
Maison >Périphériques technologiques >IA >La nouvelle méthode de l'Université Tsinghua localise avec succès des clips vidéo précis ! SOTA a été surpassé et open source
La nouvelle méthode de l'Université Tsinghua localise avec succès des clips vidéo précis ! SOTA a été surpassé et open source

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-09 15:26:221312parcourir
Avec une seule phrase de description, vous pouvez localiser le clip correspondant dans une grande vidéo !
Par exemple, en décrivant "une personne buvant de l'eau en descendant les escaliers", grâce à la correspondance d'images vidéo et de pas, la nouvelle méthode peut trouver instantanément les horodatages de début et de fin correspondants :

Même "en riant" Même ceux dont la sémantique est difficile à comprendre peuvent être positionnés avec précision :

La méthode s'appelle Adaptive Dual-Branch Promoting Network (ADPN) et a été proposée par l'équipe de recherche de l'Université Tsinghua.
Plus précisément, ADPN est utilisé pour effectuer une tâche intermodale visuo-linguistique appelée positionnement de clip vidéo (Temporal Sentence Grounding, TSG), qui consiste à localiser les clips pertinents de la vidéo en fonction du texte de la requête.
ADPN se caractérise par sa capacité à utiliser efficacement la cohérence et la complémentarité des modalités visuelles et audio dans les vidéos pour améliorer les performances de positionnement des clips vidéo.
Par rapport à d'autres travaux TSG PMI-LOC et UMT qui utilisent l'audio, la méthode ADPN a obtenu des améliorations de performances plus significatives par rapport au mode audio et a remporté un nouveau SOTA dans plusieurs tests.
Actuellement, ce travail a été accepté par ACM Multimedia 2023 et est entièrement open source.

Jetons un coup d'œil à ce qu'est ADPN~
Positionnement de clips vidéo dans une phrase
Positionnement de clips vidéo (Temporal Sentence Grounding, TSG) est une tâche intermodale visuo-linguistique importante.
Son objectif est de trouver les horodatages de début et de fin des segments qui leur correspondent sémantiquement dans une vidéo non éditée basée sur des requêtes en langage naturel. Cela nécessite que la méthode ait de fortes capacités de raisonnement multimodal temporel.
Cependant, la plupart des méthodes TSG existantes ne prennent en compte que les informations visuelles de la vidéo, telles que RVB, flux optique(flux optiques), profondeur(profondeur), etc., tout en ignorant les informations audio accompagnant naturellement la vidéo. .
Les informations audio contiennent souvent une sémantique riche et sont cohérentes et complémentaires avec les informations visuelles. Comme le montre la figure ci-dessous, ces propriétés aideront la tâche TSG.
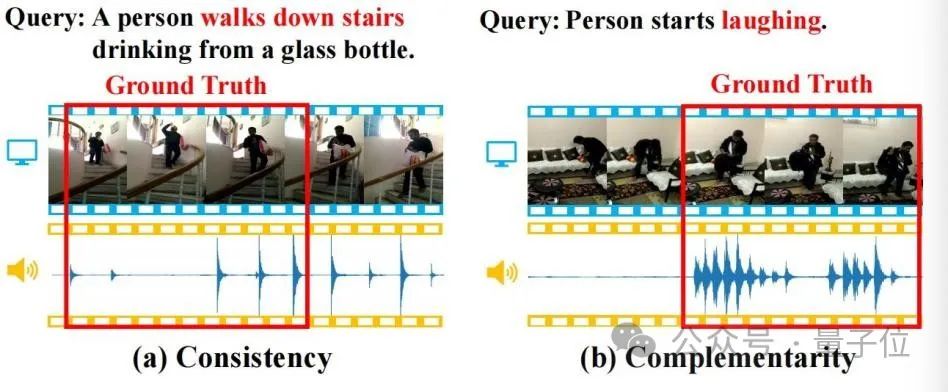
△Figure 1
(a) Cohérence : l'image vidéo et les pas correspondent systématiquement à la sémantique de « descendre les escaliers » dans la requête (b) Complémentarité : l'image vidéo est difficile à identifier ; comportement pour localiser le sens sémantique de « rire » dans la requête, mais la présence du rire fournit un indice de positionnement complémentaire fort.
Les chercheurs ont donc étudié en profondeur la tâche de localisation de clips vidéo améliorée par l'audio (Audio-enhanced Temporal Sentence Grounding, ATSG), dans le but de mieux capturer les indices de localisation à partir des modalités visuelles et audio. Cependant, le mode audio L'introduction de. Les modalités apportent également les défis suivants :
- La cohérence et la complémentarité des modalités audio et visuelles sont associées au texte de la requête, donc capturer la cohérence et la complémentarité audiovisuelles nécessite de modéliser les trois modes d'interaction avec état texte-visuel-audio.
- Il existe des différences modales significatives entre l'audio et la vision. La densité de l'information et l'intensité du bruit des deux sont différentes, ce qui affectera les performances de l'apprentissage audiovisuel.
Pour résoudre les défis ci-dessus, les chercheurs ont proposé une nouvelle méthode ATSG « Adaptive Dual-branch Prompted Network » (Adaptive Dual-branch Prompted Network, ADPN).
Grâce à une conception de structure de modèle à double branche, cette méthode peut modéliser de manière adaptative la cohérence et la complémentarité entre l'audio et la vision, et éliminer davantage le bruit modal audio à l'aide d'une stratégie d'optimisation du débruitage basée sur les interférences d'apprentissage de cours, révélant l'importance des signaux audio pour la vidéo. récupération.
La structure globale de l'ADPN est présentée dans la figure ci-dessous :
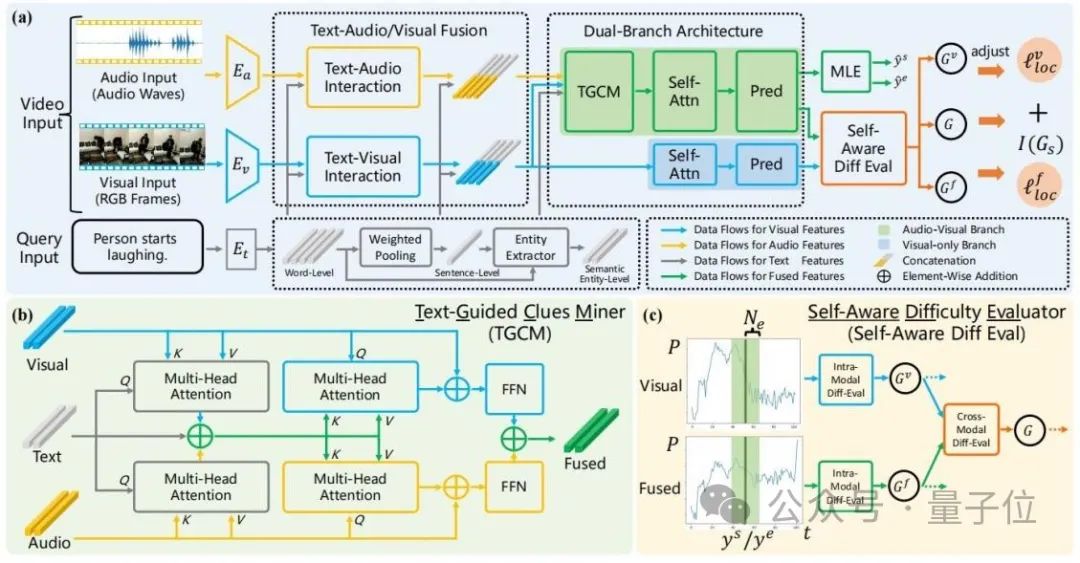
△ Figure 2 : Schéma général du réseau de promotion adaptatif à double branche (ADPN)
Il comprend principalement trois conceptions :
1. conception de la structure du réseau
Étant donné que le bruit de l'audio est plus évident et que pour les tâches TSG, l'audio contient généralement plus d'informations redondantes, de sorte que le processus d'apprentissage des modalités audio et visuelles doit avoir une importance différente, cet article implique donc une double branche La structure du réseau utilise l'audio et la vision pour l'apprentissage multimodal tout en améliorant les informations visuelles.
Plus précisément, en référence à la figure 2(a), ADPN entraîne simultanément une branche (branche visuelle) qui utilise uniquement des informations visuelles et une branche (branche conjointe) qui utilise à la fois des informations visuelles et des informations audio.
Les deux branches ont des structures similaires, dans lesquelles la branche commune ajoute une unité d'exploration d'indices guidée par texte (TGCM) pour modéliser l'interaction modale texte-visuel-audio. Au cours du processus de formation, les deux branches mettent à jour les paramètres en même temps et la phase d'inférence utilise le résultat de la branche commune comme résultat de prédiction du modèle.
2. Text-Guided Clues Miner (Text-Guided Clues Miner, TGCM)
Considérant que la cohérence et la complémentarité des modalités audio et visuelles sont basées sur la requête textuelle donnée, les chercheurs ont donc conçu l'unité TGCM. modéliser l’interaction entre les trois modalités texte-visuel-audio.
Reportez-vous à la figure 2(b), le TGCM est divisé en deux étapes : « extraction » et « propagation ».
Tout d'abord, le texte est utilisé comme condition de requête, et les informations associées sont extraites et intégrées des modalités visuelles et audio ; ensuite les modalités visuelles et audio sont utilisées comme condition de requête, et les informations intégrées sont diffusées vers le visuel et modes audio par l'attention. Leurs modalités respectives sont enfin fusionnées via FFN.
3. Stratégie d'optimisation de l'apprentissage du programme
Les chercheurs ont observé que l'audio contient du bruit, ce qui affectera l'effet de l'apprentissage multimodal, ils ont donc utilisé l'intensité du bruit comme référence pour un échantillon de difficulté et ont introduit l'apprentissage du programme (Curriculum Learning, CL) Débruitez le processus d'optimisation, reportez-vous à la figure 2(c).
Ils évaluent la difficulté de l'échantillon en fonction de la différence dans la sortie prévue des deux branches. Ils pensent qu'un échantillon trop difficile a une forte probabilité d'indiquer que son audio contient trop de bruit et n'est pas adapté à l'échantillon. Tâche TSG, de sorte que la perte du processus de formation est basée sur le score d'évaluation de la difficulté de l'échantillon. Les termes de fonction sont repondérés pour éliminer les mauvais gradients causés par le bruit dans l'audio.
(Veuillez vous référer au texte original pour le reste de la structure du modèle et les détails de la formation.)
Tests multiples New SOTA
Les chercheurs ont mené des évaluations expérimentales sur les ensembles de données de référence Charades-STA et ActivityNet Légendes du TSG tâche et comparée à la méthode de base. La comparaison est présentée dans le tableau 1.
La méthode ADPN peut atteindre des performances SOTA ; en particulier, par rapport à d'autres travaux TSG PMI-LOC et UMT qui utilisent l'audio, la méthode ADPN obtient des améliorations de performances plus significatives de la modalité audio, indiquant que la méthode ADPN utilise la modalité audio pour promouvoir la supériorité du TSG.
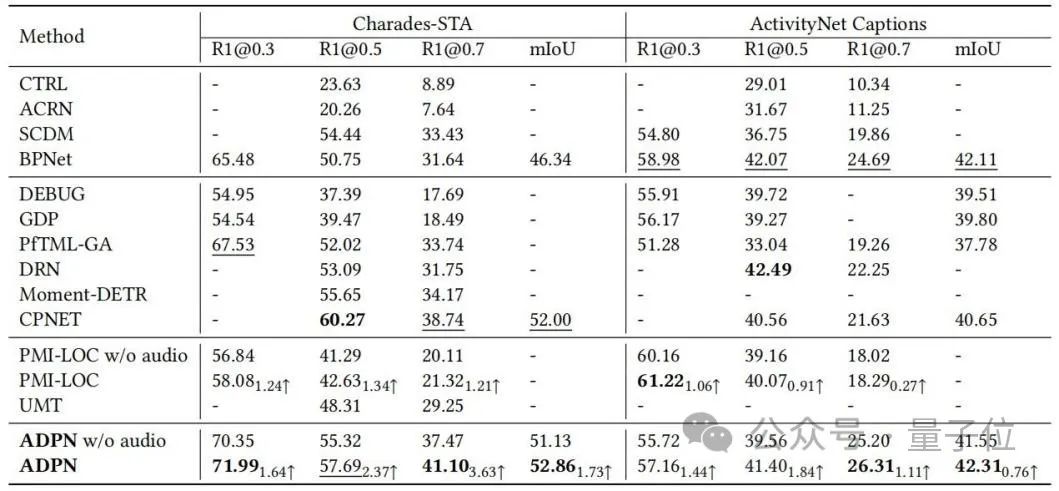
△Tableau 1 : Résultats expérimentaux sur Charades-STA et ActivityNet Captions
Les chercheurs ont en outre démontré l'efficacité de différentes unités de conception dans ADPN grâce à des expériences d'ablation, comme le montre le tableau 2.
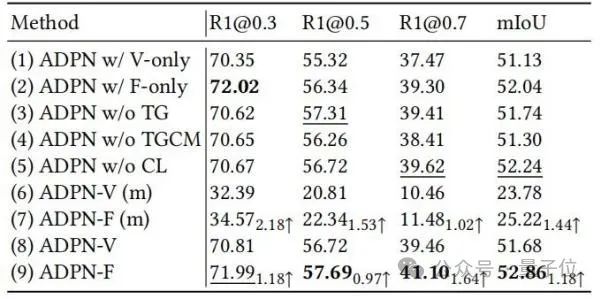
△Tableau 2 : Expérience d'ablation sur Charades-STA
Les chercheurs ont sélectionné les résultats de prédiction de certains échantillons pour la visualisation et ont dessiné le « texte en vision » (T → V) lors de l'étape « d'extraction » dans TGCM ) et la distribution du poids d'attention « texte en audio » (T → A), comme le montre la figure 3.
On peut observer que l'introduction de la modalité audio améliore les résultats de prédiction. Dans le cas de « La personne en rit », nous pouvons voir que la répartition du poids d'attention de T→A est plus proche de la vérité terrain, ce qui corrige l'orientation erronée de la prédiction du modèle par la répartition du poids de T→V.
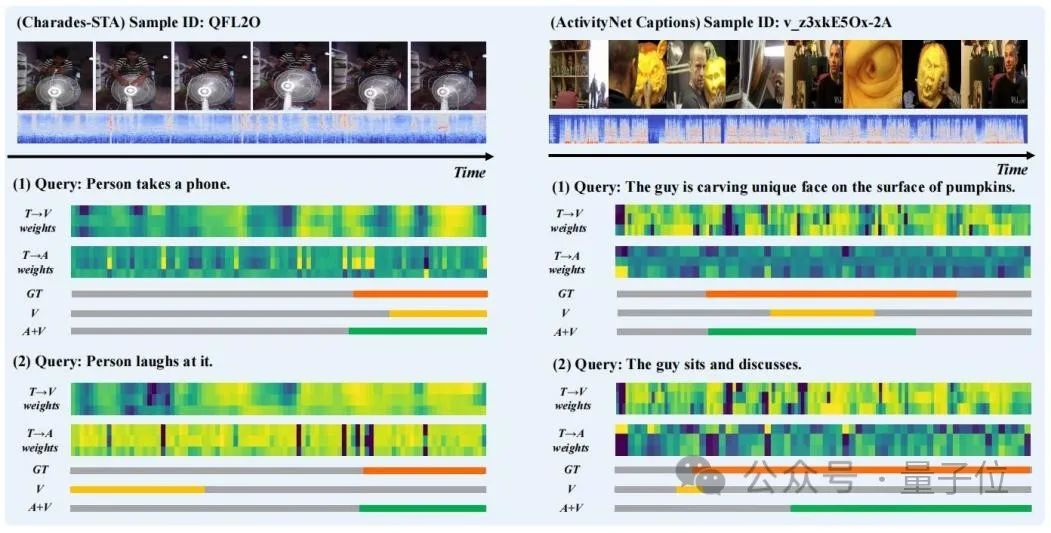
△ Figure 3 : Présentation de cas
En résumé, les chercheurs de cet article ont proposé un nouveau réseau adaptatif de facilitation à double branche (ADPN) pour résoudre la localisation de clips vidéo améliorée par l'audio (ATSG) Question.
Ils ont conçu une structure modèle à deux branches pour former conjointement la branche visuelle et la branche commune audiovisuelle afin de résoudre la différence d'information entre les modalités audio et visuelles.
Ils ont également proposé une unité d'exploration d'indices guidée par texte (TGCM) qui utilise la sémantique du texte comme guide pour modéliser l'interaction texte-audiovisuel.
Enfin, les chercheurs ont conçu une stratégie d'optimisation basée sur l'apprentissage des cours pour éliminer davantage le bruit audio, évaluer la difficulté des échantillons en tant que mesure de l'intensité du bruit de manière consciente et ajuster le processus d'optimisation de manière adaptative.
Ils ont d'abord mené une étude approfondie des caractéristiques de l'audio dans ATSG pour mieux améliorer l'effet d'amélioration des performances des modes audio.
À l'avenir, ils espèrent construire un référentiel d'évaluation plus approprié pour l'ATSG afin d'encourager des recherches plus approfondies dans ce domaine.
Lien papier : https://dl.acm.org/doi/pdf/10.1145/3581783.3612504
Lien entrepôt : https://github.com/hlchen23/ADPN-MM
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment insérer une vidéo à lecture automatique dans une page en utilisant HTML5
- Comment résoudre le problème de l'absence de la barre d'attributs en haut de l'IA ?
- Quel logiciel peut être utilisé pour ouvrir et modifier les fichiers ai ?
- Quels sont les logiciels d'application de vidéos courtes ?
- Pourquoi ne puis-je pas télécharger et enregistrer des vidéos sur Douyin ?