
Maison >Périphériques technologiques >IA >NeuRAD : application de la technologie de rendu neuronal multi-ensembles de données de pointe dans la conduite autonome
NeuRAD : application de la technologie de rendu neuronal multi-ensembles de données de pointe dans la conduite autonome

- 王林avant
- 2023-12-05 11:21:022566parcourir
L'article "NeuRAD: Neural Rendering for Autonomous Driving", de Zenseact, Chalmers University of Technology, Linkoping University et Lund University.
 Les champs de rayonnement neuronal (NeRF) deviennent de plus en plus populaires dans la communauté de la conduite autonome (DA). Des méthodes récentes ont montré le potentiel des NeRF dans les simulations en boucle fermée, les tests de systèmes AD et les techniques d'augmentation des données de formation. Cependant, les méthodes existantes nécessitent souvent un long temps de formation, une supervision sémantique intensive et manquent de généralisabilité. Cela entrave à son tour l’application à grande échelle du NeRF dans la MA. Cet article propose NeuRAD, une nouvelle méthode robuste de synthèse de vues pour les données AD dynamiques. L'approche comprend une conception de réseau simple, une modélisation de capteurs comprenant des caméras et un lidar (y compris l'obturateur roulant, la divergence du faisceau et la chute de lumière) et fonctionne sur plusieurs ensembles de données prêts à l'emploi.
Les champs de rayonnement neuronal (NeRF) deviennent de plus en plus populaires dans la communauté de la conduite autonome (DA). Des méthodes récentes ont montré le potentiel des NeRF dans les simulations en boucle fermée, les tests de systèmes AD et les techniques d'augmentation des données de formation. Cependant, les méthodes existantes nécessitent souvent un long temps de formation, une supervision sémantique intensive et manquent de généralisabilité. Cela entrave à son tour l’application à grande échelle du NeRF dans la MA. Cet article propose NeuRAD, une nouvelle méthode robuste de synthèse de vues pour les données AD dynamiques. L'approche comprend une conception de réseau simple, une modélisation de capteurs comprenant des caméras et un lidar (y compris l'obturateur roulant, la divergence du faisceau et la chute de lumière) et fonctionne sur plusieurs ensembles de données prêts à l'emploi.
Comme le montre la figure : NeuRAD est une méthode de rendu neuronal adaptée aux scènes de voiture dynamiques. La posture du propre véhicule et des autres usagers de la route peut être modifiée et des participants peuvent être ajoutés et/ou supprimés librement. Ces caractéristiques font de NeuRAD une base idéale pour des composants tels que des simulateurs en boucle fermée réalistes ou de puissants moteurs d'augmentation des données.
 L'objectif de cet article est d'apprendre une représentation à partir de laquelle des données réelles de capteurs peuvent être générées, ce qui peut modifier la plate-forme du véhicule, la posture de l'acteur, ou les deux. On suppose qu'il existe un accès aux données collectées par la plate-forme mobile, constituées d'images de caméra définies et de nuages de points lidar, ainsi que d'estimations de la taille et de la pose de tout acteur mobile. Pour des raisons pratiques, la méthode doit être performante en termes d'erreur de reconstruction sur les principaux ensembles de données automobiles tout en réduisant au minimum le temps de formation et d'inférence.
L'objectif de cet article est d'apprendre une représentation à partir de laquelle des données réelles de capteurs peuvent être générées, ce qui peut modifier la plate-forme du véhicule, la posture de l'acteur, ou les deux. On suppose qu'il existe un accès aux données collectées par la plate-forme mobile, constituées d'images de caméra définies et de nuages de points lidar, ainsi que d'estimations de la taille et de la pose de tout acteur mobile. Pour des raisons pratiques, la méthode doit être performante en termes d'erreur de reconstruction sur les principaux ensembles de données automobiles tout en réduisant au minimum le temps de formation et d'inférence.
