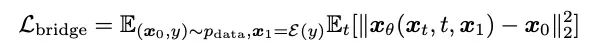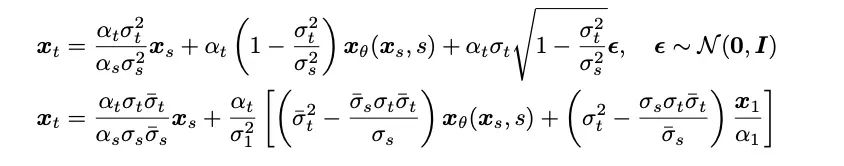Récemment, un système de synthèse vocale basé sur le pont de Schrödinger [1] publié par le groupe de recherche du professeur Zhu Jun du département d'informatique de l'université de Tsinghua a vaincu le modèle de diffusion en termes de qualité d'échantillon et de vitesse d'échantillonnage grâce à ses « données- paradigme de génération "to-data". Le paradigme "noise-to-data". 
Lien papier : https://arxiv.org/abs/2312.03491 Site Web du projet : https://bridge-tts.github.io/ Implémentation du code : https://github.com/thu -ml/Bridge-TTSDepuis 2021, les modèles de diffusion ont commencé à devenir les plus populaires dans le domaine de la synthèse texte-parole (texte-parole , TTS) L'une des méthodes de génération de base, telle que Grad-TTS [2] proposée par le laboratoire Noah's Ark de Huawei et DiffSinger [3] proposée par l'Université du Zhejiang, a atteint une qualité de génération élevée. Depuis lors, de nombreux travaux de recherche ont amélioré efficacement la vitesse d'échantillonnage des modèles de diffusion, notamment grâce à l'optimisation préalable [2, 3, 4], à la distillation de modèles [5, 6], à la prédiction des résidus [7] et à d'autres méthodes. Cependant, comme le montre cette étude, étant donné que le modèle de diffusion est limité au paradigme de génération du « bruit aux données », sa distribution préalable fournit toujours des informations limitées pour la cible de génération et ne peut pas utiliser pleinement les informations conditionnelles. Le dernier travail de recherche dans le domaine de la synthèse vocale, Bridge-TTS, s'appuie sur son cadre de génération basé sur le pont Schrödinger pour réaliser le processus de génération « données à données » Pour la première fois, les informations préalables de la synthèse vocale. est modifié du bruit aux données propres , est modifié