
Maison >Tutoriel système >Linux >L'évolution historique de la programmation Python
L'évolution historique de la programmation Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-01 09:31:11603parcourir
| Présentation | Une fois que vous vous engagez sur la voie de la programmation, si vous ne comprenez pas le problème de codage, il vous hantera comme un fantôme tout au long de votre carrière, et divers événements surnaturels se succéderont et persisteront. Ce n'est qu'en donnant libre cours à l'esprit de combat des programmeurs jusqu'au bout que vous pourrez vous débarrasser complètement des problèmes causés par les problèmes de codage. |
La première fois que j'ai rencontré un problème de codage, c'était lorsque j'écrivais un projet lié à JavaWeb. Une chaîne de caractères errait du navigateur vers le code de l'application et s'immergeait dans la base de données. Il est possible de coder des mines à tout moment et. n'importe où. La deuxième fois que j'ai rencontré un problème de codage, c'était lorsque j'apprenais Python. Lors de l'exploration des données d'une page Web, le problème de codage est revenu à ce moment-là. La phrase la plus populaire de nos jours est : « J'étais confus à ce moment-là. .
Pour comprendre le codage des caractères, nous devons partir de l'origine des ordinateurs. Toutes les données contenues dans les ordinateurs, qu'il s'agisse de textes, d'images, de vidéos ou de fichiers audio, sont essentiellement stockées sous une forme numérique similaire à 01010101. Nous avons de la chance, mais aussi de la malchance. Heureusement, les temps nous ont donné l'occasion d'entrer en contact avec les ordinateurs. Malheureusement, les ordinateurs n'ont pas été inventés par nos compatriotes, les normes informatiques doivent donc être conçues selon les habitudes de chacun. Empire américain. Alors, au final, comment les ordinateurs ont-ils d'abord représenté les personnages ? Cela commence par l’histoire du codage informatique.
ASCIIChaque novice qui fait du développement JavaWeb rencontrera des problèmes de code tronqué, et chaque novice qui utilise le robot d'exploration Python rencontrera des problèmes d'encodage. Pourquoi le problème d'encodage est-il si douloureux ? Ce problème a commencé lorsque Guido van Rossum a créé le langage Python en 1992. À cette époque, Guido ne s'attendait pas à ce que le langage Python soit si populaire aujourd'hui, ni à ce que la vitesse de développement informatique soit si étonnante. Guido n'avait pas besoin de se soucier de l'encodage lorsqu'il a conçu ce langage, car dans le monde anglais, le nombre de caractères est très limité, 26 lettres (majuscules et minuscules), 10 chiffres, signes de ponctuation et caractères de contrôle, c'est-à-dire , sur le clavier Les caractères correspondant à toutes les touches totalisent un peu plus d'une centaine de caractères. C'est plus que suffisant pour utiliser un octet d'espace de stockage pour représenter un caractère dans un ordinateur, car un octet équivaut à 8 bits, et 8 bits peuvent représenter 256 symboles. Les Américains intelligents ont donc développé un ensemble de normes de codage de caractères appelées ASCII (American Standard Code for Information Interchange). Par exemple, la valeur binaire correspondant au caractère A est 01000001 et la valeur décimale correspondante est 65. Au début, ASCII ne définissait que 128 codes de caractères, dont 96 textes et 32 symboles de contrôle, soit un total de 128 caractères. Seuls 7 bits d'un octet sont nécessaires pour représenter tous les caractères, donc ASCII n'utilise qu'un seul octet et le. les bits les plus élevés sont tous 0.
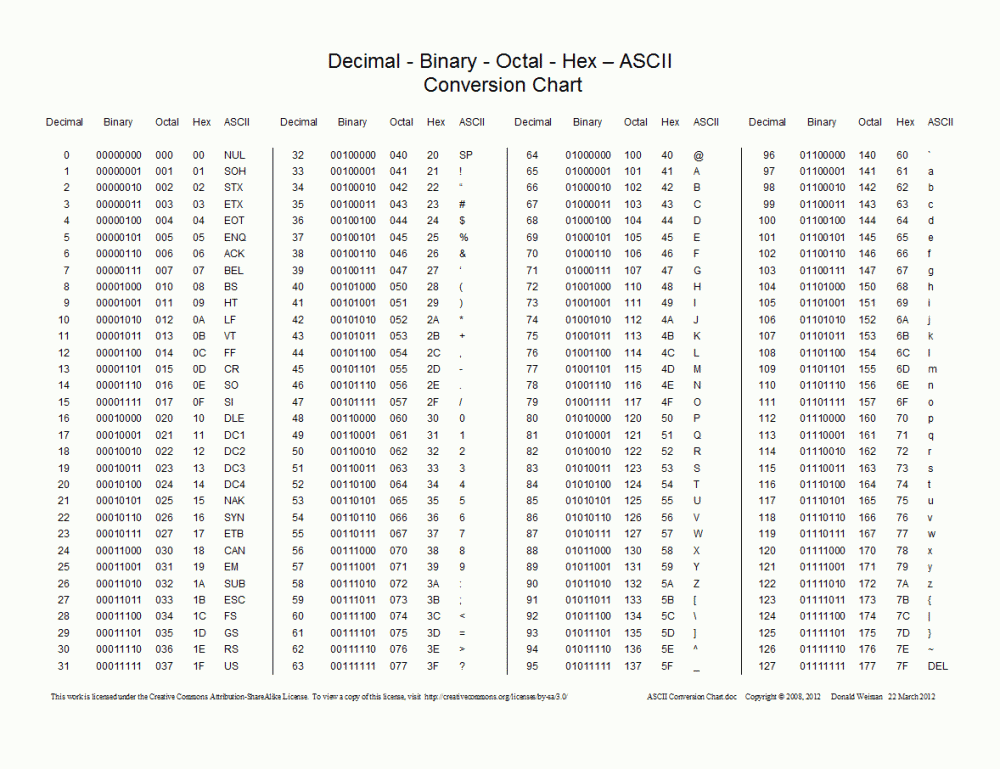
Cependant, lorsque les ordinateurs se sont lentement répandus dans d'autres régions d'Europe occidentale, ils ont découvert qu'il y avait de nombreux caractères uniques à l'Europe occidentale qui ne figuraient pas dans la table de codage ASCII, donc un ASCII extensible appelé EASCII est apparu plus tard. Comme son nom l'indique, il est basé. sur ASCII Étendu de 7 bits à 8 bits, il est entièrement compatible avec ASCII. Les symboles étendus incluent des symboles de table, des symboles de calcul, des lettres grecques et des symboles latins spéciaux. Cependant, l'ère EASCII est une époque chaotique. Ils utilisent chacun le bit le plus élevé pour implémenter leur propre ensemble de normes de codage de caractères selon leurs propres normes. Les plus célèbres sont CP437. utilisé dans les systèmes Windows, comme indiqué ci-dessous :
Un autre EASCII largement utilisé est ISO/8859-1 (Latin-1), qui est une série de normes de jeu de caractères 8 bits développées conjointement par l'Organisation internationale de normalisation (ISO) et la Commission électrotechnique internationale (CEI), ISO. /8859-1 n'hérite que des caractères compris entre 128 et 159 du codage de caractères CP437, il est donc défini à partir de 160. Malheureusement, ces nombreux jeux de caractères étendus ASCII sont incompatibles les uns avec les autres.

Avec l'avancée des temps, les ordinateurs ont commencé à se répandre dans des milliers de foyers. Bill Gates a réalisé le rêve de chacun d'avoir un ordinateur sur son bureau. Cependant, un problème auquel les ordinateurs doivent faire face lorsqu'ils entrent en Chine est le codage des caractères. Bien que les caractères chinois dans notre pays soient les caractères les plus fréquemment utilisés par les humains, les caractères chinois sont larges et profonds, et il existe des dizaines de milliers de caractères chinois courants. est bien au-delà de ce que l'encodage ASCII peut représenter. Même EASCII semblait être une goutte d'eau dans l'océan, alors les Chinois intelligents ont créé leur propre ensemble de codes appelé GB2312, également connu sous le nom de GB0, qui a été publié par l'Administration d'État des normes de La Chine en 1981. L'encodage GB2312 contient un total de 6 763 caractères chinois et est également compatible avec ASCII. L'émergence du GB2312 répond essentiellement aux besoins de traitement informatique des caractères chinois. Les caractères chinois qu'il contient couvrent 99,75 % de la fréquence d'utilisation en Chine continentale. Cependant, le GB2312 ne peut toujours pas répondre à 100 % aux besoins des caractères chinois. Le GB2312 ne peut pas gérer certains caractères rares et traditionnels. Plus tard, un code appelé GBK a été créé sur la base du GB2312. GBK contient non seulement 27 484 caractères chinois, mais également des langues de minorités ethniques majeures telles que le tibétain, le mongol et l'ouïghour. De même, GBK est également compatible avec le codage ASCII. Les caractères anglais sont représentés par 1 octet et les caractères chinois sont représentés par deux octets.
UnicodeNous pouvons créer un sommet séparé pour traiter les caractères chinois et développer un ensemble de normes de codage en fonction de nos propres besoins. Cependant, les ordinateurs ne sont pas seulement utilisés par les Américains et les Chinois, mais utilisent également des caractères d'autres pays d'Europe et d'Asie. comme le japonais, on estime qu'il existe des centaines de milliers de caractères coréens provenant du monde entier, ce qui est bien au-delà de la plage que le code ASCII ou même GBK peut représenter. D'ailleurs, pourquoi les gens utilisent-ils votre norme GBK ? Comment exprimer une bibliothèque de personnages aussi énorme ? Ainsi, l'Organisation internationale United Alliance a proposé le codage Unicode. Le nom scientifique d'Unicode est « Jeu de caractères codés universels à plusieurs octets », appelé UCS.

Unicode a deux formats : UCS-2 et UCS-4. UCS-2 utilise deux octets pour coder, avec un total de 16 bits. En théorie, il peut représenter jusqu'à 65 536 caractères. Cependant, pour représenter tous les caractères du monde, 65 536 nombres ne suffisent évidemment pas, car les caractères chinois seuls en contiennent. près de 100 000, donc la spécification Unicode 4.0 définit un ensemble supplémentaire de codages de caractères. UCS-4 utilise 4 octets (en fait, seuls 31 bits sont utilisés et le bit le plus élevé doit être 0).
Unicode peut théoriquement couvrir les symboles utilisés dans toutes les langues. N'importe quel caractère dans le monde peut être représenté par un codage Unicode. Une fois le codage Unicode d'un caractère déterminé, il ne changera pas. Cependant, Unicode présente certaines limites. Lorsqu'un caractère Unicode est transmis sur le réseau ou finalement stocké, il ne nécessite pas nécessairement deux octets pour chaque caractère. Par exemple, un caractère « A » peut être représenté par un octet. deux octets, ce qui est évidemment une perte d'espace. Le deuxième problème est que lorsqu'un caractère Unicode est enregistré dans l'ordinateur, il s'agit d'une chaîne de nombres 01. Alors, comment l'ordinateur sait-il si un caractère Unicode de 2 octets représente un caractère de 2 octets ou deux caractères de 1 octet ? si vous n'en informez pas l'ordinateur à l'avance, l'ordinateur sera également confus. Unicode stipule uniquement comment encoder, mais ne précise pas comment transmettre ou enregistrer cet encodage. Par exemple, le codage Unicode du caractère "汉" est 6C49. Je peux utiliser 4 chiffres ASCII pour transmettre et sauvegarder ce codage ; je peux également utiliser 3 octets consécutifs E6 B1 89 codés en UTF-8 pour le représenter. La clé est que les deux parties à la communication doivent être d’accord. Par conséquent, le codage Unicode a différentes méthodes d'implémentation, telles que : UTF-8, UTF-16, etc. Ici, Unicode est comme l'anglais. C'est une norme universelle pour la communication entre les pays. Chaque pays a sa propre langue. Ils traduisent les documents anglais standard dans le texte de leur propre pays. C'est la méthode de mise en œuvre, tout comme UTF-8.
UTF-8 (Unicode Transformation Format), en tant qu'implémentation d'Unicode, est largement utilisé sur Internet. Il s'agit d'un codage de caractères de longueur variable qui peut utiliser 1 à 4 octets pour représenter un caractère en fonction de la situation spécifique. Par exemple, les caractères anglais qui peuvent initialement être exprimés en code ASCII ne nécessitent qu'un seul octet d'espace lorsqu'ils sont exprimés en UTF-8, ce qui est identique à l'ASCII. Pour les caractères multi-octets (n octets), les n premiers bits du premier octet sont définis sur 1, le n+1ème bit est défini sur 0 et les deux premiers bits des octets suivants sont définis sur 10. Les chiffres binaires restants sont remplis avec le code UNICODE du caractère.
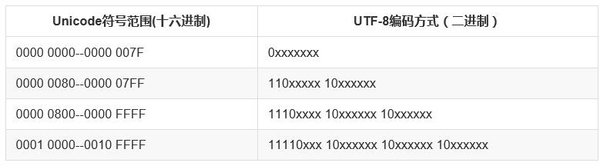
Prenons l'exemple du caractère chinois "好". L'Unicode correspondant de "好" est 597D et l'intervalle correspondant est 0000 0800 -- 0000 FFFF. Par conséquent, lorsqu'il est exprimé en UTF-8, il a besoin de 3 octets pour être stocké. . 597D est exprimé en binaire : 0101100101111101, remplissez à 1110xxxx 10xxxxxx 10xxxxxx pour obtenir 11100101 10100101 10111101, converti en hexadécimal : E5A5BD, donc l'encodage UTF-8 correspondant au "bon" Unicode "597D" est "E5A5". BD".
unicode 0101 100101 111101
Règles d'encodage 1110xxxx 10xxxxxx 10xxxxxx
--------------------------
utf-8 11100101 10100101 10111101
--------------------------
Hexadécimal utf-8 e 5 a 5 b d Encodage de caractères Python
Maintenant, j'ai enfin terminé la théorie. Parlons des problèmes de codage en Python. Python est né bien avant Unicode et le codage par défaut de Python est ASCII.
>>> importer le système
>>> sys.getdefaultencoding()
'ascii'
Par conséquent, si vous ne spécifiez pas explicitement l'encodage dans le fichier de code source Python, une erreur de syntaxe se produira
#test.py
imprimer "Bonjour"
Ce qui précède est le script test.py, exécutez
python test.py
L'erreur suivante sera incluse :
File “test.py”, line 1 yntaxError: Non-ASCII character ‘/xe4′ in file test.py on line 1, but no encoding declared;
Afin de prendre en charge les caractères non-ASCII dans le code source, le format d'encodage doit être explicitement spécifié sur la première ou la deuxième ligne du fichier source :
# coding=utf-8
ou :
#!/usr/bin/python # -*- coding: utf-8 -*-
Les types de données liés aux chaînes en Python sont str et unicode. Ce sont deux sous-classes de basestring. On peut voir que str et unicode sont deux types différents d'objets chaîne.
basestring
/ /
/ /
str unicode
Pour le même caractère chinois "好", lorsqu'il est exprimé en str, il correspond à l'encodage UTF-8 '/xe5/xa5/xbd', et lorsqu'il est exprimé en Unicode, son symbole correspondant est u'/u597d' , équivaut à toi "bien". Il convient d'ajouter que le format d'encodage spécifique des caractères de type str est UTF-8, GBK ou d'autres formats, selon le système d'exploitation. Par exemple, dans le système Windows, la ligne de commande cmd affiche :
# windows终端 >>> a = '好' >>> type(a) <type 'str'> >>> a '/xba/xc3'
Et ce qui est affiché dans la ligne de commande du système Linux est :
# linux终端 >>> a='好' >>> type(a) <type 'str'> >>> a '/xe5/xa5/xbd' >>> b=u'好' >>> type(b) <type 'unicode'> >>> b u'/u597d'
Qu'il s'agisse de Python3x, de Java ou d'autres langages de programmation, l'encodage Unicode est devenu le format d'encodage par défaut du langage. Lorsque les données sont finalement enregistrées sur le support, différents supports peuvent utiliser différentes méthodes. Certaines personnes aiment utiliser UTF-8. et certains Peu importe si les gens aiment utiliser GBK. Tant que la plate-forme dispose de normes de codage unifiées, la manière dont elle est mise en œuvre n'a pas d'importance.
Alors, comment convertir entre str et unicode en Python ? La conversion entre ces deux types de types de chaînes repose sur ces deux méthodes : décoder et encoder.
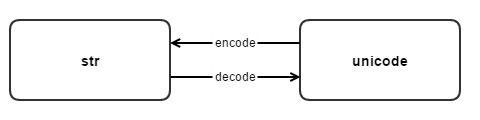
#从str类型转换到unicode
s.decode(encoding) =====> <type 'str'> to <type 'unicode'>
#从unicode转换到str
u.encode(encoding) =====> <type 'unicode'> to <type 'str'>
>>> c = b.encode('utf-8')
>>> type(c)
<type 'str'>
>>> c
'/xe5/xa5/xbd'
>>> d = c.decode('utf-8')
>>> type(d)
<type 'unicode'>
>>> d
u'/u597d'
This'/xe5/xa5/xbd' est la chaîne de type str codée en UTF-8 codée par Unicode u'ha' via la fonction encode. Vice versa, le type str c est décodé en chaîne Unicode d via la fonction decode.
str(s) contre unicode(s)str(s) et unicode(s) sont deux méthodes d'usine qui renvoient respectivement des objets chaîne str et des objets chaîne Unicode. str(s) est l'abréviation de s.encode('ascii'). Expérience :
>>> s3 = u"你好" >>> s3 u'/u4f60/u597d' >>> str(s3) Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
Le s3 ci-dessus est une chaîne de type Unicode. str(s3) équivaut à exécuter s3.encode('ascii'). Parce que les deux caractères chinois "Bonjour" ne peuvent pas être représentés par du code ASCII, une erreur est signalée. encoding. : s3.encode('gbk') ou s3.encode('utf-8') ne posera pas ce problème. Un Unicode similaire a la même erreur :
>>> s4 = "你好" >>> unicode(s4) Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xc4 in position 0: ordinal not in range(128) >>>
unicode(s4) équivaut à s4.decode('ascii')
, donc pour une conversion correcte, vous devez spécifier correctement son encodage s4.decode('gbk') ou s4.decode('utf-8').
Toutes les raisons des caractères tronqués peuvent être attribuées aux formats d'encodage incohérents utilisés dans le processus d'encodage des caractères après différents encodages et décodages, tels que :
# encoding: utf-8
>>> a='好'
>>> a
'/xe5/xa5/xbd'
>>> b=a.decode("utf-8")
>>> b
u'/u597d'
>>> c=b.encode("gbk")
>>> c
'/xba/xc3'
>>> print c
Le caractère codé en UTF-8 '好' occupe 3 octets. Après le décodage en Unicode, si vous utilisez GBK pour décoder, il ne fera que 2 octets de long. À la fin, des caractères tronqués apparaîtront, évitez donc les caractères tronqués. La meilleure façon est de toujours utiliser le même format d’encodage pour encoder et décoder les caractères.

Pour les chaînes au format Unicode (type str) :
s = 'id/u003d215903184/u0026index/u003d0/u0026st/u003d52/u0026sid'
Pour convertir en Unicode réel, vous devez utiliser :
s.decode('unicode-escape')
Test :
>>> s = 'id/u003d215903184/u0026index/u003d0/u0026st/u003d52/u0026sid/u003d95000/u0026i'
>>> print(type(s))
<type 'str'>
>>> s = s.decode('unicode-escape')
>>> s
u'id=215903184&index=0&st=52&sid=95000&i'
>>> print(type(s))
<type 'unicode'>
>>>
Les codes et concepts ci-dessus sont basés sur Python2.x.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment vérifier l'occupation (l'utilisation) du processeur sous Linux ?
- Qu'est-ce que la certification Linux ?
- Comment créer un répertoire de test dans le répertoire racine du système Linux
- Comment passer à l'utilisateur root dans le système Linux
- Comment utiliser la commande base64 pour crypter la commande Linux et l'exécuter