
Maison >Périphériques technologiques >IA >Lancement d'un système gratuit et personnalisé de recommandation d'articles académiques - la « plateforme personnalisée arXiv » des meilleures équipes visuelles des universités allemandes
Lancement d'un système gratuit et personnalisé de recommandation d'articles académiques - la « plateforme personnalisée arXiv » des meilleures équipes visuelles des universités allemandes

- 王林avant
- 2023-12-27 17:49:401336parcourir
Une image est générée en 10 millisecondes, et 6 000 images sont générées en 1 minute. Quel est le concept ?
Dans l'image ci-dessous, vous pouvez ressentir profondément le super pouvoir de l'IA.
 Images
Images
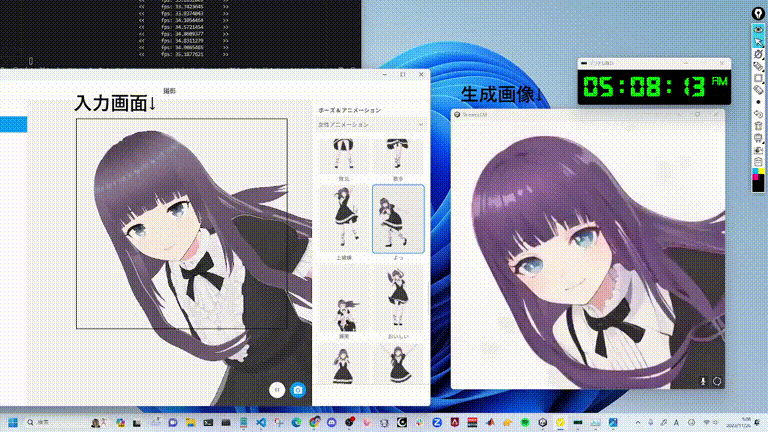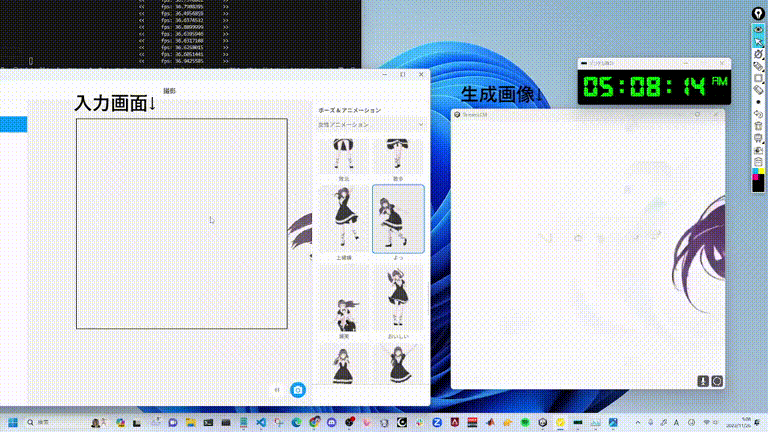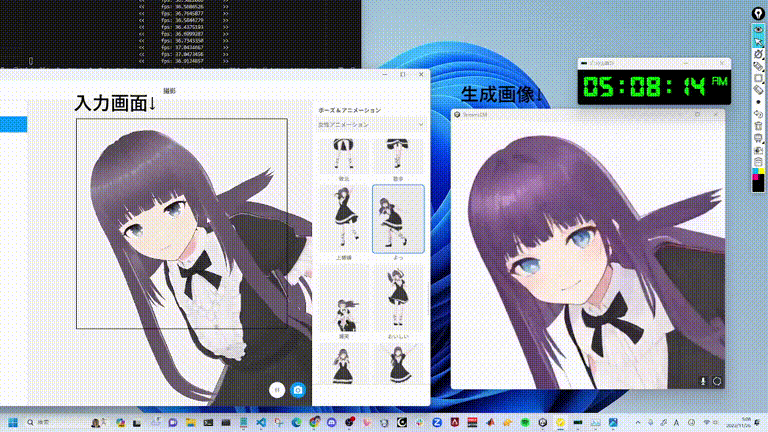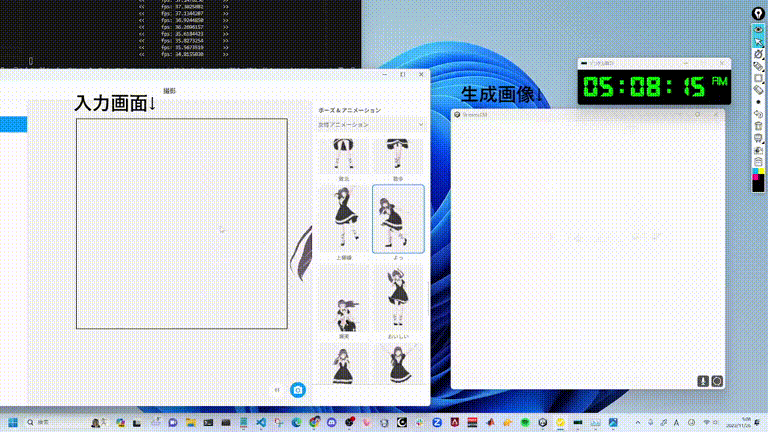
Même lorsque vous continuez à ajouter de nouveaux éléments aux invites générées par les images de fille en deux dimensions, les changements d'image de différents styles clignotent instantanément.
 Pictures
Pictures
Une vitesse de génération d'images en temps réel si étonnante est le résultat de StreamDiffusion proposé par des chercheurs de l'UC Berkeley, de l'Université de Tsukuba, au Japon, etc.
Cette toute nouvelle solution est un processus de modèle de diffusion qui permet la génération d'images interactives en temps réel à plus de 100 ips.
 Pictures
Pictures
Adresse papier : https://arxiv.org/abs/2312.12491
StreamDiffusion a directement dominé GitHub après avoir été open source, récoltant 3,7k étoiles.
 Pictures
Pictures
StreamDiffusion utilise de manière innovante une stratégie de traitement par lots au lieu du débruitage séquentiel, qui est environ 1,5 fois plus rapide que les méthodes traditionnelles. De plus, le nouvel algorithme de guidage sans classificateur résiduel (RCFG) proposé par l'auteur peut être 2,05 fois plus rapide que le guidage traditionnel sans classificateur.
La chose la plus remarquable est que la nouvelle méthode peut atteindre une vitesse de génération d'image à image de 91,07 ips sur RTX 4090.
 Pictures
Pictures
À l'avenir, dans différents scénarios tels que le métaverse, le rendu graphique de jeux vidéo et le streaming vidéo en direct, la génération rapide de StreamDiffusion pourra répondre aux besoins à haut débit de ces applications.
En particulier, la génération d'images en temps réel peut fournir de puissantes capacités d'édition et de création à ceux qui travaillent dans le développement de jeux et le rendu vidéo.
 Images
Images
Spécialement conçu pour la génération d'images en temps réel
Actuellement, dans divers domaines, l'application de modèles de diffusion nécessite des pipelines de diffusion à haut débit et à faible latence pour garantir l'efficacité de l'interaction homme-machine
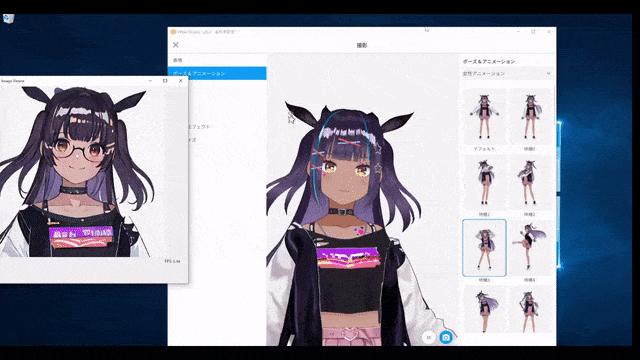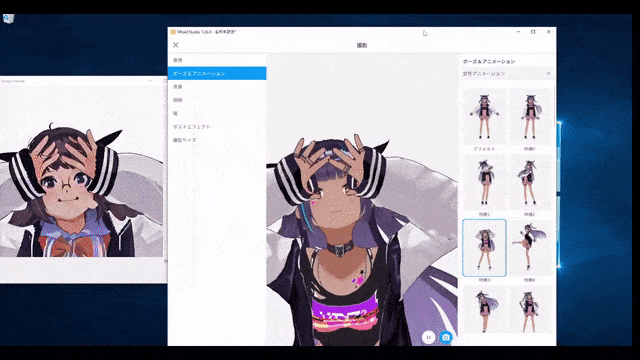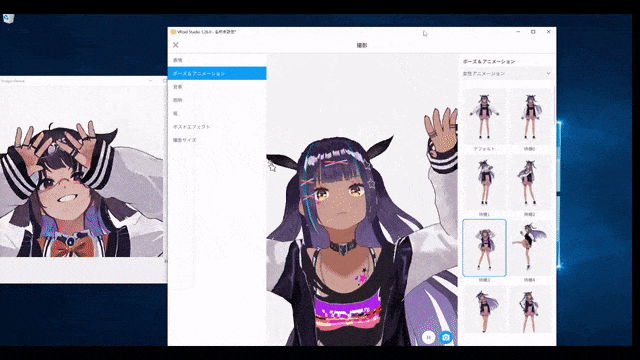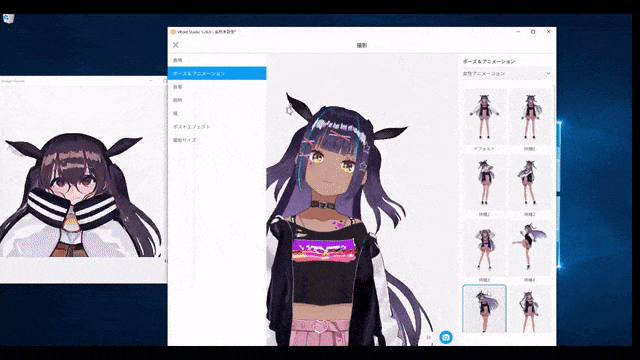
Un exemple typique consiste à utiliser le modèle de diffusion pour créer un personnage virtuel VTuber - capable de répondre en douceur aux entrées de l'utilisateur.
 Images
Images
Afin d'améliorer le haut débit et les capacités d'interaction en temps réel, l'orientation actuelle de la recherche se concentre principalement sur la réduction du nombre d'itérations de débruitage, par exemple en le réduisant de 50 itérations à plusieurs, voire un.
Une stratégie courante consiste à affiner le modèle de diffusion en plusieurs étapes en plusieurs étapes et à reconstruire le processus de diffusion à l'aide d'ODE. Pour améliorer l'efficacité, des modèles de diffusion ont également été quantifiés.
Dans le dernier article, les chercheurs sont partis de la direction orthogonale et ont introduit StreamDiffusion - un pipeline de diffusion en temps réel conçu pour un haut débit de génération d'images interactives.
Les travaux de conception de modèles existants peuvent être intégrés à StreamDiffusion tout en utilisant également des modèles de diffusion de débruitage en N étapes pour maintenir un débit élevé et offrir aux utilisateurs des options plus flexibles
 Images
Images
Génération d'images en temps réel|Première et deuxième colonnes : exemples de dessin en temps réel assisté par IA, troisième colonne : rendu en temps réel d'illustrations 2D à partir d'avatars 3D. Colonnes 4 et 5 : filtres de caméra en direct. Génération d'images en temps réel | Les première et deuxième colonnes montrent des exemples de dessin en temps réel assisté par l'IA, et la troisième colonne montre le processus de génération d'illustrations 2D en rendant des avatars 3D en temps réel. Les quatrième et cinquième colonnes montrent l'effet des filtres de caméra en temps réel
Comment est-il implémenté spécifiquement ?
StreamDiffusion Architecture
StreamDiffusion est un nouveau pipeline de diffusion conçu pour augmenter le débit.
Il se compose de plusieurs éléments clés :
Stratégie de traitement par lots en streaming, guidage sans classificateur résiduel (RCFG), file d'attente d'entrée et de sortie, filtre de similarité stochastique (Stochastic Similarity Filter), programme de précalcul, accélération du modèle de micro-encodeur automatique outils.
Débruitage par lots
Dans le modèle de diffusion, les étapes de débruitage sont effectuées en séquence, ce qui entraîne une augmentation du temps de traitement d'U-Net proportionnellement au nombre d'étapes.
Cependant, afin de générer des images haute fidélité, le nombre d'étapes doit être augmenté.
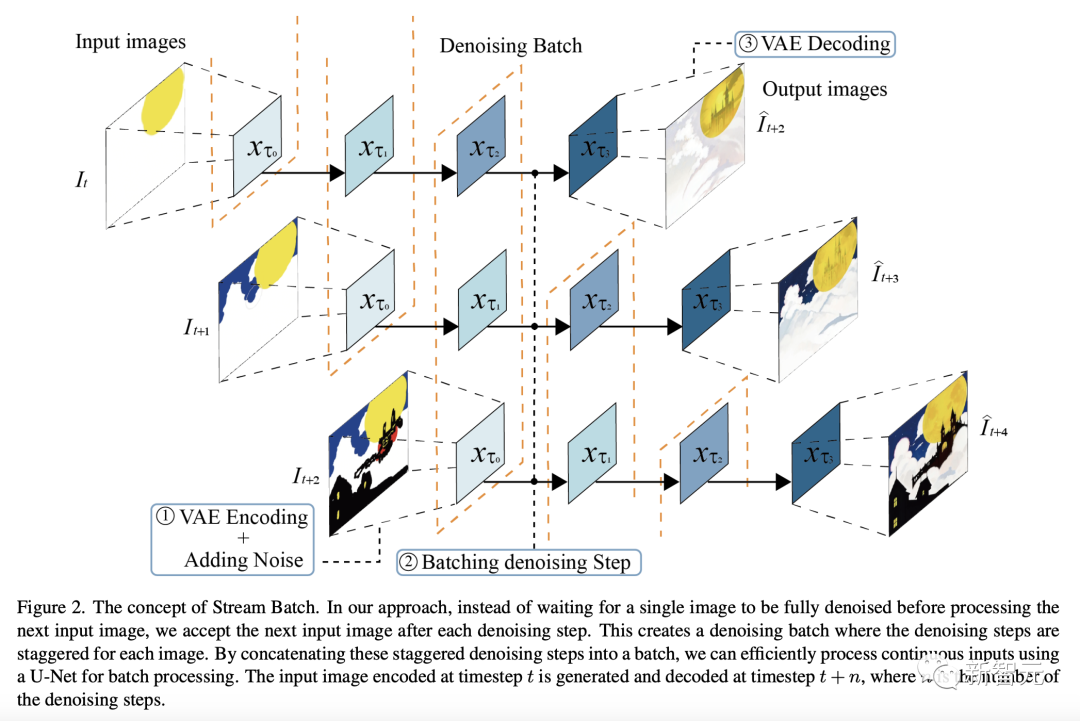
Pour résoudre le problème de la génération de latence élevée dans la diffusion interactive, les chercheurs ont proposé une méthode appelée Stream Batch.
Comme le montre la figure ci-dessous, dans les dernières méthodes, au lieu d'attendre qu'une seule image soit complètement débruitée avant de traiter l'image d'entrée suivante, l'image d'entrée suivante est acceptée après chaque étape de débruitage.
Cela forme un lot de débruitage, et les étapes de débruitage pour chaque image sont échelonnées.
En concaténant ces étapes de débruitage entrelacées en un lot, les chercheurs peuvent utiliser U-Net pour traiter efficacement des lots d'entrées consécutives.
L'image d'entrée codée au pas de temps t est générée et décodée au pas de temps t+n, où n est le nombre d'étapes de débruitage.
 Photos
Photos
Residual Classifier-Free Guidance (RCFG)
Common Classifier-Free Guidance (CFG) est une méthode qui effectue un vecteur entre un terme conditionnel inconditionnel ou négatif et un terme conditionnel primitif calculer . Un algorithme pour améliorer l'effet de la condition d'origine.
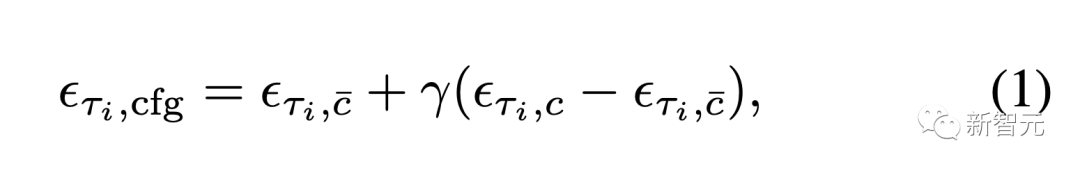 Images
Images
Cela peut apporter des avantages tels que l'amélioration de l'effet de l'invite.
Cependant, afin de calculer le bruit résiduel conditionnel négatif, chaque variable latente d'entrée doit être associée à une intégration conditionnelle négative et transmise à U-Net à chaque moment d'inférence.
Pour résoudre ce problème, l'auteur présente un bootstrapping sans classificateur résiduel innovant (RCFG)
Cette méthode utilise le bruit résiduel virtuel pour approximer les conditions négatives, de sorte que nous n'avons besoin que de pouvoir calculer le bruit conditionnel négatif, réduisant ainsi considérablement le coût de calcul supplémentaire de l'inférence U-Net lors de l'intégration conditionnelle négative à l'image de sortie nécessite un temps de traitement supplémentaire non négligeable.
Pour éviter d'ajouter ce temps de traitement d'image au pipeline d'inférence du réseau neuronal, nous séparons le pré- et post-traitement de l'image en différents threads, permettant un traitement parallèle.
De plus, en utilisant la file d'attente du tenseur d'entrée, il peut également faire face à des interruptions temporaires de l'image d'entrée dues à une panne de l'appareil ou à des erreurs de communication, permettant une diffusion fluide.
photos
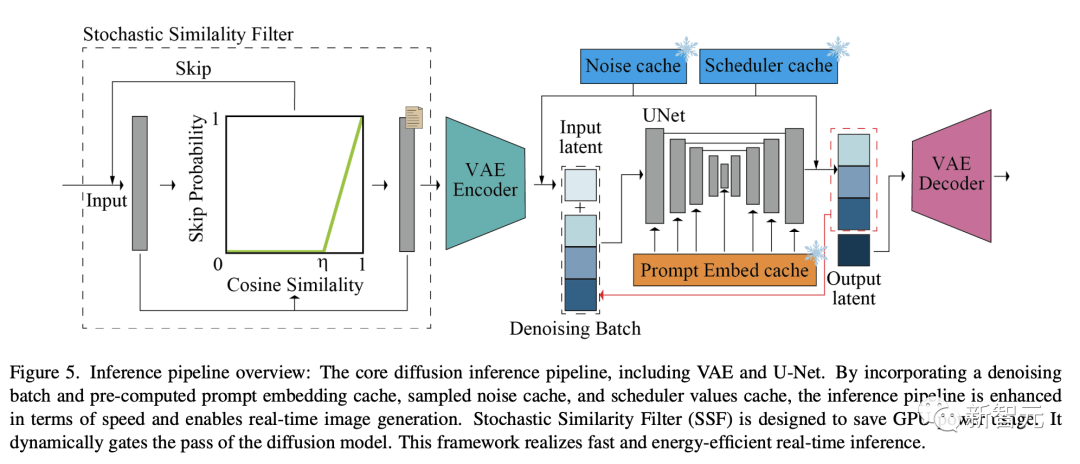
Filtre de similarité stochastique
Comme indiqué ci-dessous, le pipeline d'inférence de diffusion de base comprend VAE et U-Net.
Améliore la vitesse du pipeline d'inférence et permet la génération d'images en temps réel en introduisant le traitement par lots de débruitage et le cache d'intégration d'indices précalculés, le cache de bruit échantillonné et le cache de valeurs du planificateur.
Le filtrage de similarité stochastique (SSF) est conçu pour économiser la consommation d'énergie du GPU et peut fermer dynamiquement le pipeline du modèle de diffusion, permettant ainsi une inférence en temps réel rapide et efficace.
 Image
Image
Pré-calcul
L'architecture U-Net nécessite à la fois des variables latentes d'entrée et des intégrations conditionnelles.
Normalement, l'intégration conditionnelle est dérivée de "l'intégration d'indices" et reste inchangée entre les différentes images.
Pour optimiser cela, les chercheurs précalculent les intégrations d'indices et les stockent dans le cache. En mode interactif ou en streaming, ce cache d'intégration d'indices précalculé est rappelé.
Dans U-Net, le calcul de la clé et de la valeur pour chaque image est implémenté sur la base d'intégrations d'indices pré-calculées
Par conséquent, les chercheurs ont modifié U-Net pour stocker ces paires clé et valeur, le rendant ainsi réutilisable . Chaque fois que l'invite de saisie est mise à jour, les chercheurs recalculent et mettent à jour ces paires clé et valeur dans U-Net.
Accélération du modèle et petits encodeurs automatiques
Pour optimiser la vitesse, nous avons configuré le système pour utiliser une taille de lot statique et des tailles d'entrée fixes (hauteur et largeur).
Cette approche garantit que le graphique de calcul et l'allocation de mémoire sont optimisés pour une taille d'entrée spécifique, ce qui entraîne un traitement plus rapide.
Cependant, cela signifie que si vous devez traiter des images de formes différentes (c'est-à-dire différentes hauteurs et largeurs), utilisez différentes tailles de lot (y compris la taille du lot pour l'étape de débruitage).
Évaluation expérimentale
Évaluation quantitative des lots de débruitage
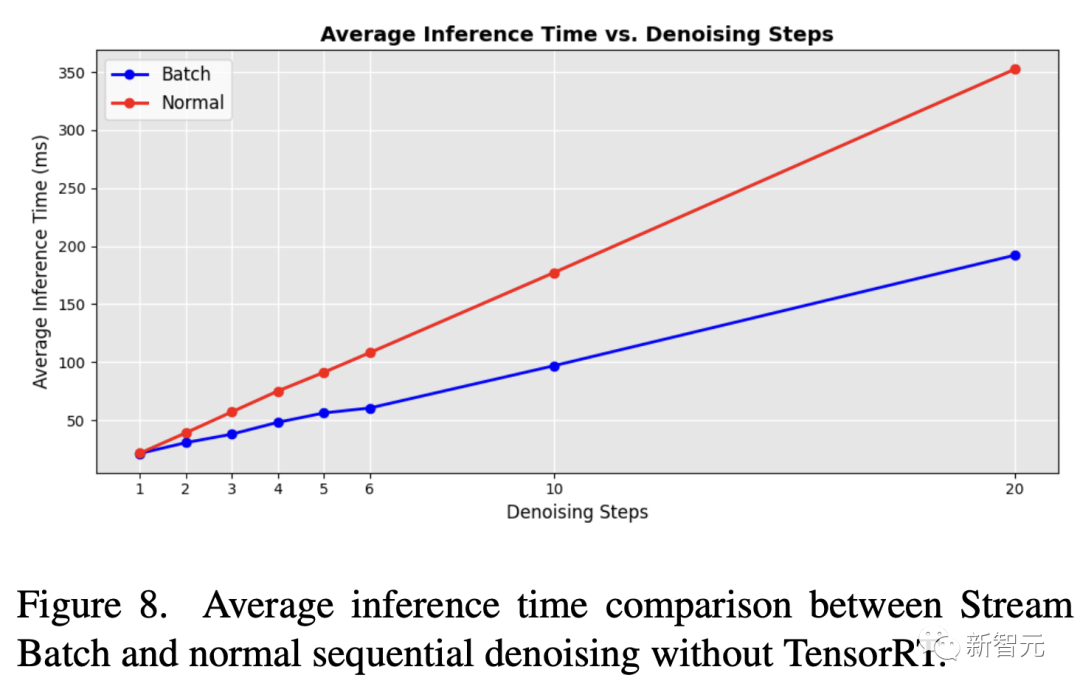
La figure 8 montre la comparaison de l'efficacité du débruitage par lots et des boucles U-Net séquentielles originales
Lors de la mise en œuvre de la stratégie de débruitage par lots, les chercheurs ont constaté que les temps de traitement ont amélioré de manière significative. Cela réduit le temps de moitié par rapport aux boucles U-Net traditionnelles avec des étapes de débruitage séquentielles.
Même avec l'outil d'accélération du module neuronal TensorRT appliqué, le traitement par lots de flux proposé par les chercheurs peut encore améliorer considérablement l'efficacité du pipeline de diffusion séquentielle d'origine dans différentes étapes de débruitage.
 Image
Image
De plus, les chercheurs ont comparé la dernière méthode avec le pipeline AutoPipeline-ForImage2Image développé par Huggingface Diffusers.
La comparaison du temps d'inférence moyen est présentée dans le tableau 1. Le dernier pipeline montre que la vitesse a été considérablement améliorée.
Lors de l'utilisation de TensorRT, StreamDiffusion est capable d'atteindre une accélération de 13x lors de l'exécution de 10 étapes de débruitage. Lorsqu'une seule étape de débruitage est impliquée, l'augmentation de la vitesse peut atteindre 59,6 fois
Même sans TensorRT, StreamDiffusion est 29,7 fois plus rapide qu'AutoPipeline lors de l'utilisation du débruitage en une seule étape, et s'améliore 8,3 fois lors de l'utilisation du débruitage en 10 étapes.
 Photos
Photos
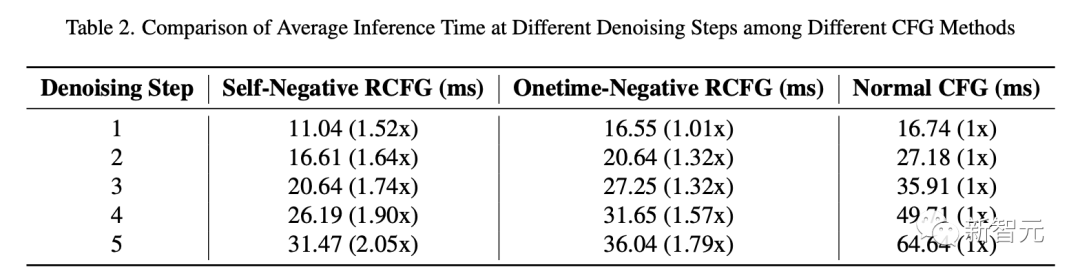
Le tableau 2 compare le temps d'inférence du pipeline de diffusion de flux utilisant RCFG et CFG régulier.
Dans le cas d'un débruitage en une seule étape, le temps d'inférence du RCFG Onetime-Negative et du CFG traditionnel est presque le même.
Ainsi, le temps d'inférence du RCFG unique et du CFG traditionnel en débruitage en une seule étape est presque le même. Cependant, à mesure que le nombre d’étapes de débruitage augmente, l’amélioration de la vitesse d’inférence du CFG traditionnel au RCFG devient plus évidente.
À l'étape 5 du débruitage, le RCFG auto-négatif est 2,05 fois plus rapide que le CFG traditionnel, et le RCFG Onetime-Negative est 1,79 fois plus rapide que le CFG traditionnel.
 Photos
Photos
 Photos
Photos
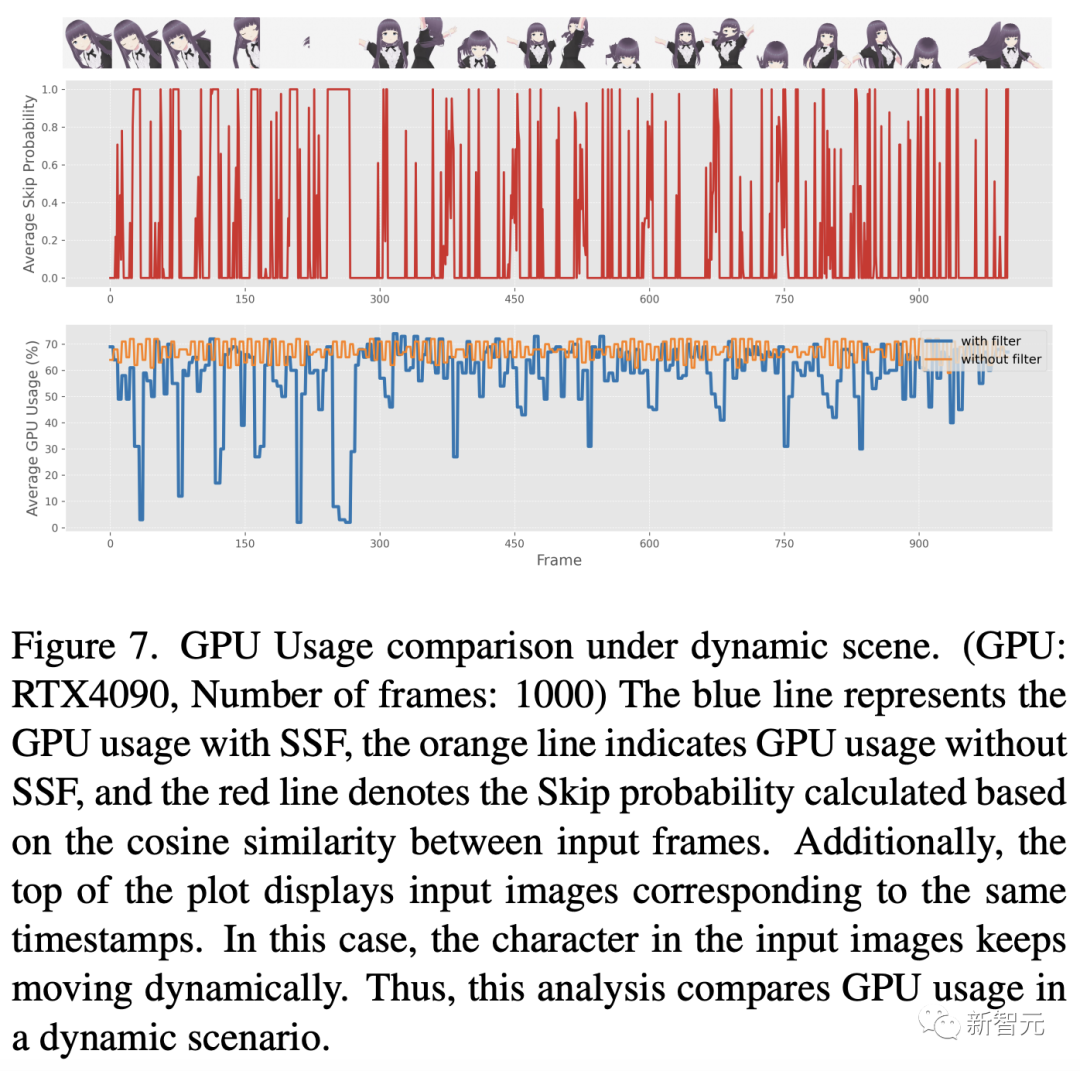
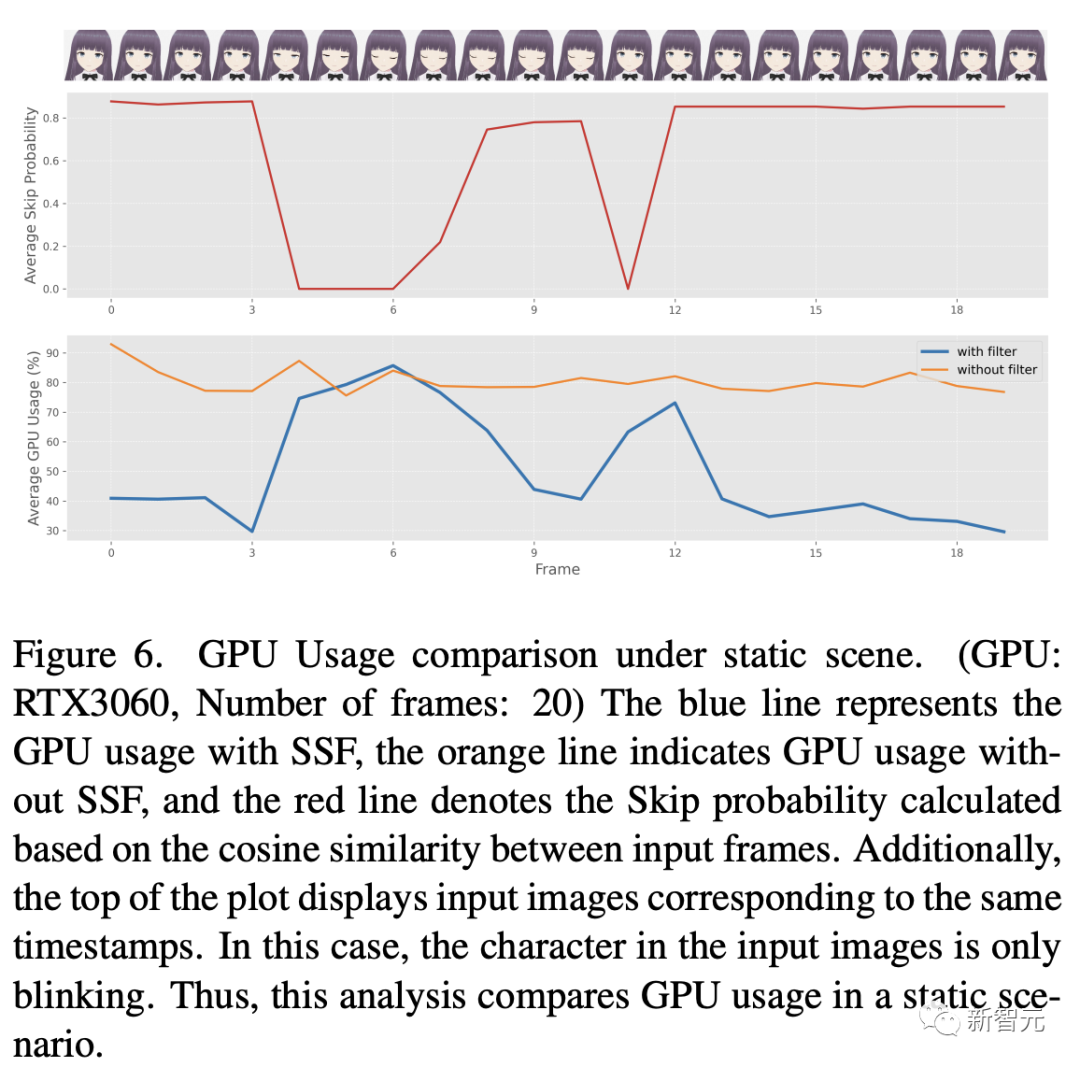
Après cela, les chercheurs ont mené une évaluation complète de la consommation d'énergie du SSF proposé. Les résultats de ce processus sont visibles dans les figures 6 et 7.
Ces figures illustrent le modèle d'utilisation du GPU lors de l'application de SSF (en définissant le seuil η à 0,98) à la vidéo d'entrée pour des scènes contenant des caractéristiques statiques périodiques
L'analyse comparative montre que lorsque les images d'entrée sont principalement des images statiques et présentent un degré élevé de similitude, l'utilisation de SSF peut réduire considérablement l'utilisation du GPU.
 Photos
Photos
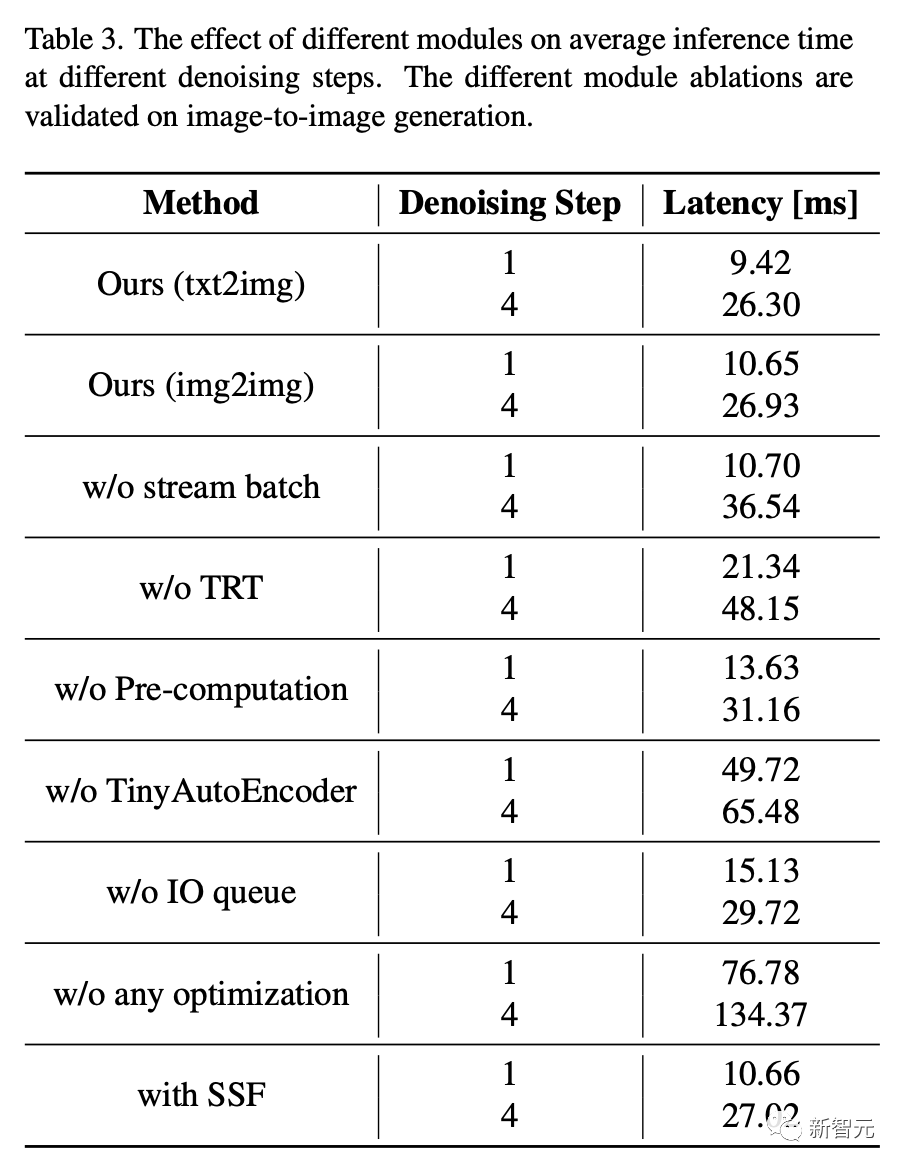
Étude d'ablation
L'impact de différents modules sur le temps d'inférence moyen sous différentes étapes de débruitage est présenté dans le tableau 3. Comme on peut le voir, la réduction des différents modules se vérifie dans le processus de génération image à image. 🎙 , sans utiliser aucune forme de CFG, montre des indices d'alignement faibles, notamment dans des aspects tels que les changements de couleur ou l'ajout d'éléments inexistants, qui ne sont pas implémentés efficacement.
 En revanche, l'utilisation de CFG ou RCFG améliore la capacité de modifier l'image originale, comme changer la couleur des cheveux, ajouter des motifs corporels ou même inclure des objets comme des lunettes. Notamment, l’utilisation du RCFG peut améliorer l’influence des signaux par rapport au CFG standard.
En revanche, l'utilisation de CFG ou RCFG améliore la capacité de modifier l'image originale, comme changer la couleur des cheveux, ajouter des motifs corporels ou même inclure des objets comme des lunettes. Notamment, l’utilisation du RCFG peut améliorer l’influence des signaux par rapport au CFG standard.
Images
Enfin, la qualité des résultats standard de génération de texte en image est illustrée dans la figure 11.
En utilisant le modèle sd-turbo, vous pouvez générer des images de haute qualité comme celle présentée dans la figure 11 en une seule étape.
Lors de l'utilisation du pipeline de diffusion de flux et du modèle sd-turbo proposés par les chercheurs pour générer des images dans l'environnement du GPU : RTX 4090, CPU : Core i9-13900K, OS : Ubuntu 22.04.3 LTS, il atteint plus de 100 ips Il est possible de produire des images de cette qualité à un rythme rapide.
 Photos
Photos
Les internautes ont commencé et une grande vague de femmes en deux dimensions est arrivée
Le code du dernier projet est open source et il a collecté 3,7 000 étoiles sur Github.
Pictures
Adresse du projet : https://github.com/cumulo-autumn/StreamDiffusion
images
 et animation en temps réel.
et animation en temps réel.
Photos
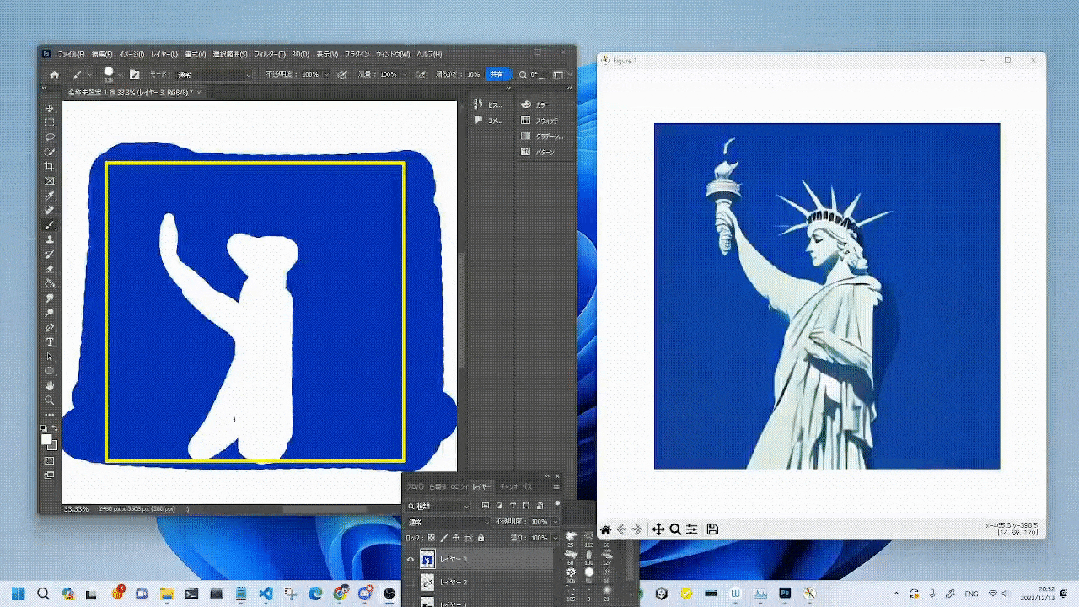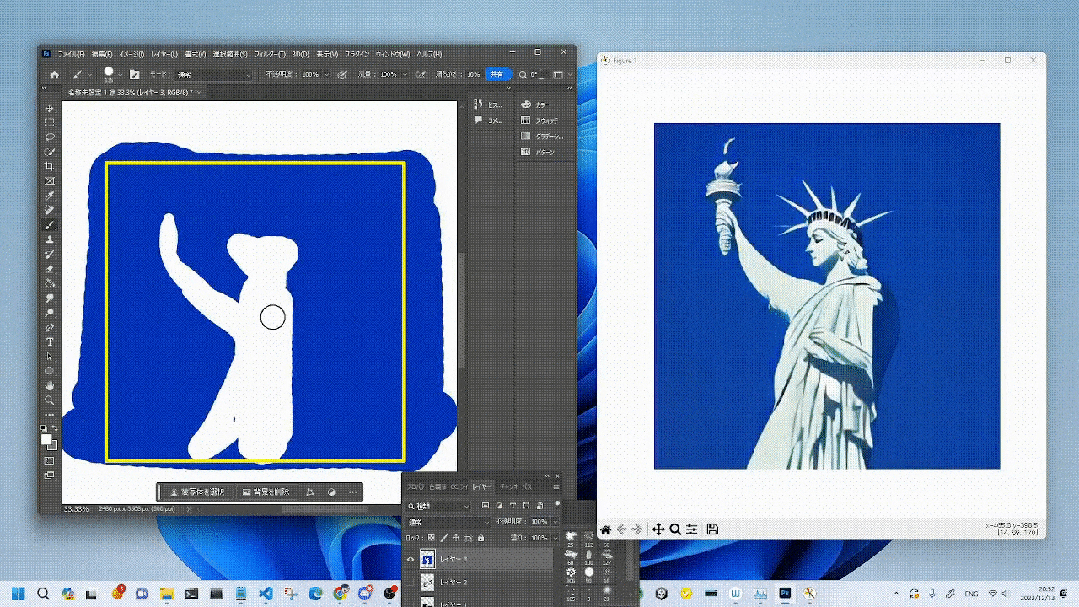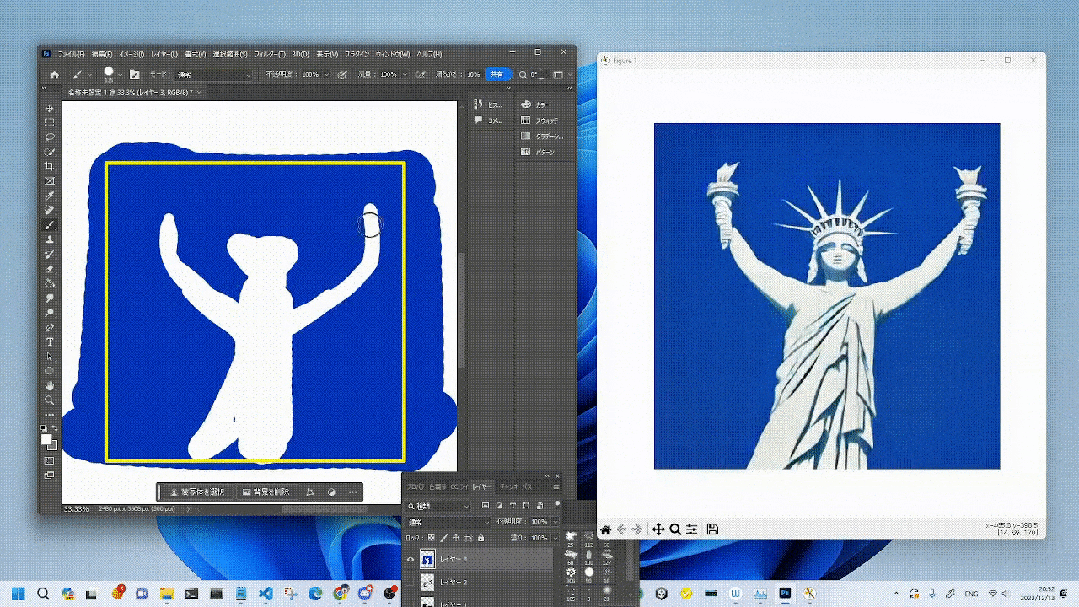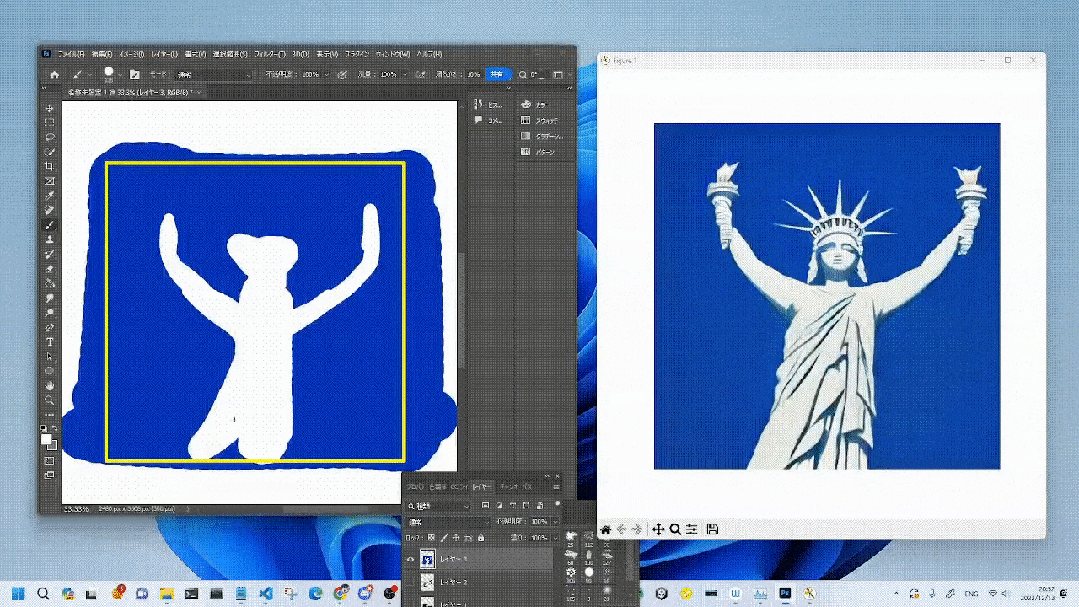
Génération dessinée à la main à une vitesse 10x.
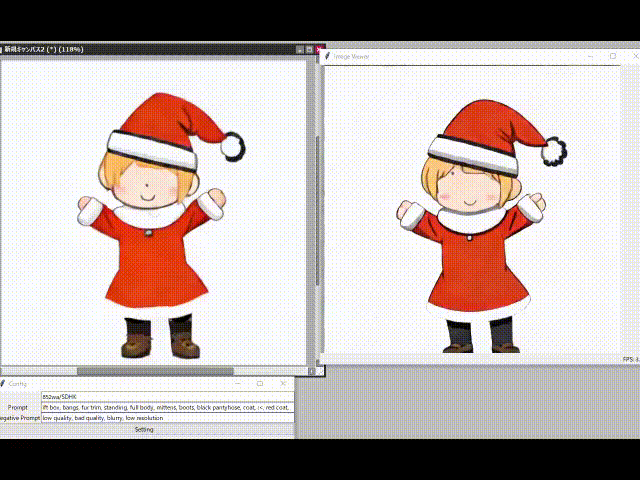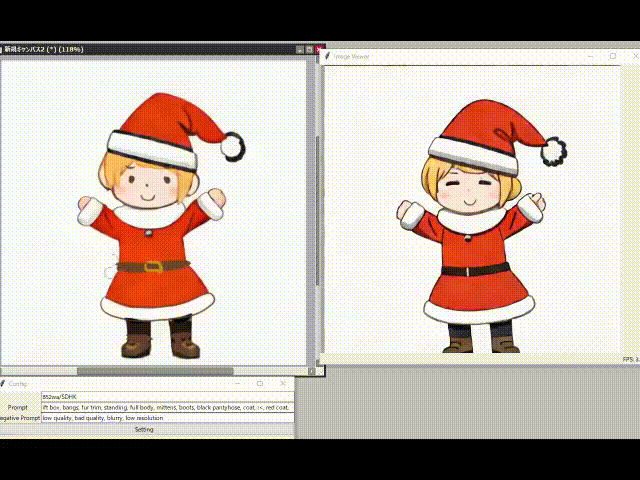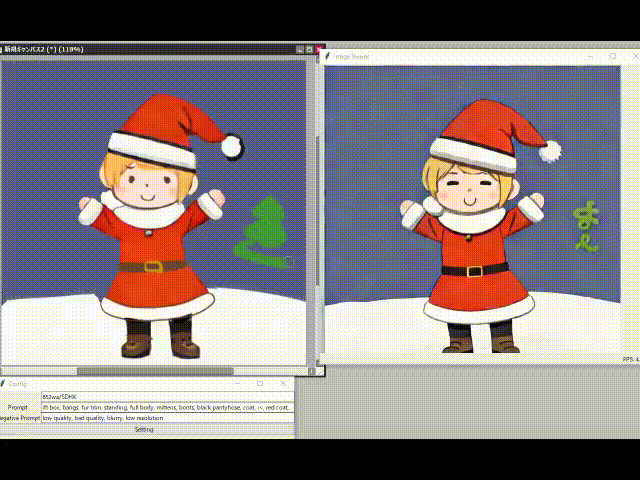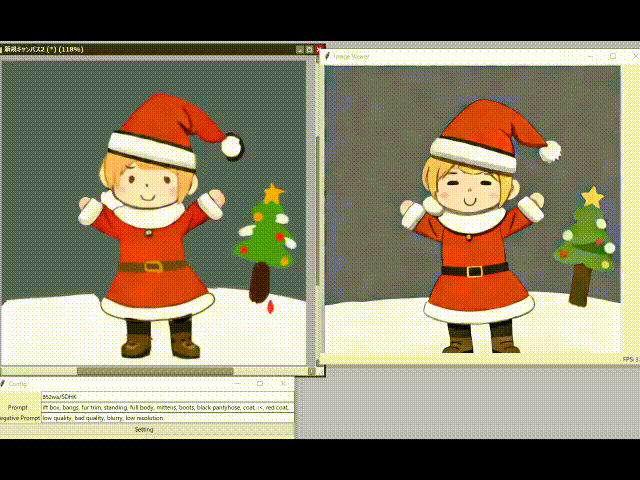 Photos
Photos
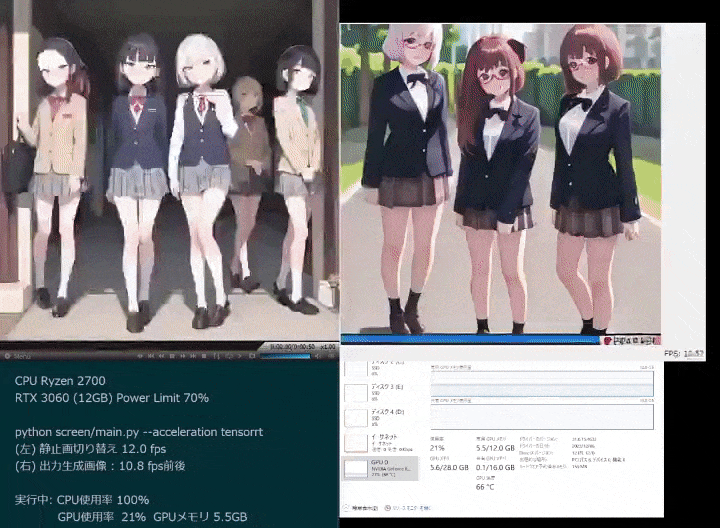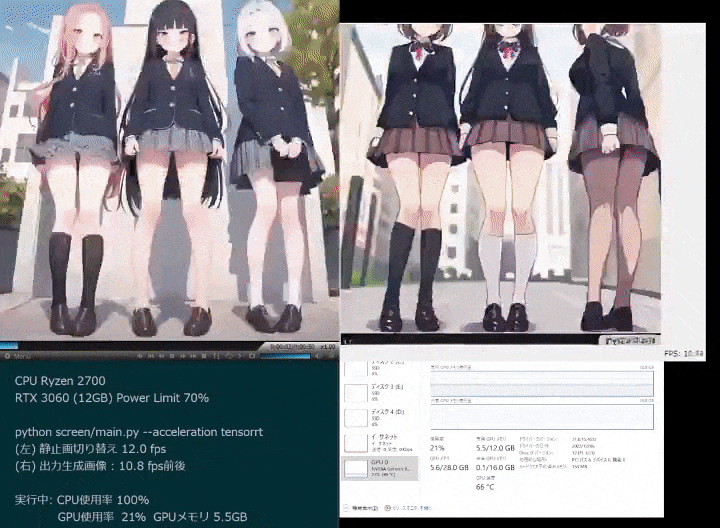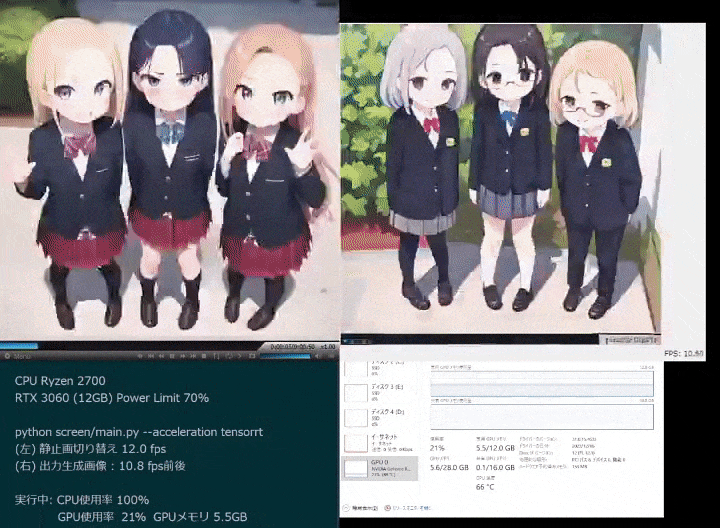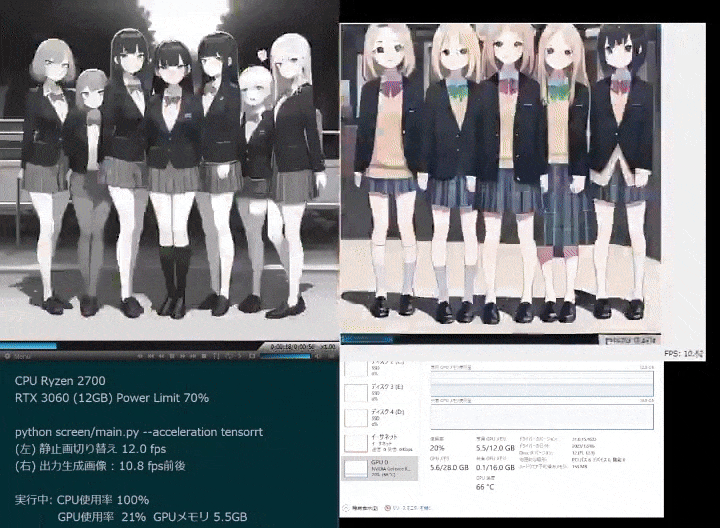 Photos
Photos
 Photos
Photos
Pour ceux qui s'intéressent aux chaussures pour enfants, pourquoi ne pas le faire vous-même.
Références :
https://www.php.cn/link/f9d8bf6b7414e900118caa579ea1b7be
https://www.php.cn/link/75a6e59 93aefba4f6cb07254637a6133
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment puis-je modifier le code du programme sur mon téléphone mobile ? (Recommandation de logiciel)
- Comment activer le système win10 sans clé ?
- Que dois-je faire si mon ordinateur portable ne parvient pas à démarrer le système ?
- L'intelligence basée sur le silicium fait une grande apparition au salon de l'intelligence artificielle de Tokyo 2023, et les humains numériques IA entrent sur le marché japonais
- La créativité de Google au Japon brille : le chapeau avec clavier QWERTY fait des débuts époustouflants