
Maison >Périphériques technologiques >IA >Le grand modèle multimodal open source de Megvii prend en charge l'OCR au niveau du document, couvrant le chinois et l'anglais. Cela marque-t-il la fin de l'OCR ?
Le grand modèle multimodal open source de Megvii prend en charge l'OCR au niveau du document, couvrant le chinois et l'anglais. Cela marque-t-il la fin de l'OCR ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-05 21:23:581192parcourir
Vous souhaitez convertir une image de document au format Markdown ?
Dans le passé, cette tâche nécessitait plusieurs étapes telles que la reconnaissance de texte, la détection et le tri de la mise en page, le traitement des tableaux de formules, le nettoyage du texte, etc. -
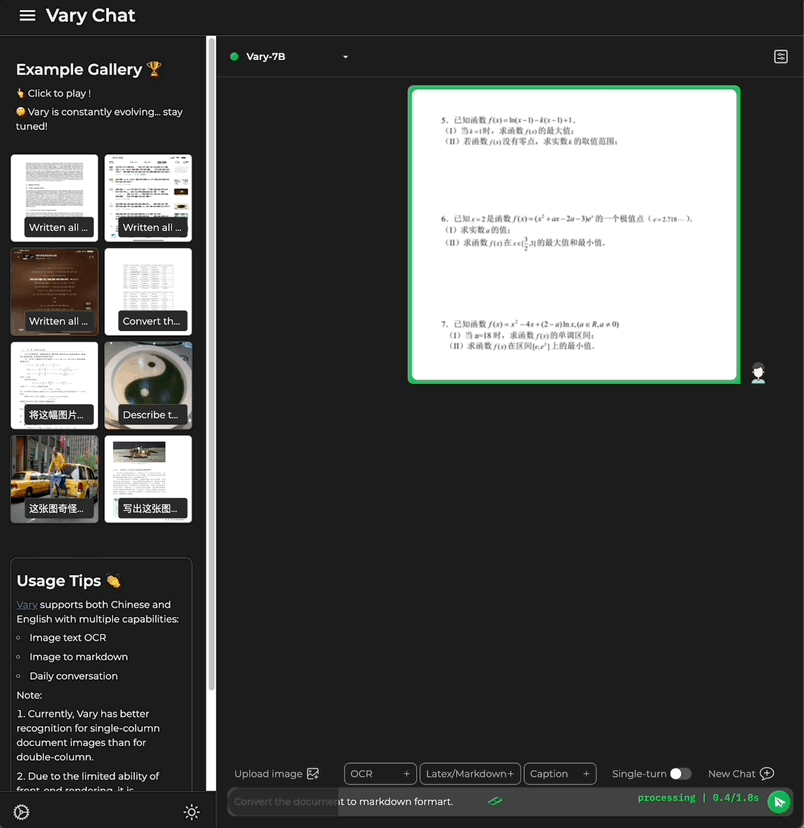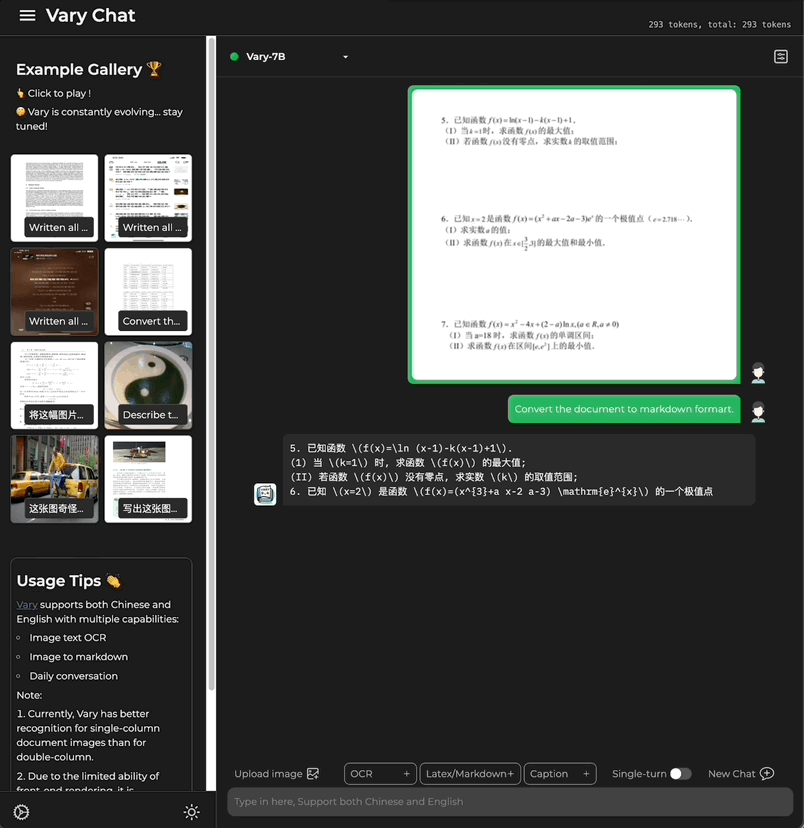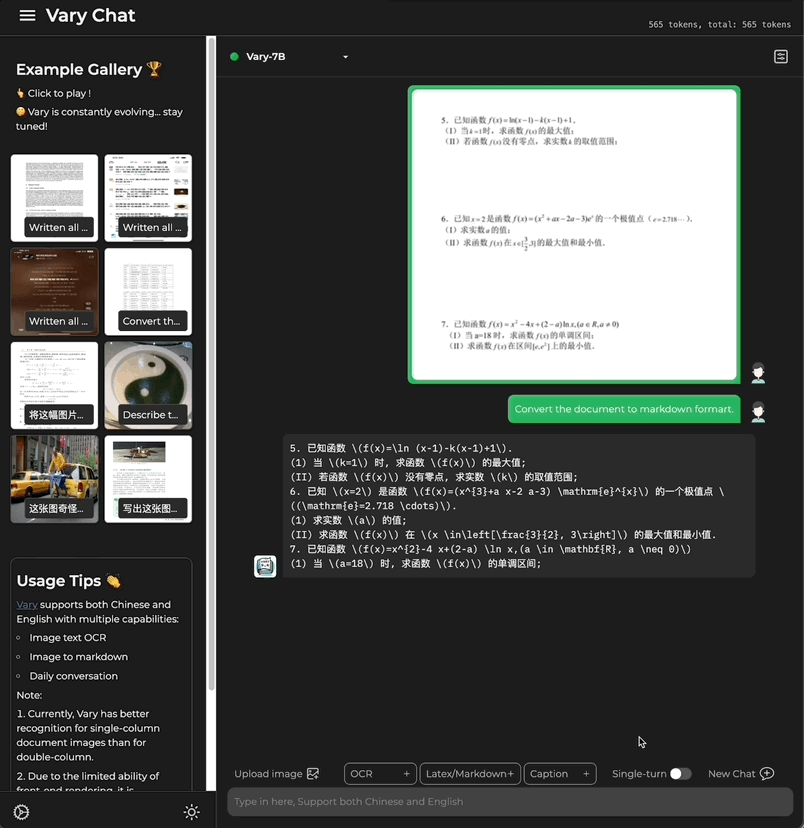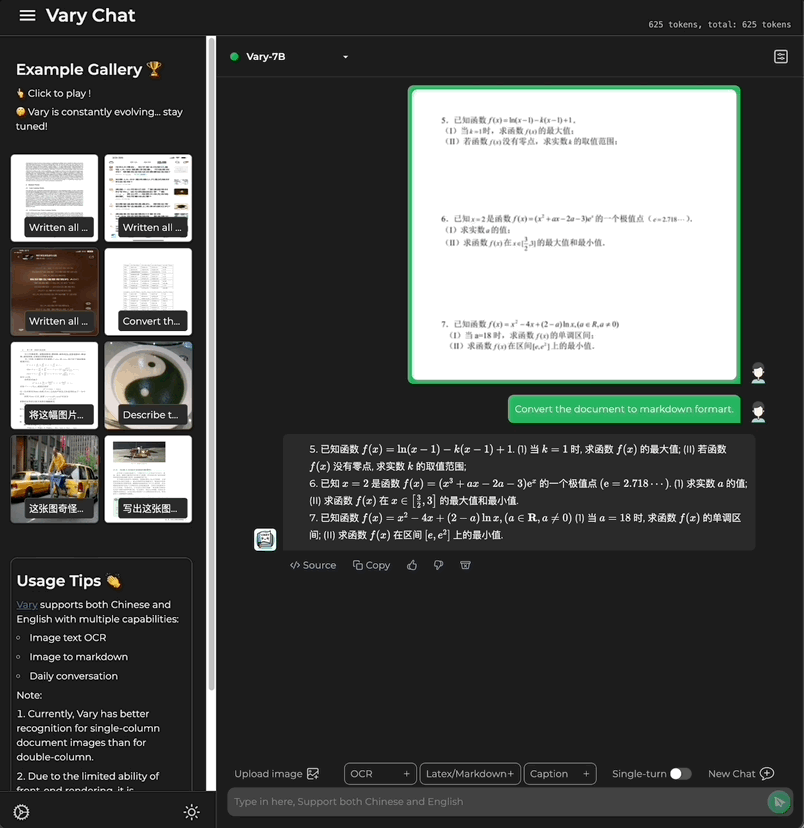
Cette fois, avec une seule phrase de commande, Grand modèle multimodal Vary est directement transmis aux résultats de sortie du terminal :
 images
images
Qu'il s'agisse d'un grand texte en chinois et en anglais :
 images
images
inclut également des images de document de formule
 images
images
ou une page mobile Capture d'écran :
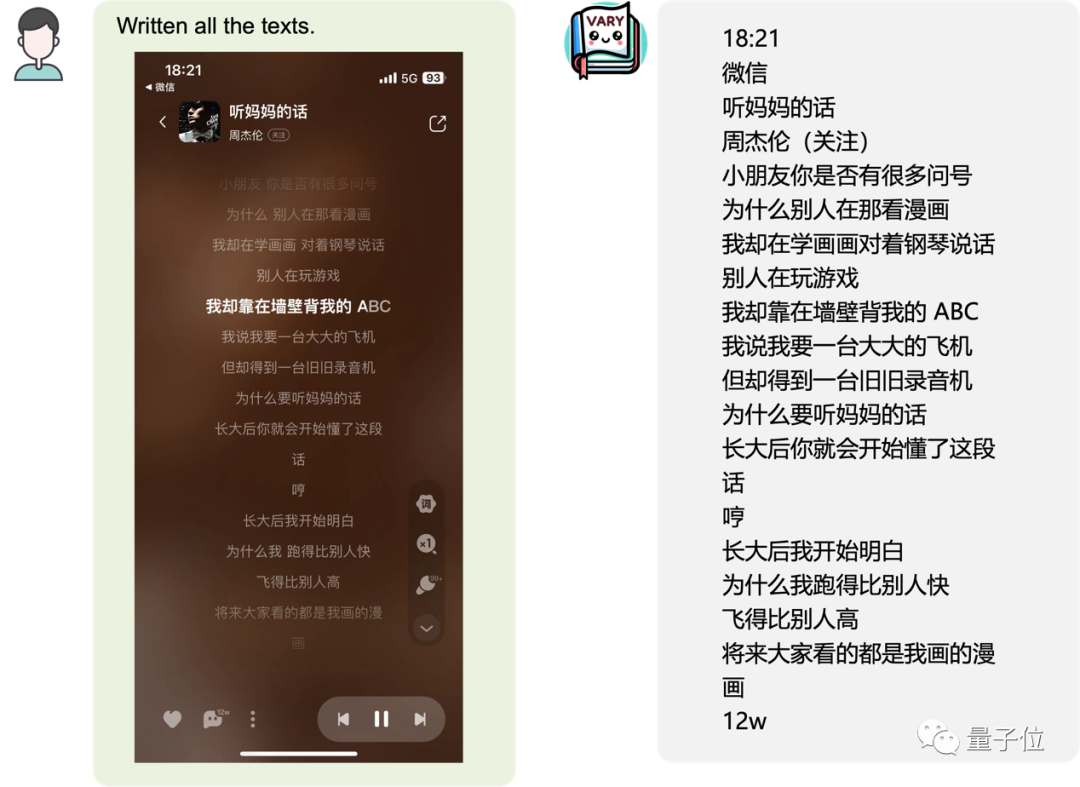 image
image
Vous pouvez même convertir le tableau de l'image en latexFormat :
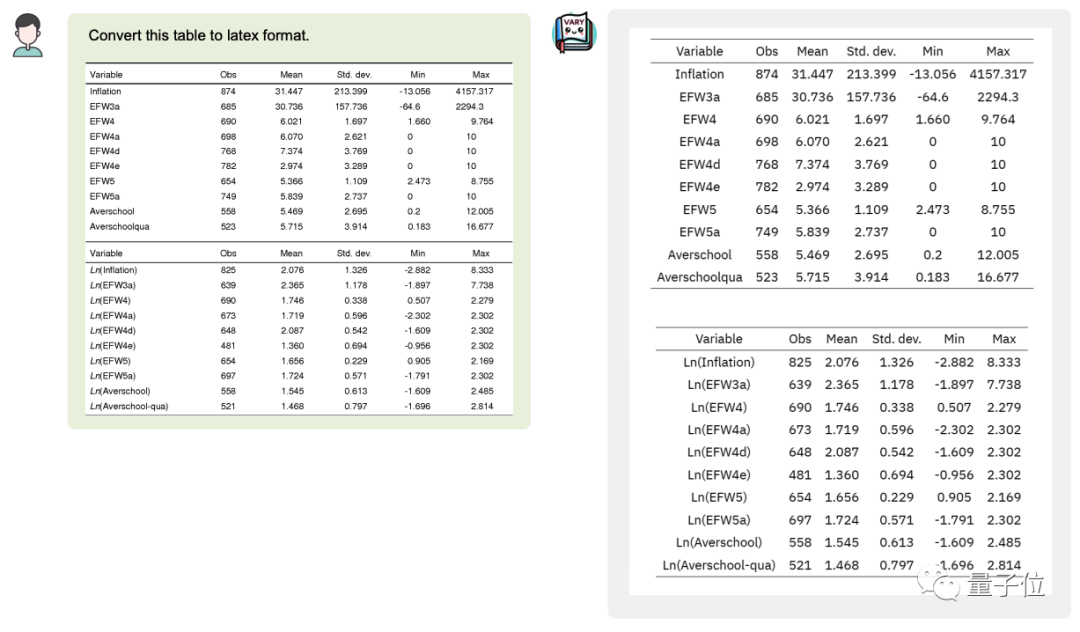 image
image
Bien sûr, en grand multi-modèle modèle, le maintien des capacités universelles est essentiel. Les
 images
images
Vary montrent un grand potentiel et une limite supérieure extrêmement élevée. L'OCR ne peut plus nécessiter de longs pipelines, est directement produite de bout en bout et peut produire différents formats tels que le latex. selon les invites de l'utilisateur, mot, démarque.
Avec des priorités linguistiques fortes, cette architecture peut éviter les mots sujets aux fautes de frappe dans l'OCR, tels que « levier » et « dupôle », etc. Pour les documents flous, avec l'aide des priorités linguistiques, il devrait également obtenir des effets OCR plus forts
Le projet qui a attiré l'attention de nombreux internautes a immédiatement suscité une large discussion une fois lancé. L'un des internautes a crié après l'avoir vu : « C'est tellement génial ! »
 Photo
Photo
Comment cet effet est-il obtenu ?
Inspiré des grands modèles
Actuellement, presque tous les grands modèles multimodaux utilisent CLIP comme Vision Encoder ou vocabulaire visuel. En effet, CLIP formé sur 400 millions de paires image-texte possède de fortes capacités d'alignement visuel du texte et peut couvrir l'encodage d'images dans la plupart des tâches quotidiennes.
Mais pour les tâches de perception denses et fines, telles que l'OCR au niveau du document et la compréhension de graphiques, en particulier dans des scénarios non anglais, CLIP montre des problèmes évidents d'inefficacité de codage et de manque de vocabulaire.
Lorsqu'un grand modèle PNL pur (tel que LLaMA) passe de l'anglais au chinois (une « langue étrangère » pour le grand modèle), parce que le vocabulaire original codant le chinois est inefficace, le vocabulaire du texte doit être élargi pour obtenir de meilleurs résultats.
L'équipe de recherche s'en est inspirée. C'est précisément à cause de cette fonctionnalité
Maintenant, le grand modèle multimodal basé sur le vocabulaire visuel CLIP est confronté au même problème, rencontrant une « image en langue étrangère », comme une page de texte dense. dans un article, il est difficile de tokeniser efficacement les images.
Vary est une solution fournie pour résoudre ce problème. Elle peut élargir efficacement le vocabulaire visuel sans rétablir le vocabulaire original
 Images
Images
Différent des méthodes existantes directement En utilisant un vocabulaire CLIP prêt à l'emploi, Vary fonctionne en deux étapes :
Premièrement, nous utiliserons un petit réseau uniquement décodeur dans la première étape pour générer un nouveau vocabulaire visuel puissant de manière autorégressive
Ensuite, dans la deuxième étape, le nouveau vocabulaire et le vocabulaire CLIP sont fusionné pour entraîner efficacement LVLM et lui donner de nouvelles fonctionnalités
Ce qui suit est une illustration de la méthode de formation et de la structure du modèle de Vary :
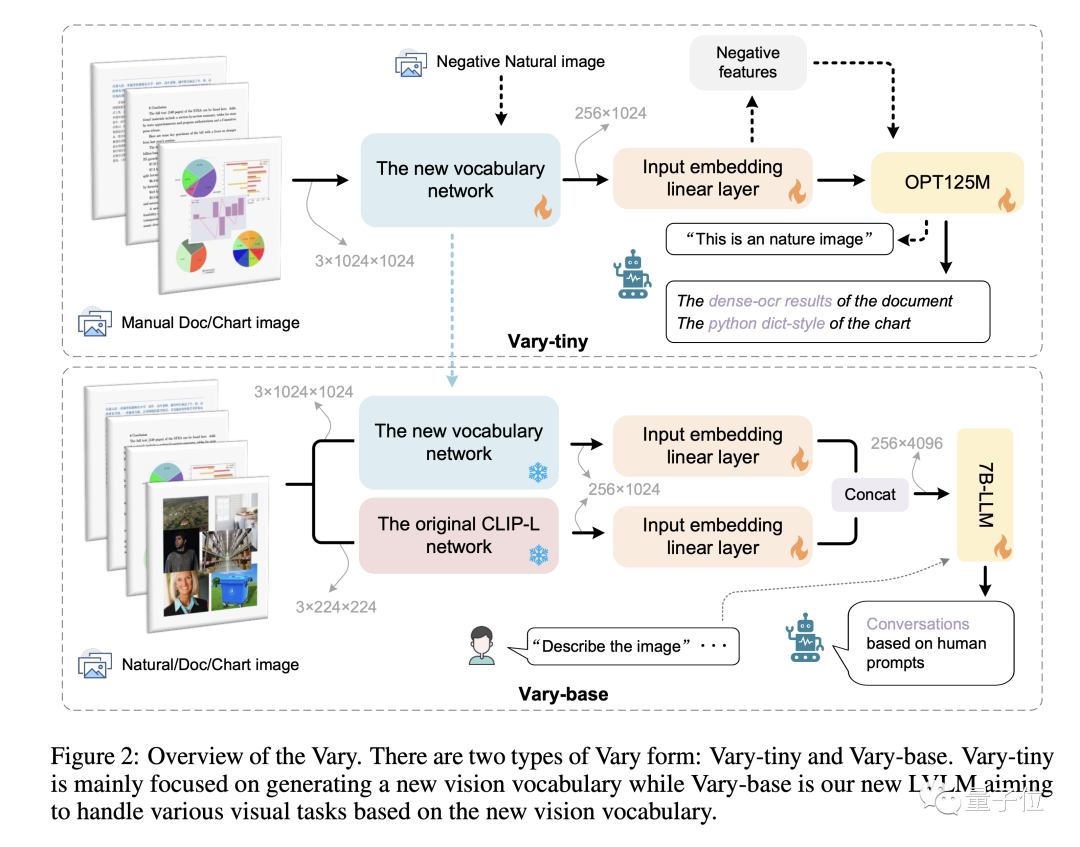 Images
Images
Par formé sur des ensembles de données publiques et des graphiques de documents rendus, Vary améliore considérablement la granularité fine capacités de perception visuelle.
Tout en conservant les capacités multimodales de Vanilla, il inspire une compréhension de bout en bout des images, des captures d'écran de formules et des graphiques en chinois et en anglais.
De plus, l'équipe de recherche a remarqué que le contenu de la page qui aurait pu nécessiter à l'origine des milliers de jetons était saisi par des images de documents, et que les informations étaient compressées en 256 jetons d'image, ce qui offrait également plus d'imagination pour une analyse plus approfondie des pages et un espace de résumé. .
Actuellement, le code et le modèle de Vary sont open source, et une démo Web est également proposée à tous.
Les amis intéressés peuvent l'essayer~
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!