La figure montre un aperçu de la méthode proposée dans cet article NeuRAD : apprentissage d'un champ de caractéristiques neuronales conjointes statique et dynamique pour les scènes automobiles, distingué par un codage de hachage sensible aux acteurs. Les points situés dans le cadre de délimitation de l'acteur sont convertis en coordonnées locales de l'acteur et utilisés avec l'index de l'acteur pour interroger la grille de hachage 4D. Les caractéristiques de niveau de lumière rendues en volume sont décodées en valeurs RVB à l'aide d'un CNN de suréchantillonnage et en probabilités et intensités de chute de rayons à l'aide d'un MLP.
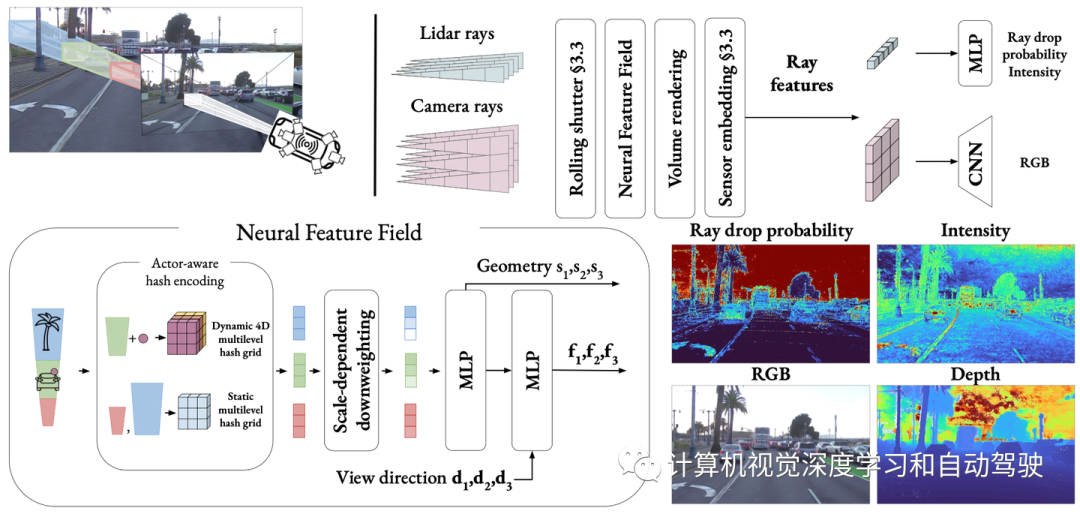 S'appuyant sur les travaux de synthèse de nouvelles vues [4, 47], les auteurs utilisent des champs de caractéristiques neuronales (NFF), des généralisations des NeRF [25] et des méthodes similaires [23] pour modéliser le monde.
S'appuyant sur les travaux de synthèse de nouvelles vues [4, 47], les auteurs utilisent des champs de caractéristiques neuronales (NFF), des généralisations des NeRF [25] et des méthodes similaires [23] pour modéliser le monde.
Afin de restituer l'image, un ensemble de rayons de caméra doit être rendu en volume pour générer une carte de caractéristiques F. Comme décrit dans l'article [47], un réseau de neurones convolutifs (CNN) est ensuite utilisé pour restituer l'image finale. Dans les applications pratiques, les cartes de caractéristiques ont une faible résolution et doivent être suréchantillonnées à l'aide de CNN pour réduire considérablement le nombre de requêtes de rayons
Les capteurs Lidar permettent aux véhicules autonomes de mesurer la profondeur et la réflectivité (intensité) d'un ensemble de points discrets). Ils ont déterminé la distance et la réflectivité de la puissance de retour en tirant des impulsions d'un faisceau laser et en mesurant le temps de vol. Pour capturer ces propriétés, les impulsions transmises par le capteur lidar d'attitude sont modélisées sous la forme d'un ensemble de rayons et des techniques de rendu de type volume sont utilisées.
Considérons un rayon laser qui ne renvoie aucun point. Si la puissance de retour est trop faible, un phénomène connu sous le nom de chute de rayons se produit, ce qui est important pour la modélisation réduisant les différences simulées-réelles [21]. En règle générale, cette lumière se propage suffisamment loin pour ne pas toucher une surface, ou elle atteint une surface où le faisceau rebondit dans un espace ouvert, tel qu'un miroir, un verre ou une chaussée mouillée. La modélisation de ces effets est importante pour une simulation réaliste des capteurs mais, comme indiqué dans [14], est difficile à capturer uniquement sur une base physique car ils reposent sur des détails (souvent non divulgués) de la logique de détection des capteurs de bas niveau. Par conséquent, nous choisissons d’apprendre la chute des rayons à partir des données. Semblable à l'intensité, les caractéristiques lumineuses peuvent être rendues volumétriquement et passées à travers un petit MLP pour prédire la probabilité de chute de lumière pd(r). A noter que contrairement à [14], l’écho secondaire du faisceau lidar n’est pas modélisé puisque cette information n’est pas présente dans les cinq jeux de données de l’expérience.
Étendez la définition du champ de caractéristiques neuronales (NFF) à la fonction d'apprentissage (s, f) = NFF (x, t, d), où x est la coordonnée spatiale, t représente le temps et d représente la direction de visualisation. Cette définition introduit le temps comme entrée, crucial pour modéliser les aspects dynamiques de la scène
Neural Architecture
L'architecture NFF suit la meilleure approche reconnue dans NeRF [4, 27]. Étant donné un emplacement x et une heure t, interrogez le code de hachage sensible à l'acteur. Cet encodage est ensuite introduit dans un petit MLP, qui calcule la distance signée s et les caractéristiques intermédiaires g. Le codage de la direction de vue d avec des harmoniques sphériques [27] permet au modèle de capturer les réflexions et autres effets liés à la vue. Enfin, le codage de direction et les caractéristiques intermédiaires sont traités conjointement via un deuxième MLP, amélioré avec des connexions sautées de g, ce qui donne la caractéristique f.
Composition de scène
Semblable aux travaux précédents [18, 29, 46, 47], nous divisons le monde en deux parties, à savoir un arrière-plan statique et un ensemble d'acteurs dynamiques rigides, chaque acteur est composé de Défini par une boîte englobante 3D et un ensemble de poses SO(3). Nous servons le double objectif de simplifier le processus d'apprentissage et de permettre un degré d'éditabilité qui permet à l'acteur de générer dynamiquement de nouveaux scénarios après la formation. Contrairement aux approches précédentes qui utilisaient des NFF distincts pour différents éléments de la scène, nous utilisons un seul NFF unifié dans lequel tous les réseaux sont partagés et la distinction entre les composants statiques et dynamiques est gérée de manière transparente par un codage de hachage sensible aux acteurs. La stratégie d'encodage est simple : encodez un échantillon donné (x, t) avec l'une des deux fonctions selon qu'il se trouve ou non dans le cadre de délimitation de l'acteur
Scène statique illimitée
à l'aide d'un réseau de hachage multi-résolution. Représentation en treillis de scènes statiques s'est avérée être une méthode de représentation très expressive et efficace. Cependant, pour mapper des scènes illimitées sur des maillages, nous adoptons la méthode de retrait proposée dans MipNerf-360. Cette approche peut représenter avec précision les éléments routiers proches et les nuages distants avec un seul maillage de hachage. En revanche, les méthodes existantes utilisent des NFF dédiés pour capturer le ciel et d'autres régions lointaines
Acteurs dynamiques rigides
Lorsqu'un échantillon (x, t) tombe dans la boîte englobante de l'acteur, sa coordonnée spatiale x et les directions de vision d sont transformées en système de coordonnées de l'acteur à un instant t donné. Ignorez ensuite l'aspect temporel et échantillonnez les caractéristiques d'une grille de hachage multi-résolution indépendante du temps, tout comme une scène statique. En termes simples, plusieurs grilles de hachage différentes doivent être échantillonnées séparément, une pour chaque acteur. Cependant, une seule grille de hachage 4D est utilisée, où la quatrième dimension correspond à l'index de l'acteur. Cette approche permet d'échantillonner toutes les fonctionnalités des acteurs en parallèle, obtenant ainsi des accélérations significatives tout en correspondant aux performances des grilles de hachage individuelles.
Problème de scène à plusieurs échelles
L'un des plus grands défis dans l'application du rendu neuronal aux données automobiles est la gestion des multiples niveaux de détail présents dans ces données. Lorsqu’une voiture parcourt une longue distance, elle voit de nombreuses surfaces, de loin comme de près. Dans ce cas multi-échelle, la simple application d'intégrations positionnelles d'iNGP [27] ou de NeRF peut conduire à des artefacts d'alias [2]. Pour résoudre ce problème, de nombreuses méthodes modélisent les rayons sous forme de tronc de tronc, la direction longitudinale du tronc de cône est déterminée par la taille du bac et la direction radiale est déterminée par la zone des pixels et la distance du capteur [2, 3, 13].
Zip -NeRF[4] est actuellement la seule méthode d'anti-aliasing pour les grilles de hachage iNGP, qui combine deux techniques de modélisation du tronc : le multi-échantillonnage et la réduction de poids. En échantillonnage multiple, les incorporations de positions à plusieurs positions du tronc de tronc sont moyennées, capturant les étendues longitudinales et radiales. Pour la sous-pondération, chaque échantillon est modélisé comme une gaussienne isotrope, avec des caractéristiques de grille pondérées proportionnellement au rapport entre la taille des cellules et la variance gaussienne, supprimant ainsi les résolutions plus fines. Si la combinaison de techniques améliore considérablement les performances, le multi-échantillonnage augmente également considérablement la durée d'exécution. L’objectif de cet article est donc d’incorporer des informations d’échelle avec un impact opérationnel minimal. Inspirés par Zip-NeRF, les auteurs proposent un schéma intuitif de réduction de poids qui réduit le poids des fonctionnalités de grille de hachage par rapport à leur taille par rapport au tronc de fruit.
Échantillonnage efficace
Une autre difficulté dans le rendu de scènes à grande échelle est la nécessité de stratégies d'échantillonnage efficaces. Dans une image, vous souhaiterez peut-être restituer un texte détaillé sur un panneau de signalisation à proximité tout en capturant l'effet de parallaxe entre des gratte-ciel à plusieurs kilomètres. Pour atteindre ces deux objectifs, un échantillonnage uniforme des rayons nécessiterait des milliers d’échantillons par rayon, ce qui est irréalisable sur le plan informatique. Les travaux antérieurs reposaient fortement sur les données lidar pour élaguer les échantillons [47], ce qui rendait difficile le rendu en dehors du travail lidar.
Au lieu de cela, cet article restitue les échantillons le long du rayon selon une fonction puissance [4], de telle sorte que l'espace entre les échantillons augmente avec la distance par rapport à l'origine du rayon. Malgré cela, il est impossible de satisfaire toutes les conditions pertinentes avec une augmentation drastique de la taille de l’échantillon. Par conséquent, deux séries d'échantillonnage de proposition [25] sont également utilisées, où une version allégée du champ de caractéristiques neuronales (NFF) est interrogée pour générer une distribution de poids le long du rayon. Ensuite, un nouvel ensemble d’échantillons est rendu en fonction de ces poids. Après deux tours de ce processus, un ensemble affiné d'échantillons est obtenu, concentré aux positions pertinentes sur le rayon et peut être utilisé pour interroger le NFF à grande échelle. Pour superviser le réseau proposé, une méthode de distillation en ligne anti-aliasing [4] est adoptée et est ensuite supervisée à l'aide du lidar.
Modélisation de volet roulant
Dans la formulation standard basée sur NeRF, il est supposé que chaque image est capturée à partir d'une origine o. Cependant, de nombreux capteurs de caméra sont dotés d'un obturateur roulant, où des rangées de pixels sont capturées séquentiellement. Par conséquent, le capteur de la caméra peut se déplacer entre la capture de la première ligne et la capture de la dernière ligne, rompant ainsi l’hypothèse d’une origine unique. Bien que ce ne soit pas un problème avec les données synthétiques [24] ou les données prises avec des caméras portatives lentes, l'obturateur roulant devient perceptible dans les photos de véhicules se déplaçant rapidement, en particulier les caméras latérales. Le même effet est présent dans le lidar, où chaque scan est généralement collecté en 0,1 seconde, ce qui équivaut à plusieurs mètres de mouvement lors de déplacements à vitesse d'autoroute. Même pour les nuages de points à compensation de mouvement automatique, ces différences peuvent conduire à des erreurs de ligne de visée nuisibles, où les points 3D sont transformés en rayons traversant une autre géométrie. Pour atténuer ces effets, un volet roulant est modélisé en attribuant à chaque rayon une heure distincte et en ajustant son origine en fonction du mouvement estimé. Étant donné que l’obturateur roulant affecte tous les éléments dynamiques de la scène, une interpolation linéaire est effectuée pour chaque temps d’éclairage et pose d’acteur.
Différents paramètres de caméra
Un autre problème lors de la simulation de séquences de conduite autonome est que les images proviennent de différentes caméras, avec des paramètres de capture potentiellement différents tels que l'exposition. Ici, l'inspiration est tirée de la recherche sur les « NeRF dans la nature » [22], où les intégrations d'apparence sont apprises pour chaque image et transmises au deuxième MLP avec ses caractéristiques. Cependant, lorsqu'on sait quelle image provient de quel capteur, une seule intégration est apprise pour chaque capteur, minimisant ainsi la possibilité de surajustement et permettant d'utiliser ces intégrations de capteurs lors de la génération de nouvelles vues. Ces intégrations sont appliquées après le rendu du volume, ce qui réduit considérablement la charge de calcul lors du rendu des caractéristiques au lieu des couleurs.
Noisy Actor Pose
Le modèle repose sur l'estimation des poses dynamiques des acteurs, que ce soit sous forme d'annotations ou de sortie de suivi. Pour remédier aux lacunes, les poses des acteurs sont incorporées dans le modèle en tant que paramètres apprenables et optimisées conjointement. L'attitude est paramétrée en translation t et en rotation R, en utilisant la représentation 6D [50].
NeuRAD est implémenté dans le projet open source Nerfstudio[33]. La formation est effectuée sur 20 000 itérations à l'aide de l'optimiseur Adam[17]. Sur un NVIDIA A100, la formation prend environ 1 heure
Reproduire UniSim : UniSim [47] est un simulateur de capteur neuronal en boucle fermée. Il présente des rendus photoréalistes et fait peu d'hypothèses sur la supervision disponible, c'est-à-dire qu'il ne nécessite que des images de caméra, des nuages de points lidar, des poses de capteurs et des cadres de délimitation 3D avec des trajectoires d'acteurs dynamiques. Ces propriétés font d'UniSim une référence appropriée car elle est facilement applicable aux nouveaux ensembles de données de conduite autonome. Cependant, le code est fermé et il n’y a pas d’implémentation non officielle. Par conséquent, cet article choisit de réimplémenter UniSim comme son propre modèle et de l'implémenter dans Nerfstudio [33]. Étant donné que l'article principal d'UniSim ne détaille pas de nombreux détails du modèle, il faut s'appuyer sur le matériel supplémentaire fourni par IEEE Xplore. Néanmoins, certains détails restent inconnus et les auteurs ont ajusté ces hyperparamètres pour qu'ils correspondent aux performances rapportées sur 10 séquences PandaSet sélectionnées [45].
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quoi étudier dans le domaine du big data
- Comment comparer et filtrer les mêmes données de deux tables ?
- Huawei Cloud et un certain nombre d'entreprises ont lancé une initiative d'action : construire conjointement un écosystème industriel ouvert pour la conduite autonome
- Une brève analyse de la voie technologique de perception visuelle pour la conduite autonome
- Une analyse approfondie des solutions technologiques de conduite autonome de Tesla