
Maison >Périphériques technologiques >IA >La nouvelle mise à niveau mPLUG-Owl d'Alibaba offre le meilleur des deux mondes, et la collaboration modale permet le nouveau SOTA de MLLM
La nouvelle mise à niveau mPLUG-Owl d'Alibaba offre le meilleur des deux mondes, et la collaboration modale permet le nouveau SOTA de MLLM

- 王林avant
- 2024-01-11 18:33:09747parcourir
OpenAI GPT-4V et Google Gemini ont démontré de très fortes capacités de compréhension multimodale et ont favorisé le développement rapide de grands modèles multimodaux (MLLM) qui est devenu la direction de recherche la plus en vogue du secteur.
MLLM a atteint une excellente capacité d’instruction dans une variété de tâches ouvertes visuo-linguistiques. Bien que des recherches antérieures sur l'apprentissage multimodal aient montré que différentes modalités peuvent collaborer et se promouvoir mutuellement, les recherches MLLM existantes se concentrent principalement sur l'amélioration de la capacité des tâches multimodales et sur la manière d'équilibrer les avantages de la collaboration modale et l'impact de l'interférence modale. il faut s'en occuper.

Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/pdf/2311.04257.pdf
Veuillez consulter l'adresse de code suivante : https://github.com/X -PLUG/mPLUG -Owl/tree/main/mPLUG-Owl2
Adresse de l'expérience ModelScope : https://modelscope.cn/studios/damo/mPLUG-Owl2/summary
Lien de l'adresse de l'expérience HuggingFace : https : //huggingface.co/spaces/MAGAer13/mPLUG-Owl2
En réponse à ce problème, le grand modèle multimodal mPLUG-Owl d'Alibaba a reçu une mise à niveau majeure. Grâce à la collaboration modale, il améliore simultanément les performances du texte brut et de la multimodalité, surpassant LLaVA1.5, MiniGPT4, Qwen-VL et d'autres modèles, et obtient les meilleures performances dans une variété de tâches. Plus précisément, mPLUG-Owl2 utilise des modules fonctionnels partagés pour promouvoir la collaboration entre différentes modalités et introduit un module d'adaptation modale pour conserver les caractéristiques de chaque modalité. Avec une conception simple et efficace, mPLUG-Owl2 atteint les meilleures performances dans plusieurs domaines, notamment le texte brut et les tâches multimodales. L'étude des phénomènes de coopération modale fournit également une source d'inspiration pour le développement de futurs grands modèles multimodaux
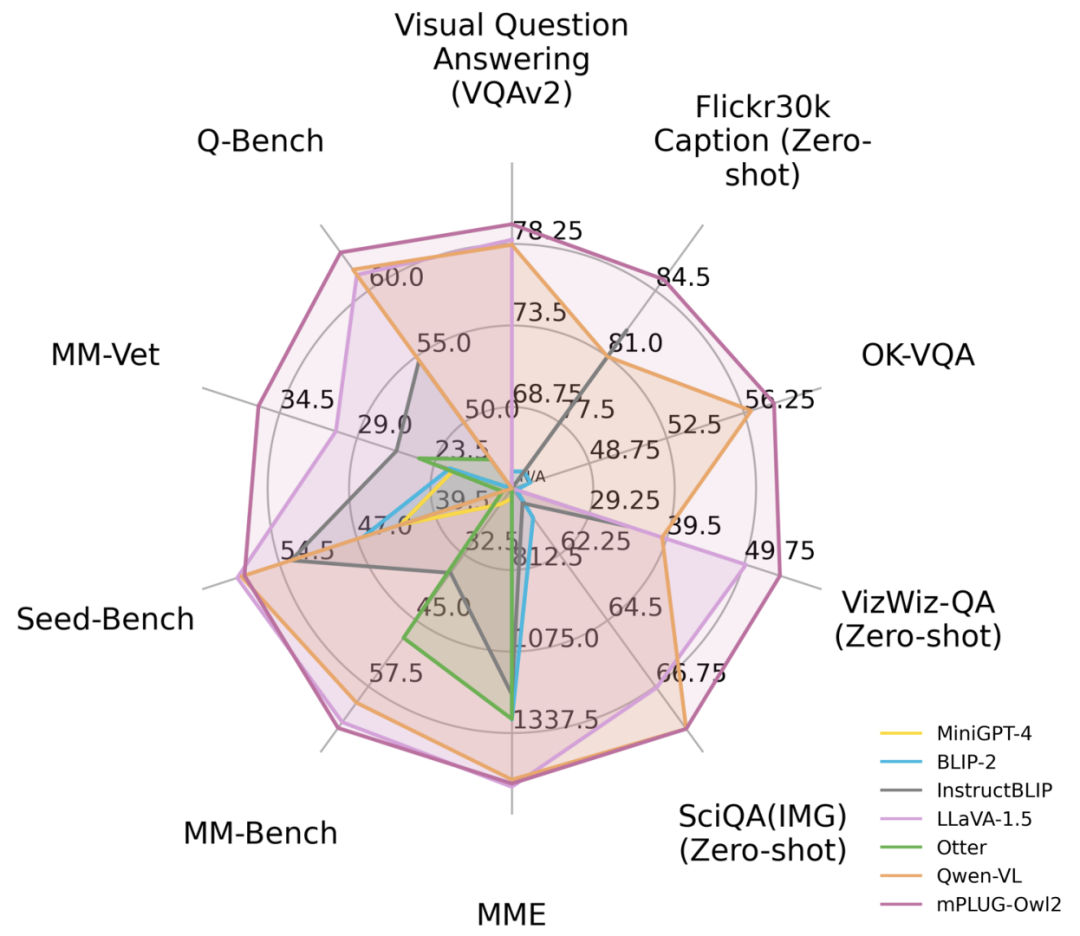
Figure 1 Comparaison des performances avec les modèles MLLM existants
Introduction à la méthode Afin d'atteindre l'objectif de ne pas changer le sens original, le contenu doit être réécrit en chinois
Le modèle mPLUG-Owl2 se compose principalement de trois parties :
Encodeur visuel : utilisation de ViT-L/14 comme visuel encodeur, la résolution d'entrée. Une image avec un taux de H x W est convertie en une séquence de jetons visuels de H/14 x W/14 et entrée dans Visual Abstractor.
Visual Extractor : extrait les fonctionnalités sémantiques de haut niveau en apprenant un ensemble de requêtes disponibles tout en réduisant la longueur de la séquence visuelle du modèle de langage d'entrée
Modèle de langage : LLaMA-2-7B est utilisé comme décodeur de texte, et conçu le module d'adaptation modale comme le montre la figure 3.
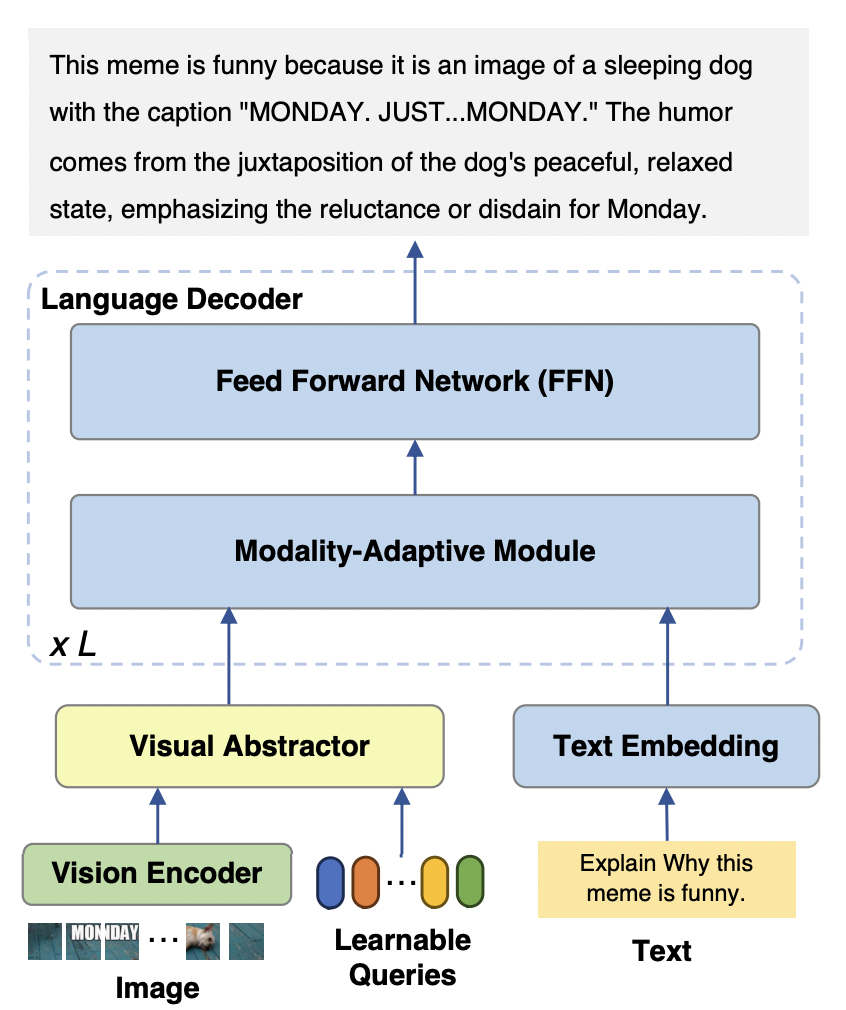
Figure 2 Structure du modèle mPLUG-Owl2
Afin d'aligner les modalités visuelles et linguistiques, les travaux existants mappent généralement les caractéristiques visuelles dans l'espace sémantique du texte. Cependant, cette approche ignore les caractéristiques respectives. L'utilisation d'informations visuelles et textuelles peut affecter les performances du modèle en raison