de la distribution à la représentation déterministe . L'architecture principale de cette méthode est présentée dans la figure ci-dessus. Le texte d'entrée est d'abord extrait via l'encodeur de texte pour extraire la représentation spatiale latente de la cible générée (spectrogramme mel, spectre mel). Par la suite, contrairement au modèle de diffusion qui intègre ces informations dans la distribution du bruit ou les utilise comme informations de condition, la méthode Bridge-TTS prend en charge directement son utilisation comme information préalable et prend en charge un échantillonnage aléatoire ou déterministe, Haute qualité, rapide Génération de cible. Sur l'ensemble de données standard LJ-Speech qui vérifie la qualité de la synthèse vocale, l'équipe de recherche a accéléré Bridge-TTS avec 9 systèmes de synthèse vocale et modèles de diffusion de haute qualité Les méthodes d'échantillonnage ont été comparées. Comme indiqué ci-dessous, cette méthode surpasse les systèmes TTS basés sur un modèle de diffusion de haute qualité [2, 3, 7] en qualité d'échantillon (1 000 étapes, 50 étapes d'échantillonnage) et en vitesse d'échantillonnage sans aucun post-traitement. comme la distillation modèle supplémentaire, elle dépasse de nombreuses méthodes d'accélération, telles que la prédiction résiduelle, la distillation progressive et la dernière distillation consensus [5, 6, 7]. Voici des exemples des effets de génération de Bridge-TTS et de la méthode basée sur un modèle de diffusion. Pour plus de comparaisons d'échantillons de génération, veuillez visiter le site Web du projet : https://bridge-tts.github.io/
-
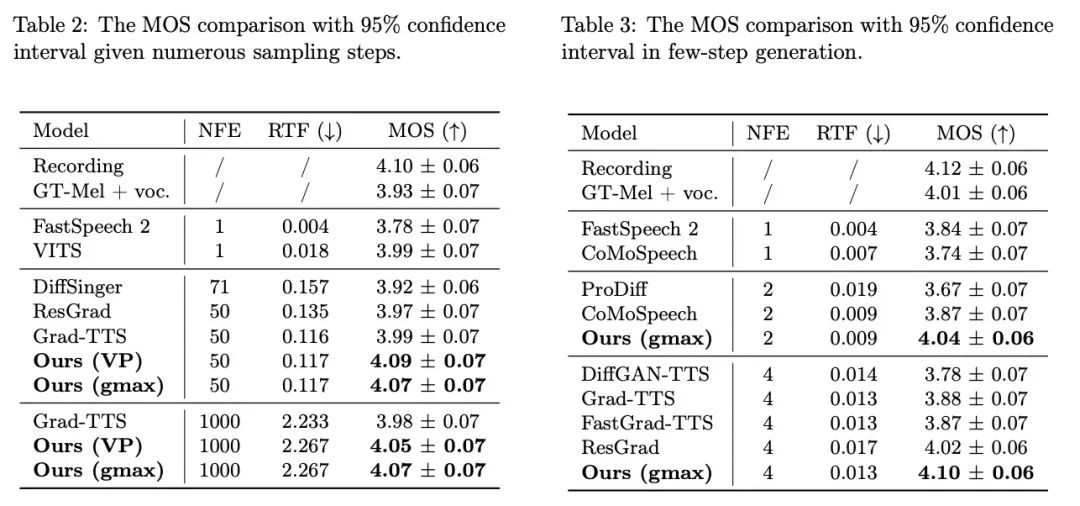
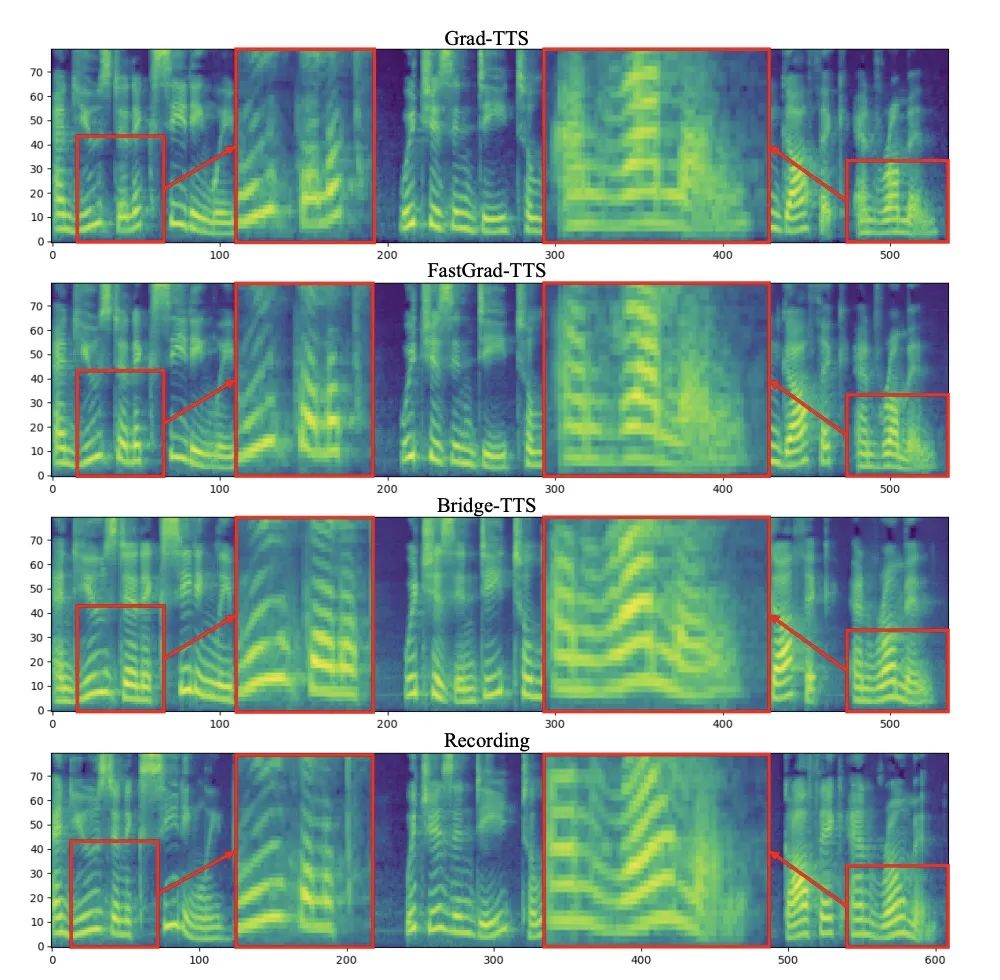
Comparaison des effets de synthèse en 1000 étapes
Entrez le texte : "L'impression peut donc, pour notre propos, être considérée comme l'art de fabriquer des livres au moyen de caractères mobiles."
-
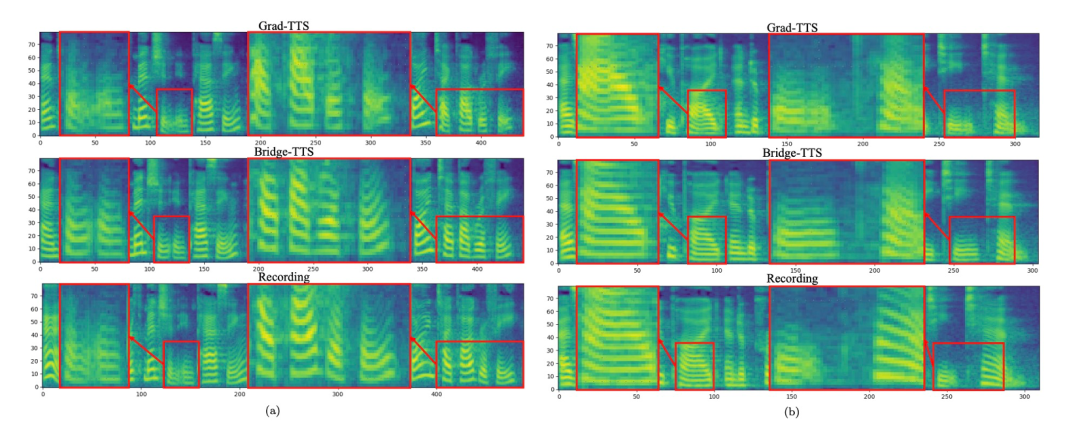
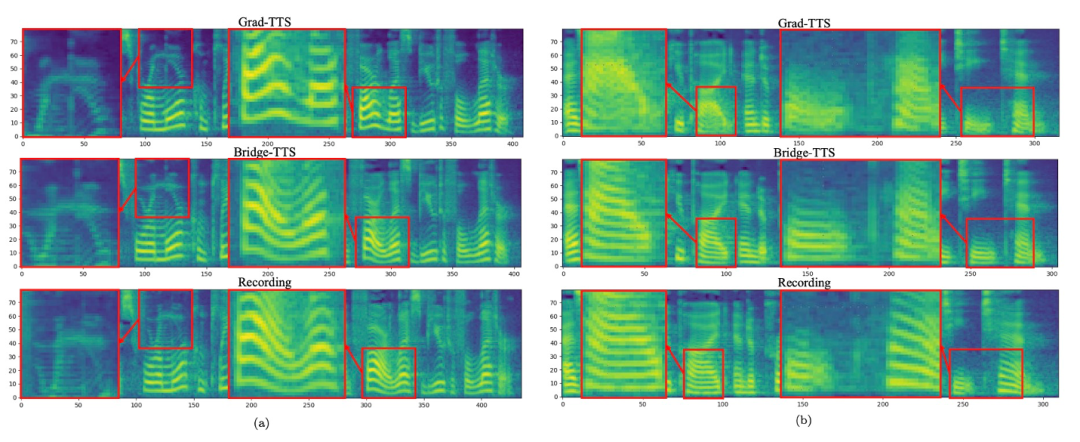
Comparaison des effets de synthèse en 4 étapes
Texte d'entrée : "Les premiers livres étaient imprimés en lettre noire, c'est-à-dire la lettre qui était un développement gothique du caractère romain antique",
- 2 Comparaison des effets de la synthèse par étapes
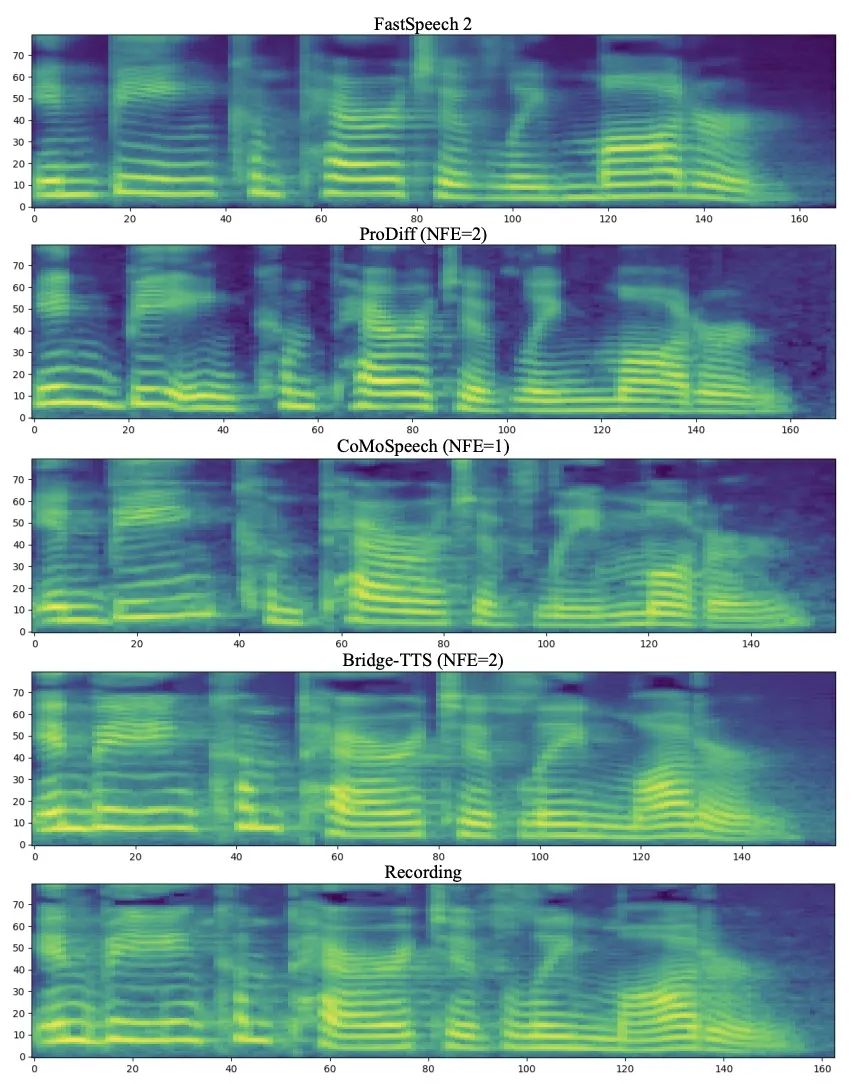
Texte d'entrée : "La population carcérale a beaucoup fluctué",
Dans le domaine fréquentiel, davantage d'échantillons générés sont présentés ci-dessous. En 1000 étapes de synthèse, cette méthode génère un spectre Mel de meilleure qualité par rapport au modèle de diffusion lorsque le nombre d'étapes d'échantillonnage est réduit à 50 étapes. le modèle de diffusion a sacrifié certains détails d'échantillonnage, tandis que la méthode basée sur le pont de Schrödinger conserve toujours des effets de génération de haute qualité. Dans la synthèse en 4 et 2 étapes, cette méthode ne nécessite pas de distillation, d'entraînement en plusieurs étapes ni de fonctions de perte contradictoires, tout en permettant d'obtenir des effets de génération de haute qualité.
En 1000 étapes de synthèse, la comparaison du spectre Mel de Bridge-TTS et la méthode basée sur un modèle de diffusion
En 50 étapes de synthèse, Bridge-TTS et la méthode basée sur le modèle de diffusion Comparaison du spectre Mel des méthodes du modèle de diffusion
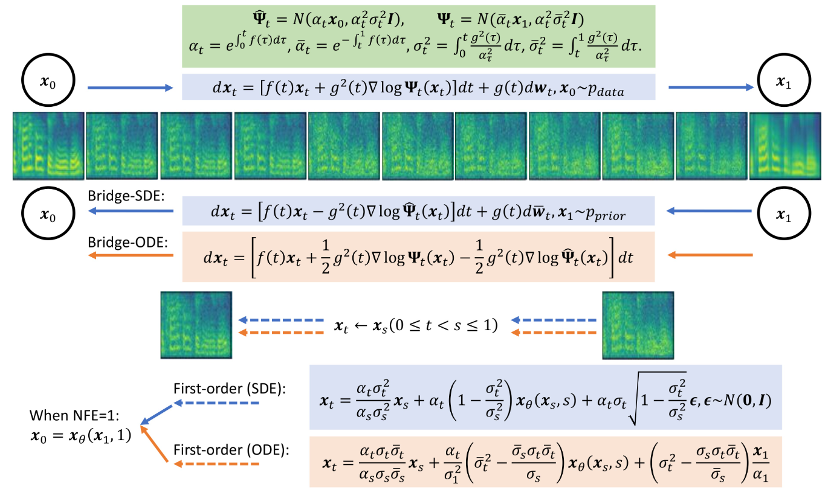
Comparaison des spectres Mel entre les méthodes Bridge-TTS et basées sur un modèle de diffusion en synthèse en 4 étapesEn synthèse en 2 étapes, Bridge-TTS et basée sur la diffusion méthodes Comparaison du spectre de Mel des méthodes modèles Bridge-TTS une fois publié, avec sa conception nouvelle et son effet de synthèse de haute qualité dans la synthèse vocale, a attiré une attention enthousiaste sur Twitter et a reçu des centaines de commentaires Avec plus de . Avec 100 retweets et des centaines de likes, Huggingface a été sélectionné dans le Daily Paper de Huggingface le 12.7 et a remporté la première place du taux de soutien ce jour-là. En même temps, il a été suivi sur de nombreuses plateformes nationales et étrangères telles que LinkedIn, Weibo, Zhihu, et Xiaohongshu et transmettre des rapports. De nombreux sites Web en langues étrangères ont également rapporté et discuté : Introduction à la méthode Le pont de Schrödinger est un type de modèle qui a récemment émergé à la suite du modèle de diffusion. le modèle génératif profond a des applications préliminaires dans la génération d'images, la traduction d'images et d'autres domaines [8,9]. Contrairement au modèle de diffusion, qui établit un processus de transformation entre les données et le bruit gaussien, le pont de Schrödinger prend en charge la transformation entre deux distributions limites quelconques. Dans l'étude de Bridge-TTS, les auteurs ont proposé un cadre de synthèse vocale basé sur le pont de Schrödinger entre des données appariées, qui prend en charge de manière flexible une variété de processus directs, de cibles de prédiction et de processus d'échantillonnage. Un aperçu de sa méthode est présenté dans la figure ci-dessous :
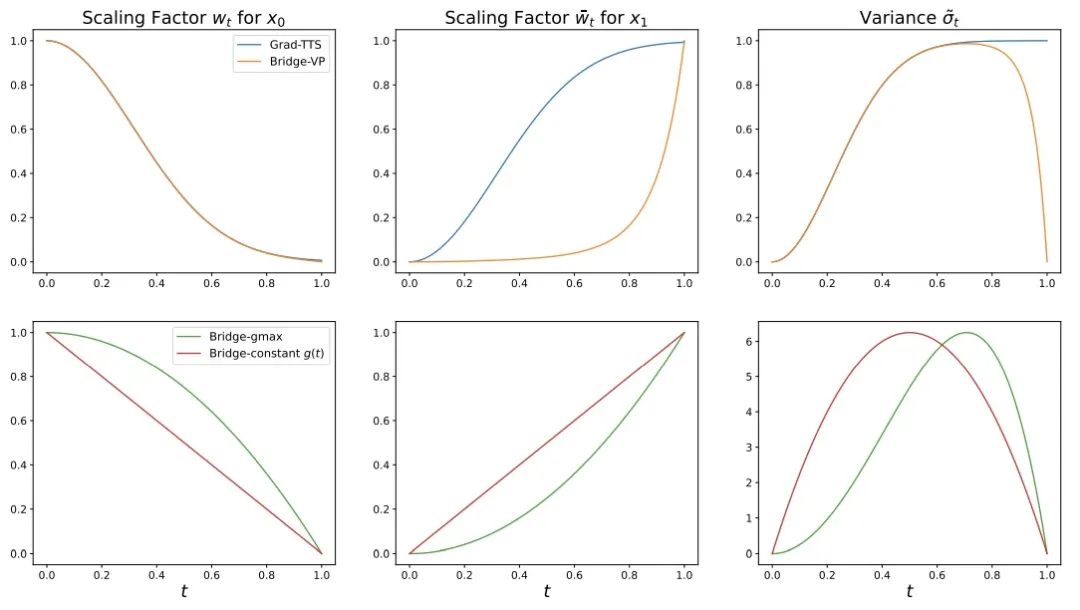
- Processus Forward : Cette recherche construit un pont de Schrödinger entièrement résoluble entre des informations a priori fortes et des objectifs de génération, prenant en charge un processus forward flexible. Choisissez parmi bruit symétrique stratégies : , stratégies de bruit constantes et asymétriques : , linéaires, ainsi que des stratégies de bruit préservant la variance (VP) qui correspondent directement aux modèles de diffusion. Cette méthode a révélé que dans les tâches de synthèse vocale, les stratégies de bruit asymétriques : les processus linéaires (gmax) et VP ont de meilleurs effets de génération que les stratégies de bruit symétriques.
- Formation de modèle : Cette méthode conserve les multiples avantages du processus de formation du modèle de diffusion, tels qu'une seule étape, un modèle unique et une fonction de perte unique. Et il compare diverses méthodes de paramétrage du modèle (paramétrage du modèle), c'est-à-dire la sélection des cibles d'entraînement du réseau, y compris la prédiction du bruit (Noise), la prédiction de la cible de génération (Data) et la technologie d'adaptation de flux correspondant au modèle de diffusion [10,11 ] Prédiction de la vitesse (Velocity), etc. L'article révèle que lorsque la cible de génération, c'est-à-dire le spectre mel, est utilisée comme cible de prédiction du réseau, des résultats de génération relativement meilleurs peuvent être obtenus.
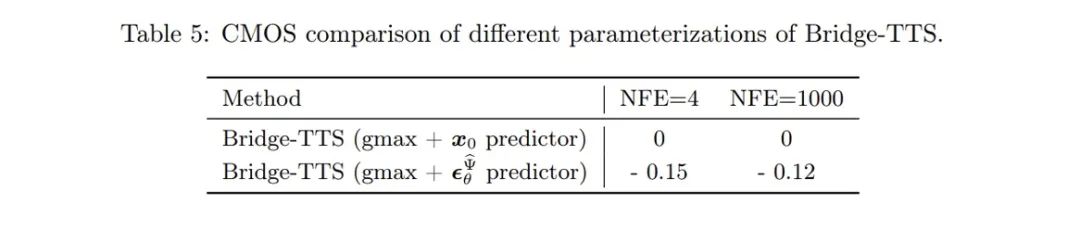
- Processus d'échantillonnage : Grâce à la forme complètement résoluble du pont de Schrödinger dans cette étude, en transformant le système SDE avant-arrière correspondant au pont de Schrödinger, les auteurs ont obtenu le Bridge SDE et Bridge ODE est utilisé pour l’inférence. Dans le même temps, en raison de la lenteur de la simulation directe de l'inférence Bridge SDE/ODE, afin d'accélérer l'échantillonnage, cette étude a utilisé l'intégrateur exponentiel couramment utilisé dans les modèles de diffusion [12, 13], et a donné le premier ordre Formes d'échantillonnage SDE et ODE du pont de Schrödinger :
Dans l'échantillonnage en une étape, les formes d'échantillonnage du SDE et de l'ODE de premier ordre dégénèrent conjointement en prédiction en une seule étape du réseau. Dans le même temps, ils sont étroitement liés à l’échantillonnage DDIM du modèle d’échantillonnage/diffusion postérieur, et l’article donne une analyse détaillée en annexe. L'article fournit également les algorithmes d'échantillonnage SDE et ODE d'échantillonnage de second ordre du pont de Schrödinger. Les auteurs ont découvert qu’en synthèse vocale, la qualité de la génération est similaire à celle d’un processus d’échantillonnage de premier ordre. Dans d'autres tâches telles que l'amélioration de la parole, la séparation de la parole, l'édition de la parole et d'autres tâches où l'information préalable est également forte, les auteurs s'attendent à ce que cette recherche apporte également une plus grande valeur d'application. Cette étude compte trois co-premiers auteurs : Chen Zehua, He Guande et Zheng Kaiwen, tous appartiennent au groupe de recherche de Zhu Jun au département d'informatique de l'université Tsinghua. L'auteur correspondant de l'article est le professeur Zhu Jun, Microsoft Asia Research Tan Xu, directeur de recherche en chef de l'institut, est un collaborateur du projet.
Tan Xu, directeur de la recherche chez Microsoft Research Asia, effets sonores, synthèse de signaux bioélectriques et autres applications. Il a effectué des stages dans de nombreuses entreprises telles que Microsoft, JD.com et TikTok, et a publié de nombreux articles lors d'importantes conférences internationales dans le domaine de la parole et de l'apprentissage automatique, telles que ICML/NeurIPS/ICASSP.
He Guande est étudiant en troisième année de maîtrise à l'Université Tsinghua. Ses principaux domaines de recherche sont l'estimation de l'incertitude et les modèles génératifs. Il a déjà publié des articles en tant que premier auteur à l'ICLR et dans d'autres conférences.
Zheng Kaiwen est étudiant en deuxième année de master à l'Université Tsinghua. Son principal axe de recherche est la théorie et l'algorithme des modèles génératifs profonds, ainsi que leurs applications en génération d'images, d'audio et de 3D. Il a déjà publié de nombreux articles lors de conférences de premier plan telles que ICML/NeurIPS/CVPR, impliquant des technologies telles que l'appariement de flux et les intégrateurs exponentiels dans les modèles de diffusion. [1] Zehua Chen, Guande He, Kaiwen Zheng, Xu Tan et Jun Schrodinger battent les modèles de diffusion sur la synthèse de synthèse vocale arXiv. :2312.03491, 2023. [2] Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova et Mikhail A. Kudinov : un modèle probabiliste de diffusion pour la synthèse vocale dans ICML, 2021.[3] Jinglin Liu, Chengxi Li, Yi Ren, Feiyang Chen et Zhou Zhao : synthèse vocale chantée via un mécanisme de diffusion peu profonde dans AAAI, 2022.[ 4. ] Sang-gil Lee, Heeseung Kim, Chaehun Shin, Xu Tan, Chang Liu, Qi Meng, Tao Qin, Wei Chen, Sungroh Yoon et Tie-Yan Liu : amélioration des modèles de diffusion de débruitage conditionnel avec un préalable adaptatif dépendant des données. Dans ICLR, 2022. [5] Rongjie Huang, Zhou Zhao, Huadai Liu, Jinglin Liu, Chenye Cui et Yi Ren : modèle de diffusion rapide progressive pour une synthèse vocale de haute qualité. ACM Multimedia, 2022. [6] Zhen Ye, Wei Xue, Xu Tan, Jie Chen, Qifeng Liu et Yike Guo : synthèse vocale et vocale en une étape via un modèle de cohérence dans ACM Multimedia. , 2023.[7] Zehua Chen, Yihan Wu, Yichong Leng, Jiawei Chen, Haohe Liu, Xu Tan, Yang Cui, Ke Wang, Lei He, Sheng Zhao, Jiang Bian et Danilo P. Mandic . ResGrad : Modèles probabilistes de diffusion de débruitage résiduel pour la synthèse vocale. NeurIPS 2023.[9] Guan-Horng Liu, Arash Vahdat, De-An Huang, Evangelos A. Theodorou, Weili Nie et Anima Anandkumar : pont Schrödinger image à image dans ICML, 2023.[10] Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel et Matt Le Flow Matching pour la modélisation générative, 2023.[11 ] Kaiwen Zheng, Cheng Lu, Jianfei Chen et Jun Zhu. Techniques améliorées pour l'estimation de la vraisemblance maximale pour les ODE de diffusion dans ICML, 2023.[12] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan. Li et Jun Zhu. DPM-Solver : un solveur ODE rapide pour l'échantillonnage de modèles probabilistes de diffusion en 10 étapes environ dans NeurIPS, 2022.[13] Kaiwen Zheng, Cheng Lu, Jianfei Chen et Jun Zhu. . DPM-Solver-v3 : Solveur ODE de diffusion amélioré avec statistiques de modèle empirique dans NeurIPS, 2023..Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



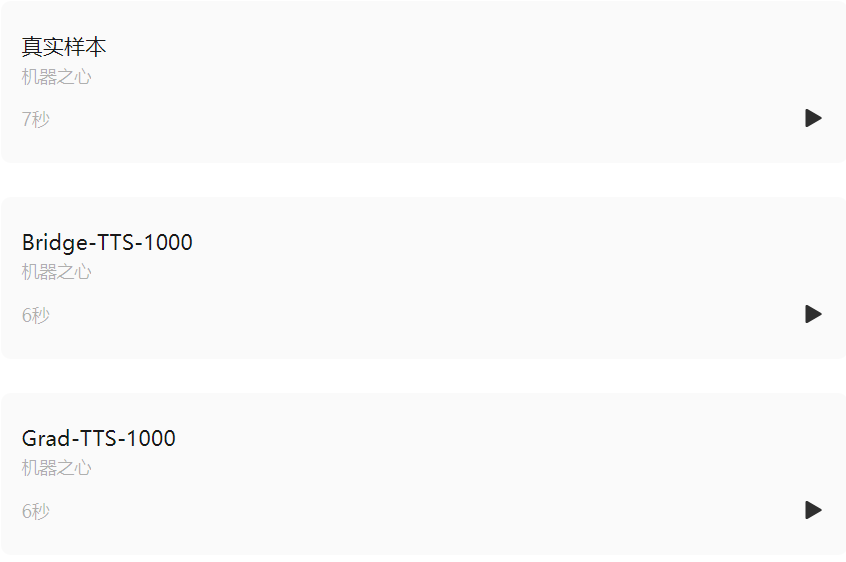
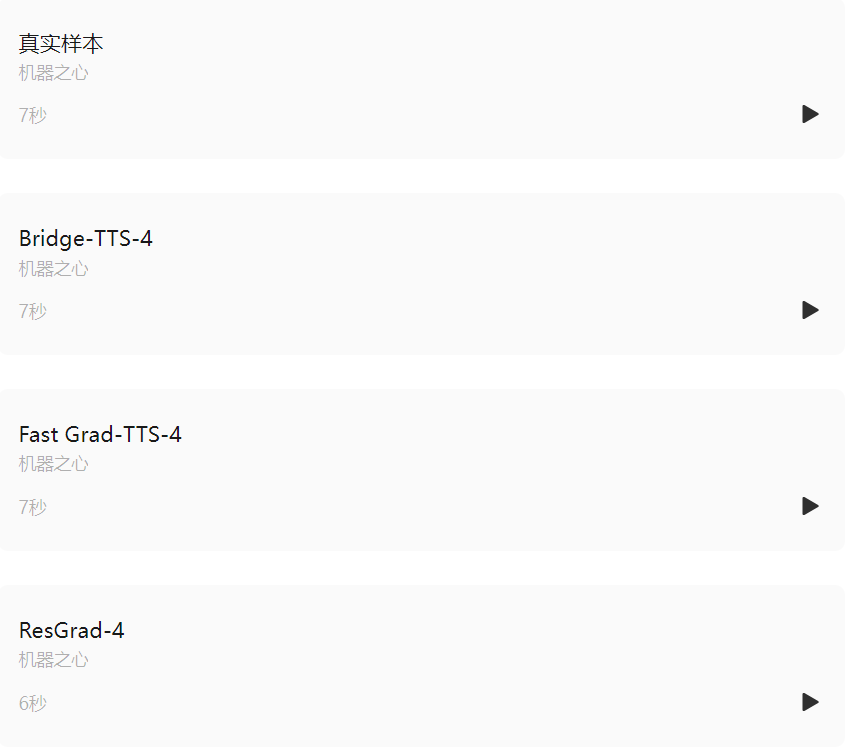
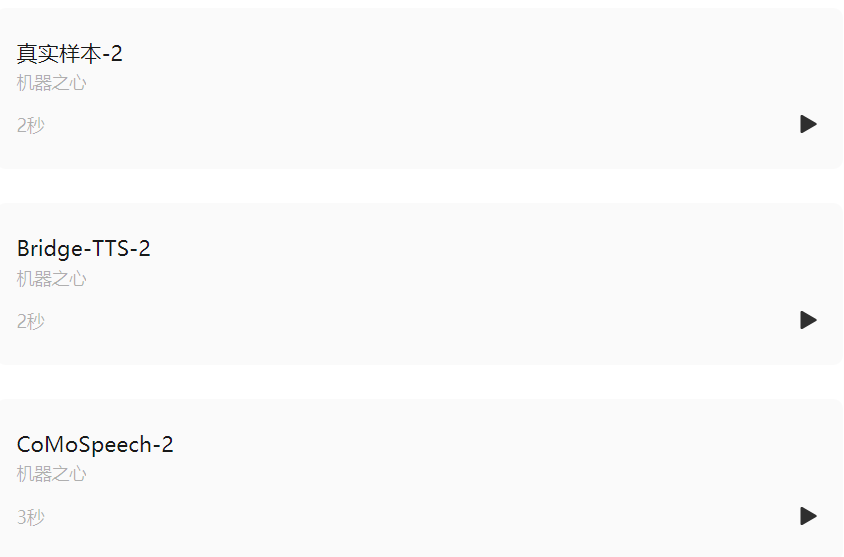 Ce qui suit montre une synthèse déterministe (échantillonnage ODE) de Bridge -TTS en 2 étapes et 4 étapes). Dans la synthèse en 4 étapes, cette méthode synthétise significativement plus de détails d'échantillon que le modèle de diffusion, et il n'y a aucun problème de bruit résiduel. Dans une synthèse en 2 étapes, cette méthode présente des trajectoires d'échantillonnage totalement pures et affine davantage de détails générés à chaque étape.
Ce qui suit montre une synthèse déterministe (échantillonnage ODE) de Bridge -TTS en 2 étapes et 4 étapes). Dans la synthèse en 4 étapes, cette méthode synthétise significativement plus de détails d'échantillon que le modèle de diffusion, et il n'y a aucun problème de bruit résiduel. Dans une synthèse en 2 étapes, cette méthode présente des trajectoires d'échantillonnage totalement pures et affine davantage de détails générés à chaque étape. 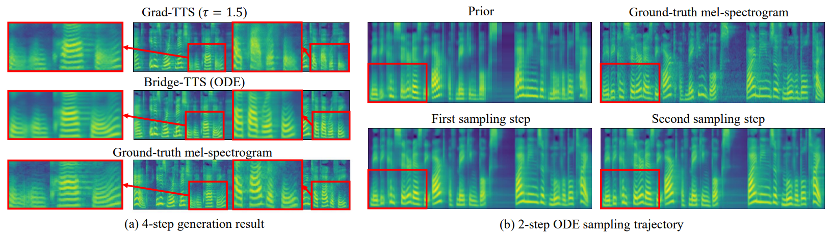
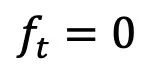 , stratégies de bruit constantes
, stratégies de bruit constantes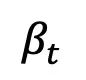 et asymétriques :
et asymétriques :  , linéaires
, linéaires , ainsi que des stratégies de bruit préservant la variance (VP) qui correspondent directement aux modèles de diffusion. Cette méthode a révélé que dans les tâches de synthèse vocale, les stratégies de bruit asymétriques : les processus linéaires
, ainsi que des stratégies de bruit préservant la variance (VP) qui correspondent directement aux modèles de diffusion. Cette méthode a révélé que dans les tâches de synthèse vocale, les stratégies de bruit asymétriques : les processus linéaires