
Maison >Périphériques technologiques >IA >LLM apprend à se battre et le modèle de base peut ouvrir la voie à l'innovation de groupe
LLM apprend à se battre et le modèle de base peut ouvrir la voie à l'innovation de groupe

- 王林avant
- 2024-01-08 19:34:011226parcourir
Il y a une compétence d'arts martiaux unique dans les romans d'arts martiaux de Jin Yong : les combats à gauche et à droite. C'était un art martial créé par Zhou Botong qui a pratiqué durement dans une grotte de l'île Peach Blossom pendant plus de dix ans. se battre entre la main gauche et la main droite pour son propre divertissement. Cette idée peut non seulement être utilisée pour pratiquer les arts martiaux, mais également pour former des modèles d’apprentissage automatique, tels que le Generative Adversarial Network (GAN) qui a fait fureur ces dernières années.
À l’ère actuelle des grands modèles (LLM), les chercheurs ont découvert l’utilisation subtile de l’interaction gauche-droite. Récemment, l'équipe de Gu Quanquan de l'Université de Californie à Los Angeles a proposé une nouvelle méthode appelée SPIN (Self-Play Fine-Tuning). Cette méthode peut améliorer considérablement les capacités de LLM uniquement grâce au jeu autonome sans utiliser de données de réglage supplémentaires. Le professeur Gu Quanquan a déclaré : « Il vaut mieux apprendre à quelqu'un à pêcher que de lui apprendre à pêcher : grâce au réglage fin du jeu automatique (SPIN), tous les grands modèles peuvent être améliorés de faible à fort
! Cette recherche est également diffusée sur les réseaux sociaux. Elle a suscité de nombreuses discussions. Par exemple, le professeur Ethan Mollick de la Wharton School de l'Université de Pennsylvanie a déclaré : « De plus en plus de preuves montrent que l'IA ne sera pas limitée par la quantité de choses créées par l'homme. contenu disponible pour la formation. Cet article montre une fois de plus que l'utilisation de l'IA Training AI avec des données créées peut obtenir des résultats de meilleure qualité que l'utilisation uniquement de données créées par l'homme. enthousiasmés par cette méthode et attendons avec impatience son développement dans des directions connexes en 2024. Les progrès montrent de grandes attentes. Le professeur Gu Quanquan a déclaré à Machine Heart : « Si vous souhaitez entraîner un grand modèle au-delà de GPT-4, c'est une technologie qui vaut vraiment la peine d'être essayée
L'adresse papier est https://arxiv org/pdf. /2401.01335.pdf.
 Les grands modèles linguistiques (LLM) ont marqué le début d'une ère de percées dans l'intelligence artificielle générale (AGI), avec des capacités extraordinaires pour résoudre un large éventail de tâches qui nécessitent un raisonnement et une expertise complexes. Les domaines d'expertise du LLM comprennent le raisonnement mathématique/la résolution de problèmes, la génération/programmation de code, la génération de texte, la synthèse et l'écriture créative, et plus encore.
Les grands modèles linguistiques (LLM) ont marqué le début d'une ère de percées dans l'intelligence artificielle générale (AGI), avec des capacités extraordinaires pour résoudre un large éventail de tâches qui nécessitent un raisonnement et une expertise complexes. Les domaines d'expertise du LLM comprennent le raisonnement mathématique/la résolution de problèmes, la génération/programmation de code, la génération de texte, la synthèse et l'écriture créative, et plus encore.
Une avancée clé du LLM est le processus d'alignement après la formation, qui peut rendre le modèle plus conforme aux exigences, mais ce processus repose souvent sur des données coûteuses étiquetées par l'homme. Les méthodes d'alignement classiques incluent le réglage fin supervisé (SFT) basé sur des démonstrations humaines et l'apprentissage par renforcement basé sur le feedback des préférences humaines (RLHF).
Et ces méthodes d'alignement nécessitent toutes une grande quantité de données étiquetées par l'homme. Par conséquent, pour rationaliser le processus d’alignement, les chercheurs espèrent développer des méthodes de réglage précis qui exploiteront efficacement les données humaines.
C'est aussi l'objectif de cette recherche : développer de nouvelles méthodes de réglage fin afin que le modèle affiné puisse continuer à devenir plus fort, et ce processus de réglage fin ne nécessite pas l'utilisation de données étiquetées par l'homme à l'extérieur. l’ensemble des données de mise au point.
En fait, la communauté de l'apprentissage automatique s'est toujours préoccupée de la manière d'améliorer des modèles faibles en modèles forts sans utiliser de données de formation supplémentaires. Les recherches dans ce domaine remontent même à l'algorithme de boosting. Certaines études montrent également que les algorithmes d’auto-formation peuvent convertir des apprenants faibles en apprenants forts dans des modèles hybrides sans avoir besoin de données étiquetées supplémentaires. Cependant, la capacité d’améliorer automatiquement le LLM sans assistance externe est complexe et peu étudiée. Cela soulève la question suivante :
Pouvons-nous procéder à une auto-amélioration LLM sans données supplémentaires étiquetées par l'homme ?
Méthode Dans les détails techniques, nous pouvons désigner le LLM de l'itération précédente comme pθt, qui génère la réponse y' pour l'invite x dans l'ensemble de données SFT étiqueté par l'homme. Le prochain objectif est de trouver un nouveau LLM pθ{t+1} capable de distinguer la réponse y' générée par pθt de la réponse y donnée par un humain.
Ce processus peut être vu comme un processus de jeu entre deux joueurs : l'acteur principal est le nouveau LLM pθ{t+1}, dont le but est de distinguer la réponse du joueur adverse pθt de la réponse générée par l'humain ; le joueur adverse est l'ancien LLM pθt, dont la tâche est de générer des réponses aussi proches que possible de l'ensemble de données SFT étiqueté par l'homme.
Le nouveau LLM pθ{t+1} est obtenu en affinant l'ancien LLM pθt. Le processus de formation consiste à faire en sorte que le nouveau LLM pθ{t+1} ait une bonne capacité à distinguer la réponse y' générée par pθt. et la réponse donnée par les humains y. Et cet entraînement permet non seulement au nouveau LLM pθ{t+1} d'atteindre une bonne capacité de discrimination en tant que joueur principal, mais permet également au nouveau LLM pθ{t+1} de donner un meilleur alignement en tant que joueur adverse lors de l'itération suivante. Réponses de l'ensemble de données SFT. Dans l'itération suivante, le LLM pθ{t+1} nouvellement obtenu devient la réponse générée par le joueur adverse.
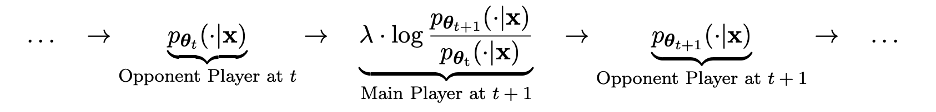

Le but de ce processus d'auto-jeu est de laisser le LLM éventuellement converger vers pθ∗=p_data, afin que la réponse générée par le LLM le plus puissant qui puisse exister ne soit plus différent de sa version précédente et des humains La réponse générée est différente.
Fait intéressant, cette nouvelle méthode présente des similitudes avec la méthode d'optimisation des préférences directes (DPO) récemment proposée par Rafailov et al., mais la différence évidente de la nouvelle méthode est l'utilisation d'un mécanisme d'auto-jeu. Cette nouvelle méthode présente donc un avantage significatif : aucune donnée supplémentaire sur les préférences humaines n’est requise.
De plus, on voit aussi clairement la similitude entre cette nouvelle méthode et le Generative Adversarial Network (GAN), sauf que le discriminateur (acteur principal) et le générateur (adversaire) dans la nouvelle méthode sont les mêmes exemples de LLM. après deux itérations adjacentes.
L'équipe a également mené une preuve théorique de cette nouvelle méthode, et les résultats ont montré que la méthode peut converger si et seulement si la distribution de LLM est égale à la distribution des données cible, c'est-à-dire p_θ_t=p_data.
Expérience
Dans l'expérience, l'équipe a utilisé une instance LLM zephyr-7b-sft-full basée sur le réglage fin de Mistral-7B.
Les résultats montrent que la nouvelle méthode peut améliorer continuellement zephyr-7b-sft-full en itérations continues. En comparaison, lorsque la méthode SFT est utilisée pour la formation continue sur l'ensemble de données SFT Ultrachat200k, le score d'évaluation atteindra la performance. Il y a même eu un déclin.
Ce qui est encore plus intéressant, c'est que l'ensemble de données utilisé par la nouvelle méthode n'est qu'un sous-ensemble de 50 000 de l'ensemble de données Ultrachat200 000 !
La nouvelle méthode SPIN a une autre réussite : elle peut améliorer efficacement le score moyen du modèle de base zephyr-7b-sft-full dans le classement HuggingFace Open LLM de 58,14 à 63,16, parmi lesquels elle peut obtenir de meilleurs résultats sur GSM8k. et TruthfulQA Une amélioration étonnante de plus de 10%, il peut également être amélioré de 5,94 à 6,78 sur MT-Bench.
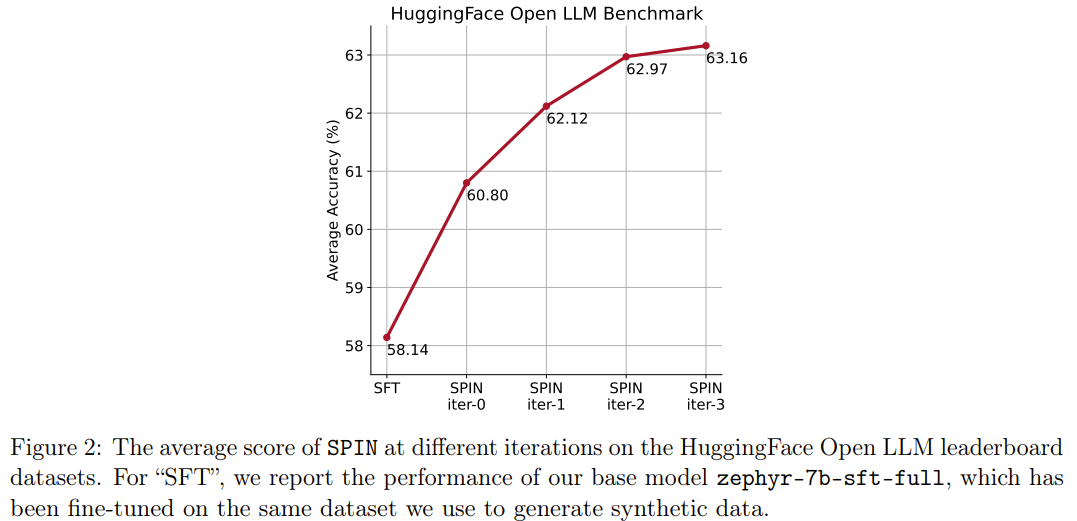
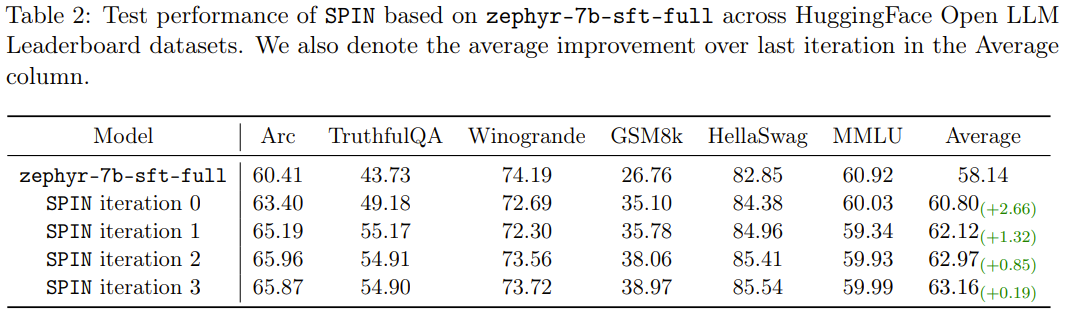
Notamment, dans le classement Open LLM, le modèle affiné avec SPIN est même comparable au modèle entraîné avec un ensemble de données de préférences supplémentaires de 62 000.
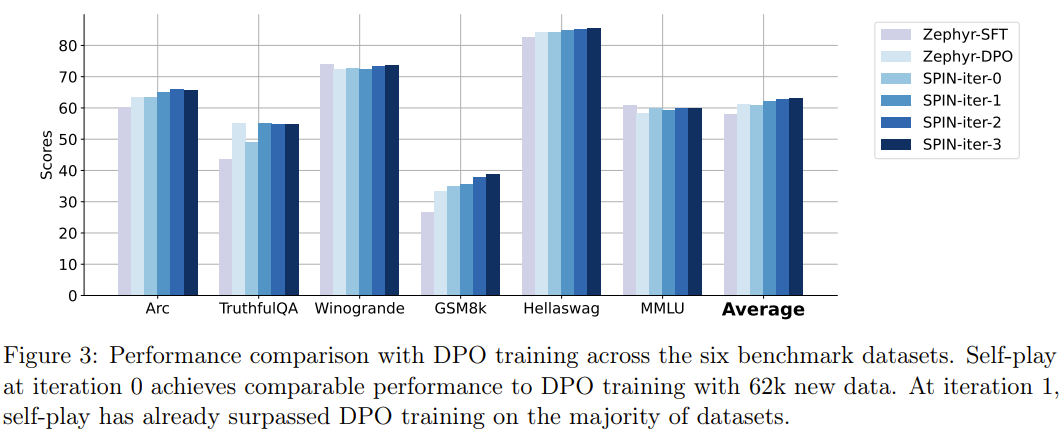
Conclusion
En utilisant pleinement les données annotées par l'homme, SPIN permet aux grands modèles de passer de faibles à forts par eux-mêmes. Comparé à l'apprentissage par renforcement basé sur le feedback des préférences humaines (RLHF), SPIN permet au LLM de s'auto-améliorer sans feedback humain supplémentaire ni feedback LLM plus fort. Dans le cadre d'expériences sur plusieurs ensembles de données de référence, notamment le classement HuggingFace Open LLM, SPIN améliore de manière significative et stable les performances de LLM, surpassant même les modèles formés avec des commentaires supplémentaires de l'IA.
Nous espérons que SPIN pourra contribuer à l'évolution et à l'amélioration des grands modèles, et finalement atteindre une intelligence artificielle au-delà des niveaux humains.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!