de l'inadéquation de la granularité sémantique. Pour résoudre ce problème, cet article propose un module adaptatif aux modalités (MAM) pour mapper les caractéristiques visuelles et textuelles dans un espace sémantique partagé, tout en découplant les représentations visuo-linguistiques pour conserver les propriétés uniques de chaque modalité.
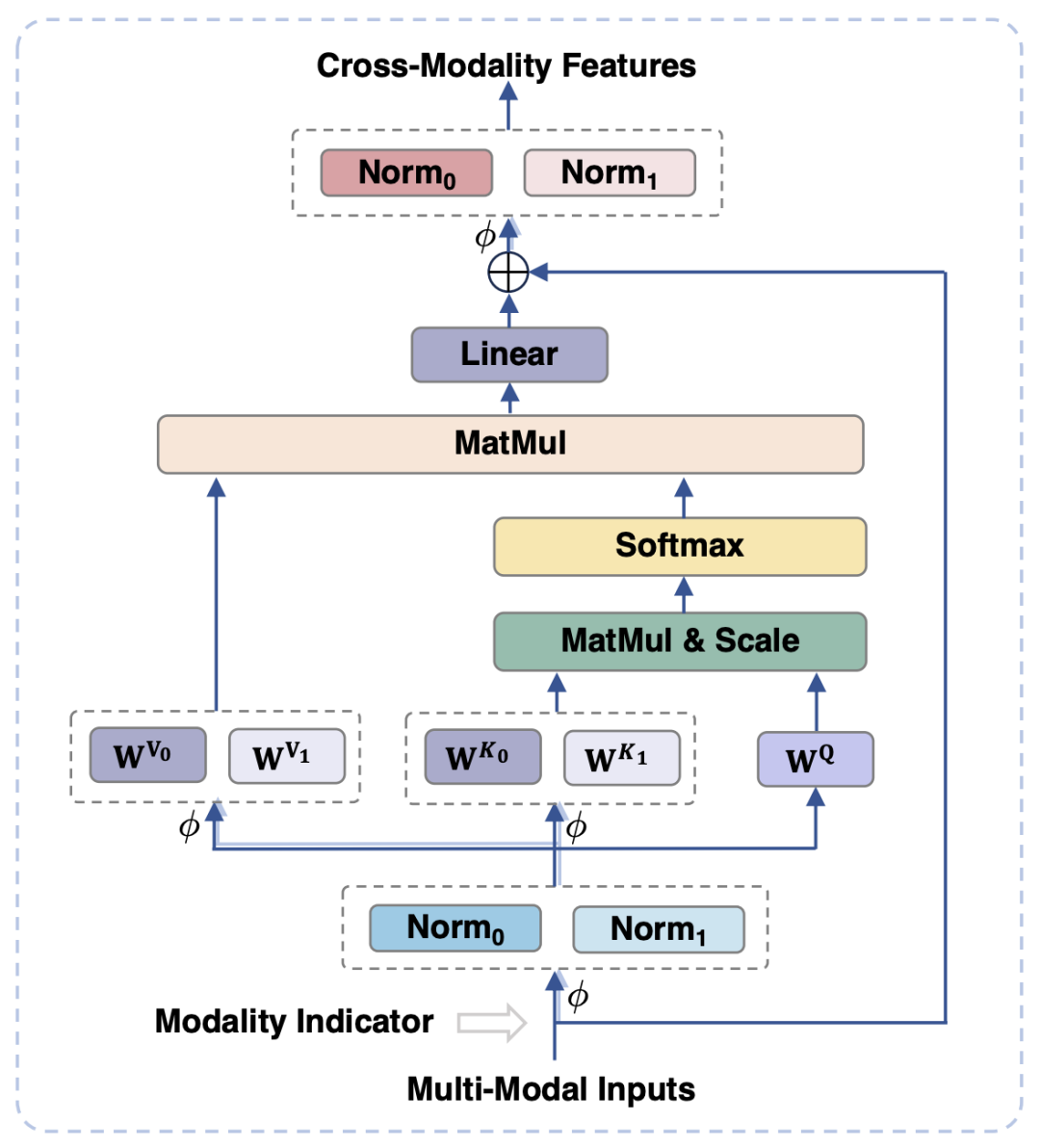
La figure 3 montre le diagramme schématique du module d'adaptation modale
Ce qui est montré dans la figure 3 est que, par rapport au transformateur traditionnel, la conception principale du module d'adaptation modale est :
-
Dans les étapes d'entrée et de sortie du module, les opérations LayerNorm sont effectuées respectivement sur les modalités visuelles et linguistiques pour s'adapter aux distributions de fonctionnalités respectives des deux modalités.
Dans l'opération d'auto-attention, des matrices de projection de clé et de valeur distinctes sont utilisées pour les modalités visuelles et linguistiques, mais une matrice de projection de requête partagée est utilisée en découplant ainsi les matrices de projection de clé et de valeur. la granularité sémantique peut être obtenue, évitant les interférences entre les deux modes.
En partageant le même FFN, les deux modalités peuvent favoriser la collaboration entre elles
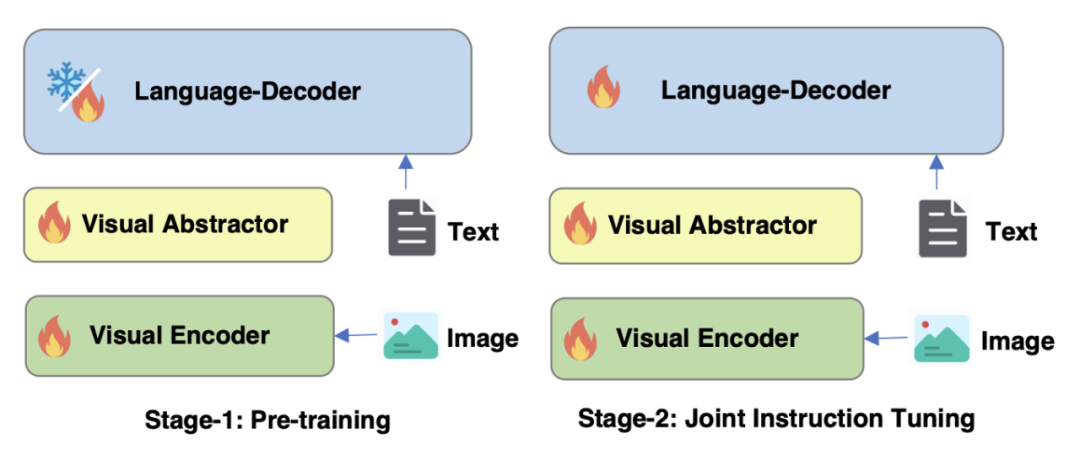
Optimisation de la stratégie de formation de la Figure 4 mPLUG-Owl2
Comme le montre la figure 4, la formation de mPLUG-Owl2 comprend deux étapes : la pré-formation et la mise au point de l'instruction. L'étape de pré-formation consiste principalement à réaliser l'alignement de l'encodeur visuel et du modèle de langage. À ce stade, le Visual Encoder et le Visual Abstractor peuvent être entraînés, et dans le modèle de langage, seuls les poids du modèle liés au visuel ajoutés par la modalité. Le module adaptatif est traité. Au cours de l'étape de réglage fin des instructions, tous les paramètres du modèle sont affinés en fonction du texte et des données d'instructions multimodales (comme le montre la figure 5) pour améliorer la capacité de suivi des instructions du modèle.
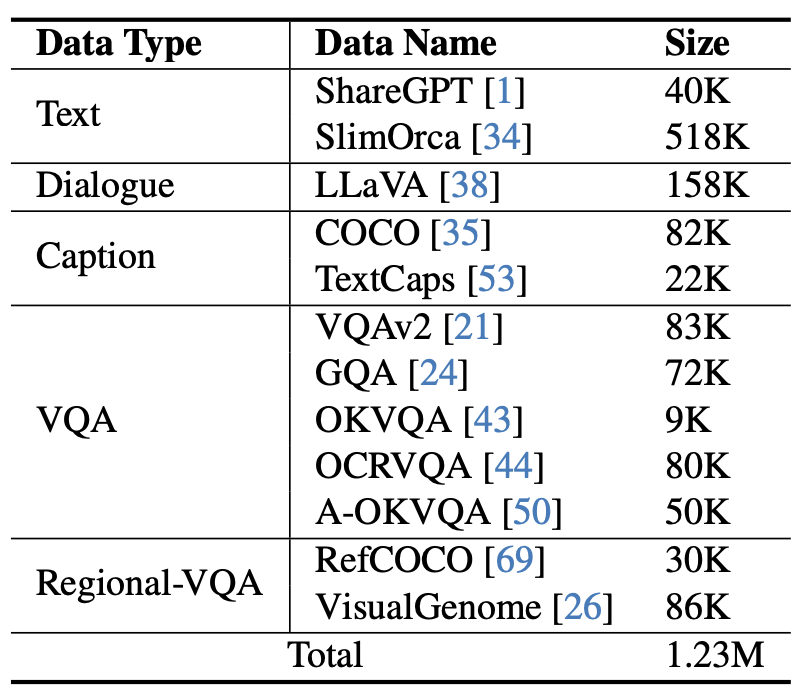
Figure 5 Données de réglage fin des instructions utilisées par mPLUG-Owl2
Expériences et résultats
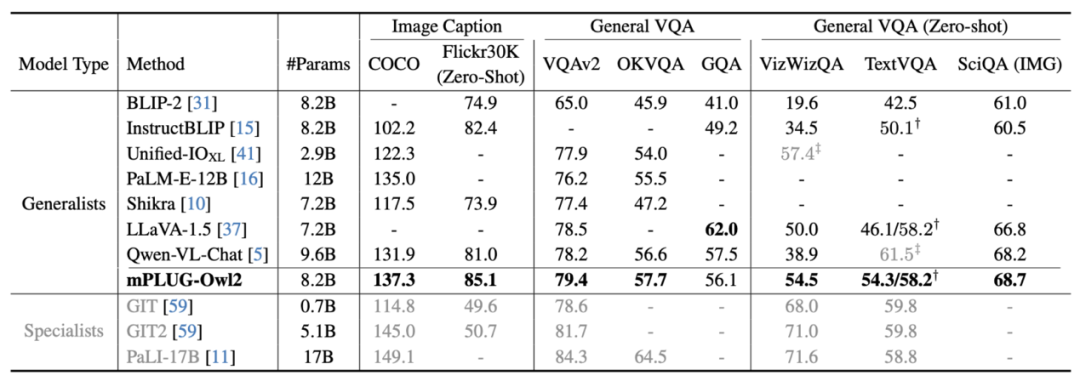
Figure 6 Description de l'image et performance des tâches VQA 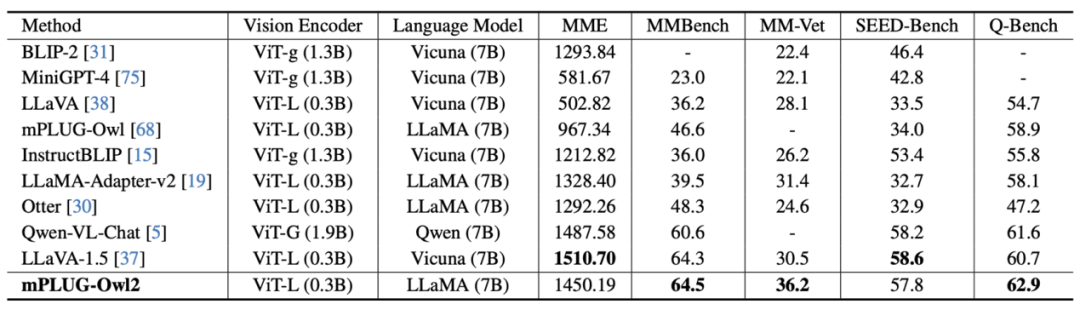
Image 7 Les performances du benchmark MLLM
sont présentées dans les figures 6 et 7, qu'il s'agisse de description d'image traditionnelle, de VQA et d'autres tâches de langage visuel, ou de MMBench, Q-Bench et d'autres ensembles de données de référence pour les grands projets multimodaux. Les modèles mPLUG-Owl2 atteignent tous de meilleures performances que les travaux existants.
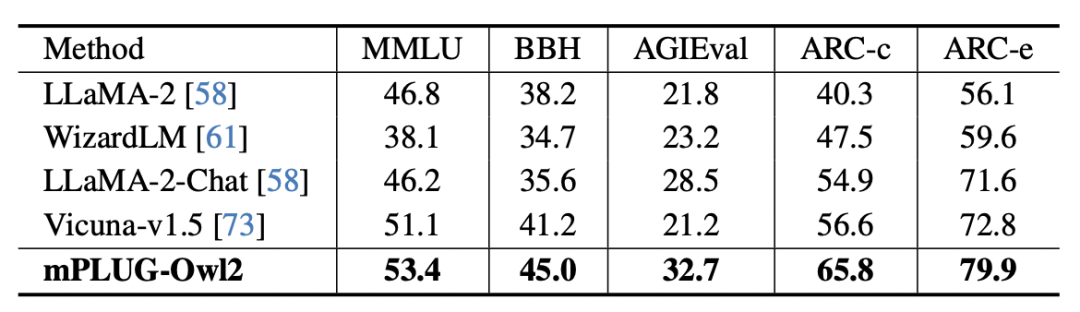
Figure 8 Performances du benchmark en texte pur
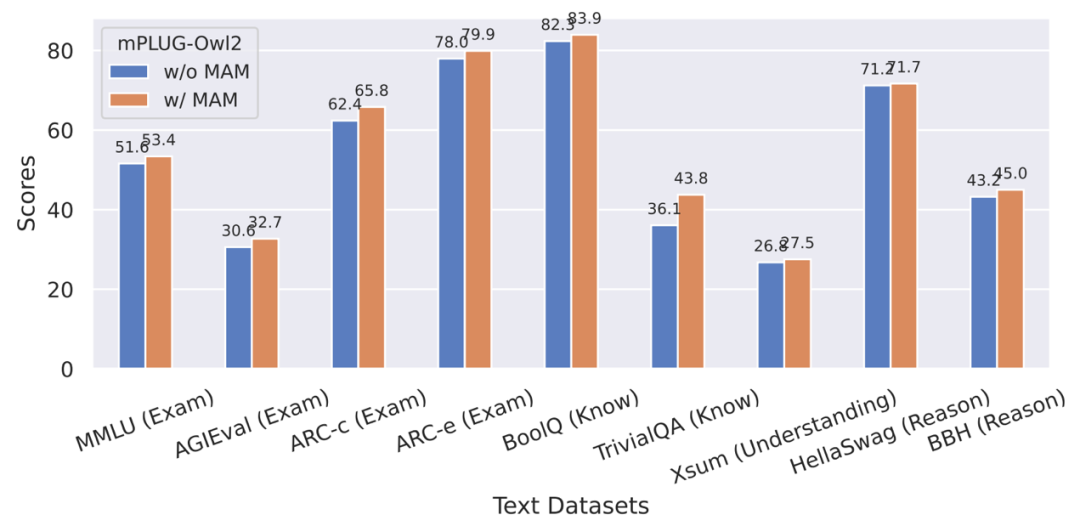
Figure 9 Impact du module d'adaptation de modalité sur les performances des tâches en texte pur
De plus, afin d'évaluer l'impact de la collaboration modale sur les tâches de texte pur Concernant l'impact des tâches de texte, les auteurs ont également testé les performances de mPLUG-Owl2 dans la compréhension et la génération du langage naturel. Comme le montre la figure 8, mPLUG-Owl2 atteint de meilleures performances par rapport aux autres LLM à réglage fin. La figure 9 montre les performances sur la tâche de texte brut. On peut voir que puisque le module d'adaptation modale favorise la collaboration modale, les capacités d'examen et de connaissance du modèle ont été considérablement améliorées. L'auteur analyse que cela est dû au fait que la collaboration multimodale permet au modèle d'utiliser des informations visuelles pour comprendre des concepts difficiles à décrire dans le langage, et améliore la capacité de raisonnement du modèle grâce à la richesse des informations contenues dans l'image, et renforce indirectement la capacité de raisonnement de le texte.


mPLUG-Owl2 démontre d'excellentes capacités de compréhension multimodale et atténue avec succès les hallucinations multimodales. Cette technologie multimodale a été appliquée aux produits principaux de Tongyi tels que Tongyi Stardust et Tongyi Zhiwen, et a été vérifiée dans la démo ouverte ModelScope et HuggingFace
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Renforcez l'industrie de la mode grâce à la technologie et aidez le district de Futian à construire un « centre de siège social de la mode dans la région de la Baie »
- En mettant l'accent sur le changement et la persévérance, Web3 et l'IA remodèlent le dialogue organisé au sommet de l'industrie cinématographique
- Xiaoyu Yilian est apparue à l'Exposition internationale de l'industrie intelligente de Chine
- Zhipu AI a coopéré avec Tsinghua KEG pour lancer un grand modèle multimodal open source appelé CogVLM-17B
- Comment les robots collaboratifs peuvent-ils permettre la fabrication intelligente et la modernisation de l'industrie chimique quotidienne ? Écoutez ce que disent les experts