
Maison >Périphériques technologiques >IA >Lancement du mPLUG-Owl de la DAMO Academy : un grand modèle multimodal modulaire, rattrapant les capacités multimodales du GPT-4
Lancement du mPLUG-Owl de la DAMO Academy : un grand modèle multimodal modulaire, rattrapant les capacités multimodales du GPT-4

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-17 08:28:051455parcourir
Les grands modèles de texte pur sont en plein essor, et le travail multimodal sur grands modèles a commencé à émerger dans le domaine multimodal, le plus puissant en surface, a la capacité multimodale de lire des images, mais il n'est pas encore ouvert. le public pour l'expérience, donc il n'y a pas de recherche. La communauté a commencé à rechercher et à ouvrir des sources dans cette direction. Peu de temps après l'avènement de MiniGPT-4 et de LLaVA, l'Alibaba DAMO Academy a lancé mPLUG-Owl, un grand modèle multimodal basé sur une mise en œuvre modulaire.
mPLUG-Owl est le dernier ouvrage de la série mPLUG de l'Alibaba Damo Academy. Il poursuit l'idée de formation modulaire de la série mPLUG et met à niveau le LLM en un grand modèle multimodal. Dans la série de travaux mPLUG, les précédents E2E-VLP, mPLUG et mPLUG-2 ont été acceptés respectivement par ACL2021, EMNLP2022 et ICML2023. Parmi eux, les travaux mPLUG sont en tête de la liste VQA avec des résultats surhumains.
Aujourd'hui, nous présenterons mPLUG-Owl. Ce travail démontre non seulement d'excellentes capacités multimodales à travers un grand nombre de cas, mais propose également pour la première fois un ensemble de tests complet OwlEval pour la compréhension des instructions visuelles, qui est comparé. grâce à une évaluation manuelle. En intégrant des modèles existants, notamment LLaVA, MiniGPT-4, BLIP-2 et MM-REACT basé sur le système, les résultats expérimentaux montrent que mPLUG-Owl présente de meilleures capacités multimodales, en particulier dans les capacités de compréhension des commandes multimodales et capacités de compréhension des commandes multimodales. Performances exceptionnelles en matière de capacité de conversation à tour de rôle, de capacité de raisonnement par connaissances, etc.
Lien du code : https://github.com/ Adresse de l'expérience HuggingFace : 
https://huggingface.co/spaces/MAGAer13/mPLUG-Owl
Démonstration de la capacité multimodaleNous comparons mPLUG-Owl avec les travaux existants Pour ressentir l'effet multimodal de mPLUG-Owl, il convient de mentionner que les échantillons de test évalués dans ce travail proviennent essentiellement de travaux existants, évitant ainsi le problème du choix.
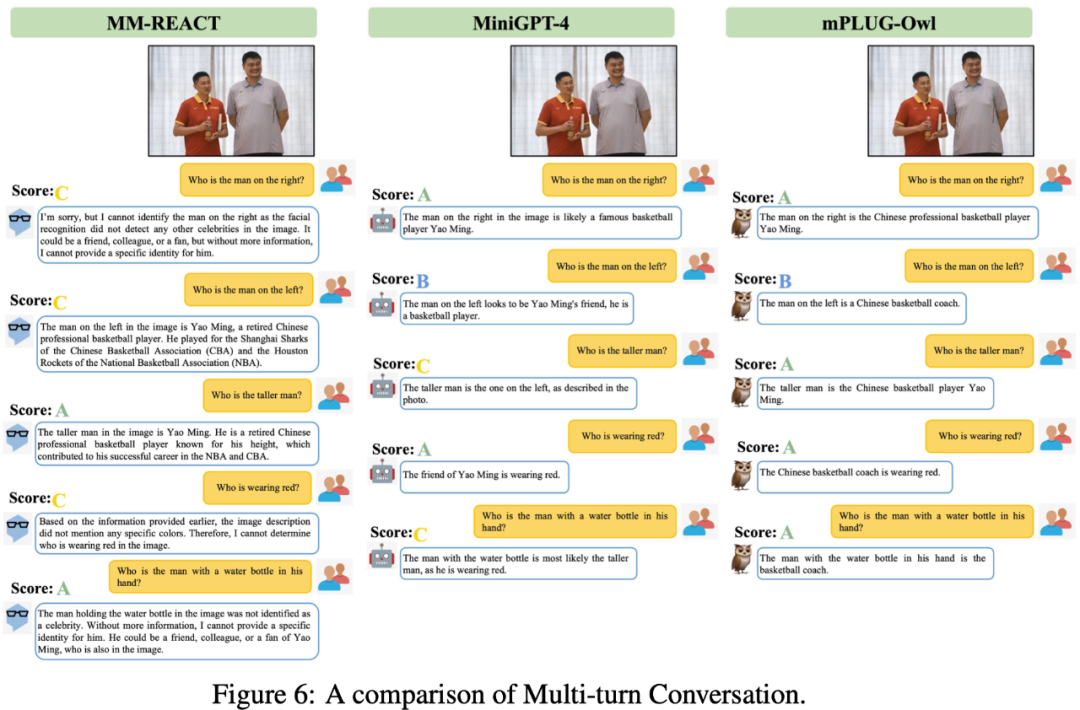
La figure 6 ci-dessous montre les fortes capacités de dialogue multi-tours de mPLUG-Owl.
On peut constater à partir de la figure 7 que mPLUG-Owl a de fortes capacités de raisonnement.
La figure 9 montre quelques exemples d'explications de blagues.
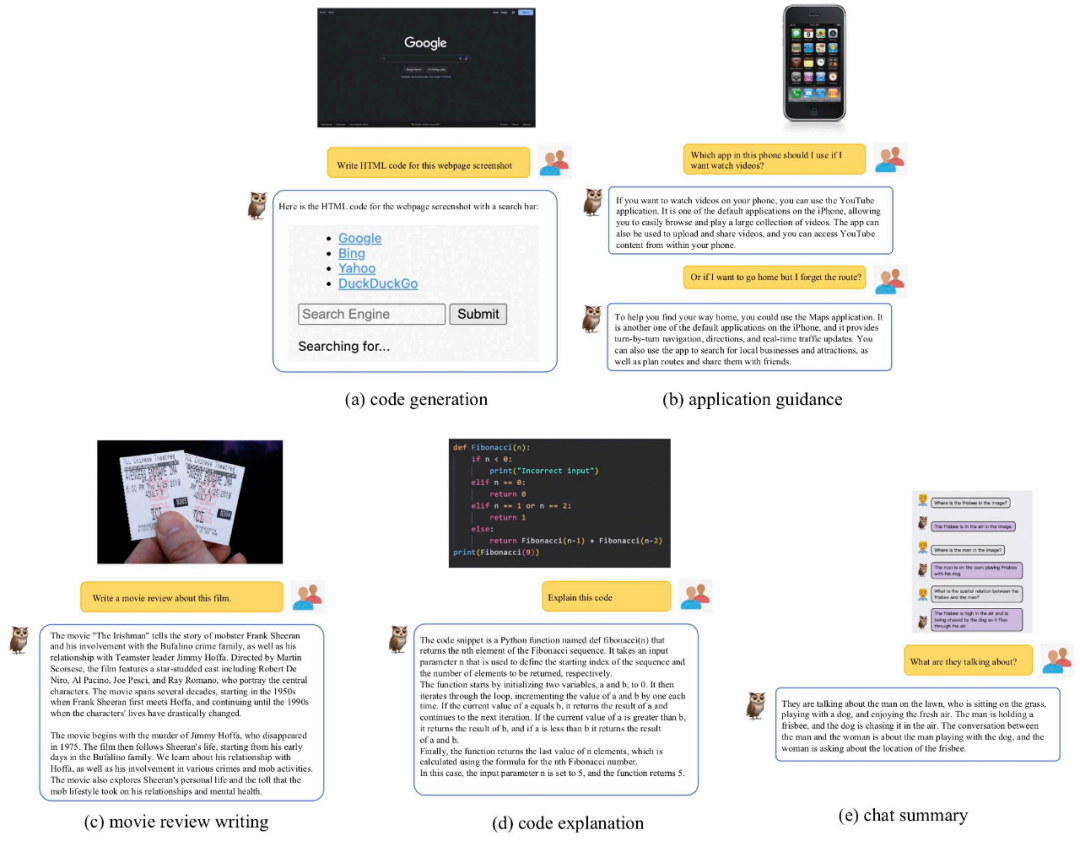
Dans ce travail, en plus de l'évaluation et de la comparaison, l'équipe de recherche a également observé que mPLUG-Owl a initialement démontré des capacités inattendues, telles que l'association multi-images, le multi-langue, la reconnaissance de texte et compréhension des documents et autres capacités.
Comme le montre la figure 10, bien que les données de corrélation multi-graphiques ne soient pas entraînées pendant la phase de formation, mPLUG-Owl a démontré certaines capacités de corrélation multi-graphiques.
Comme le montre la figure 11, bien que mPLUG-Owl n'utilise que des données en anglais au cours de la phase de formation, il présente des capacités multilingues intéressantes. Cela peut être dû au fait que le modèle de langage dans mPLUG-Owl utilise LLaMA, ce qui entraîne ce phénomène.

Bien que mPLUG-Owl n'ait pas été formé sur les données de documents annotés, il a néanmoins démontré certaines capacités de reconnaissance de texte et de compréhension de documents. Les résultats des tests sont présentés dans la figure 12.
Introduction à la méthode
L'architecture globale de mPLUG-Owl proposée dans ce travail est présentée dans la figure 2.
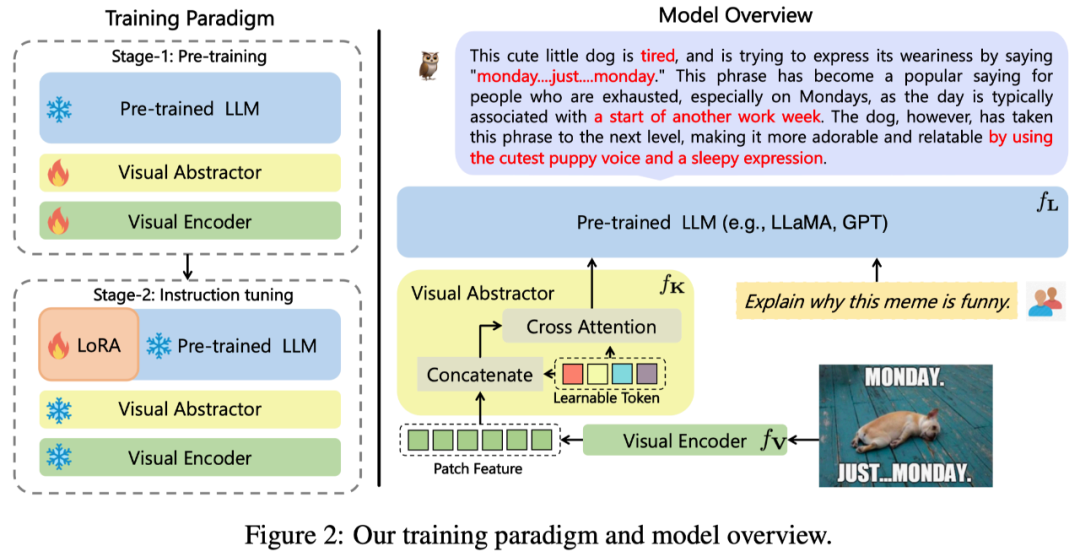
Structure du modèle : Il se compose du module de base visuel
(open source ViT-L), du module d'abstraction visuelle
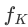
et langue de formation ⾔ Modèle
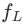
(LLaMA-7B) Composition. Le module d'abstraction visuelle résume des caractéristiques d'image plus longues et plus fines en un petit nombre de jetons apprenables, permettant ainsi une modélisation efficace des informations visuelles. Les jetons visuels générés sont entrés dans le modèle de langage avec la requête textuelle pour générer les réponses correspondantes.
Formation sur modèle : Une méthode de formation en deux étapes est adoptée
La première étape : L'objectif principal est également d'apprendre d'abord la relation entre les modalités visuelles et linguistiques. Contrairement aux travaux précédents, mPLUG-Owl propose que le gel du module visuel de base limitera la capacité du modèle à associer connaissances visuelles et connaissances textuelles. Par conséquent, mPLUG-Owl ne gèle les paramètres de LLM que dans la première étape et utilise LAION-400M, COYO-700M, CC et MSCOCO pour entraîner le module visuel de base et le module de résumé visuel.
Deuxième étape : Poursuivant la découverte selon laquelle l'entraînement mixte de différentes modalités dans mPLUG et mPLUG-2 est bénéfique l'un pour l'autre, Owl utilise également des données d'instructions en texte brut (52k d'Alpaca+) dans l'entraînement de mise au point des instructions de la deuxième étape. .90k de Vicuna+50k de Baize) et données de commande multimodales (150k de LLaVA). Grâce à des expériences d'ablation détaillées, l'auteur a vérifié les avantages apportés par l'introduction d'un enseignement textuel pur, affinant des aspects tels que la compréhension des instructions. Dans la deuxième étape, les paramètres du module visuel de base, du module de résumé visuel et du LLM original sont gelés. En référence à LoRA, seule une structure d'adaptateur avec un petit nombre de paramètres est introduite dans le LLM pour un réglage fin des instructions.
Résultats expérimentaux
Comparaison SOTA
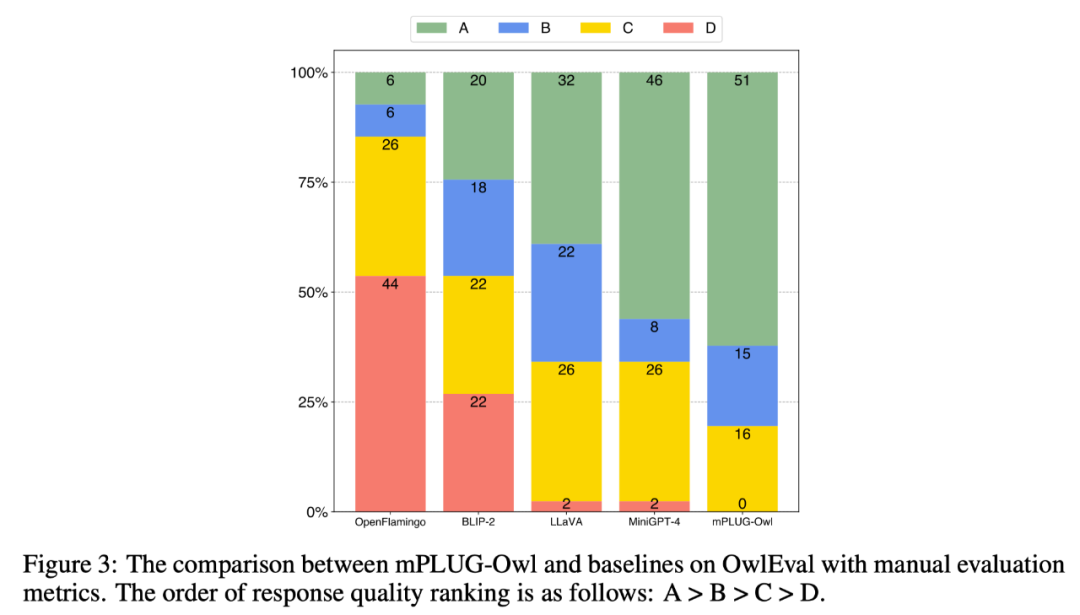
Afin de comparer les capacités multimodales de différents modèles, ce travail construit un ensemble d'évaluation d'instructions multimodales OwlEval. Puisqu'il n'existe actuellement aucun indicateur automatisé approprié, reportez-vous à Self-Intruct pour une évaluation manuelle des réponses du modèle. Les règles de notation sont : A = Correct et satisfaisant » B = Quelques imperfections, mais acceptables » ; instructions mais il y avait des erreurs évidentes dans les réponses"; D="Réponses complètement non pertinentes ou incorrectes".
Les résultats de la comparaison sont présentés dans la figure 3 ci-dessous. Les expériences prouvent que Owl est meilleur que les OpenFlamingo, BLIP-2, LLaVA et MiniGPT-4 existants dans les tâches de réponse aux commandes liées au visuel.
Comparaison des capacités multidimensionnelles
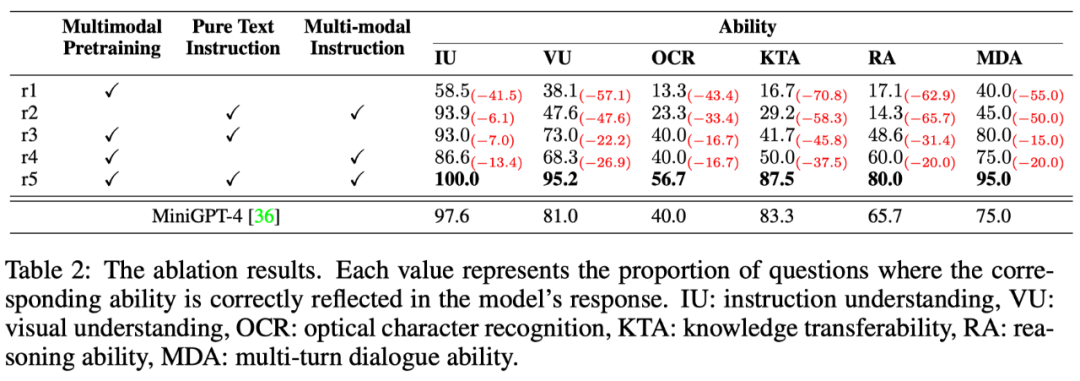
Les tâches de réponse aux commandes multimodales impliquent diverses capacités, telles que la compréhension des commandes, la compréhension visuelle, la compréhension du texte sur les images et le raisonnement. Afin d'explorer le niveau des différentes capacités du modèle de manière fine, cet article définit en outre 6 capacités principales dans des scénarios multimodaux et annote manuellement chaque instruction de test OwlEval avec les exigences de capacités pertinentes et les réponses du modèle qui y sont reflétées. . Quelles capacités ont été acquises.
Les résultats sont présentés dans le tableau 6 ci-dessous. Dans cette partie de l'expérience, l'auteur a non seulement mené des expériences d'ablation Owl pour vérifier l'efficacité de la stratégie d'entraînement et des données de réglage fin de l'instruction multimodale, mais également par rapport à les meilleures performances de l'expérience précédente Baseline : MiniGPT4 ont été comparées, et les résultats ont montré que Owl est meilleur que MiniGPT4 dans tous les aspects des capacités.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI