
Maison >Périphériques technologiques >IA >Google Deepmind envisage un avenir qui réinvente les robots, en apportant l'intelligence incarnée aux modèles à grande échelle
Google Deepmind envisage un avenir qui réinvente les robots, en apportant l'intelligence incarnée aux modèles à grande échelle

- PHPzavant
- 2024-01-09 19:49:59837parcourir
Au cours de la dernière année, des modèles successifs à grande échelle ont réalisé des percées qui remodèlent le domaine de la recherche en robotique.
Les grands modèles les plus avancés devenant le « cerveau » des robots, les robots évoluent plus vite qu'on ne l'imaginait.
En juillet, Google DeepMind a annoncé le lancement de RT-2 : le premier modèle vision-langage-action (VLA) au monde pour contrôler des robots.
Il vous suffit de donner une commande comme une conversation, et il sera capable d'identifier Swift parmi un tas d'images et de lui donner un pot d'"eau heureuse".

Il peut même penser de manière proactive, en effectuant un raisonnement en plusieurs étapes, depuis la « sélection d'un animal en vue de l'extinction » jusqu'à la saisie d'un dinosaure en plastique sur la table.

Après RT-2, Google DeepMind a proposé Q-Transformer, et le monde de la robotique a également son propre Transformer. Q-Transformer permet aux robots de ne plus dépendre de données de démonstration de haute qualité et de mieux accumuler de l'expérience en s'appuyant sur une « réflexion » indépendante.
Deux mois seulement après sa sortie, RT-2 offre un autre moment ImageNet pour les robots. Google DeepMind et d'autres institutions ont lancé Open new ideas.
Imaginez simplement donner à votre robot assistant une simple demande, telle que « nettoyer la maison » ou « préparer un repas délicieux et sain », et il peut accomplir ces tâches. Pour les humains, ces tâches peuvent être simples, mais pour les robots, elles nécessitent une compréhension approfondie du monde, ce qui n’est pas facile. Sur la base d'années de recherche dans le domaine des robots Transformers, Google a récemment annoncé une série de progrès dans la recherche sur les robots : AutoRT, SARA-RT et RT-Trajectory, qui peuvent aider les robots à prendre des décisions plus rapidement et à mieux les comprendre. Quel type d'environnement vous sont présents peuvent mieux vous guider pour accomplir la tâche. Google estime qu'avec le lancement de résultats de recherche tels qu'AutoRT, SARA-RT et RT-Trajectory, il peut apporter des améliorations aux capacités de collecte de données, de vitesse et de généralisation des robots du monde réel. Ensuite, passons en revue ces études importantes.AutoRT : utilisez de grands modèles pour mieux entraîner les robots
AutoRT combine de grands modèles de base (tels que les grands modèles de langage (LLM) ou les modèles de langage visuel (VLM)) et des modèles de contrôle de robot (RT-1 ou RT-2) , créant un système capable de déployer des robots dans de nouveaux environnements pour collecter des données de formation. AutoRT peut guider simultanément plusieurs robots équipés de caméras vidéo et d’effecteurs finaux pour effectuer diverses tâches dans divers environnements. Plus précisément, chaque robot utilisera un modèle de langage visuel (VLM) pour « regarder autour de lui » et comprendre son environnement et les objets dans son champ de vision, basé sur AutoRT. Ensuite, le grand modèle de langage lui proposera une série de tâches créatives, telles que « mettre des collations sur la table », et jouera le rôle de décideur, en choisissant les tâches que le robot devra effectuer. Les chercheurs ont mené une évaluation approfondie de sept mois d'AutoRT dans le monde réel. Des expériences ont prouvé que le système AutoRT peut coordonner en toute sécurité jusqu'à 20 robots en même temps, et un maximum de 52 robots au total. En guidant les robots pour qu'ils effectuent diverses tâches dans divers immeubles de bureaux, les chercheurs ont collecté un ensemble de données diversifié couvrant 77 000 essais de robots avec 6 650 tâches uniques.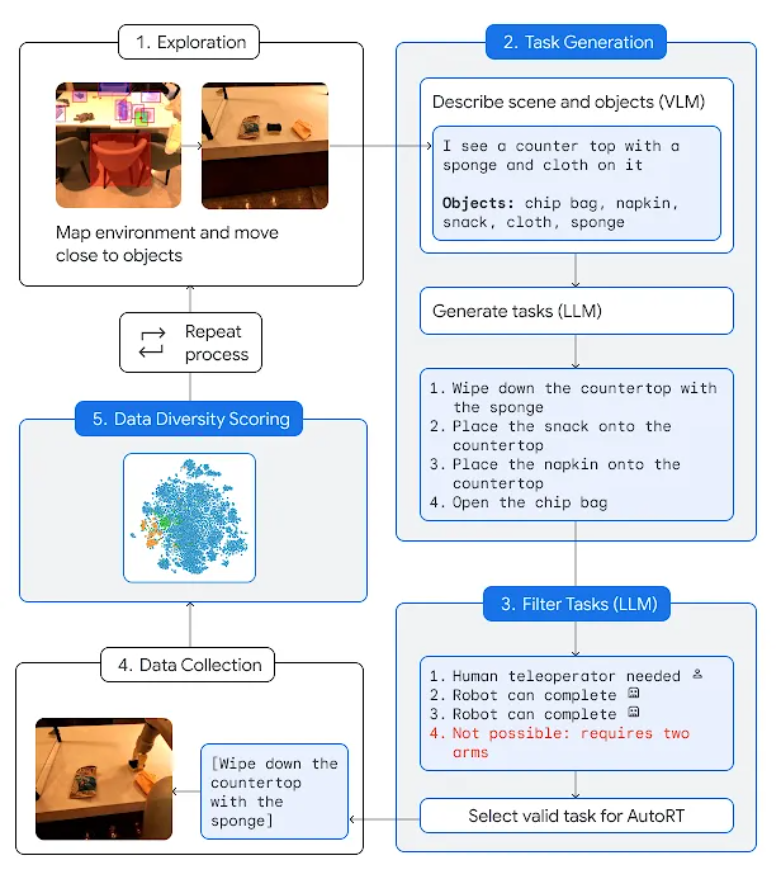
Bien qu'AutoRT ne soit désormais qu'un système de collecte de données, considérez-le comme les premières étapes des robots autonomes dans le monde réel. Il comporte des garde-corps de sécurité, dont l'un est un ensemble de mots d'invite axés sur la sécurité qui fournissent des règles de base à suivre lorsque le robot prend des décisions basées sur le LLM.
Ces règles sont en partie inspirées des Trois lois de la robotique d'Isaac Asimov, dont la plus importante est qu'un robot "ne doit pas nuire à un être humain". Les règles de sécurité imposent également aux robots de ne pas tenter de tâches impliquant des humains, des animaux, des objets tranchants ou des appareils électriques.
Le simple fait de travailler sur les mots d'invite ne peut pas garantir complètement les problèmes de sécurité dans l'application réelle du robot. Par conséquent, le système AutoRT comprend également une couche de mesures de sécurité pratiques qui constituent une conception classique de la robotique. Par exemple, les robots collaboratifs sont programmés pour s'arrêter automatiquement si les forces exercées sur leurs articulations dépassent un seuil donné, et tous les robots contrôlés de manière autonome peuvent être limités à la ligne de mire d'un superviseur humain via un interrupteur de désactivation physique.
SARA-RT : Rendre le robot Transformer (RT) plus rapide et plus léger
Une autre réalisation, SARA-RT, peut convertir le modèle de robot Transformer (RT) en une version plus efficace.
L'architecture de réseau neuronal RT développée par l'équipe Google a été utilisée dans les derniers systèmes de contrôle de robots, y compris le modèle RT-2. Le meilleur modèle SARA-RT-2 est 10,6 % plus précis et 14 % plus rapide que le modèle RT-2 lorsqu'on lui donne un bref historique des images. Google affirme qu'il s'agit du premier mécanisme d'attention évolutif qui augmente la puissance de calcul sans compromettre la qualité.
Bien que les Transformers soient puissants, ils peuvent être limités par les exigences informatiques, ce qui ralentit la prise de décision. Transformer s'appuie principalement sur le module d'attention de complexité quadratique. Cela signifie que si l'entrée du modèle RT est doublée (par exemple, en fournissant au robot des capteurs plus nombreux ou de plus haute résolution), les ressources informatiques requises pour traiter cette entrée sont multipliées par quatre, ce qui ralentit la prise de décision.
SARA-RT adopte une nouvelle méthode de réglage fin du modèle (appelée « up-training ») pour améliorer l'efficacité du modèle. La formation convertit la complexité quadratique en complexité purement linéaire, réduisant considérablement les exigences de calcul. Cette conversion améliore non seulement la vitesse du modèle original, mais maintient également sa qualité.
Google espère que de nombreux chercheurs et praticiens appliqueront ce système pratique à la robotique et à d'autres domaines. Étant donné que SARA fournit une approche générale pour accélérer les Transformers sans nécessiter une pré-formation coûteuse en termes de calcul, cette approche a le potentiel de faire évoluer la technologie Transformer à grande échelle. SARA-RT ne nécessite aucun codage supplémentaire car diverses variantes linéaires open source sont disponibles.
Lorsque SARA-RT est appliqué au modèle SOTA RT-2 avec des milliards de paramètres, il permet une prise de décision plus rapide et de meilleures performances dans une variété de tâches robotiques :

pour la manipulation SARA-RT-2 modèle de mission. Les actions du robot sont conditionnées par des images et des instructions textuelles.
Grâce à sa solide base théorique, SARA-RT peut être appliqué à différents modèles de Transformer. Par exemple, l'application de SARA-RT au Point Cloud Transformer, qui traite les données spatiales de la caméra de profondeur d'un robot, peut plus que doubler la vitesse.
RT-Trajectory : Aider les robots à généraliser
Les humains peuvent intuitivement comprendre et apprendre à nettoyer les tables, mais les robots ont besoin de nombreuses façons possibles pour traduire les instructions en actions physiques réelles.
Traditionnellement, l'entraînement des bras robotiques repose sur la mise en correspondance d'un langage naturel abstrait (essuyer la table) avec des actions concrètes (fermer la pince, bouger à gauche, bouger à droite), ce qui rend difficile la généralisation du modèle à de nouvelles tâches. En revanche, le modèle RT-Trajectory permet au modèle RT de comprendre « comment » une tâche est accomplie en interprétant des actions spécifiques du robot (telles que celles d'une vidéo ou d'un croquis).
Le modèle RT-Trajectory peut ajouter automatiquement des contours visuels pour décrire les mouvements du robot dans les vidéos de formation. RT-Trajectory superpose chaque vidéo de l'ensemble de données de formation avec un croquis de trajectoire 2D de la pince pendant que le bras du robot effectue une tâche. Ces trajectoires, sous forme d'images RVB, fournissent des repères visuels pratiques de bas niveau permettant au modèle d'apprendre les stratégies de contrôle du robot.
Lorsqu'il a été testé sur 41 tâches non visibles dans les données d'entraînement, le bras robot contrôlé par RT-Trajectory a plus que doublé les performances du modèle SOTA RT existant : le taux de réussite des tâches a atteint 63 %, tandis que le RT-2 a un taux de réussite de seulement 29 %.
Le système est très polyvalent, RT-Trajectory peut également créer des trajectoires en regardant des démonstrations humaines des tâches requises, et accepte même des croquis dessinés à la main. De plus, il peut s’adapter à tout moment à différentes plateformes robotiques.
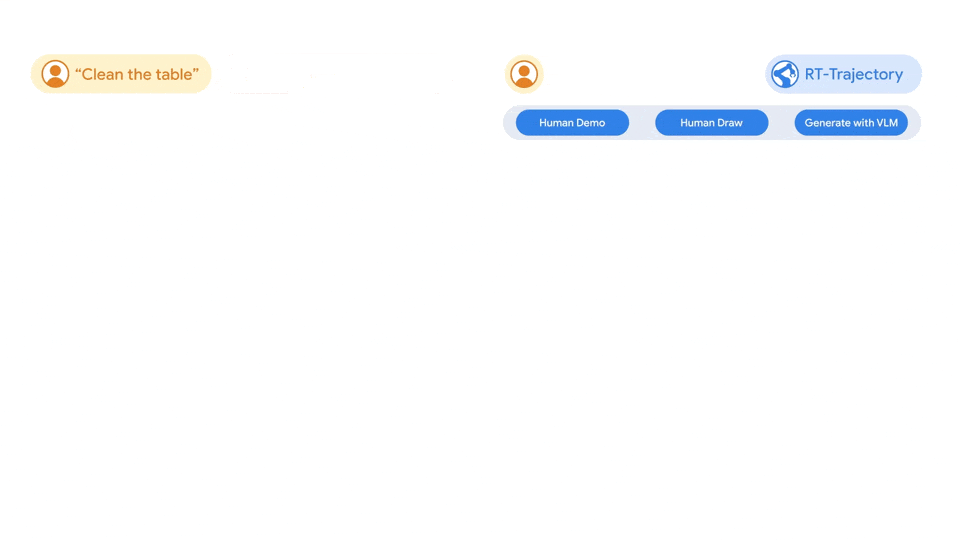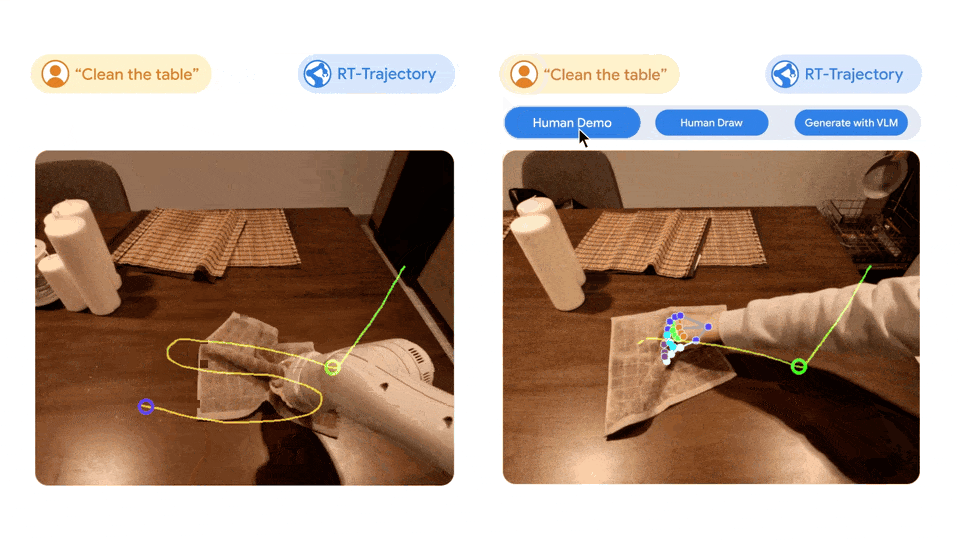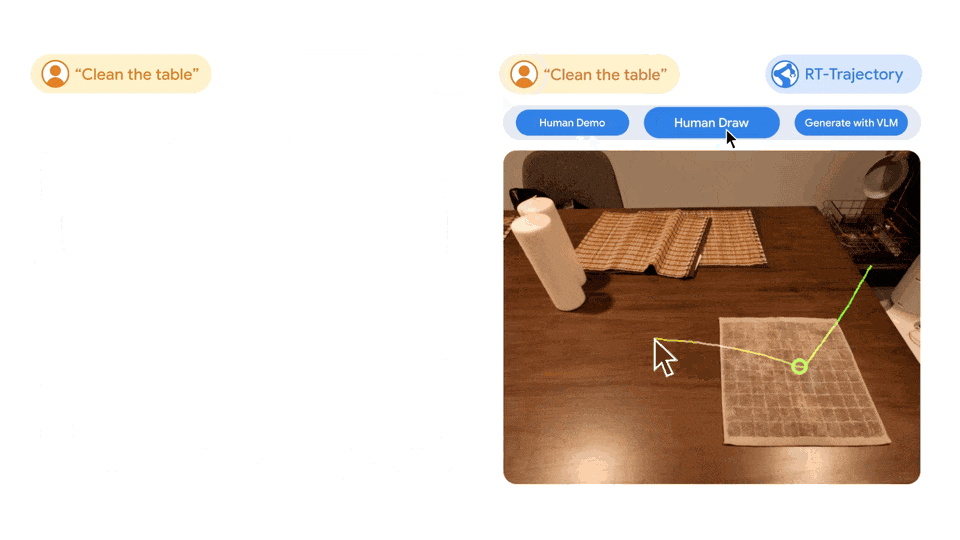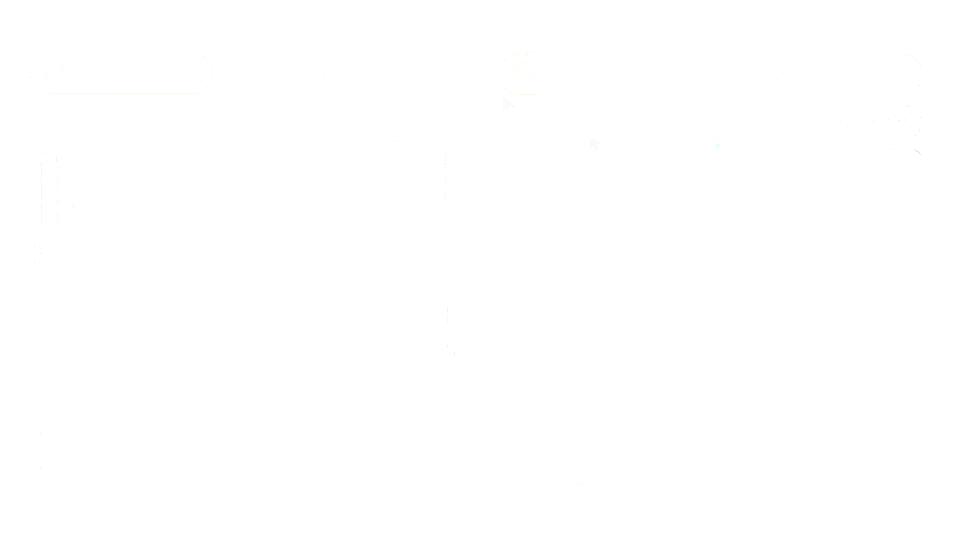 Image de gauche : Le robot contrôlé par le modèle RT entraîné uniquement à l'aide de l'ensemble de données en langage naturel a été frustré lors de l'exécution de la nouvelle tâche consistant à effacer la table, tandis que le robot contrôlé par le modèle de trajectoire RT effectué sur le même ensemble de données a été amélioré. par trajectoires 2D Après la formation, la trajectoire d’essuyage a été planifiée et exécutée avec succès. À droite : un modèle de trajectoire RT entraîné, chargé d'une nouvelle tâche (essuyer une table), peut créer des trajectoires 2D de différentes manières, avec l'assistance humaine ou seul à l'aide d'un modèle de langage visuel.
Image de gauche : Le robot contrôlé par le modèle RT entraîné uniquement à l'aide de l'ensemble de données en langage naturel a été frustré lors de l'exécution de la nouvelle tâche consistant à effacer la table, tandis que le robot contrôlé par le modèle de trajectoire RT effectué sur le même ensemble de données a été amélioré. par trajectoires 2D Après la formation, la trajectoire d’essuyage a été planifiée et exécutée avec succès. À droite : un modèle de trajectoire RT entraîné, chargé d'une nouvelle tâche (essuyer une table), peut créer des trajectoires 2D de différentes manières, avec l'assistance humaine ou seul à l'aide d'un modèle de langage visuel.
Les trajectoires RT exploitent les riches informations sur les mouvements du robot qui sont présentes dans tous les ensembles de données de robot mais qui sont actuellement sous-utilisées. RT-Trajectory représente non seulement une autre étape sur la voie de la création de robots qui se déplacent de manière efficace et précise pour de nouvelles tâches, mais permet également la découverte de connaissances à partir d'ensembles de données existants.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Article vedette|La demande de puissance de calcul explose sous le boom des grands modèles d'IA : Lingang veut construire une industrie de plusieurs dizaines de milliards, et SenseTime sera le « maître de la chaîne »
- Pour aider au développement de l'industrie Yuanverse, ce concours d'applications innovantes de communication mobile a été lancé
- Exploration de l'application du langage Go dans l'industrie automobile intelligente
- Ministère de l'Industrie et des Technologies de l'information : l'industrie de base de l'IA en Chine atteint 500 milliards de yuans, et plus de 2 500 ateliers numériques et usines intelligentes ont été construits
- Le Forum général de développement de l'industrie des grands modèles d'intelligence artificielle et la cérémonie de dévoilement de la zone du cluster industriel des grands modèles d'intelligence artificielle générale dans le district de Shijingshan se sont déroulés avec succès.