
Maison >Périphériques technologiques >IA >Analyse des fonctions d'activation de l'IA couramment utilisées : pratique d'apprentissage en profondeur de Sigmoid, Tanh, ReLU et Softmax
Analyse des fonctions d'activation de l'IA couramment utilisées : pratique d'apprentissage en profondeur de Sigmoid, Tanh, ReLU et Softmax

- 王林avant
- 2023-12-28 23:35:131396parcourir
Les fonctions d'activation jouent un rôle crucial dans l'apprentissage en profondeur. Elles peuvent introduire des caractéristiques non linéaires dans les réseaux neuronaux, permettant au réseau de mieux apprendre et simuler des relations entrées-sorties complexes. La sélection et l'utilisation correctes des fonctions d'activation ont un impact important sur les performances et l'effet d'entraînement des réseaux de neurones
Cet article présentera quatre fonctions d'activation couramment utilisées : Sigmoid, Tanh, ReLU et Softmax, depuis l'introduction, les scénarios d'utilisation, les avantages, inconvénients et solutions d'optimisation Explorez cinq dimensions pour vous fournir une compréhension complète des fonctions d'activation.

1. Fonction sigmoïde
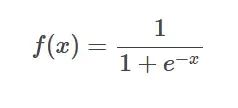 Formule de la fonction SIgmoïde
Formule de la fonction SIgmoïde
Introduction : La fonction sigmoïde est une fonction non linéaire couramment utilisée qui peut mapper n'importe quel nombre réel entre 0 et 1. Il est souvent utilisé pour convertir des valeurs prédites non normalisées en distributions de probabilité.
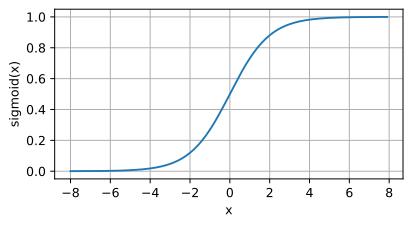 Image de la fonction SIgmoïde
Image de la fonction SIgmoïde
Scénario d'application :
- La sortie est limitée entre 0 et 1, représentant la distribution de probabilité.
- Gérez les problèmes de régression ou les problèmes de classification binaire.
Voici les avantages suivants :
- peut mapper n'importe quelle plage d'entrée sur entre 0 et 1, ce qui convient pour exprimer une probabilité.
- La portée est limitée, ce qui rend les calculs plus simples et plus rapides.
Inconvénients : Lorsque la valeur d'entrée est très grande, le gradient peut devenir très petit, conduisant au problème de disparition du gradient.
Schéma d'optimisation :
- Utilisez d'autres fonctions d'activation telles que ReLU : Utilisez d'autres fonctions d'activation en combinaison avec ReLU ou ses variantes (Leaky ReLU et Parametric ReLU).
- Utilisez des techniques d'optimisation dans les frameworks de deep learning : Utilisez des techniques d'optimisation fournies par des frameworks de deep learning (tels que TensorFlow ou PyTorch), telles que le découpage de dégradé, l'ajustement du taux d'apprentissage, etc.
2. Fonction Tanh
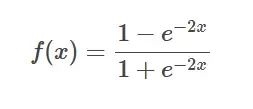 Formule de la fonction Tanh
Formule de la fonction Tanh
Introduction : La fonction Tanh est la version hyperbolique de la fonction sigmoïde, qui mappe n'importe quel nombre réel entre -1 et 1.
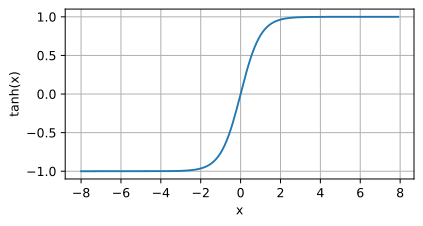 Image de la fonction Tanh
Image de la fonction Tanh
Scénario d'application : Lorsqu'une fonction plus raide que Sigmoïde est requise, ou dans certaines applications spécifiques qui nécessitent une sortie comprise entre -1 et 1.
Les avantages suivants sont les suivants : Elle offre une plage dynamique plus large et une courbe plus raide, ce qui peut accélérer la vitesse de convergence.
L'inconvénient de la fonction Tanh est que lorsque l'entrée est proche de ±1, sa dérivée se rapproche rapidement de 0. , provoquant la disparition du dégradé Problème
Solution d'optimisation :
- Utilisez d'autres fonctions d'activation telles que ReLU : Utilisez d'autres fonctions d'activation telles que ReLU ou ses variantes (Leaky ReLU et Parametric ReLU) en combinaison.
- Utilisation de la connexion résiduelle : La connexion résiduelle est une stratégie d'optimisation efficace, comme ResNet (réseau résiduel).
3, Fonction ReLU
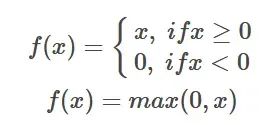 Formule de la fonction ReLU
Formule de la fonction ReLU
Introduction : La fonction d'activation ReLU est une fonction non linéaire simple, et son expression mathématique est f(x) = max( 0, x). Lorsque la valeur d'entrée est supérieure à 0, la fonction ReLU génère la valeur ; lorsque la valeur d'entrée est inférieure ou égale à 0, la fonction ReLU génère 0.
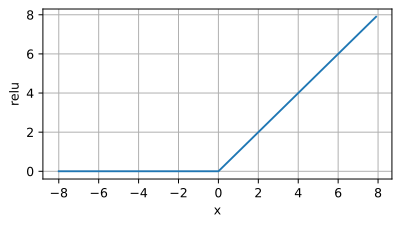 Image de la fonction ReLU
Image de la fonction ReLU
Scénario d'application : la fonction d'activation ReLU est largement utilisée dans les modèles d'apprentissage en profondeur, en particulier dans les réseaux de neurones convolutifs (CNN). Ses principaux avantages sont qu'il est simple à calculer, qu'il peut atténuer efficacement le problème de la disparition du gradient et qu'il peut accélérer la formation du modèle. Par conséquent, ReLU est souvent utilisé comme fonction d’activation préférée lors de la formation de réseaux neuronaux profonds.
Voici les avantages suivants :
- Atténuer le problème du gradient de disparition : Par rapport aux fonctions d'activation telles que Sigmoïde et Tanh, ReLU ne réduit pas le gradient lorsque la valeur d'activation est positive, évitant ainsi le gradient de disparition problème.
- Formation accélérée : En raison de la simplicité et de l'efficacité informatique de ReLU, il peut considérablement accélérer le processus de formation du modèle.
Inconvénients :
- Problème de « neurone mort » : Lorsque la valeur d'entrée est inférieure ou égale à 0, la sortie de ReLU est 0, provoquant la défaillance du neurone. Ce phénomène est appelé « . neurone mort "Yuan".
- Asymétrie : La plage de sortie de ReLU est [0, +∞), et la sortie est 0 lorsque la valeur d'entrée est négative, ce qui entraîne une distribution asymétrique de la sortie ReLU et limite la diversité de génération .
Schéma d'optimisation :
- Leaky ReLU : Leaky ReLU génère une pente plus petite lorsque l'entrée est inférieure ou égale à 0, évitant ainsi le problème complet du "neurone mort".
- Parametric ReLU (PReLU) : Différent de Leaky ReLU, la pente de PReLU n'est pas fixe, mais peut être apprise et optimisée en fonction des données.
4. Fonction Softmax
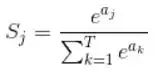 Formule de fonction Softmax
Formule de fonction Softmax
Introduction : Softmax est une fonction d'activation couramment utilisée, principalement utilisée dans les problèmes de multi-classification, qui peut convertir les neurones d'entrée en distribution de probabilité. Sa principale caractéristique est que la plage des valeurs de sortie est comprise entre 0 et 1 et que la somme de toutes les valeurs de sortie est 1.
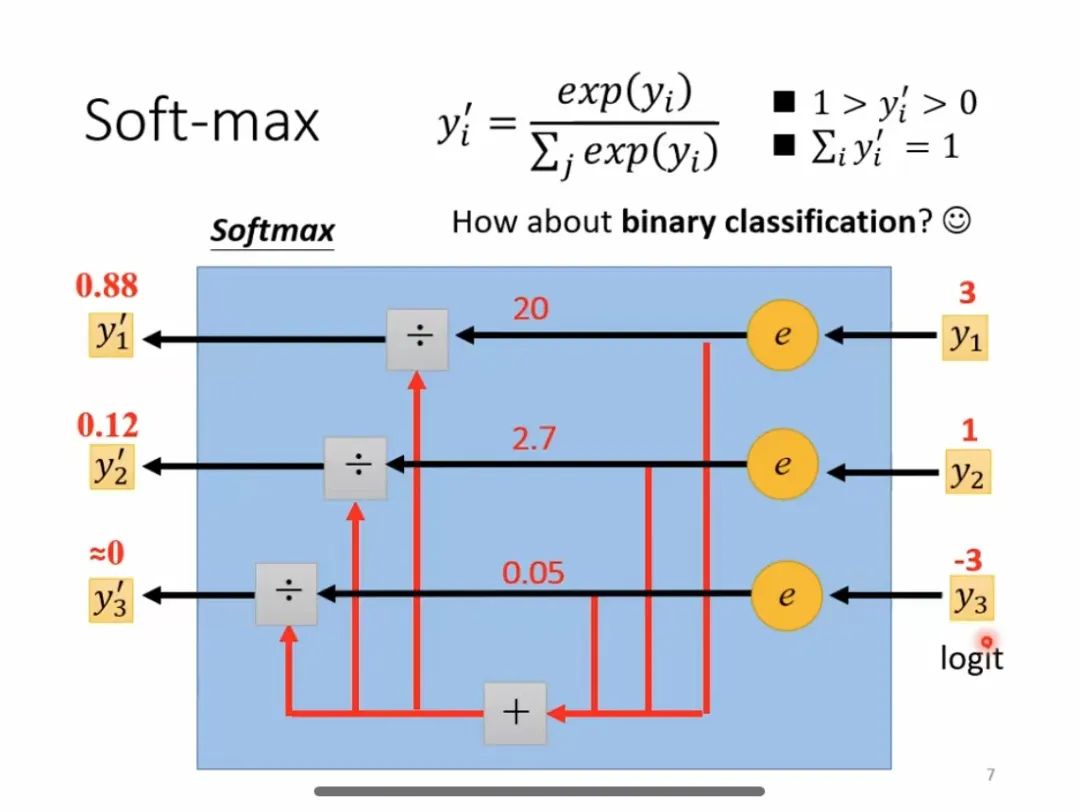 Processus de calcul Softmax
Processus de calcul Softmax
Scénario d'application :
- Dans les tâches multi-classifications, il est utilisé pour convertir la sortie du réseau neuronal en une distribution de probabilité.
- Largement utilisé dans le traitement du langage naturel, la classification d'images, la reconnaissance vocale et d'autres domaines.
Voici les avantages suivants : Dans les problèmes multi-classifications, une valeur de probabilité relative peut être fournie pour chaque catégorie afin de faciliter la prise de décision et la classification ultérieures.
Inconvénients : Il y aura des problèmes de disparition ou d'explosion de gradient.
Schéma d'optimisation :
- Utilisez d'autres fonctions d'activation telles que ReLU : Utilisez d'autres fonctions d'activation en combinaison avec ReLU ou ses variantes (Leaky ReLU et Parametric ReLU).
- Utilisez des techniques d'optimisation dans les frameworks d'apprentissage profond : Utilisez des techniques d'optimisation fournies par des frameworks d'apprentissage profond (tels que TensorFlow ou PyTorch), telles que la normalisation par lots, la décroissance du poids, etc.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!