre les scénarios, le modèle de classement pour les grands scénarios tels que la recommandation de flux d'informations ne fonctionne pas bien lorsqu'il est directement appliqué aux scénarios dans lesquels de bons produits sont disponibles. Par conséquent, l’équipe a fait des efforts considérables dans le sens d’une recommandation inter-domaines, notamment en utilisant une série de méthodes existantes telles que la pré-formation et le réglage fin, la formation conjointe multi-scénarios et l’apprentissage global. Ces méthodes ne sont pas assez efficaces ou posent de nombreux problèmes dans les applications en ligne réelles. Le projet d'apprentissage par transfert continu propose une nouvelle méthode de recommandation inter-domaines simple et efficace pour une série de problèmes liés à l'application de ces méthodes en entreprise. Cette méthode utilise les résultats de représentation de la couche intermédiaire du modèle de domaine source pré-entraîné en continu comme connaissance supplémentaire du modèle de domaine cible
et a obtenu des résultats commerciaux significatifs dans le classement des bonnes recommandations de produits sur Taobao.La version détaillée de cet article Apprentissage par transfert continu pour la prévision du taux de clics inter-domaines sur Taobao a été publiée sur ArXiv https://arxiv.org/abs/2208.05728.
Méthode
▐ Travaux existants et leurs lacunes
Analyse des travaux existants liés aux recommandations inter-domaines (CDR) dans le monde universitaire et industriel, qui peuvent être divisés en deux grandes catégories : apprentissage conjoint et pré-formation & Réglage fin. Parmi eux, la méthode de formation conjointe optimise simultanément les modèles de domaine source (Source Domain) et de domaine cible (Target Domain). Cependant, ce type de méthode nécessite l'introduction de données du domaine source dans la formation, et les échantillons du domaine source sont généralement de grande taille, consommant ainsi d'énormes ressources de calcul et de stockage. De nombreuses petites entreprises ne peuvent pas se permettre une telle surcharge de ressources. D'un autre côté, ce type de méthode doit optimiser plusieurs objectifs de scène en même temps, et les différences entre les scènes peuvent également entraîner des effets négatifs de conflits d'objectifs. Par conséquent, les méthodes de réglage fin avant l'entraînement ont des applications plus larges dans de nombreuses scènes. l'industrie.
Une caractéristique importante du système de recommandation industrielle est que la formation du modèle suit le paradigme de l'apprentissage continu, c'est-à-dire que le modèle doit utiliser les derniers échantillons et utiliser la mise à jour incrémentielle hors ligne (apprentissage incrémentiel) ou apprentissage en ligne) et d'autres méthodes pour connaître la dernière distribution de données. Pour la tâche de recommandation inter-domaines étudiée dans cet article, les modèles du domaine source et du domaine cible suivent tous deux la méthode de formation en apprentissage continu. Nous proposons ainsi un nouveau problème qui sera largement utilisé dans les applications académiques et industrielles : l'apprentissage par transfert continu (Continual Transfer Learning), défini comme le transfert de connaissances d'un domaine qui évolue avec le temps vers un autre domaine qui évolue également avec le temps. Nous pensons que l'application des méthodes existantes de recommandation interdomaine et d'apprentissage par transfert dans les systèmes de recommandation industrielle, les moteurs de recherche, la publicité informatique, etc. devraient suivre le paradigme d'apprentissage par transfert continu, c'est-à-dire que le processus de transfert doit être continu et multiple. La raison en est que la distribution des données change rapidement et que seule une migration continue peut garantir un effet de migration stable. En combinaison avec les caractéristiques de ce système de recommandation industrielle, nous pouvons rencontrer des problèmes dans l'application pratique de la pré-formation et de la mise au point. En raison des différences de scène entre le domaine source et le domaine cible, il est généralement nécessaire d'utiliser un grand nombre d'échantillons pour obtenir un meilleur résultat en affinant le modèle du domaine source. Afin de réaliser un apprentissage par transfert continu, nous devons utiliser le dernier modèle de domaine source pour l'affiner de temps en temps, ce qui entraîne un coût de formation très énorme. Cette méthode de formation est également difficile à mettre en ligne. De plus, l'utilisation de ce grand nombre d'échantillons pour un réglage fin peut également amener le modèle de domaine source à oublier les connaissances utiles conservées, évitant ainsi le problème d'oubli catastrophique dans le modèle. Il est également possible d'utiliser les paramètres du modèle de domaine source pour remplacer l'original ; les paramètres qui ont été appris dans le domaine cible. Les connaissances utiles acquises historiquement à partir du modèle d'origine sont écartées. Par conséquent, nous devons concevoir un modèle d’apprentissage par transfert continu plus efficace, adapté aux scénarios de recommandation industrielle.
Cet article propose un modèle simple et efficaceCTNet (Continual Transfer Network, Continu Transfer Network) pour résoudre les problèmes ci-dessus. Différent des méthodes traditionnelles de pré-formation et de réglage fin, l'idée centrale de CTNet est qu'il ne peut pas oublier et rejeter toutes les connaissances acquises par le modèle au cours de l'histoire, et conserve tous les paramètres du modèle de domaine source d'origine et du modèle de domaine cible. . Ces paramètres stockent les connaissances acquises grâce à un très long apprentissage de données historiques (par exemple, le modèle de classement fin de Taobao a été continuellement entraîné progressivement pendant plus de deux ans). CTNet adopte une structure simple à deux tours et utilise une couche d'adaptateur légère pour mapper les résultats de représentation de la couche intermédiaire du modèle de domaine source pré-entraîné en continu en tant que connaissance supplémentaire du modèle de domaine cible. Contrairement aux méthodes de réglage précis avant la formation qui nécessitent un retour en arrière des données pour obtenir un apprentissage par transfert continu, CTNet nécessite uniquement la mise à jour des données incrémentielles, permettant ainsi un apprentissage par transfert continu efficace.
|
Pas besoin d'utiliser un grand nombre d'échantillons de domaine source |
Non affecté par la source cible de la scène de domaine |
Il suffit d'ajouter | L'apprentissage par transfert continuNon |
Non |
Oui |
Pré-formation - Mise au point |
Oui |
Oui | Non |
|
CTNet proposé dans cet article |
est |
est |
est |
Tableau 1 : Comparaison entre CTNet et les modèles de recommandation inter-domaines existants
▐ Définition du problème
Cet article explore le nouveau problème de l'apprentissage par transfert continu :
Persistance donnée dans le temps Avec source changeante et domaines cibles, l'apprentissage par transfert continu espère utiliser les connaissances historiques ou actuellement acquises des domaines source et cible pour améliorer la précision des prédictions dans le futur domaine cible.
Nous appliquons le problème de l'apprentissage par transfert continu à la tâche de recommandation inter-domaines de Taobao. Cette tâche présente les caractéristiques suivantes :
- L'échelle des différents scénarios de recommandation varie considérablement et la connaissance du modèle formé dans le domaine source plus large peut être utilisée pour améliorer l'effet de recommandation du domaine cible.
- Les utilisateurs et les produits dans différents scénarios partagent le même gros pot. Cependant, il existe des différences évidentes sur le terrain dans différents scénarios en raison des différents effets d'affichage des pools de produits sélectionnés, des utilisateurs principaux, des graphiques et du texte, etc.
- Tous les modèles de scénarios recommandés sont continuellement formés progressivement sur la base des dernières données.
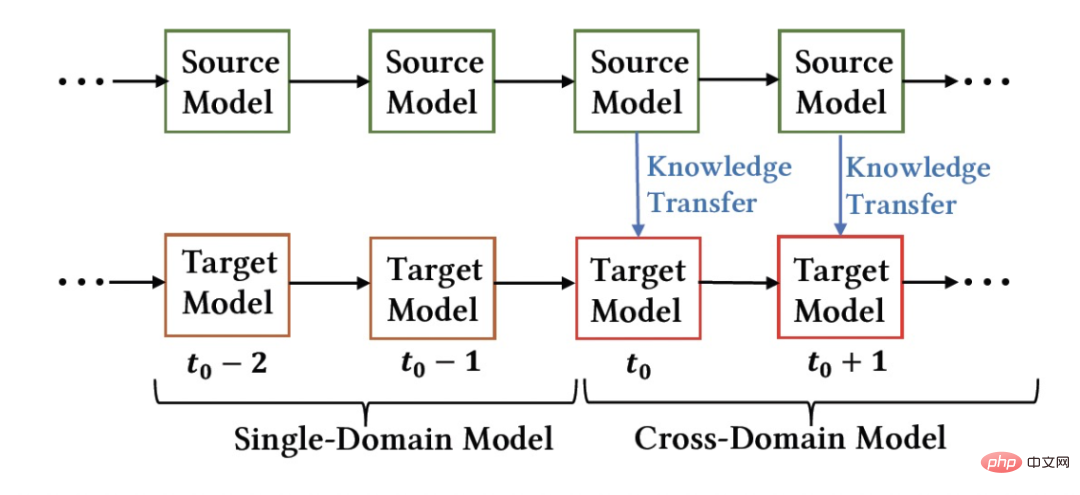
Figure 1 : Schéma schématique de déploiement du modèle
La figure ci-dessus montre le déploiement de notre méthode en ligne. Avant le moment 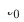 , le modèle de domaine source et le modèle de domaine cible étaient entraînés individuellement et continuellement de manière incrémentale en utilisant uniquement les données de supervision des scènes respectives. À partir du
, le modèle de domaine source et le modèle de domaine cible étaient entraînés individuellement et continuellement de manière incrémentale en utilisant uniquement les données de supervision des scènes respectives. À partir du 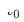 moment, nous avons déployé le modèle de recommandation inter-domaines CTNet sur le domaine cible. Ce modèle continuera à s'entraîner progressivement sur les données du domaine cible sans oublier les connaissances acquises dans l'historique, tout en transférant continuellement les connaissances de jusqu'à. -date modèles de domaine source. Modèle de réseau de transfert continu (CTNet) caractéristiques du modèle de domaine source et de ses paramètres de réseau dans le modèle raffiné original du domaine cible, formant une structure à deux tours, dans laquelle la tour gauche de CTNet est la tour source et la tour droite est la tour cible (Tar Target) . Différent des méthodes courantes qui utilisent uniquement le score de notation final du modèle de domaine source ou n'utilisent que certaines représentations superficielles (telles que l'intégration), nous utilisons un réseau d'adaptateurs léger pour combiner toutes les couches cachées intermédiaires du modèle de domaine source MLP
moment, nous avons déployé le modèle de recommandation inter-domaines CTNet sur le domaine cible. Ce modèle continuera à s'entraîner progressivement sur les données du domaine cible sans oublier les connaissances acquises dans l'historique, tout en transférant continuellement les connaissances de jusqu'à. -date modèles de domaine source. Modèle de réseau de transfert continu (CTNet) caractéristiques du modèle de domaine source et de ses paramètres de réseau dans le modèle raffiné original du domaine cible, formant une structure à deux tours, dans laquelle la tour gauche de CTNet est la tour source et la tour droite est la tour cible (Tar Target) . Différent des méthodes courantes qui utilisent uniquement le score de notation final du modèle de domaine source ou n'utilisent que certaines représentations superficielles (telles que l'intégration), nous utilisons un réseau d'adaptateurs léger pour combiner toutes les couches cachées intermédiaires du modèle de domaine source MLP
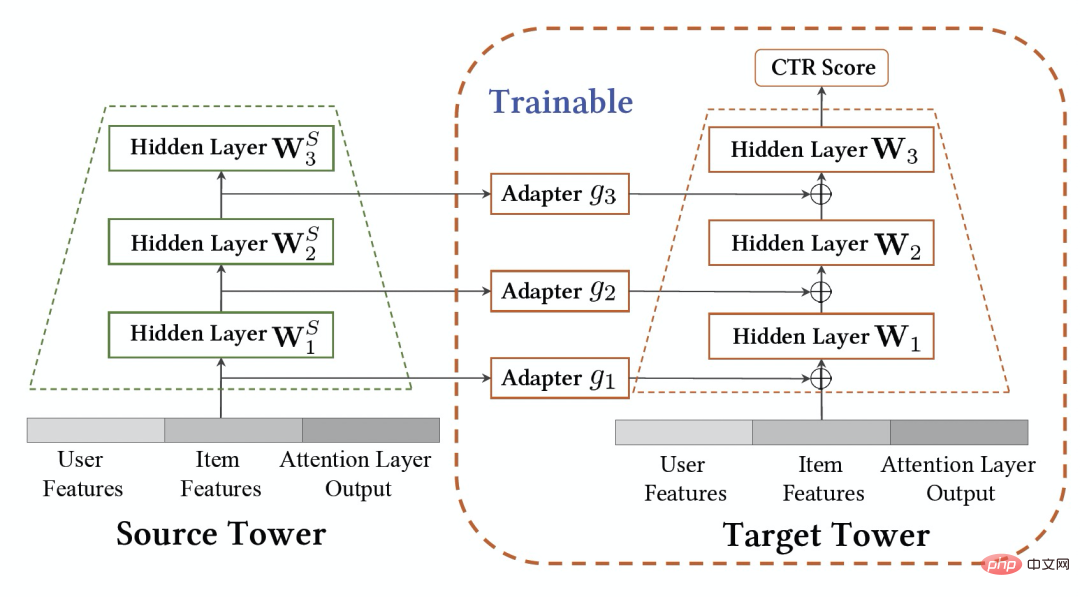
de Target Tower (la formule suivante Exprime le situation de
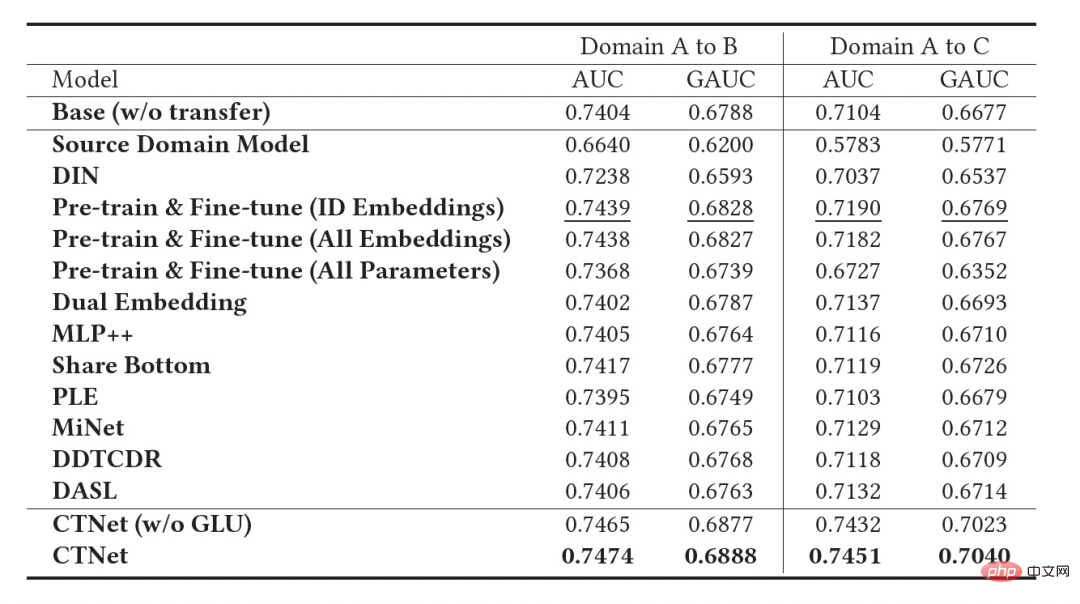
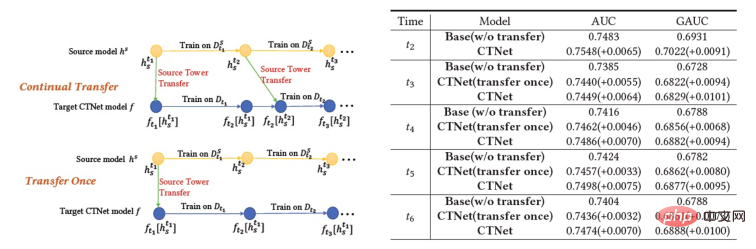
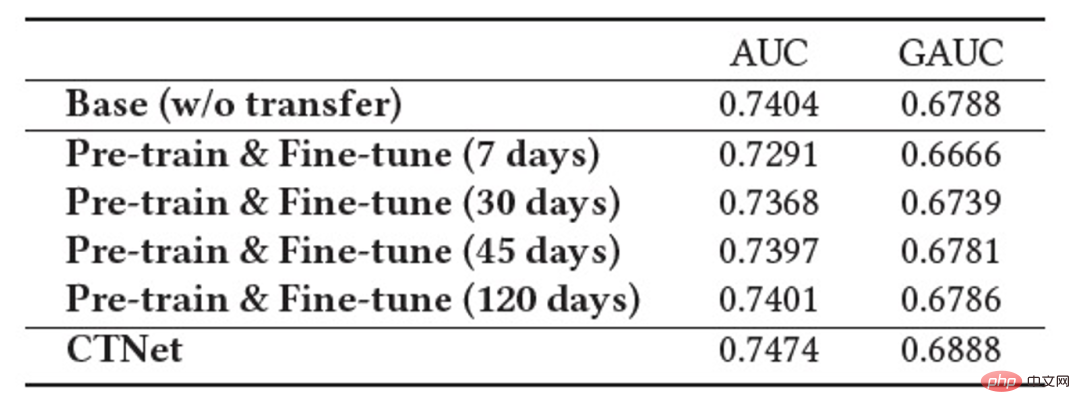
). La clé pour améliorer l'effet de CTNet est d'utiliser la migration des informations de représentation profonde dans MLP. S'appuyant sur l'idée des unités linéaires fermées (GLU), le réseau d'adaptateurs utilise une couche linéaire fermée, qui peut mettre en œuvre efficacement la sélection adaptative des caractéristiques du domaine source. Les connaissances utiles dans le modèle seront migrées et les informations incompatibles avec celles-ci. les caractéristiques de la scène seront transférées et peuvent être filtrées. Étant donné que le modèle de domaine source continue d'utiliser les dernières données de supervision du domaine source pour une pré-formation continue, pendant notre processus de formation, Source Tower continuera également à charger les derniers paramètres du modèle de domaine source mis à jour et restera fixe pendant le processus de rétropropagation, garantissant ainsi le bon fonctionnement du modèle de domaine source. progrès efficace de l’apprentissage par transfert continu. Par conséquent, le modèle CTNet est très adapté au paradigme d'apprentissage continu, permettant au modèle de domaine cible d'apprendre en permanence les dernières connaissances fournies par le modèle de domaine source pour s'adapter aux derniers changements de distribution des données. Dans le même temps, étant donné que le modèle est formé uniquement sur les données du domaine cible, il garantit qu'il n'est pas affecté par les objectifs de formation du domaine source et ne nécessite aucune formation sur les données du domaine source, évitant ainsi une grande quantité de stockage et surcharge de calcul. De plus, une telle structure de réseau adopte une méthode de conception additive, de sorte que les dimensions de la couche MLP du modèle d'origine n'ont pas besoin d'être modifiées pendant le processus de migration. La tour cible est complètement initialisée par le modèle en ligne du domaine cible d'origine, évitant ainsi. Réinitialisation aléatoire de la couche MLP. Cela peut garantir que l'effet du modèle d'origine n'est pas endommagé dans la plus grande mesure et nécessite seulement moins de données incrémentielles pour obtenir de bons résultats, permettant ainsi un démarrage à chaud du modèle. Nous définissons le modèle de domaine source comme Figure 3 : Formation CTNet Nous avons également comparé une série de méthodes de base de recommandation inter-domaines traditionnelles, y compris des méthodes courantes de pré-formation et de réglage fin et des méthodes de formation conjointes (telles que MLP++, PLE, MiNet, DDTCDR, DASL, etc.). a les meilleures performances dans les deux cas. Elle est nettement meilleure que les méthodes existantes sur tous les ensembles de données. Par rapport au modèle principal entièrement en ligne, CTNet a obtenu des améliorations significatives du GAUC de +1,0 % et +3,6 % respectivement sur les deux ensembles de données. Nous avons en outre analysé les avantages du transfert continu par rapport au transfert unique via des expériences. Dans le cadre de CTNet, l'amélioration de l'effet apporté par un seul transfert s'atténuera avec la mise à jour incrémentielle du modèle, tandis que l'apprentissage continu par transfert peut assurer l'amélioration stable de l'effet du modèle. Figure 4 : Avantages de l'apprentissage par transfert continu par rapport au transfert unique Le tableau suivant montre l'effet du réglage fin de pré-formation traditionnel. Nous utilisons le modèle de domaine source complet pour effectuer. sur les données du domaine cible Sur la formation. En raison des différences entre les champs, un très grand nombre d'échantillons (tels que des échantillons sur 120 jours) sont nécessaires pour ajuster l'effet du modèle à un niveau comparable à celui du modèle de base complet en ligne. Afin de réaliser un apprentissage par transfert continu, nous devons réajuster en utilisant le dernier modèle de domaine source à intervalles réguliers. Le coût énorme de chaque ajustement rend également cette méthode impropre à l'apprentissage par transfert continu. De plus, cette méthode ne surpasse pas le modèle de base sans migration en termes d'effet. La raison principale est que l'utilisation d'un apprentissage massif d'échantillons de domaines cibles fait également oublier au modèle les connaissances originales du domaine source et l'effet final du modèle obtenu. la formation est similaire à un L'effet de la formation uniquement sur les données du domaine cible. Dans le cadre du paradigme de réglage précis avant la formation, il est préférable de charger uniquement certains paramètres d'intégration plutôt que de réutiliser tous les paramètres (comme indiqué dans le tableau 2). ▐ L'activité de recommandation de bons produits est pleinement lancée. Par rapport au modèle complet de la génération précédente, des améliorations significatives des indicateurs commerciaux ont été obtenues dans deux scénarios de recommandation : Scénario B : CTR+2,5%, achats supplémentaires +6,7%, nombre de transactions +3,4%, GMV+7,7% CTR +12,3%, durée de séjour +8,8%, achats supplémentaires +10,9%, nombre de transactions +30,9%, GMV +31,9% CTNet adopte une structure de réseau parallèle Afin d'économiser les ressources informatiques, nous en partageons quelques-uns. Les paramètres et résultats de la couche Attention permettent de calculer la couche Attention dans la même partie de la Tour Source et de la Tour Cible n'être calculée qu'une seule fois. Par rapport au modèle de base, le temps de réponse en ligne (RT) de CTNet est fondamentalement le même. Présentation de l'équipeNous sommes l'équipe d'algorithme de contenu technologique Taobao et d'algorithme de bons produits. Les bons produits sont recommandés par Taobao sur la base du bouche-à-oreille et constituent un guide d'achat conçu pour aider les consommateurs à découvrir de bons produits. L'équipe est chargée d'optimiser l'algorithme de lien complet pour les activités de recommandation de produits et de recommandation de contenu vidéo court afin d'améliorer les capacités avantageuses d'exploration de produits et les capacités de guide d'achat de canaux. Les principales orientations techniques actuelles sont la recommandation interdomaine d'apprentissage par transfert continu, l'apprentissage impartial, la modélisation de liens complets du système de recommandation, la modélisation de séquences, etc. Tout en créant de la valeur commerciale, nous avons également publié plusieurs articles lors de conférences internationales telles que SIGIR. Les principaux résultats incluent PDN, UMI, CDAN, etc. 
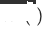 #🎜🎜 # , le modèle de domaine cible de recommandation de domaine unique d'origine est
#🎜🎜 # , le modèle de domaine cible de recommandation de domaine unique d'origine est 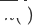 , et le modèle de recommandation inter-domaines de domaine cible nouvellement déployé est
, et le modèle de recommandation inter-domaines de domaine cible nouvellement déployé est 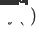 , #🎜 🎜# est le moment où le modèle de recommandation inter-domaines est déployé et lancé. Le modèle est continuellement et progressivement mis à jour au fil du temps
, #🎜 🎜# est le moment où le modèle de recommandation inter-domaines est déployé et lancé. Le modèle est continuellement et progressivement mis à jour au fil du temps 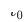 . Les paramètres de l'adaptateur, de la tour source et de la tour cible sont respectivement ,
. Les paramètres de l'adaptateur, de la tour source et de la tour cible sont respectivement , 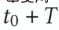 et
et 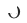 . Le processus de formation CTNet est le suivant :
. Le processus de formation CTNet est le suivant : 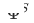
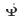

Experiment
▐ Effet hors ligne# 🎜 🎜#
Cet article explore comment mettre en œuvre un modèle de recommandation inter-domaines dans le cadre de l'apprentissage continu dans l'industrie et propose un nouveau paradigme de recommandation inter-domaines d'apprentissage par transfert continu, utilisant des formations pré-formées en continu. modèles de domaine source Les résultats de la représentation de la couche intermédiaire sont utilisés comme connaissances supplémentaires du modèle de domaine cible. Un module adaptateur léger est conçu pour réaliser la migration des connaissances inter-domaines et a obtenu des résultats commerciaux significatifs dans le classement des bonnes recommandations de produits. Bien que cette méthode soit mise en œuvre pour les caractéristiques commerciales des bons biens, il s’agit également d’une méthode de modélisation relativement générale. Les méthodes et idées de modélisation associées peuvent être appliquées à l’optimisation de nombreux autres scénarios commerciaux similaires. Étant donné que le modèle de domaine source pré-entraîné continu existant de CTNet utilise uniquement des scénarios de recommandation de flux d'informations, nous envisagerons à l'avenir de mettre à niveau le modèle de domaine source pré-entraîné en continu vers un modèle pré-entraîné d'apprentissage de domaine complet qui comprend la recommandation, la recherche, domaine privé et d'autres scénarios supplémentaires. Entraînez le modèle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI