
Maison >Périphériques technologiques >IA >Zhipu AI a coopéré avec Tsinghua KEG pour lancer un grand modèle multimodal open source appelé CogVLM-17B
Zhipu AI a coopéré avec Tsinghua KEG pour lancer un grand modèle multimodal open source appelé CogVLM-17B

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-10-12 11:41:011513parcourir
Builder News le 12 octobre, récemment, Zhipu AI et Tsinghua KEG ont publié et directement open source le grand modèle multimodal-CogVLM-17B dans la communauté Moda. Il est rapporté que CogVLM est un puissant modèle de langage visuel open source qui utilise le module expert visuel pour intégrer profondément le codage linguistique et le codage visuel, et a atteint les performances SOTA sur 14 références multimodales faisant autorité.
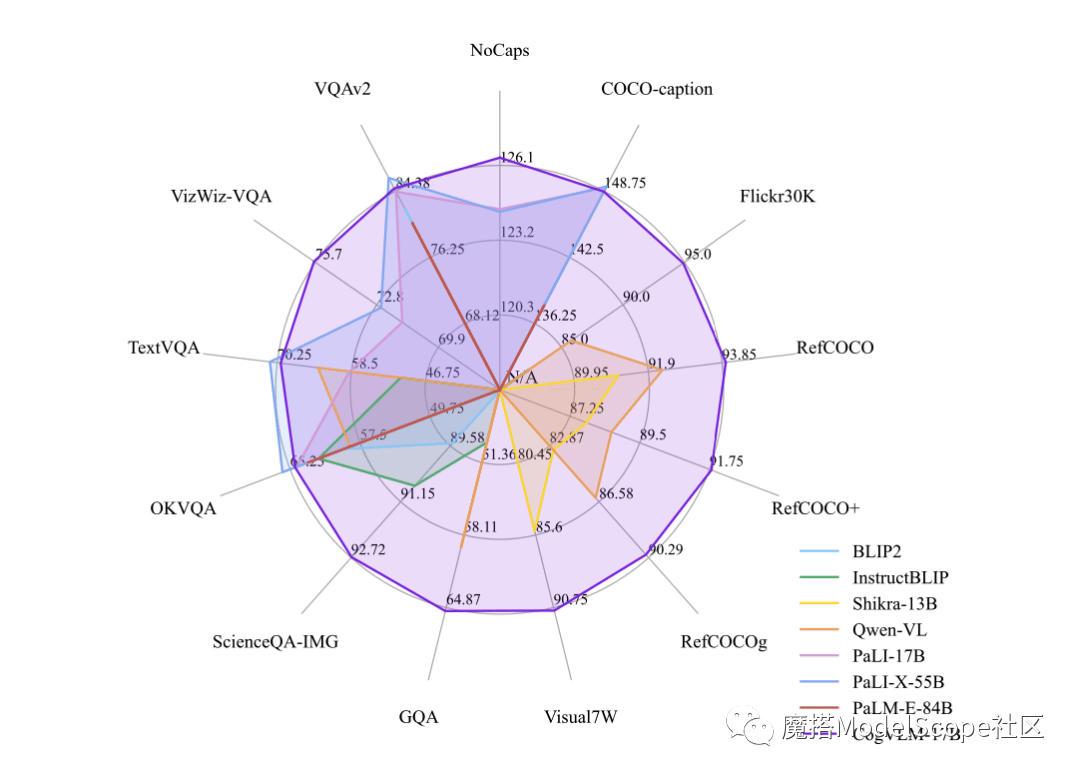
CogVLM-17B est actuellement le modèle avec la première performance complète sur la liste académique multimodale faisant autorité, et a obtenu les résultats les plus avancés ou la deuxième place sur 14 ensembles de données. L'effet de CogVLM dépend de l'idée de « priorité visuelle », c'est-à-dire de donner à la compréhension visuelle une priorité plus élevée dans les modèles multimodaux. Il utilise un encodeur visuel de paramètres 5B et un module expert visuel de paramètres 6B, avec un total de paramètres 11B pour modéliser les caractéristiques de l'image, encore plus que les paramètres 7B du texte
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- 360 a conclu une coopération stratégique avec Zhipu AI pour développer conjointement le grand modèle de langage 360GLM
- 360 et Zhipu AI ont annoncé une coopération stratégique pour développer conjointement un grand modèle de langage de 100 milliards de niveaux « 360GLM »
- Première réplique nationale du modèle R&D ChatGPT, 360 s'associe à Zhipu AI pour coopérer stratégiquement sur un grand modèle linguistique.
- 360 lancera le grand modèle de langage 360GLM de niveau 100 milliards et coopérera stratégiquement avec Zhipu AI
- Présentation des invités du Sommet technologique de Sohu 2023 Zhang Fan : Zhipu AI COO |