
Maison >Périphériques technologiques >IA >He Kaiming coopère avec le MIT : un cadre simple réalise la dernière percée en matière de génération d'images inconditionnelles
He Kaiming coopère avec le MIT : un cadre simple réalise la dernière percée en matière de génération d'images inconditionnelles

- 王林avant
- 2023-12-15 09:57:28970parcourir
Le grand patron He Yuming n'a pas encore officiellement rejoint le MIT, mais la première recherche collaborative avec le MIT est sortie :
Lui et les enseignants et étudiants du MIT ont développé un cadre de génération d'images auto-conditionnelles, appelé RCG ( Le code est open source) .
Cette structure de framework est très simple mais l'effet est exceptionnel. Elle implémente directement le nouveau SOTA de génération d'images inconditionnelles sur l'ensemble de données ImageNet-1K.
Les images qu'il génère ne nécessitent aucune annotation humaine (c'est-à-dire des mots d'invite, des étiquettes de classe, etc.) , et peuvent atteindre à la fois fidélité et diversité.

De cette façon, il améliore non seulement considérablement le niveau de génération d'images inconditionnelles, mais rivalise également avec les meilleures méthodes de génération conditionnelle actuelles.
Selon les mots de l'équipe de He Yuming :
L'écart de performance de longue date entre les tâches de génération conditionnelle et inconditionnelle a enfin été comblé en ce moment.
Alors, comment ça se passe exactement ?
Génération auto-conditionnelle similaire à l'apprentissage auto-supervisé
Tout d'abord, la génération dite inconditionnelle signifie que le modèle capture directement le contenu de génération de distribution de données sans l'aide de signaux d'entrée.
Cette méthode de formation est difficile, il y a donc toujours eu un écart de performance important avec la génération conditionnelle - tout comme l'apprentissage non supervisé ne peut pas être comparé à l'apprentissage supervisé
Tout comme l'apprentissage auto-supervisé est apparu, il a également changé cette situation
Dans le domaine de la génération inconditionnelle d’images, il existe également une méthode de génération auto-conditionnelle similaire au concept d’apprentissage auto-supervisé.
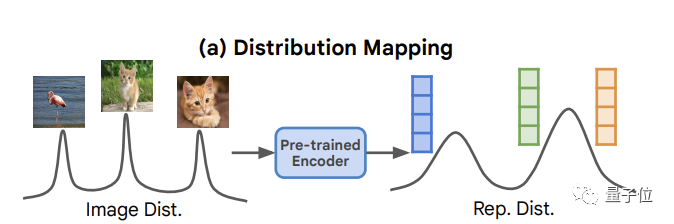
Par rapport à la génération inconditionnelle traditionnelle qui mappe simplement la distribution du bruit à la distribution de l'image, cette méthode définit principalement le processus de génération de pixels sur une distribution de représentation dérivée de la distribution des données elle-même.
Il devrait aller au-delà de la génération d'images conditionnelles et promouvoir le développement d'applications telles que la la conception moléculaire ou la découverte de médicamentsqui ne nécessitent pas d'annotation humaine (C'est pourquoi la génération d'images conditionnelles se développe si bien, nous devons également y prêter attention à la génération inconditionnelle).
Maintenant, sur la base de ce concept de génération autoconditionnelle, l'équipe de He Kaiming a d'abord développé un modèle de diffusion de représentation RDM.
Intercepté à partir de l'image via un encodeur d'image auto-supervisé, principalement utilisé pour générer une représentation d'image auto-supervisée de basse dimension
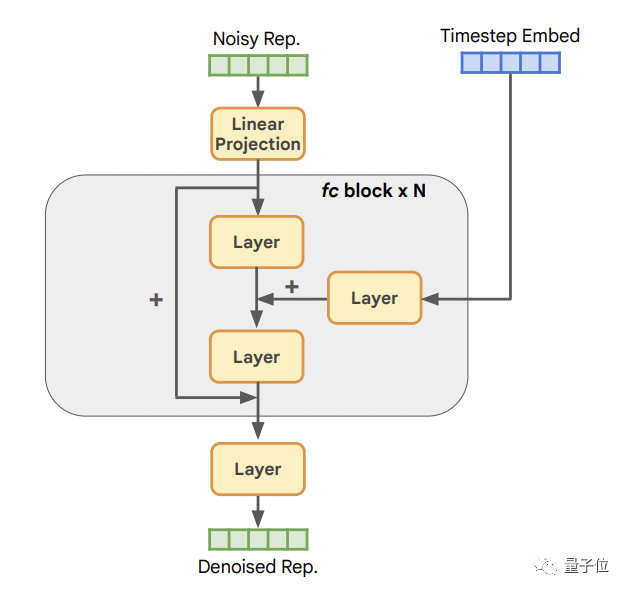
Son architecture de base est la suivante :
La première est la couche d'entrée, qui est responsable de projeter la représentation dans la dimension cachée C , suivi de N blocs entièrement connectés, et enfin d'une couche de sortie, qui est chargée de reprojeter (convertir) les caractéristiques latentes de la couche cachée dans la dimension de représentation d'origine.
Chaque couche comprend une couche LayerNorm, une couche SiLU et une couche linéaire.
Un tel RDM présente deux avantages :
L'une de ses caractéristiques est qu'il a une forte diversité, et l'autre est que la charge de calcul est faible
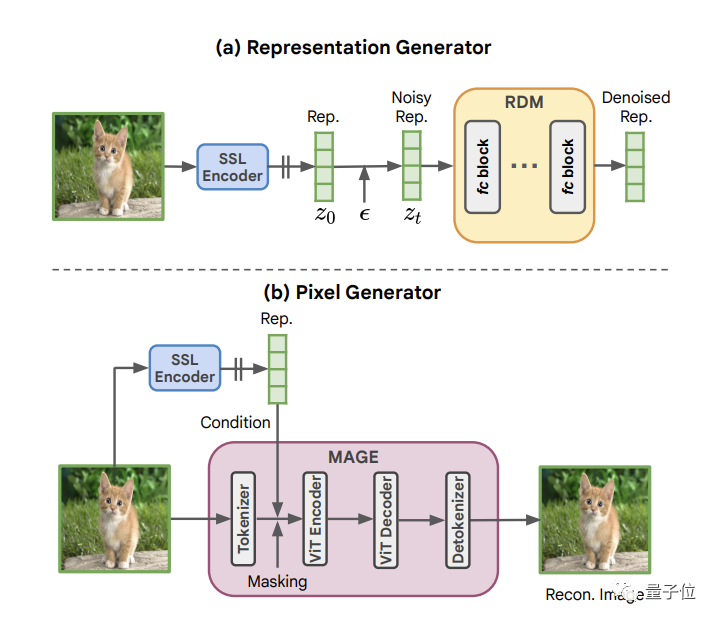
Après cela, l'équipe a proposé le protagoniste d'aujourd'hui avec l'aide de RDM : représente l'architecture de génération d'images conditionnelles RCG
Il s'agit d'un simple cadre de génération auto-conditionnelle composé de trois composants :
L'un est un encodeur d'image SSL , qui est utilisé pour convertir la distribution d'image en un compact représente la distribution.
L'un est le RDM, qui est utilisé pour modéliser et échantillonner cette distribution.
Le dernier est un générateur de pixels MAGE, qui sert à traiter l'image en fonction de la représentation.
MAGE fonctionne en ajoutant un masque aléatoire à l'image tokenisée et en demandant au réseau de reconstruire le jeton manquant en fonction de la représentation extraite de la même image
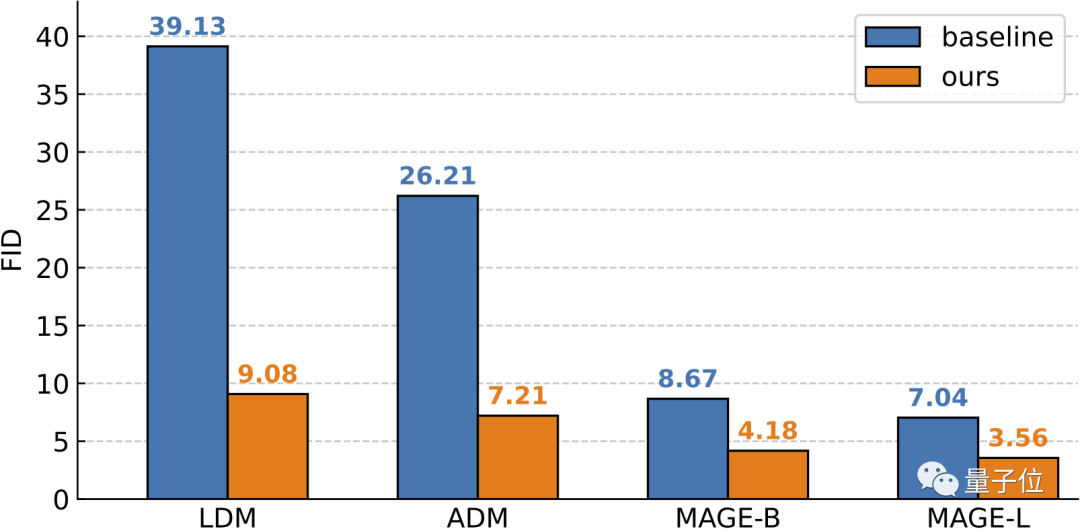
Après les tests, il a été constaté que les résultats finaux ont montré que malgré le La structure de ce cadre de génération autoconditionnelle est simple, mais son effet est très bon sur ImageNet 256×256, RCG a atteint un FID de
3,56 et un IS de 186,9 (Inception Score). En comparaison, la méthode de génération inconditionnelle la plus puissante avant elle a un score FID de 7,04 et un score IS de 123,5.
Pour RCG, non seulement il fonctionne bien en génération conditionnelle, mais il fonctionne également au même niveau, voire dépasse les modèles de référence dans ce domaine
Enfin, sans conseils de classificateur, les performances de RCG peuvent encore être améliorées à 3,31(FID) et 253.4(EST).
L'équipe a exprimé :
Ces résultats montrent que le modèle de génération d'images conditionnelles a un grand potentiel et pourrait annoncer une nouvelle ère dans ce domaine
Présentation de l'équipe
Il y a trois auteurs dans cet article :

Un. auteur Il s'agit de Li Tianhong, doctorant au MIT. Il est diplômé de la classe Yao de l'Université Tsinghua avec son diplôme de premier cycle. Son domaine de recherche est la technologie de détection intégrée multimodale. Sa page d'accueil personnelle est très intéressante, et il possède également une collection de recettes - la recherche et la cuisine sont les deux choses qui le passionnent le plus
L'autre auteur est du département de génie électrique et d'informatique du MIT. (EECS)  La professeure Dina Katabi, directrice du MIT Wireless Networks and Mobile Computing Center, est la lauréate du prix Sloan de cette année et a été élue académicien de l'Académie nationale des sciences.
La professeure Dina Katabi, directrice du MIT Wireless Networks and Mobile Computing Center, est la lauréate du prix Sloan de cette année et a été élue académicien de l'Académie nationale des sciences.
Enfin, l'auteur correspondant est He Mingming. Il retournera officiellement dans le monde universitaire l'année prochaine et quittera Meta pour rejoindre le Département de génie électrique et d'informatique du MIT, où il deviendra collègue de Dina Katabi.

Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/abs/2312.03701
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment créer et utiliser le modèle de modèle de framework Laravel
- À quelle couche du modèle de référence OSI correspond la couche de transport du modèle de référence TCP/IP ?
- Dans la conception de bases de données, quel est le processus de conversion du diagramme ER en modèle de données relationnelles ?
- Former BERT et ResNet sur un smartphone pour la première fois, réduisant ainsi la consommation d'énergie de 35 %
- Les programmeurs sont en danger ! On dit qu'OpenAI recrute des troupes d'externalisation dans le monde entier et forme étape par étape les agriculteurs de code ChatGPT.