
Maison >Périphériques technologiques >IA >Une analyse approfondie des solutions technologiques de conduite autonome de Tesla
Une analyse approfondie des solutions technologiques de conduite autonome de Tesla

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-17 08:55:052210parcourir
01 Perception : Construire une scène de conduite autonome 4D en temps réel
1. Disposition de la caméra Tesla
# 🎜🎜#
Le champ de vision de la caméra de Tesla peut couvrir 360° autour de la carrosserie de la voiture et dispose d'un fisheye et d'un téléobjectif de 120° dans le sens avant pour améliorer l'observation et disposition Comme indiqué ci-dessus.
2. Prétraitement des données d'image Tesla

1) Le FAI effectue la mise au point automatique (AF) et l'exposition automatique sur le signal d'origine en fonction de l'algorithme à base de règles. (AE), balance des blancs automatique (AWB), correction des pixels morts (DNS), imagerie à plage dynamique élevée (HDR), correction des couleurs (CCM), etc., ceux-ci répondent aux besoins de visualisation de l'œil humain, mais ne sont pas nécessairement les besoins de la conduite autonome. Comparé au FAI basé sur des règles, le réseau neuronal possède des capacités de traitement plus puissantes et peut mieux utiliser les informations originales des images tout en évitant la perte de données causée par le FAI.
2) L'existence du FAI n'est pas propice à la transmission de données à haut débit et affecte la fréquence d'images des images. Il est beaucoup plus rapide de traiter le signal d'origine dans les opérations réseau.
Cette méthode transcende l'expertise traditionnelle de type FAI et pilote directement le réseau de la demande back-end pour apprendre des capacités plus fortes des FAI, ce qui peut renforcer le système dans des conditions de faible luminosité, Au-delà de la perception de l'œil humain dans des conditions de faible visibilité. Sur la base de ce principe, il devrait s’agir d’une meilleure façon d’utiliser les données brutes Lidar et radar pour l’ajustement du réseau.
3.backbone network : Conception d'espaces de conception de réseau
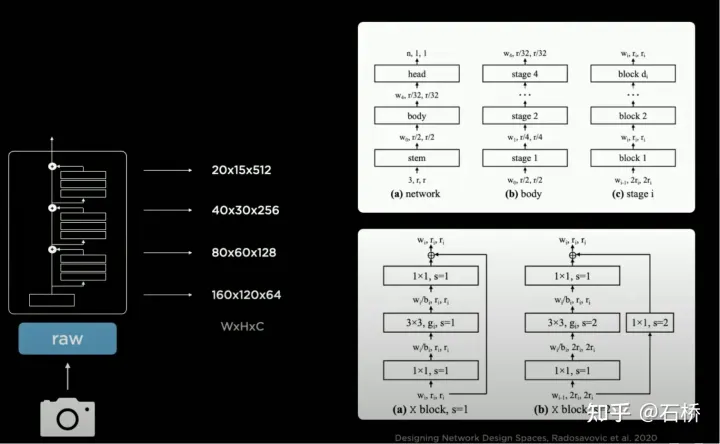 # 🎜🎜#
# 🎜🎜#
Tesla utilise RegNet, qui a un niveau d'abstraction plus élevé que ResNet pour résoudre Il surmonte les inconvénients du NAS fixe espace de conception de recherche (convolution, mise en commun et autres modules : combinaison de connexions/évaluation de la formation/sélection du meilleur) et incapacité à créer de nouveaux modules. Il peut créer de nouveaux paradigmes d'espace de conception et explorer davantage d'adaptations de scène. Le nouveau "ResNet" évite ce besoin. pour rechercher et concevoir spécifiquement des architectures de réseaux neuronaux. Si un meilleur BackBone sort, cette pièce peut être remplacée.
4. neckwork : EfficientDet : Détection d'objets évolutive et efficace
#🎜🎜 #
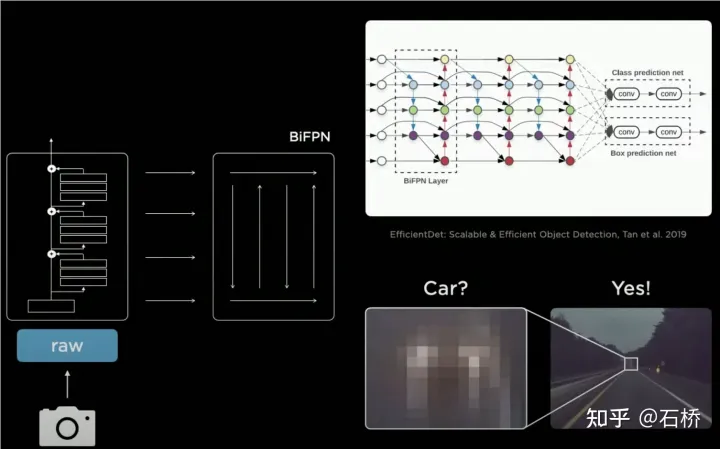 BiFPN
BiFPN
PANet est plus précis que FPN car : en FPN top-down single Sur le sur la base du flux de chemin, un flux de chemin ascendant supplémentaire est ajouté, qui apporte des paramètres et des calculs plus élevés
- BiFPN supprime un seul nœud d'entrée (la couche supérieure et le couche la plus inférieure), car le but du réseau est de fusionner des fonctionnalités, de sorte que les nœuds sans capacités de fusion peuvent être connectés directement.
- BiFPN connecte directement l'entrée au nœud de sortie, intégrant plus de fonctionnalités sans augmenter les calculs.
- BiFPN empile la structure de base en plusieurs couches et peut intégrer des fonctionnalités de dimension supérieure.
 FPN->BiFPN
FPN->BiFPN
#🎜 🎜#5.BEV Fusion : Capacité de compréhension spatiale de la perception FSD 🎜🎜#Perception 2D
Avant l'émergence du BEV, les solutions traditionnelles pour la perception de la conduite autonome étaient toutes basées sur l'espace d'image 2D de la caméra, mais les applications en aval de la perception - prise de décision et planification de trajet sont toutes réalisées dans l'espace BEV 2D où le véhicule est situé, entre perception et contrôle. Des barrières entravent le développement du FSD. Afin d'éliminer cette barrière, il est nécessaire de réorganiser la perception de l'espace d'image 2D vers l'espace du système de référence 2D du véhicule autonome, c'est-à-dire l'espace BEV.
Basé sur la technologie traditionnelle :
utilisera l'IPM (Inverse Perspective Mapping) en supposant que le sol est un plan et utilisera les paramètres externes de la caméra-auto-véhicule pour convertir l'espace d'image 2D en un auto-2D -l'espace véhicule, c'est-à-dire l'espace de vue à vol d'oiseau du BEV. Il y a ici un défaut évident : l’hypothèse de l’avion n’est plus vraie face aux hauts et aux bas de la route.
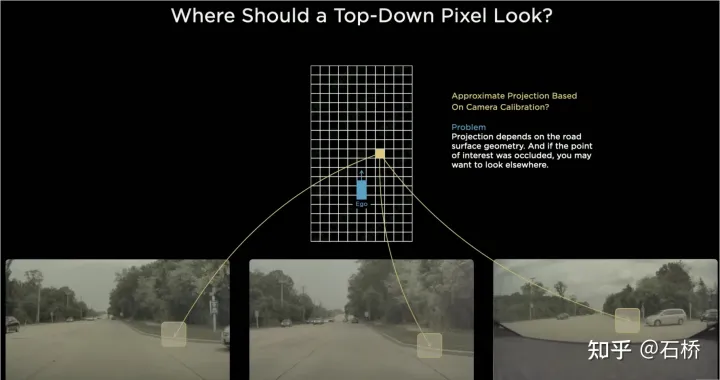
Problème d'assemblage des bords multi-caméras
Étant donné que le champ de vision de chaque caméra est limité, même si vous utilisez IPM pour convertir l'espace d'image 2D en espace BEV 2D, vous devez toujours résoudre le BEV espace de plusieurs images de caméra Épissage. Cela nécessite en fait un algorithme d'étalonnage multi-caméras de haute précision et un algorithme de correction en temps réel en ligne. En résumé, ce qu'il faut réaliser est de mapper les caractéristiques de l'espace d'image 2D multi-caméras sur l'espace BEV tout en résolvant le problème de chevauchement de transformation causé par l'étalonnage et les hypothèses non planaires.于La solution d'implémentation de Bev Layer de Tesla basée sur Transformer :
Bev_fusion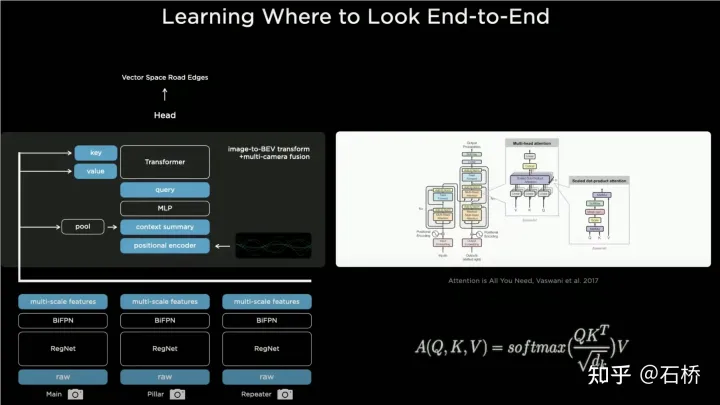
extrait d'abord les couches de fonctionnalités multi-échelles via le réseau principal CNN et BIFPN, et multi-échelle, multi-échelle, multi -scale, multi -scale D'une part, la couche de fonctionnalités génère la clé et la valeur requises dans la méthode Transformer via la couche MLP. D'autre part, elle effectue l'opération de pooling global sur la carte de fonctionnalités multi-échelle pour obtenir. un vecteur de description global (c'est-à-dire le résumé du contexte dans la figure). En même temps, l'espace BEV de sortie est rastérisé et chaque raster BEV est codé en position. Ces codes de position sont concaténés (concaténés) avec le vecteur de description global. , puis la requête requise par le transformateur est obtenue via une couche MLP.
Dans l'opération Cross Attention, l'échelle de la requête détermine l'échelle de sortie après la couche BEV finale (c'est-à-dire l'échelle de la grille BEV), et la clé et la valeur sont respectivement dans l'espace de coordonnées de l'image 2D. le principe de Transformer, via Query et Key, établit le poids d'influence de chaque raster BEV reçu par les pixels du plan image 2D, établissant ainsi l'association du BEV à l'image d'entrée, puis utilise ces poids pour pondérer la valeur obtenue par les caractéristiques sous le plan image, et obtient finalement le système de coordonnées BEV. La Feature Map complète la mission de la couche de conversion de coordonnées BEV. Plus tard, sur la base de la Feature Map sous BEV, les têtes de fonction de détection matures peuvent être utilisées pour détecter directement dans l'espace BEV. . Les résultats de la perception dans l'espace BEV sont unifiés avec le système de coordonnées de la planification décisionnelle, de sorte que la perception et les modules ultérieurs sont étroitement liés via la transformation BEV.
Calibration
Grâce à cette méthode, en fait, les changements dans les paramètres externes de la caméra et la géométrie du sol sont internalisés dans les paramètres par le modèle de réseau neuronal pendant le processus de formation. Un problème ici est qu'il existe de légères différences dans les paramètres extrinsèques des caméras de différentes voitures utilisant le même ensemble de paramètres de modèle. Karparthy a ajouté une méthode permettant à Tesla de gérer les différences de paramètres extrinsèques lors de l'AI Day : ils utilisent les paramètres extrinsèques calibrés pour comparer. chaque véhicule. Les images collectées sont uniformément converties dans le même ensemble de positions de disposition de caméra standard virtuelle grâce à la dé-distorsion, à la rotation et à la restauration de la distorsion, éliminant ainsi les légères différences dans les paramètres externes des différentes caméras du véhicule.
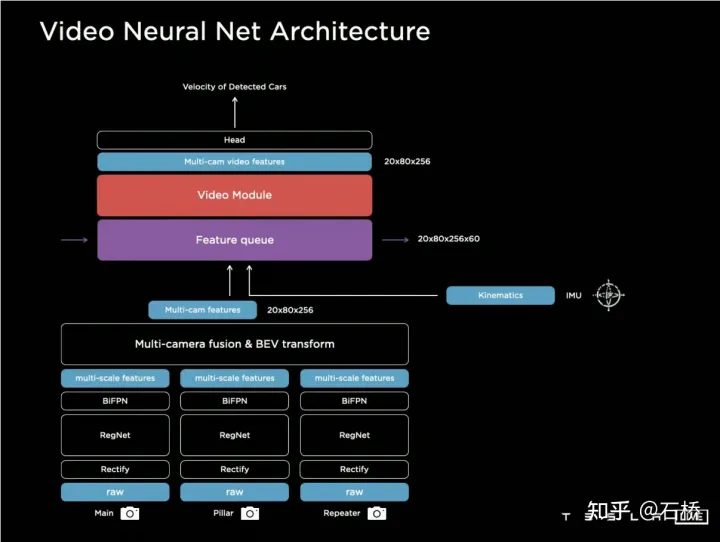
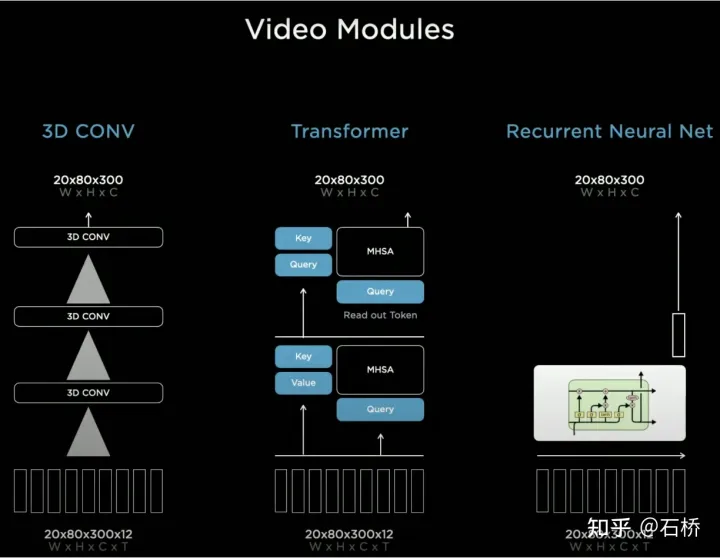
BEV est un cadre de fusion multi-caméras très efficace. Grâce à la solution de BEV, l'estimation de la taille et le suivi de grandes cibles à proximité sur plusieurs caméras qui étaient à l'origine difficiles à corréler correctement se sont améliorés. est plus précis et plus stable. Dans le même temps, cette solution rend également l'algorithme plus robuste à l'occlusion et à la perte à court terme d'une ou plusieurs caméras. En bref, BEV résout le problème de la fusion d’images et de l’épissage de plusieurs caméras et augmente la robustesse. résout la ligne de voie multi-caméras et la fusion des limites Les obstacles deviennent plus stables # 🎜🎜#(À en juger par le PPT, la solution initiale de Tesla devrait principalement utiliser des caméras orientées vers l'avant pour la perception et la prédiction de voie.) Concernant la manière de fusionner les informations de synchronisation, Tesla a essayé trois solutions traditionnelles : la convolution 3D, Transformer et RNN. Ces trois méthodes doivent toutes combiner les informations de mouvement du véhicule avec la perception d'une seule image. Karparthy a déclaré que les informations de mouvement du véhicule utilisent uniquement des informations quadridimensionnelles, notamment la vitesse et l'accélération. Ces informations de mouvement peuvent être obtenues à partir de l'IMU, puis. combinés avec l'espace BEV (20x80x256) et le codage positionnel sont combinés (concaténer) pour former une file d'attente de vecteurs de fonctionnalités de 20x80x300x12 dimensions. La troisième dimension se compose ici de caractéristiques visuelles en 256 dimensions + de caractéristiques cinématiques en 4 dimensions (vx, vy). , ax, ay) et une position à 40 dimensions. Il est composé d'un codage positionnel, donc 300 = 256 + 4 + 40, et la dernière dimension est la dimension temps/espace à 12 images après sous-échantillonnage.
3D Conv, Transformer et RNN peuvent tous traiter les informations de séquence. Chacun des trois a ses propres atouts et. faiblesses dans différentes tâches. Mais la plupart du temps, il n'y a pas beaucoup de différence dans la solution utilisée. Cependant, lors de l'AI Day, Karparthy a également partagé une solution simple, efficace, très intéressante et explicable appelée Spatial RNN. Différent des trois méthodes ci-dessus, Spatial RNN est dû au fait que RNN traite à l'origine les informations de séquence en série et que l'ordre entre les images est préservé. Par conséquent, les caractéristiques visuelles BEV peuvent être directement introduites dans le réseau RNN sans codage de position, vous pouvez donc voir ici l'entrée. les informations incluent uniquement la carte visuelle des caractéristiques BEV 20x80x256 et les informations sur le mouvement du véhicule autonome 1x1x4.
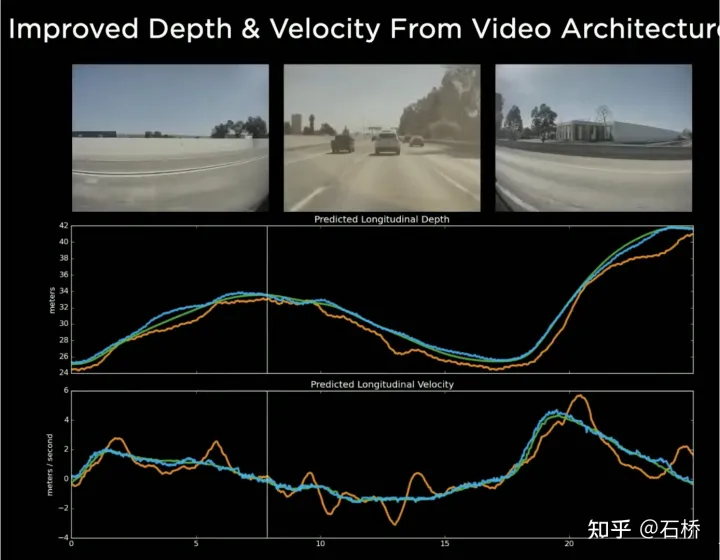
Les fonctionnalités spatiales dans CNN font souvent référence à des fonctionnalités dans les dimensions de largeur et de hauteur sur le plan de l'image, ici dans Spatial RNN Spatial fait référence à deux dimensions dans un système de coordonnées local basé sur les coordonnées BEV à un moment donné. La couche RNN de LSTM est utilisée ici à titre d'illustration. L'avantage de LSTM est sa forte interprétabilité. Il est plus approprié de la comprendre à titre d'exemple. La caractéristique du LSTM est que l'état caché peut conserver l'encodage de l'état des N moments précédents avec une longueur variable (c'est-à-dire une mémoire à court terme), puis le moment actuel peut déterminer lequel une partie de la mémoire est stockée via l'entrée et l'état caché. L'état doit être utilisé, quelles parties doivent être oubliées, etc. Dans Spatial RNN, l'état caché est une zone de grille rectangulaire plus grande que l'espace de grille BEV, avec une taille de (LxHxC) (voir la figure ci-dessus, LxH est supérieure à la taille BEV de 20x80, déterminée par les informations cinématiques du véhicule autonome). les caractéristiques BEV avant et arrière respectivement. Quelle partie de la grille de l'état caché est affectée, de sorte que les données BEV continues mettent continuellement à jour la grande zone rectangulaire de l'état caché et que la position de chaque mise à jour soit cohérente avec le mouvement de le véhicule autonome. Après des mises à jour continues, une carte de fonctionnalités d'état caché similaire à une carte locale est formée, comme le montre la figure ci-dessous. L'utilisation de files d'attente de synchronisation donne au réseau neuronal le capacité à obtenir des images La capacité de détecter les résultats en continu dans le temps, combinée au BEV, permet à FSD d'acquérir la capacité de gérer les angles morts et les occlusions dans le champ de vision, et de lire et d'écrire de manière sélective des cartes locales grâce à cette capacité à construire. cartes locales en temps réel, FSD Ce n'est qu'alors que la conduite autonome en ville peut être réalisée sans recourir à des cartes de haute précision. Il possède non seulement des capacités de carte 3D, mais également des capacités de construction de scènes 4D locales, qui peuvent être utilisées pour la prédiction, etc. Après la sortie d'Occupancy, il était généralement admis que la solution basée sur Spatial RNN avait été remplacée par la solution de transformateur mentionnée ci-dessus. #🎜🎜 # La vue à vol d'oiseau 2D du BEV est évidemment encore loin de la scène 3D à laquelle est confrontée la conduite autonome réelle, il doit donc y avoir des situations où la perception BEV2D échoue dans certains scénarios. En 2021, Tesla aura la capacité de construire en profondeur, ce n'est donc qu'une question de temps de passer de la 2D à la 3D. En 2022, elle amènera le réseau d'occupation, qui est une nouvelle expansion du réseau BEV dans le sens de la hauteur. suppression du système de coordonnées BEV. La requête générée par l'encodage de position raster 2D est mise à niveau vers la requête générée par l'encodage de position raster 3D et la fonctionnalité BEV est remplacée par la fonctionnalité d'occupation. 1) L'estimation de la profondeur est correcte à proximité, mais la profondeur à distance est incohérente. Plus on est proche du sol, moins il y a de points de valeur de profondeur (cela est limité par Due à). le principe d'imagerie de l'image, la distance verticale représentée par un pixel à une distance de 20 m peut dépasser 30 cm), et les données sont difficiles à utiliser dans les processus de planification ultérieurs. 2) Le réseau profond est construit sur la base de la régression, qui est difficile à prédire par occlusion, il est donc difficile de prédire à la frontière, et il peut passer en douceur du véhicule à l'arrière-plan. Les avantages de l'utilisation de l'occupation sont les suivants : Occupancy Advantages 2) Les flux vidéo de toutes les caméras sont obtenus, et ils sont unifiés (il n'y a pas de problème de fusion lidar-caméra, et la dimension l'information est supérieure à celle du lidar) 3) Possibilité de prédire l'état des objets occultés en temps réel (la capacité de description dynamique d'Occupancy est la transition de la 3D à la 4D ) 4) Des catégories sémantiques correspondantes peuvent être générées pour chaque voxel (la capacité de reconnaissance des images est bien plus forte que celle du lidar) #Peut même gérer des objets en mouvement si la catégorie n'est pas reconnue 5) L'état de mouvement peut être prédit pour chaque voxel et un mouvement aléatoire peut être modélisé 6) La résolution de chaque position peut être ajustée (c'est-à-dire qu'elle a une capacité de zoom spatial BEV) 7) Grâce au matériel de Tesla, Occupancy présente des avantages de stockage et de calcul efficaces 8) Le calcul peut être effectué en 10 ms et la fréquence de traitement peut être très élevée (la capacité de sortie d'image de 36 Hz est déjà plus forte que la fréquence lidar de 10 Hz ) L'avantage de la solution d'occupation par rapport à la solution de perception de la boîte englobante est que : peut décrire des objets inconnus qui n'ont pas de boîte englobante fixe, peut changer de forme à volonté et se déplacer à volonté, améliorant ainsi la la description de la granularité des obstacles, de la boîte à la granularité du Voxel, peut résoudre de nombreux problèmes de perception à longue traîne. Jetons un coup d'œil à la solution globale d'occupation : 

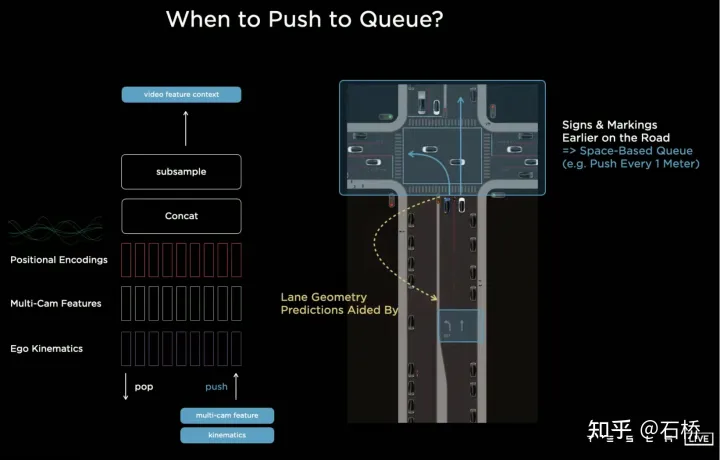
6.Architecture de réseau neuronal vidéo : séquence spatio-temporelle Construction de fonctionnalités 🎜🎜#L'utilisation du BEV améliore la perception de l'espace d'image 2D dispersé de plusieurs caméras à l'espace BEV 2D. Cependant, l'environnement réel de la conduite autonome est un problème d'espace 4D. Même si l'élévation n'est pas prise en compte, le problème reste le même. une dimension manquante est le temps. Tesla entraîne le réseau neuronal en utilisant des clips vidéo contenant des informations temporelles au lieu d'images, de sorte que le modèle de perception ait des capacités de mémoire à court terme. La méthode pour réaliser cette fonction consiste à introduire des files d'attente de fonctionnalités dans la dimension temporelle et la dimension spatiale dans le réseau neuronal. modèle. . Règle : toutes les 27 millisecondes de file d'attente ou chaque mètre parcouru seront mis en cache dans la séquence vidéo avec les informations de mouvement.


 7.Réseau d'occupation : BEV passe de la 2D à la 3D
7.Réseau d'occupation : BEV passe de la 2D à la 3D Lors du CVPR2022, Ashork a donné la raison pour laquelle il a utilisé la fonction d'occupation au lieu d'utiliser l'estimation de la profondeur basée sur l'image :
Lors du CVPR2022, Ashork a donné la raison pour laquelle il a utilisé la fonction d'occupation au lieu d'utiliser l'estimation de la profondeur basée sur l'image : # 🎜 🎜#

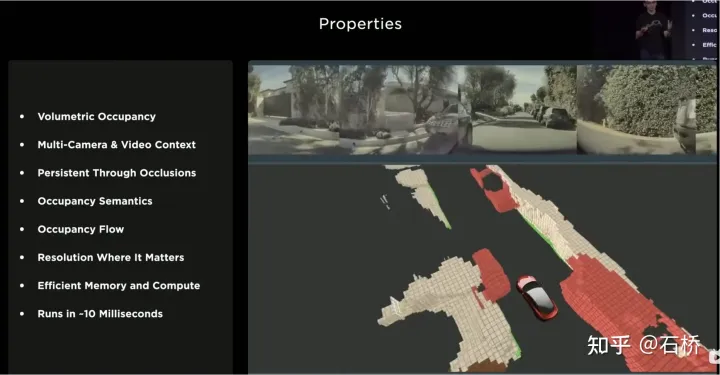

Occupancy Network
1) Entrée d'image : saisissez les informations d'image originales, en élargissant la dimension des données et la plage dynamique
2) Caractéristiques de l'image : RegNet+BiFPN extrait les caractéristiques de l'image à plusieurs échelles
3) Attention spatiale : fusion multi-caméras basée sur l'attention des caractéristiques de l'image 2D via une requête spatiale avec une position spatiale 3D
Plan de mise en œuvre 1 : Selon les paramètres internes et externes de chaque caméra, projetez la requête spatiale 3D sur la carte de caractéristiques 2D pour extraire les caractéristiques de la position correspondante.
Plan de mise en œuvre 2 : utilisez l'intégration positionnelle pour effectuer une cartographie implicite, c'est-à-dire, ajoutez une intégration positionnelle raisonnable à chaque position de la carte de caractéristiques 2D, telle que les paramètres internes et externes de la caméra, les coordonnées de pixels, etc., puis laissez le le modèle apprend la 2D à la 3D par lui-même. Correspondance des caractéristiques
4) Alignement temporel : utilisez les informations de trajectoire pour fusionner les caractéristiques d'occupation 3D de chaque image dans la dimension du canal spatial dans une séquence temporelle. Il y aura une atténuation de poids au fil du temps, et les fonctionnalités combinées entreront dans le module de déconvolution pour améliorer la résolution
5) Sorties de volume : sortie de l'occupation et du flux d'occupation de rasters de taille fixe
6) Sorties interrogeables : un décodeur MLP interrogeable implicite est conçu pour saisir n'importe quelle coordonnée valeur (x, y, z), utilisée pour obtenir une sémantique de voxel continue de plus haute résolution, des informations sur le taux d'occupation et le flux d'occupation, brisant ainsi la limitation de la résolution du modèle
7) Générer une chaussée de zone carrossable avec une géométrie et une sémantique tridimensionnelles, Propice au contrôle sur les pentes et les routes courbes.

Le sol est conforme à l'occupation
8) État NeRF : nerf construit la structure géométrique de la scène, peut générer des images sous n'importe quelle perspective et peut restaurer des scènes réelles en haute résolution.
S'il peut être mis à niveau ou remplacé par Nerf, il aura la capacité de restaurer des scènes réelles, et cette capacité de restauration de scène sera passée-présent-futur. Cela devrait constituer un excellent complément et une amélioration à la conduite autonome sur la scène 4D poursuivie par les solutions techniques de Tesla.
8.Réseau neuronal des voies FSD : prédire la relation de connexion topologique des voies
Il ne suffit pas de segmenter et d'identifier les lignes de voies, il est également nécessaire de déduire la relation de connexion topologique entre les voies, pour qu'elle puisse. être utilisé pour la planification de trajectoire.
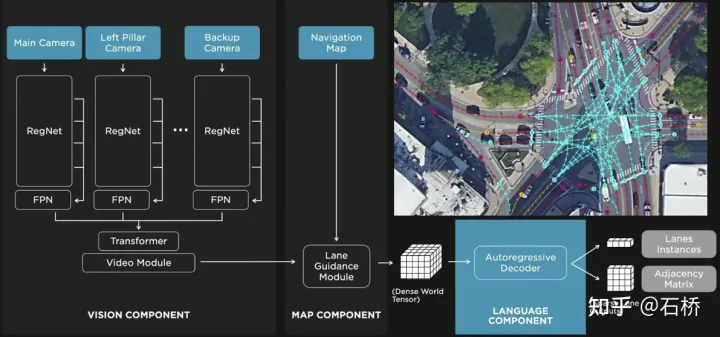
Conscience des relations topologiques de la ligne de voie FSD
1) Module de guidage sur voie : utilise la relation géométrique et topologique de la route dans la carte de navigation, le niveau de la voie, la quantité, la largeur, les informations d'attribut, intègre ces informations avec la fonction d'occupation pour encoder et générer du dense World Tensor fournit un module permettant d'établir des relations topologiques et analyse les caractéristiques denses du flux vidéo via le paradigme de génération de séquences pour obtenir des informations clairsemées sur la topologie routière (segment de voie de nœud de voie et relation de connexion adjacente).
2) Composant linguistique : les informations relatives aux voies comprennent les emplacements des nœuds de voies, les attributs (point de départ, point intermédiaire, point d'arrivée, etc.), les points de bifurcation, les points de fusion , et voies Les paramètres géométriques de la courbe spline sont codés dans un code similaire au jeton de mot dans le modèle de langage, puis traités à l'aide de méthodes de traitement de synchronisation. Le processus spécifique est le suivant :

processus de langue des voies#🎜🎜 ##🎜 🎜#

langue des voies#🎜 🎜#Enfin Le langage des voies représente la relation de connexion topologique dans le graphique.
9. Perception d'objets : Perception et prédiction des autres participants à la circulation #
Perception et prédiction d'obstacles# 🎜🎜#
La perception des objets de FSD est une méthode en 2 étapes. La première étape commence par La position de l'obstacle dans l'espace 3D est identifiée à partir de l'occupation. Dans la deuxième étape, le tenseur de ces 3D. les objets concatènent certains codages d'informations cinématiques (telles que le mouvement du véhicule autonome, les lignes de voie de circulation cibles, les feux de circulation, les feux de circulation, etc.), puis dans l'accès à la prédiction de trajectoire, à la modélisation d'objets, à la prédiction de pose de piéton et à d'autres têtes. La concentration des têtes de détection complexes sur une zone de retour sur investissement limitée réduit les retards de traitement. Comme vous pouvez le voir sur la figure ci-dessus, le module vidéo comporte deux étapes qui servent respectivement à la prédiction de votre propre véhicule et des autres véhicules. 
Laissez une question ici : Quelle est la différence entre les deux modules vidéo dans l'image ci-dessus ? Y aura-t-il des problèmes d’efficacité ?
02 Planification des décisions
1. Planification interactive des participants
La difficulté de prise de décision et de planification dans le scénario ci-dessus est la suivante : 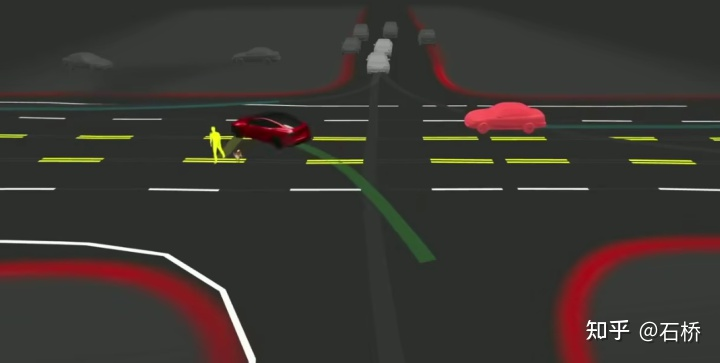
Le véhicule exécute un virage à gauche non protégé à travers l'intersection Au cours de la scène, vous devez interagir avec les piétons et les véhicules normaux se déplaçant en ligne droite pour comprendre les relations entre les différentes parties.
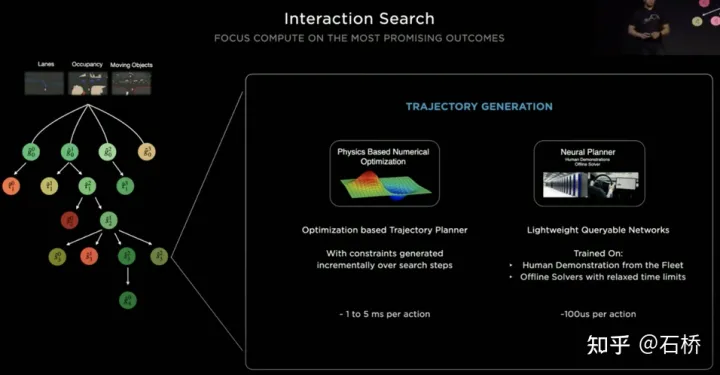
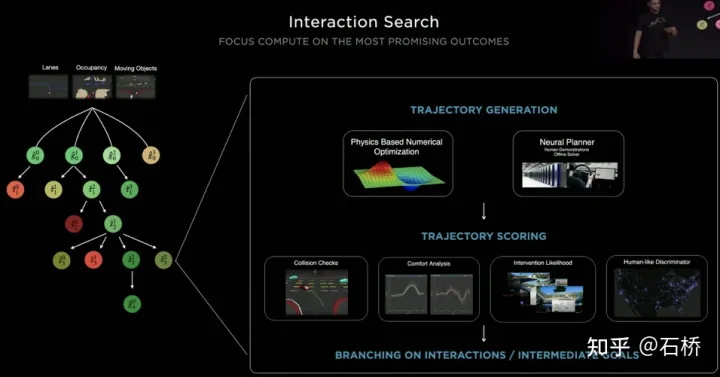
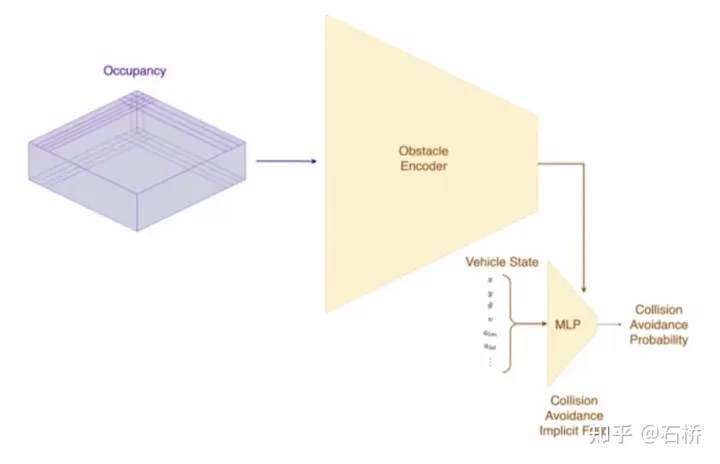
La décision d'interaction avec le premier affecte directement la stratégie d'interaction avec le second. La solution finale choisie ici est la suivante : essayez de ne pas gêner le mouvement des autres usagers de la route.Processus de planification décisionnelle Tesla utilise « interaction » Recherche », une série de possibilités les trajectoires de mouvement sont recherché en parallèle, et l'espace d'état correspondant comprend le véhicule autonome, les obstacles, les zones carrossables, les voies, les feux de circulation, etc. L'espace de solutions utilise un ensemble de trajectoires candidates au mouvement cible, qui se divisent après avoir participé à une prise de décision interactive avec un autre trafic, puis procèdent à une prise de décision et à une planification progressives, et sélectionnent enfin la trajectoire optimale. Le processus est tel qu'illustré dans l'illustration. figure ci-dessus : 1) Obtenir le point objectif ou sa distribution de probabilité (trajectoire big data) a priori en fonction de la topologie de la route ou des données de conduite humaine 2) Générer des trajectoires candidates basées sur le point objectif (algorithme d'optimisation + réseau de neurones) 3) Suivez la trajectoire du candidat Déploiement et prise de décision interactive, re-planifier le parcours, évaluer le risque et le score de chaque parcours, prioriser la recherche du meilleur parcours pour connaître le point objectif L'expression d'optimisation de l'ensemble de la planification décisionnelle : L'expression d'optimisation de la planification décisionnelle Réseau de requête de trajectoire de planification légère T esla utilise une approche incrémentale pour ajouter continuellement de nouvelles contraintes de prise de décision et utiliser la solution optimale sous moins de contraintes comme valeur initiale pour continuer à résoudre plus de problèmes. Les problèmes d'optimisation complexes donnent finalement des solutions optimales. Cependant, en raison de l'existence de nombreuses branches possibles, l'ensemble du processus de prise de décision et de planification doit être très efficace. Chaque planification de prise de décision utilisant un planificateur basé sur des algorithmes d'optimisation traditionnels prend 1 à 5 ms, ce qui n'est évidemment pas assez sûr lorsqu'il y en a. sont des acteurs du trafic à haute densité. Le Neural Planner utilisé par Tesla est un réseau léger. La trajectoire de planification des requêtes est formée à l'aide des données de conduite des conducteurs humains de la flotte Tesla et de la véritable valeur du chemin optimal global planifié dans des conditions hors ligne, sans contraintes de temps, pour chaque prise de décision. la planification ne prend que 100us. Évaluation des décisions de planification Les multiples trajectoires candidates interrogées après chaque décision doivent être évaluées sur la base de spécifications telles que l'inspection des collisions, l'analyse du confort, la possibilité de prise de contrôle et l'interaction humaine. Le degré de similarité, etc., permet d'élaguer la branche de recherche pour éviter que l'ensemble de l'arbre de décision ne soit trop volumineux, et en même temps, il peut également concentrer la puissance de calcul sur la branche la plus probable. Tesla a souligné que cette solution s'applique également aux scènes d'occlusion. Au cours du processus de planification, l'état de mouvement de l'objet occulté sera pris en compte et la planification sera effectuée en ajoutant des « fantômes ». scène d'occlusion fantôme CVPR a également partagé le processus réseau d'évitement des collisions et le processus de planification correspondant, qui ne sera pas détaillé. Réseau d'évitement de collision
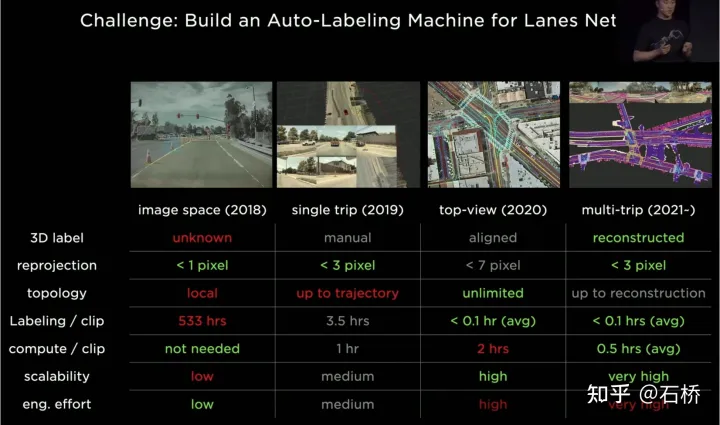
tesla étiquetage de l'itération phase 2 (2019) : les étiquettes 3D sont démarrées, mais il s'agit d'un seul processus manuel Phase 3 (2020) : l'espace BEV est utilisé pour l'étiquetage et la reprojection La précision est considérablement réduite Phase 4 (2021) : Plusieurs reconstructions sont utilisées pour l'annotation, et la précision, l'efficacité et les relations topologiques ont atteint un niveau extrêmement élevé. Le système d'annotation automatique de Tesla peut remplacer 5 millions d'heures de travail manuel, soit seulement une très petite partie de l'inspection manuelle et de la correction des fuites. (2. Méthode d'optimisation traditionnelle : [Planification conjointe de trajectoire multi-objets] : MPC multi-objets

3. Planification des chemins parallèles et élagage d'évaluation






Système d'étiquetage automatique
Étape 1 : VIO génère des trajectoires de haute précision. Alimentez le flux vidéo, l'IMU et l'odométrie au réseau neuronal, déduisez et extrayez des points, des lignes, du sol et des caractéristiques de segmentation, puis utilisez le VIO multi-caméras pour le suivi et l'optimisation dans l'espace BEV afin de produire des trajectoires 100 Hz 6dof et des structures 3dof. Et les routes, et peut également sortir la valeur d'étalonnage de la caméra. La précision de la trajectoire reconstruite est de 1,3 cm/m, 0,45 rad/m, ce qui n'est pas très élevé. Tous les FSD peuvent exécuter ce processus pour obtenir les informations prétraitées sur la trajectoire et la structure d'un certain voyage. (En regardant la vidéo, j'ai l'impression que vio n'utilise explicitement que les caractéristiques ponctuelles et peut utiliser implicitement les caractéristiques de ligne et de surface.) reconstruction. Plusieurs données reconstruites provenant de différents véhicules sont regroupées pour un alignement approximatif -> une correspondance de caractéristiques -> une optimisation des joints -> un raffinement de la surface de la route, puis une intervention manuelle est effectuée pour enfin vérifier et confirmer les résultats de l'étiquetage. Ici, une optimisation de la surface de la route a également été réalisée après une optimisation conjointe. On suppose que l'erreur de reconstruction visuelle est relativement importante après une optimisation globale, il existe un problème de chevauchement en couches sur les routes locales afin d'éliminer l'erreur de cette partie de la route. mauvaise allocation de l'optimisation globale, l'optimisation de la surface de la route a été ajoutée. D’un point de vue logique algorithmique, une optimisation globale suivie d’une optimisation locale est indispensable, car l’exigence de la conduite autonome est de pouvoir rouler partout. L'ensemble du processus est parallélisé sur le cluster.

Alignement grossier Étape 3 : Étiquetez automatiquement les nouvelles données de trajectoire. Sur la carte prédéfinie, le même processus de reconstruction que les reconstructions de trajectoires multiples est effectué sur les nouvelles données de trajectoire de conduite, de sorte que les nouvelles données de trajectoire alignées puissent obtenir automatiquement des annotations sémantiques à partir de la carte prédéfinie. Il s’agit en fait d’un processus de relocalisation pour obtenir des balises sémantiques. Cet étiquetage automatique ne peut en réalité étiqueter automatiquement que les objets statiques, tels que les lignes de voie, les limites de route, etc. Grâce au modèle de perception, des catégories sémantiques telles que les lignes de voie peuvent effectivement être obtenues. Cependant, il y aura des problèmes d'intégrité et de mauvaise reconnaissance dans des scénarios difficiles. Ces problèmes peuvent être résolus grâce à cette annotation automatique. Cependant, l’inconvénient est qu’il peut ne pas être adapté aux obstacles dynamiques, tels que les véhicules en mouvement, les piétons, etc. Voici les scénarios d'utilisation : Scénarios d'utilisation de l'étiquetage automatique # 🎜🎜# De nombreuses images présentées par Tesla ont une caractéristique : il y a une occlusion de flou ou de taches, mais cela n'affecte pas sérieusement les résultats perçus. En utilisation normale, l'objectif de la caméra du véhicule peut facilement se salir, mais avec cet étiquetage automatique, la perception de Tesla sera très robuste et le coût de maintenance de la caméra sera réduit. L'étiquetage automatique ne s'applique pas aux véhicules dynamiques #🎜 🎜 #
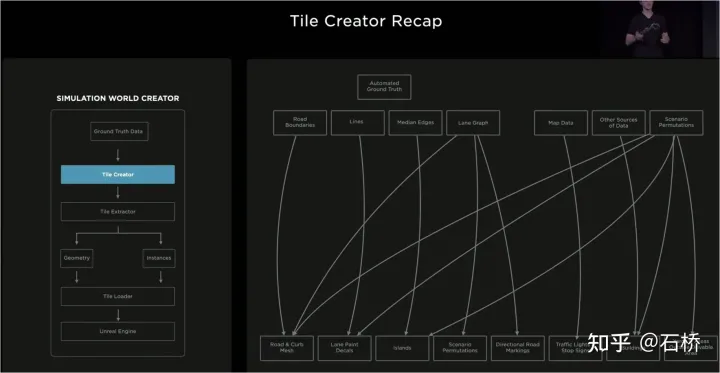
Reconstruire le monde statique et annoter # 🎜🎜# Une fois l'annotation de l'espace BEV terminée, l'annotation sera mappée à plusieurs images des caméras, réalisant ainsi qu'une annotation unique dans l'espace 4D peut être appliquée dans plusieurs images 2D. Restaurer le monde réel #🎜 🎜 # Reconstruire le monde réel #🎜 🎜#04 Simulation de scène : créez des scènes de conduite autonome basées sur des informations routières réelles Scene Simulation# 🎜🎜# La scène réelle construite à partir de la reconstruction est limitée par les données, les algorithmes, etc. Elle est actuellement difficile à mettre en œuvre à grande échelle et prend beaucoup de temps. Par exemple : la simulation d'une intersection réelle en. la photo ci-dessus prend 2 semaines. Cependant, la mise en œuvre de la conduite autonome repose sur la formation et les tests dans différents scénarios. Tesla a donc construit un système de simulation pour simuler des scénarios de conduite autonome. Ce système ne peut pas véritablement simuler des scénarios réels, mais l'avantage est qu'il est 1 000 fois plus rapide que les solutions de reconstruction courantes mentionnées ci-dessus. Il peut fournir des données difficiles à obtenir ou à étiqueter dans la réalité, et reste très utile pour les personnes autonomes. formation à la conduite. Architecture construite par simulation L'architecture de cet émulateur est celle indiquée ci-dessus. Les étapes suivantes sont requises lors du processus de création de scène : Étape 1 : Disposez dans le monde de simulation Ouvrez la route, utilisez l'étiquette de limite pour générer le maillage de route solide et réassociez-le à la relation topologique de la route Sur la section d'allée, construisez les détails de la voie Étape 5 : Utilisez la carte des voies pour obtenir la relation topologique de la voie et générer des itinéraires routiers (marquages de virage à gauche et à droite) et marqueurs auxiliaires#🎜 🎜# Étape 6 : Utilisez la carte des voies elle-même pour déterminer la contiguïté des voies et d'autres informations utiles Étape 7 Étape : générer des combinaisons de flux de circulation aléatoires basées sur les relations entre les voies Dans le processus ci-dessus, sur la base d'un ensemble de valeurs vraies de la carte de navigation sur voie, les paramètres de simulation peuvent être modifiés pour générer des changements, résultant en plusieurs scénarios de combinaison. De plus, selon les besoins de la formation, certains attributs de la vraie valeur peuvent même être modifiés pour créer de nouveaux scénarios permettant d'atteindre l'objectif de la formation.
Les données sont divisées en stockage de tuiles # 🎜🎜# #🎜🎜 #Ci-dessus La simulation construite est basée sur des informations routières réelles, de nombreux problèmes pratiques peuvent donc être résolus à l'aide de la simulation. Par exemple : les fonctions de conduite autonome peuvent être testées dans un environnement routier simulé à Los Angeles. (La méthode de stockage ci-dessus est utilisée dans la cartographie, le stockage et le chargement de simulation) Sentiments concernant la conduite autonome sous 05 Moteur de données : données de cas du coin minier #🎜 🎜# Le moteur de données extrait les données mal jugées par le modèle à partir du mode ombre, le rappelle et utilise des outils d'annotation automatique pour corriger les étiquettes, puis les ajoute aux ensembles de formation et de test pour optimiser en permanence le réseau. Ce processus est le nœud clé de la boucle fermée de données et continuera à générer des exemples de données de cas extrêmes. Exploration de données pour le stationnement en courbe L'image ci-dessus est un cas d'amélioration du modèle grâce à l'exploration de données pour le stationnement en courbe. À mesure que des données sont ajoutées continuellement à la formation, l'indice de précision continue de s'améliorer. 


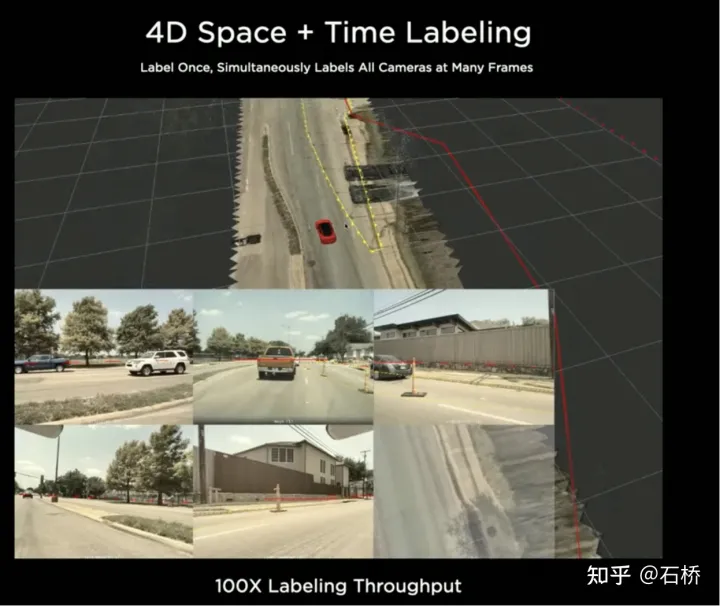


La simulation peut obtenir une étiquette absolument correcte#🎜🎜 #


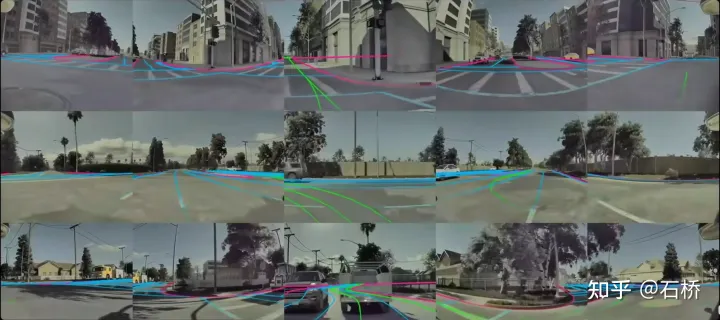 Processus de données en boucle fermée
Processus de données en boucle fermée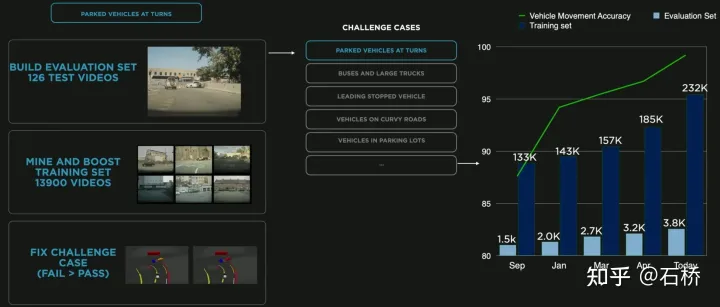
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI