
Maison >Périphériques technologiques >IA >Résolvez complètement l'amnésie ChatGPT ! Dépasser la limite d'entrée du transformateur : mesuré pour prendre en charge 2 millions de jetons valides
Résolvez complètement l'amnésie ChatGPT ! Dépasser la limite d'entrée du transformateur : mesuré pour prendre en charge 2 millions de jetons valides

- 王林avant
- 2023-05-13 14:07:062127parcourir
ChatGPT, ou le modèle de classe Transformer, présente un défaut fatal, à savoir qu'il est trop facile à oublier. Une fois que le jeton de la séquence d'entrée dépasse le seuil de la fenêtre contextuelle, le contenu de sortie ultérieur ne correspondra pas à la logique précédente.
ChatGPT ne peut prendre en charge que la saisie de 4 000 jetons (environ 3 000 mots). Même le nouveau GPT-4 ne prend en charge qu'une fenêtre de jetons maximale de 32 000. Si vous continuez à augmenter la longueur de la séquence de saisie, la complexité de calcul deviendra croissance quadratique.
Récemment, des chercheurs de DeepPavlov, AIRI et du London Institute of Mathematical Sciences ont publié un rapport technique utilisant le Recurrent Memory Transformer (RMT) pour augmenter la longueur effective du contexte de BERT à « un niveau sans précédent de 2 millions de jetons » tout en maintenant une récupération de mémoire élevée. précision.
Lien papier : https://www.php.cn/link/459ad054a6417248a1166b30f6393301
Cette méthode peut stocker et traiter des informations locales et globales, et permettre aux informations de circuler entre les segments de la séquence d'entrée en utilisant des boucles.
La section expérimentale démontre l'efficacité de cette approche, qui a un potentiel extraordinaire pour améliorer le traitement des dépendances à long terme dans les tâches de compréhension et de génération du langage naturel, permettant un traitement contextuel à grande échelle pour les applications gourmandes en mémoire.
Cependant, il n'y a pas de repas gratuit dans le monde. Bien que RMT n'augmente pas la consommation de mémoire et puisse être étendu à des longueurs de séquence presque illimitées, le problème de la dégradation de la mémoire dans RNN persiste et un temps d'inférence plus long est nécessaire.

Mais certains internautes ont proposé une solution, RMT est utilisé pour la mémoire à long terme, un grand contexte est utilisé pour la mémoire à court terme, puis l'entraînement du modèle est effectué la nuit/pendant la maintenance.
Recurrent Memory Transformer
En 2022, l'équipe a proposé le modèle Recurrent Memory Transformer (RMT) en ajoutant un jeton de mémoire spécial à la séquence d'entrée ou de sortie, puis en entraînant le modèle pour contrôler les opérations de mémoire et le traitement de la représentation de séquence. peut implémenter un nouveau mécanisme de mémoire sans modifier le modèle original du Transformer.

Lien papier : https://arxiv.org/abs/2207.06881
Conférence de publication : NeurIPS 2022
Par rapport à Transformer-XL, RMT nécessite moins de mémoire et peut gérer des tâches avec des séquences plus longues.
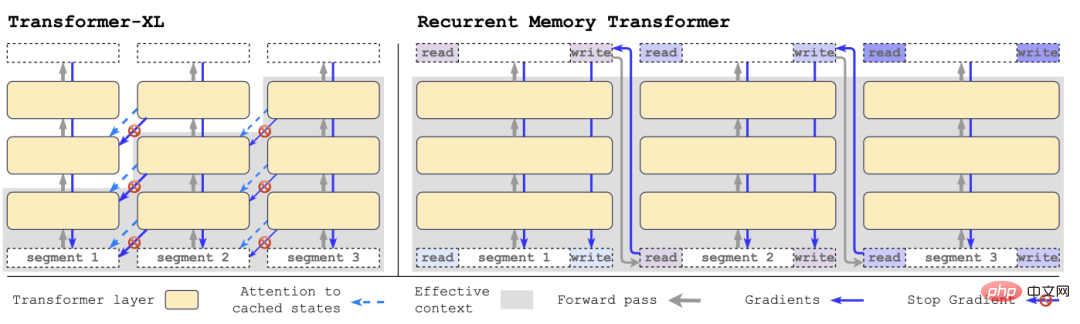
Plus précisément, RMT se compose de m vecteurs entraînables à valeur réelle. La séquence d'entrée trop longue est divisée en plusieurs segments. Le vecteur mémoire est prédéfini pour l'intégration du premier segment et combiné avec les jetons de segment. .
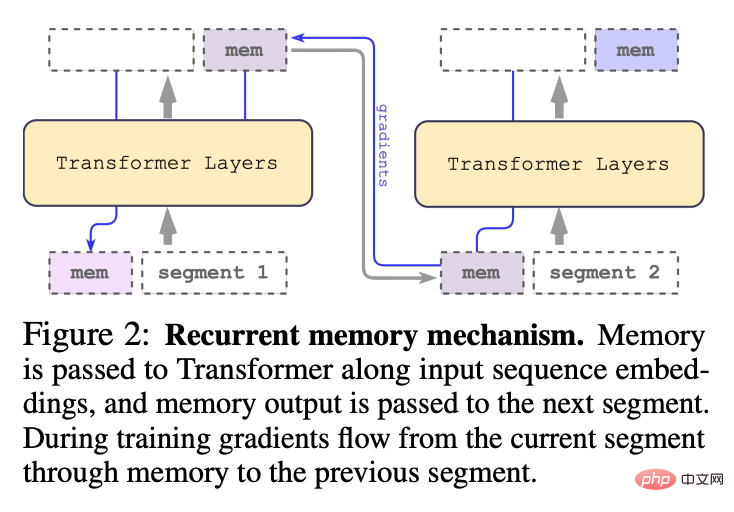
Différent du modèle RMT original proposé en 2022, pour les modèles d'encodeurs purs comme BERT, la mémoire n'est ajoutée qu'une seule fois au début du segment ; le modèle de décodage divise la mémoire en parties de lecture et d'écriture.
Dans chaque pas de temps et segment, bouclez comme suit, où N est le nombre de couches de Transformer, t est le pas de temps et H est le segment
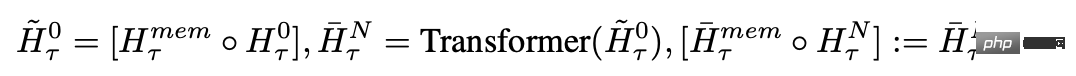
Après avoir traité les segments de la séquence d'entrée dans l'ordre, afin de réaliser une connexion récursive, les chercheurs transmettent la sortie du jeton mémoire du segment actuel à l'entrée du segment suivant :
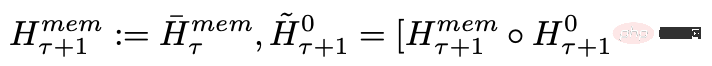
La mémoire et la boucle dans RMT sont uniquement basées sur le jeton mémoire global, qui peut conservez le modèle de base du Transformer inchangé, ce qui rend les capacités d'amélioration de la mémoire RMT compatibles avec n'importe quel modèle de Transformer.
Efficacité informatique
Selon la formule, les FLOP requis pour les modèles RMT et Transformer de différentes tailles et longueurs de séquence peuvent être estimés
Recherche sur la configuration des paramètres de taille du vocabulaire, nombre de couches, taille cachée, taille cachée intermédiaire et nombre de têtes d'attention.Nous avons suivi la configuration du modèle OPT et calculé le nombre de FLOP après la passe avant, en tenant compte de l'impact du cycle RMT.
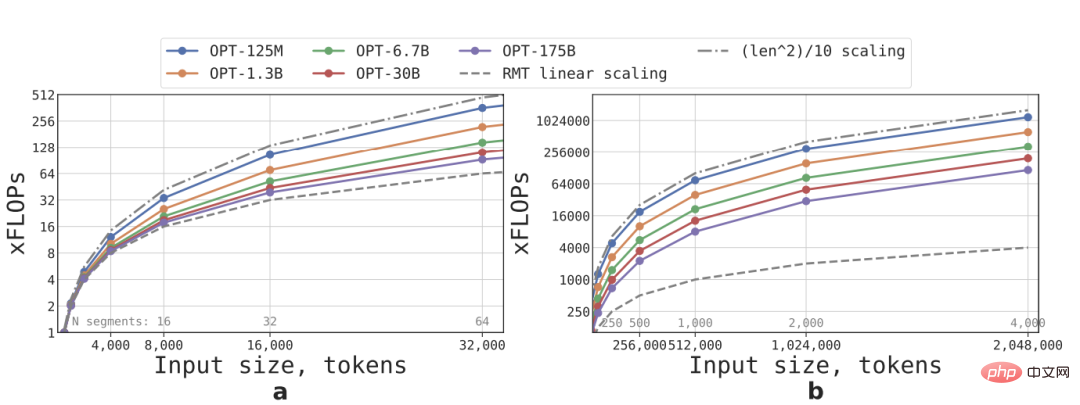
L'expansion linéaire est obtenue en divisant une séquence d'entrée en plusieurs segments et en calculant toutes les matrices d'attention uniquement dans les limites du segment. Les résultats peuvent voir que si la longueur du segment est fixe, la vitesse d'inférence du RMT est meilleure. pour n’importe quelle taille de modèle. Tous grandissent de manière linéaire.
En raison de la grande quantité de calculs de la couche FFN, les modèles Transformer plus grands ont tendance à montrer un taux de croissance quadratique plus lent par rapport à la longueur de la séquence. Cependant, sur les séquences extrêmement longues d'une longueur supérieure à 32 000, les FLOP reviennent au statut de croissance quadratique. .
Pour les séquences comportant plus d'un segment (plus de 512 dans cette étude), le RMT a des FLOP inférieurs à ceux du modèle acyclique et peut augmenter l'efficacité des FLOP jusqu'à × 295 fois sur des modèles de plus petite taille ; modèles Les grands modèles tels que l'OPT-175B peuvent être améliorés de 29 fois.
Tâche de mémoire
Pour tester les capacités de mémoire, les chercheurs ont construit un ensemble de données synthétiques qui nécessitait que le modèle mémorise des faits simples et des raisonnements de base.
La saisie des tâches consiste en un ou plusieurs faits et une question à laquelle on ne peut répondre qu'avec tous ces faits.
Pour augmenter la difficulté de la tâche, un texte en langage naturel qui n'est pas lié à la question ou à la réponse est également ajouté à la tâche. Ces textes peuvent être considérés comme du bruit, la tâche du modèle est donc en fait de séparer les faits des faits. le texte non pertinent et utilisez le texte des faits pour répondre à la question.

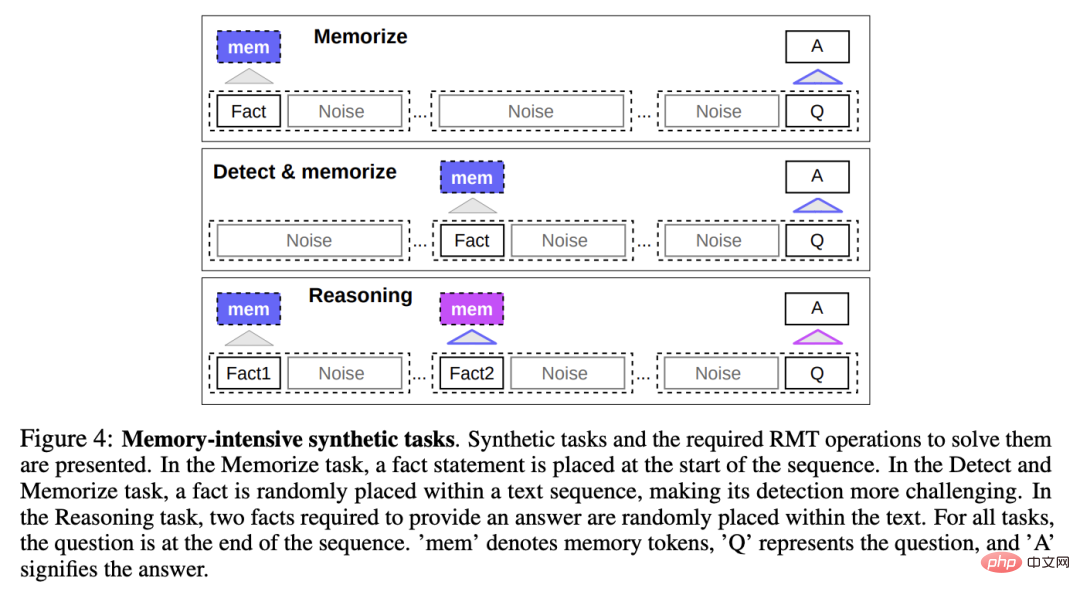
Mémoire des faits
Teste la capacité du RMT à écrire et stocker des informations en mémoire pendant de longues périodes : dans le cas le plus simple, les faits sont au début de la saisie, les questions sont au début fin de la saisie, et augmentez progressivement la quantité de texte non pertinent entre les questions et les réponses jusqu'à ce que le modèle ne puisse pas accepter toutes les saisies en même temps.

Détection des faits et mémoire
La détection des faits augmente la difficulté de la tâche en déplaçant le fait vers une position aléatoire dans l'entrée, obligeant le modèle à d'abord distinguer le fait du texte non pertinent et à l'écrire en mémoire, puis répondez à la question à la fin.
Raisonnement basé sur des faits mémorisés
Une autre opération importante de la mémoire consiste à raisonner en utilisant des faits mémorisés et le contexte actuel.
Pour évaluer cette fonctionnalité, les chercheurs ont introduit une tâche plus complexe dans laquelle deux faits sont générés et placés aléatoirement dans la séquence d'entrée ; une question posée à la fin de la séquence doit être choisie pour répondre à la question avec le fait correct.

Résultats expérimentaux
Les chercheurs ont utilisé le modèle pré-entraîné à base de Bert dans HuggingFace Transformers comme épine dorsale du RMT dans toutes les expériences, et tous les modèles ont été améliorés avec une taille de mémoire de 10.
Entraînez-vous et évaluez sur 4 à 8 GPU NVIDIA 1080Ti ; pour des séquences plus longues, passez à un seul NVIDIA A100 de 40 Go pour une évaluation accélérée.
Curriculum Learning
Les chercheurs ont observé que l'utilisation de la planification de la formation peut améliorer considérablement la précision et la stabilité de la solution.
Commencez simplement la formation RMT sur une version plus courte de la tâche. Une fois la formation converge, augmentez la durée de la tâche en ajoutant un segment et continuez le processus d'apprentissage du cours jusqu'à ce que la longueur d'entrée idéale soit atteinte.
Démarrez l'expérience avec une séquence qui correspond à un seul segment. La taille réelle du segment est de 499 car 3 jetons spéciaux de BERT et 10 espaces réservés de mémoire sont conservés de l'entrée du modèle, ce qui donne une taille totale de 512.
On peut remarquer qu'après un entraînement sur des tâches plus courtes, le RMT est plus facile à résoudre des tâches plus longues car il converge vers une solution parfaite en utilisant moins d'étapes d'entraînement.
Capacités d'extrapolation
Afin d'observer la capacité de généralisation du RMT à différentes longueurs de séquence, les chercheurs ont évalué des modèles entraînés sur différents nombres de segments pour résoudre des tâches de plus grandes longueurs.
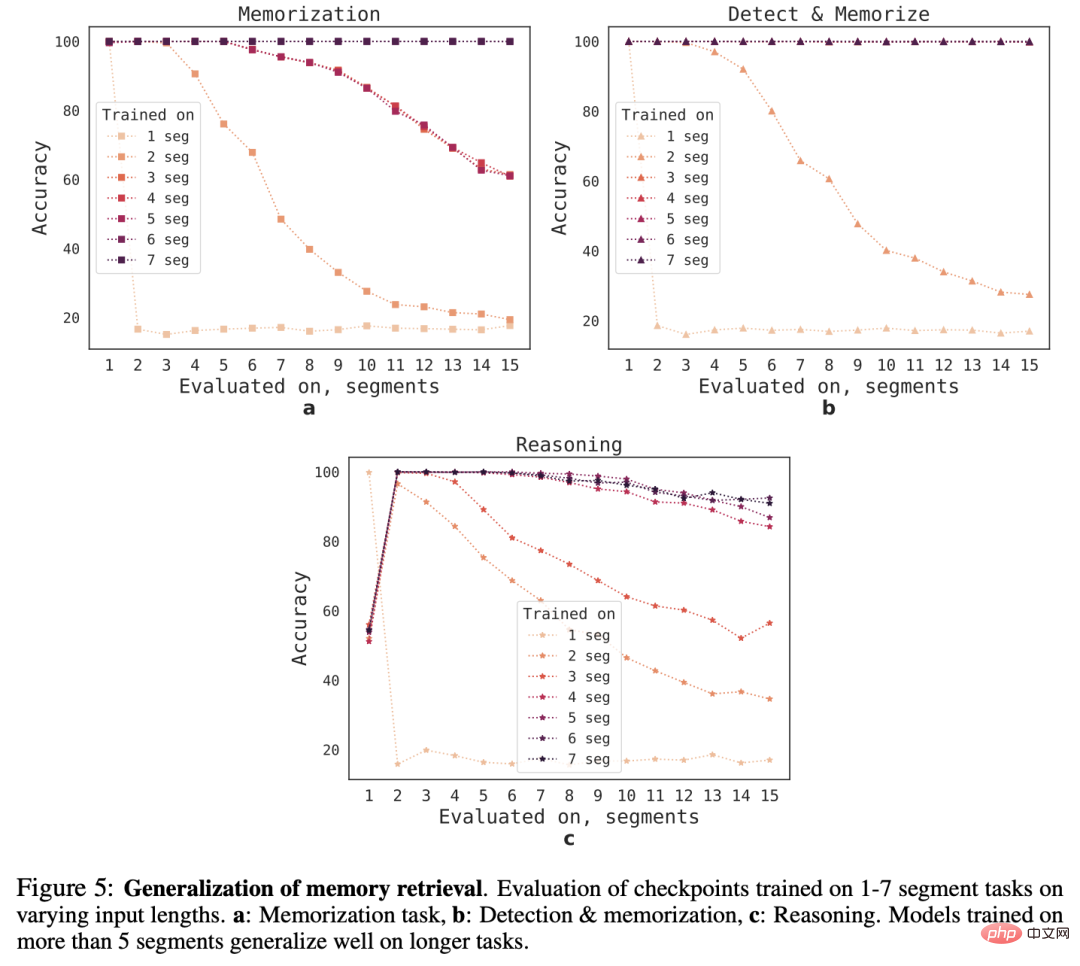
On peut observer que le modèle fonctionne souvent bien sur des tâches plus courtes, mais après avoir entraîné le modèle sur des séquences plus longues, il devient difficile de gérer des tâches d'inférence sur un seul segment.
Une explication possible est que, comme la taille de la tâche dépasse un segment, le modèle cesse d'anticiper le problème dans le premier segment, ce qui entraîne une baisse de qualité.
Fait intéressant, à mesure que le nombre de segments d'entraînement augmente, la capacité de généralisation du RMT sur des séquences plus longues apparaît également. Après un entraînement sur 5 segments ou plus, le RMT peut effectuer près de deux fois plus de temps sur des tâches de généralisation parfaite.
Pour tester la limite de généralisation, les chercheurs ont augmenté la taille de la tâche de vérification à 4096 segments (soit 2 043 904 tokens).
RMT résiste étonnamment bien sur des séquences aussi longues, parmi lesquelles la tâche « détection et mémoire » est la plus simple et la tâche d'inférence est la plus complexe.
Référence : https://www.php.cn/link/459ad054a6417248a1166b30f6393301
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI