C'est l'expérience acquise par l'auteur Sebastian Raschka après des centaines d'expériences. Elle vaut la peine d'être lue.
L'augmentation de la quantité de données et de paramètres de modèle est reconnue comme le moyen le plus direct d'améliorer les performances des réseaux de neurones. À l'heure actuelle, le nombre de paramètres des grands modèles traditionnels s'est étendu à des centaines de milliards, et la tendance des « grands modèles » à devenir de plus en plus grands deviendra de plus en plus intense. Cette tendance a engendré de nombreux défis en matière de puissance de calcul. Si vous souhaitez affiner un grand modèle de langage avec des centaines de milliards de paramètres, la formation prend non seulement beaucoup de temps, mais nécessite également beaucoup de ressources mémoire hautes performances. Afin de « réduire » le coût de réglage fin des grands modèles, les chercheurs de Microsoft ont développé la technologie adaptative de bas rang (LoRA). La subtilité de LoRA est qu'elle équivaut à ajouter un plug-in détachable au grand modèle original, et le corps principal du modèle reste inchangé. LoRA est plug-and-play, léger et pratique. Pour affiner efficacement une version personnalisée d'un grand modèle de langage, LoRA est l'une des méthodes les plus utilisées, et c'est également l'une des méthodes les plus efficaces. Si vous êtes intéressé par le LLM open source, LoRA est une technologie de base qui mérite d'être apprise et à ne pas manquer. Sebastian Raschka, professeur de science des données à l'Université du Wisconsin-Madison, a également mené une exploration approfondie de LoRA. Ayant exploré le domaine de l'apprentissage automatique pendant de nombreuses années, il est très passionné par la décomposition de concepts techniques complexes. Après des centaines d'expériences, Sebastian Raschka a résumé son expérience dans l'utilisation de LoRA pour affiner de grands modèles et l'a publié dans le magazine Ahead of AI. 
Sur la base du maintien de l'intention originale de l'auteur, ce site a compilé cet article : Le mois dernier, j'ai partagé un article sur l'expérience LoRA, qui était principalement basé sur l'article maintenu par mes collègues et moi dans la bibliothèque Open source Lit-GPT de Lightning AI, discutant des principales expériences et leçons tirées de mes expériences. De plus, je répondrai à quelques questions fréquemment posées concernant la technologie LoRA. Si vous souhaitez affiner les grands modèles de langage personnalisés, j'espère que ces informations vous aideront à démarrer rapidement. En bref, les principaux points que j'aborde dans cet article incluent :
- Bien que la formation LLM (ou tous les modèles formés sur GPU) comporte un caractère inévitablement aléatoire, les résultats de la formation multi-lun sont toujours très cohérent.
- Si vous êtes limité par la mémoire GPU, QLoRA offre un compromis rentable. Il permet d'économiser 33 % de mémoire au prix d'une augmentation de 39 % du temps d'exécution.
- Lors du réglage fin du LLM, le choix de l'optimiseur n'est pas le principal facteur affectant les résultats. Qu’il s’agisse d’AdamW, SGD avec planificateur, ou d’AdamW avec planificateur, l’impact sur les résultats est minime.
- Bien qu'Adam soit souvent considéré comme un optimiseur gourmand en mémoire car il introduit deux nouveaux paramètres pour chaque paramètre de modèle, cela n'affecte pas de manière significative les besoins maximaux en mémoire de LLM. En effet, la majeure partie de la mémoire sera allouée à la multiplication de grandes matrices plutôt qu'à la conservation de paramètres supplémentaires.
- Pour les ensembles de données statiques, plusieurs itérations, comme plusieurs cycles d'entraînement, peuvent ne pas fonctionner correctement. Cela conduit souvent à un surentraînement et à une détérioration des résultats d'entraînement.
- Si vous souhaitez combiner LoRA, assurez-vous qu'elle est appliquée sur tous les calques, pas seulement sur la matrice Clé et Valeur, afin de maximiser les performances du modèle.
- Il est crucial d'ajuster le rang LoRA et de choisir la valeur α appropriée. À titre indicatif, essayez de définir la valeur α sur deux fois la valeur de classement.
- Un seul GPU avec 14 Go de RAM peut affiner efficacement les grands modèles avec 7 milliards de paramètres en quelques heures. Pour les ensembles de données statiques, il est impossible de renforcer le LLM pour en faire un outil « polyvalent » et performant dans toutes les tâches de base. Résoudre ce problème nécessite de diversifier les sources de données ou d’utiliser d’autres technologies que LoRA.
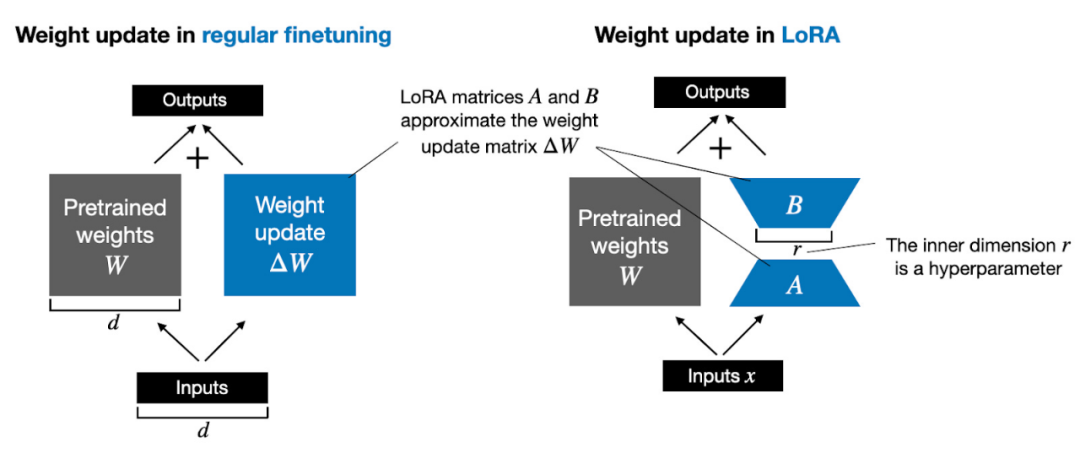
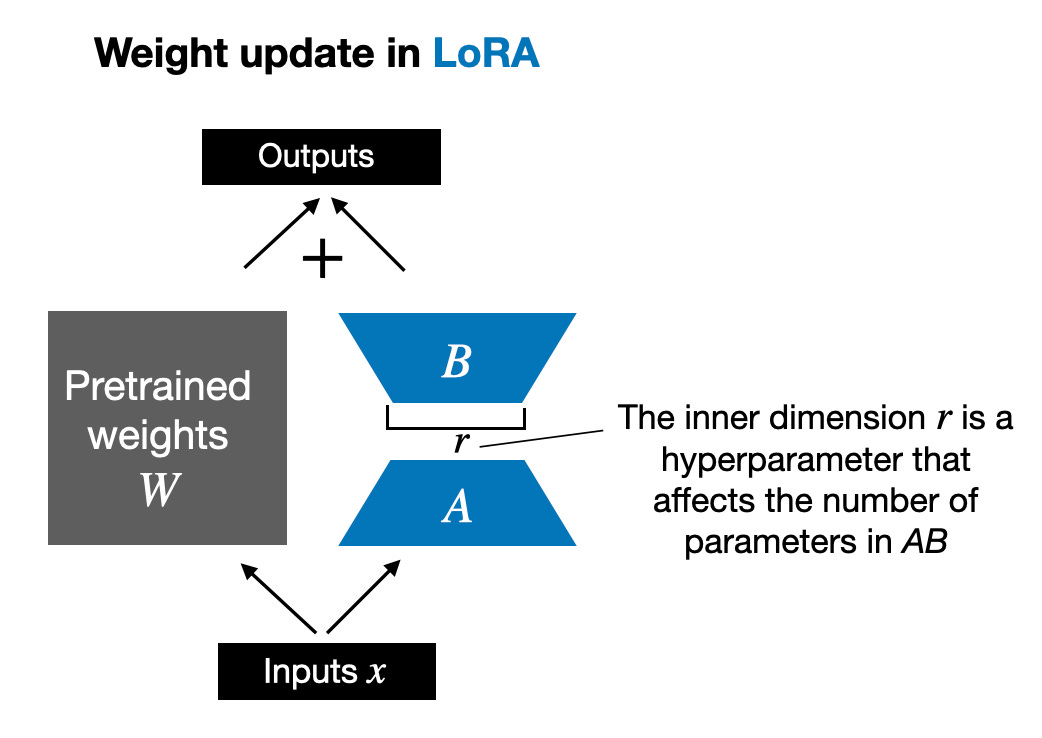
De plus, je répondrai à dix questions fréquemment posées sur LoRA. Si les lecteurs sont intéressés, j'écrirai une autre introduction plus complète à LoRA, comprenant un code détaillé pour implémenter LoRA à partir de zéro. L’article d’aujourd’hui aborde principalement les problèmes clés liés à l’utilisation de LoRA. Avant de commencer officiellement, ajoutons quelques connaissances de base. La mise à jour des poids des modèles pendant l'entraînement est coûteuse en raison des limitations de la mémoire GPU. Par exemple, supposons que nous ayons un modèle de langage de paramètres 7B, représenté par une matrice de poids W. Lors de la rétropropagation, le modèle doit apprendre une matrice ΔW, visant à mettre à jour les poids d'origine afin de minimiser la valeur de la fonction de perte. Le poids est mis à jour comme suit : W_updated = W + ΔW. Si la matrice de poids W contient 7B paramètres, la matrice de mise à jour de poids ΔW contient également 7B paramètres. Le calcul de la matrice ΔW est très gourmand en calcul et en mémoire. LoRA proposé par Edward Hu et al. décompose la partie ΔW des changements de poids en une représentation de bas rang. Plus précisément, cela ne nécessite pas de calcul explicite de ΔW. Au lieu de cela, LoRA apprend la représentation décomposée de ΔW pendant la formation, comme le montre la figure ci-dessous. C'est le secret de LoRA pour économiser les ressources informatiques.
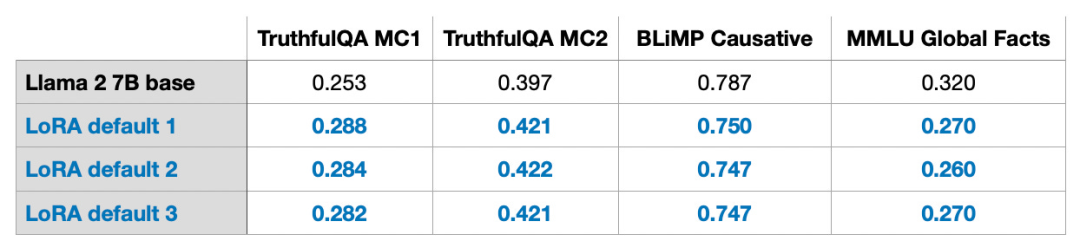
Comme indiqué ci-dessus, la décomposition de ΔW signifie que nous devons utiliser deux matrices LoRA plus petites, A et B, pour représenter la plus grande matrice ΔW. Si A a le même nombre de lignes que ΔW et B a le même nombre de colonnes que ΔW, nous pouvons écrire la décomposition ci-dessus sous la forme ΔW = AB. (AB est le résultat de la multiplication matricielle entre les matrices A et B.) Combien de mémoire cette méthode économise-t-elle ? Cela dépend aussi du rang r, qui est un hyperparamètre. Par exemple, si ΔW comporte 10 000 lignes et 20 000 colonnes, 200 000 000 de paramètres doivent être stockés. Si nous choisissons A et B avec r = 8, alors A a 10 000 lignes et 8 colonnes, et B a 8 lignes et 20 000 colonnes, soit 10 000 × 8 + 8 × 20 000 = 240 000 paramètres, soit environ 830 fois moins que 200 000 000. paramètres. Bien sûr, A et B ne peuvent pas capturer toutes les informations couvertes par ΔW, mais cela est déterminé par la conception de LoRA. Lors de l'utilisation de LoRA, nous supposons que le modèle W est une grande matrice avec un rang complet pour collecter toutes les connaissances de l'ensemble de données de pré-formation. Lorsque nous affinons LLM, nous n'avons pas besoin de mettre à jour tous les poids, mais seulement de mettre à jour moins de poids que ΔW pour capturer les informations de base. C'est ainsi que la mise à jour de bas rang est mise en œuvre via la matrice AB. Bien que le caractère aléatoire de LLM, ou du modèle formé sur le GPU, soit inévitable, LoRA a été utilisé pour mener plusieurs expériences, et les résultats finaux de référence de LLM ont été testés dans différents tests La concentration a montré une cohérence étonnante. C’est une bonne base pour mener d’autres études comparatives.
Veuillez noter que ces résultats ont été obtenus avec les paramètres par défaut, en utilisant une petite valeur de r=8. Les détails expérimentaux peuvent être trouvés dans mon autre article. Lien de l'article : https://lightning.ai/pages/community/lora-insights/QLoRA Computation - Memory TradeoffQLoRA a été proposé par Tim Dettmers et al. Abréviation de LoRA quantitative. QLoRA est une technique permettant de réduire davantage l'empreinte mémoire lors du réglage fin. Lors de la rétropropagation, QLoRA quantifie les poids pré-entraînés en 4 bits et utilise un optimiseur de pagination pour gérer les pics de mémoire. J'ai découvert que je pouvais économiser 33 % de la mémoire GPU en utilisant LoRA. Cependant, le temps de formation augmente de 39 % en raison de la quantification et de la déquantification supplémentaires des poids du modèle pré-entraîné dans QLoRA. LoRA par défaut a une précision en virgule flottante de 16 bits :
- Durée de formation : 1,85 heures
- Utilisation de la mémoire : 21,33 Go
QLoRA avec virgule flottante normale à 4 chiffres chiffres
- Le temps d'entraînement est de : 2,79 h
- L'utilisation de la mémoire est de : 14,18 Go
De plus, j'ai constaté que les performances du modèle ne sont presque pas affectées, ce qui montre que QLoRA peut être formé en tant que solution alternative LoRA qui va encore plus loin pour résoudre les goulots d'étranglement courants de la mémoire GPU.
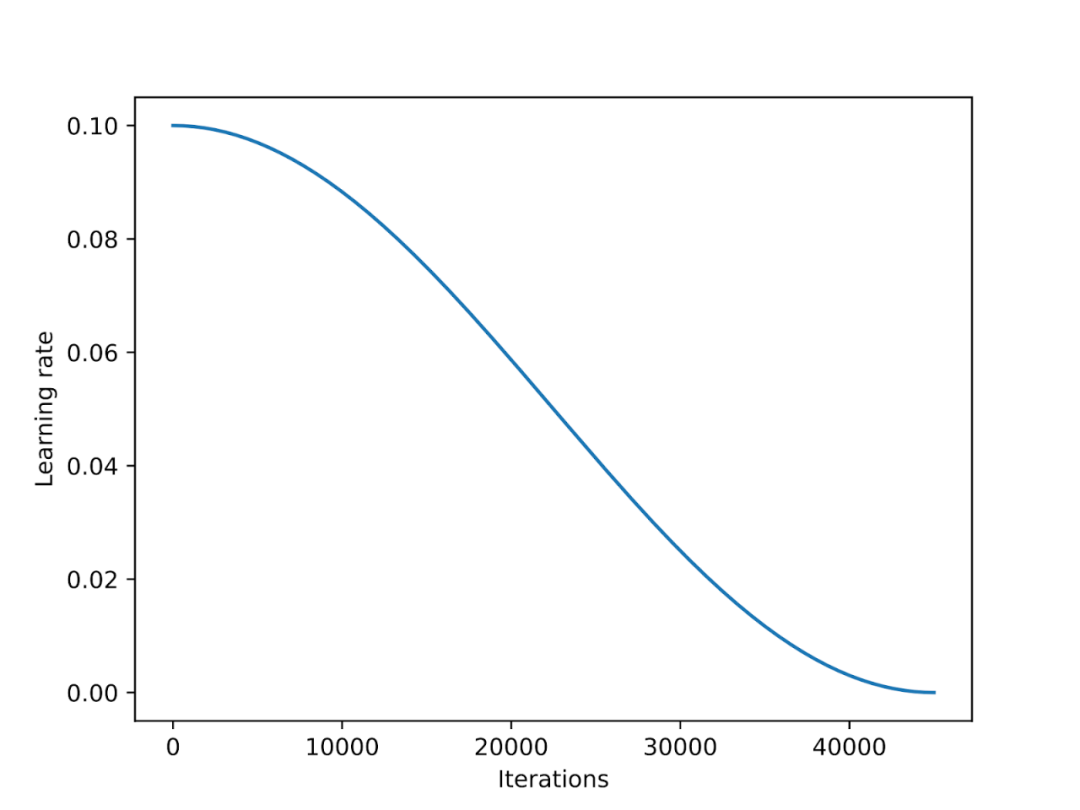
Planificateur de taux d'apprentissageLe planificateur de taux d'apprentissage réduira le taux d'apprentissage tout au long du processus de formation pour optimiser la convergence du modèle et éviter des valeurs de perte excessives. Le recuit cosinus est un planificateur qui suit une courbe cosinus pour ajuster le taux d'apprentissage. Il commence par un taux d'apprentissage plus élevé, puis diminue progressivement, se rapprochant progressivement de 0 selon un modèle semblable à celui d'un cosinus. Une variante courante du recuit cosinus est la variante demi-période, dans laquelle seul un demi-cycle cosinus est effectué pendant l'entraînement, comme le montre la figure ci-dessous.
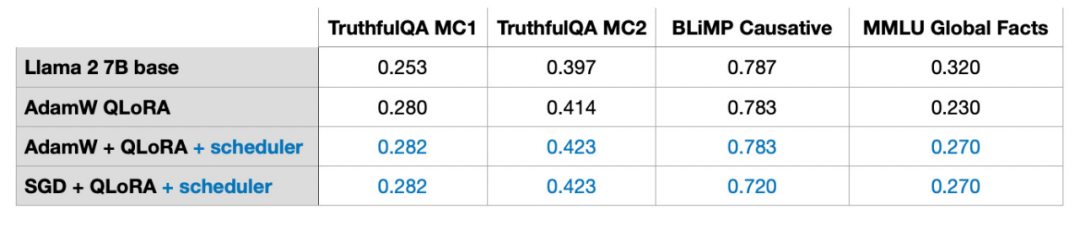
Dans les expériences, j'ai ajouté un planificateur de recuit cosinus au script de réglage fin LoRA, ce qui a considérablement amélioré les performances de SGD. Cependant, son avantage pour les optimiseurs Adam et AdamW est faible et il n'y a presque aucun changement après son ajout.
Dans la section suivante, les avantages potentiels de SGD par rapport à Adam seront discutés. Les optimiseurs Adam et AdamW sont populaires dans le deep learning. Si nous formons un modèle de paramètres 7B, l'utilisation d'Adam peut suivre des paramètres 14B supplémentaires pendant le processus de formation, ce qui équivaut à doubler le nombre de paramètres du modèle lorsque les autres conditions restent inchangées. SGD ne peut pas suivre des paramètres supplémentaires pendant l'entraînement, alors quel est l'avantage de SGD en termes de mémoire maximale par rapport à Adam ? Dans mes expériences, la formation d'un modèle Llama 2 à paramètres 7B à l'aide d'AdamW et LoRA (réglage par défaut r=8) nécessitait 14,18 Go de mémoire GPU. L'entraînement du même modèle avec SGD nécessite 14,15 Go de mémoire GPU. Par rapport à AdamW, SGD n'économise que 0,03 Go de mémoire, ce qui a un effet négligeable. Pourquoi économiser autant de mémoire ? En effet, LoRA a considérablement réduit le nombre de paramètres dans le modèle lors de l'utilisation de LoRA. Par exemple, si r = 8, sur les 6 738 415 616 paramètres du modèle Llama 2 à 7B, il n'y a que 4 194 304 paramètres LoRA pouvant être entraînés. Rien qu'en regardant les chiffres, 4 194 304 paramètres, c'est peut-être encore beaucoup, mais en fait ces nombreux paramètres n'occupent que 4 194 304 × 2 × 16 bits = 134,22 mégabits = 16,78 mégaoctets. (Nous avons observé une différence de 0,03 Go = 30 Mo en raison de la surcharge supplémentaire liée au stockage et à la copie de l'état de l'optimiseur.) 2 représente le nombre de paramètres supplémentaires stockés par Adam, tandis que 16 bits font référence aux poids du modèle Précision par défaut.
Si nous étendons le r de la matrice LoRA de 8 à 256, alors les avantages de SGD par rapport à AdamW apparaîtront :
- L'utilisation d'AdamW occupera 17,86 Go de mémoire
- L'utilisation de SGD occupera 14,46 Go
Par conséquent, lorsque la taille de la matrice augmente, la mémoire enregistrée par SGD jouera un rôle important. Étant donné que SGD n'a pas besoin de stocker des paramètres d'optimisation supplémentaires, SGD peut économiser plus de mémoire que d'autres optimiseurs tels qu'Adam lors du traitement de modèles volumineux. Il s'agit d'un avantage très important pour les tâches d'entraînement avec une mémoire limitée. Dans l'apprentissage profond traditionnel, nous répétons souvent l'ensemble de formation plusieurs fois, et chaque itération est appelée une époque. Par exemple, lors de la formation d’un réseau neuronal convolutif, vous l’exécutez généralement pendant des centaines d’époques. Alors, plusieurs cycles de formation itérative ont-ils également un effet sur la mise au point de l’enseignement ? La réponse est non, lorsque j'ai doublé le nombre d'itérations sur l'exemple d'instruction Alpaca affinant l'ensemble de données avec 50 000 données, les performances du modèle ont chuté.
Je suis donc arrivé à la conclusion que plusieurs cycles d'itérations pourraient ne pas être propices à un peaufinage de l'enseignement. J'ai observé le même comportement dans l'exemple 1k d'ensemble de réglage fin des instructions LIMA. La baisse des performances du modèle peut être causée par un surajustement, et les raisons spécifiques doivent encore être explorées plus en détail. Utilisation de LoRA dans plus de couchesLe tableau ci-dessous montre des expériences où LoRA fonctionne uniquement sur des matrices sélectionnées (c'est-à-dire les matrices de clé et de valeur dans chaque transformateur). De plus, nous pouvons activer LoRA dans la matrice de poids des requêtes, la couche de projection, d'autres couches linéaires entre les modules d'attention multi-têtes et la couche de sortie.
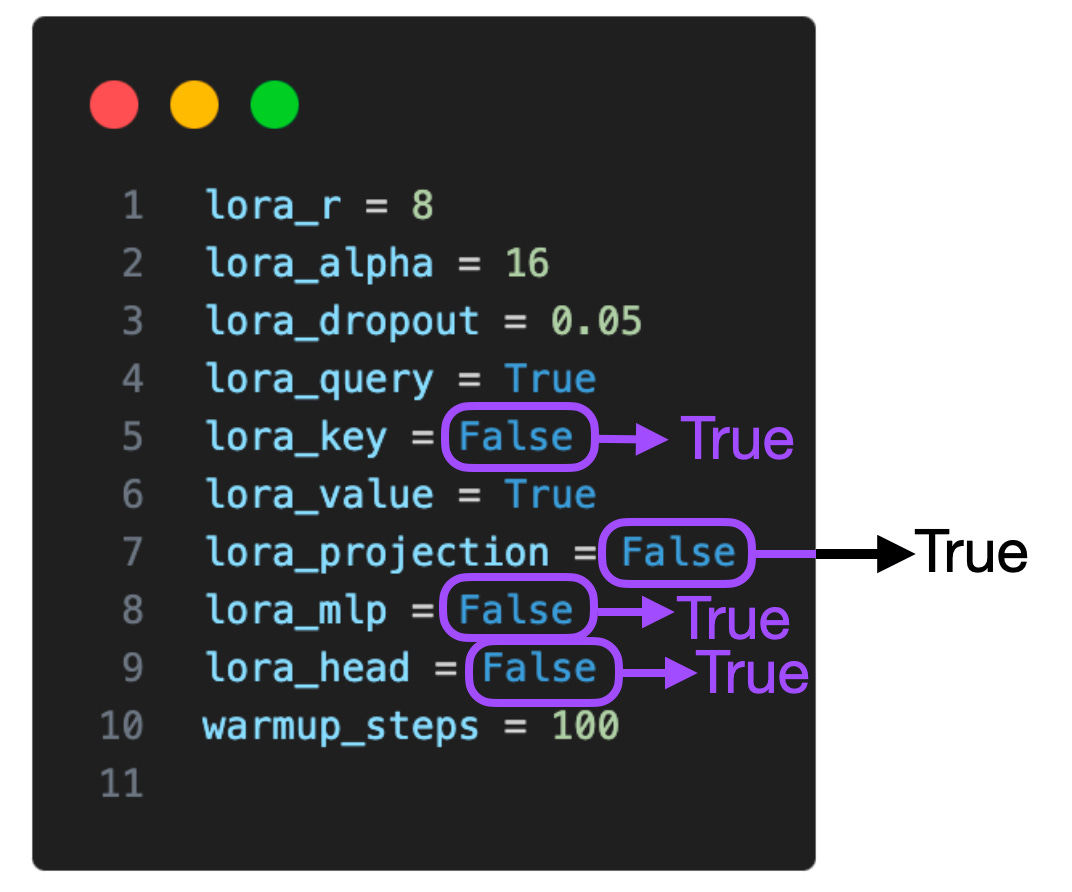
Si l'on ajoute LoRA sur ces couches supplémentaires, le nombre de paramètres entraînables est multiplié par cinq, passant de 4 194 304 à 20 277 248 pour le modèle Llama 2 à 7B. L'application de LoRA à davantage de couches peut améliorer considérablement les performances du modèle, mais nécessite également un espace mémoire plus important. De plus, j'ai uniquement exploré ces deux paramètres : (1) LoRA avec uniquement les matrices de requêtes et de poids activées, (2) LoRA avec toutes les couches activées, l'utilisation de LoRA en combinaison avec plus de couches donne Quel type d'effet vaut la peine étude plus approfondie. Si nous pouvons savoir si l'utilisation de LoRA dans la couche de projection est bénéfique pour les résultats de la formation, nous pourrons alors mieux optimiser le modèle et améliorer ses performances.
Hyperparamètres LoRA équilibrés : R et AlphaComme indiqué dans l'article qui a proposé LoRA, LoRA introduit un facteur d'échelle supplémentaire. Ce coefficient est utilisé pour appliquer des poids LoRA au pré-entraînement pendant la propagation vers l'avant. L'extension implique le paramètre de rang r discuté précédemment, ainsi qu'un autre hyperparamètre α (alpha), qui est appliqué comme suit :
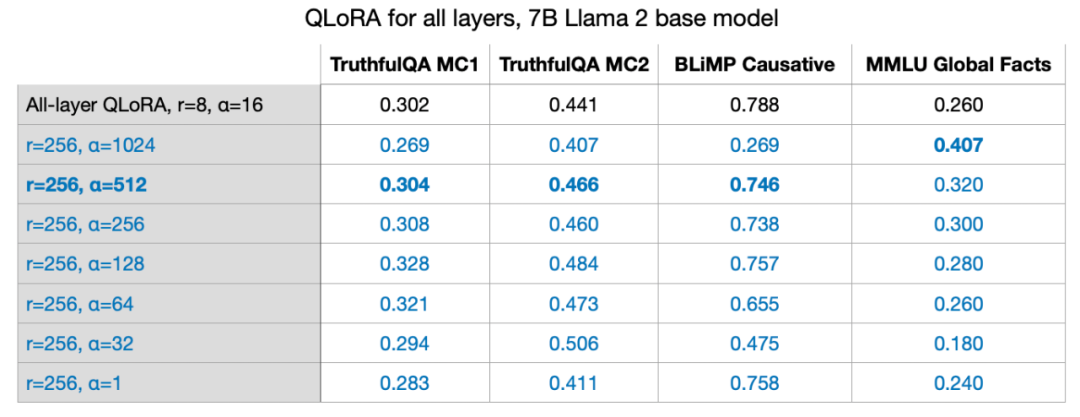
Comme le montre la formule dans l'image ci-dessus, plus la valeur du poids LoRA est grande, plus plus l’impact est grand. Dans l'expérience précédente, les paramètres que j'ai utilisés étaient r=8, alpha=16, ce qui a abouti à une expansion 2x. Lors de la réduction du poids des grands modèles avec LoRA, il est courant de définir alpha sur deux fois r. Mais je suis curieux de savoir si cette règle est toujours valable pour des valeurs plus grandes de r.
J'ai également essayé r=32, r=64, r=128 et r=512, mais j'ai omis ce processus pour plus de clarté, mais r=256 a mieux fonctionné. En fait, choisir alpha=2r fournit des résultats optimaux. Former un modèle de paramètres 7B sur un seul GPU LoRA nous permet d'affiner de grands modèles de langage à une échelle de paramètres 7B sur un seul GPU. Dans ce cas particulier, le traitement de 17,86 Go (50 000 exemples de formation) de données à l'aide de l'optimiseur AdamW a pris environ 3 heures sur l'A100 avec les meilleurs paramètres pour QLoRA (r=256, alpha=512) (ici l'ensemble de données Alpaca).
Dans la suite de cet article, je répondrai à d'autres questions que vous pourriez vous poser. Q1 : Quelle est l'importance de l'ensemble de données ? Les ensembles de données sont cruciaux. J'utilise l'ensemble de données Alpaca avec 50 000 exemples de formation. J'ai choisi l'alpaga parce qu'il est très populaire. Cet article étant déjà très long, les résultats des tests sur davantage d’ensembles de données ne seront pas abordés dans cet article. Alpaca est un ensemble de données synthétiques qui peut être un peu obsolète par rapport aux normes actuelles. La qualité des données est essentielle. Par exemple, en juin, j'ai écrit un article sur l'ensemble de données LIMA, un ensemble de données organisé composé de seulement un millier d'exemples. Lien de l'article : https://magazine.sebastianraschka.com/p/ahead-of-ai-9-llm-tuning-and-datasetComme le dit le titre de l'article proposant LIMA : Pour l'alignement, moins c'est plus. Bien que LIMA ait moins de données qu'Alpaca, le modèle 65B Llama affiné sur la base de LIMA est meilleur que les résultats d'Alpaca. En utilisant la même configuration (r=256, alpha=512), j'ai obtenu des performances de modèle similaires sur LIMA à Alpaca, qui contient 50 fois plus de données. Q2 : LoRA est-il adapté à l'adaptation de domaine ? Je n’ai pas encore de réponse claire à cette question. En règle générale, les connaissances sont généralement extraites d’ensembles de données préalables à la formation. Normalement, les modèles de langage absorbent généralement les connaissances des ensembles de données préalables à la formation, et le rôle de l'ajustement précis des instructions est principalement d'aider LLM à mieux suivre les instructions. Étant donné que la puissance de calcul est un facteur clé limitant la formation de grands modèles de langage, LoRA peut également être utilisée pour pré-former davantage les LLM pré-entraînés existants sur des ensembles de données spécialisés dans des domaines spécifiques. De plus, il convient de noter que mes expériences comprenaient deux repères arithmétiques. Sur les deux benchmarks, le modèle affiné avec LoRA a été bien moins performant que le modèle de base pré-entraîné. Je suppose que cela est dû au fait que l'ensemble de données Alpaca ne manque pas d'exemples arithmétiques correspondants, ce qui fait que le modèle "oublie" les connaissances arithmétiques. Des recherches plus approfondies sont nécessaires pour déterminer si le modèle a « oublié » les connaissances arithmétiques ou s'il a cessé de répondre aux instructions correspondantes. Cependant, une conclusion peut être tirée ici : "Lors de la mise au point d'un LLM, c'est une bonne idée que l'ensemble de données contienne des exemples pour chaque tâche qui nous intéresse." valeur? Pour ce problème, je n'ai pas encore de meilleure solution. La détermination de la valeur r optimale nécessite une analyse spécifique de problèmes spécifiques en fonction des circonstances spécifiques de chaque LLM et de chaque ensemble de données. Je suppose qu'une valeur de r trop grande entraînera un surajustement, tandis qu'une valeur de r trop petite pourrait ne pas capturer les diverses tâches de l'ensemble de données. Je soupçonne que plus il y a de types de tâches dans l'ensemble de données, plus la valeur r requise est grande. Par exemple, si j’ai uniquement besoin du modèle pour effectuer des opérations arithmétiques de base à deux chiffres, une petite valeur de r peut suffire. Cependant, ce n’est que mon hypothèse et nécessite des recherches supplémentaires pour être vérifiée. Q4 : LoRA doit-il être activé pour toutes les couches ? Je n'ai exploré que deux paramètres : (1) LoRA avec uniquement les matrices de requête et de poids activées, et (2) LoRA avec toutes les couches activées. Les effets de l’utilisation de LoRA dans des combinaisons avec plusieurs couches méritent une étude plus approfondie. Si nous pouvons savoir si l'utilisation de LoRA dans la couche de projection est bénéfique pour les résultats de la formation, nous pourrons alors mieux optimiser le modèle et améliorer ses performances. Si l'on considère les différents paramètres (lora_query, lora_key, lora_value, lora_projection, lora_mlp, lora_head), il y a 64 combinaisons à explorer.
Q5 : Comment éviter le surapprentissage ? De manière générale, un r plus grand est plus susceptible de conduire à un surapprentissage, car r détermine le nombre de paramètres pouvant être entraînés. Si votre modèle est surajusté, envisagez d'abord de réduire la valeur r ou d'augmenter la taille de l'ensemble de données. De plus, vous pouvez essayer d'augmenter le taux de dégradation du poids de l'optimiseur AdamW ou SGD, ou d'augmenter la valeur d'abandon de la couche LoRA. Je n'ai pas exploré le paramètre d'abandon de LoRA dans l'expérience (j'ai utilisé un taux d'abandon fixe de 0,05). Le paramètre d'abandon de LoRA est également une question digne de recherche.
Q6 : Existe-t-il d'autres optimiseurs parmi lesquels choisir ? Sophia, sorti en mai de cette année, vaut la peine d'être essayé. Sophia est un optimiseur stochastique de second ordre évolutif pour la pré-formation des modèles de langage.Selon l'article suivant : "Sophia : A Scalable Stochastic Second-order Optimizer for Language Model Pre-training", par rapport à Adam, Sophia est deux fois plus rapide et peut obtenir de meilleures performances. En bref, Sophia, comme Adam, implémente la normalisation via la courbure du gradient plutôt que la variance du gradient. Lien papier : https://arxiv.org/abs/2305.14342Q7 : Existe-t-il d'autres facteurs qui affectent l'utilisation de la mémoire ? En plus des paramètres de précision et de quantification, de la taille du modèle, de la taille du lot et du nombre de paramètres LoRA pouvant être entraînés, l'ensemble de données affecte également l'utilisation de la mémoire. La taille de bloc de Llama 2 est de 4048 jetons, ce qui signifie que Llama peut traiter une séquence contenant 4048 jetons à la fois. Si des masques sont ajoutés aux jetons suivants, la séquence d'entraînement sera plus courte, ce qui peut économiser beaucoup de mémoire. Par exemple, l'ensemble de données Alpaca est relativement petit, la séquence la plus longue étant de 1 304 jetons. Lorsque j'essaie d'utiliser d'autres ensembles de données avec la longueur de séquence la plus longue de 2048 jetons, l'utilisation de la mémoire passe de 17,86 Go à 26,96 Go. Q8 : Par rapport au réglage fin complet et au RLHF, quels sont les avantages de LoRA ? Je n'ai pas expérimenté le RLHF, mais j'ai essayé le trim complet. Le réglage fin complet nécessitait au moins 2 GPU, occupait 36,66 Go chacun et prenait 3,5 heures. Cependant, les mauvais résultats des tests de base peuvent être causés par un surajustement ou des paramètres sous-optimaux. Q9 : Les poids de LoRA peuvent-ils être combinés ? La réponse est oui. Pendant l'entraînement, nous séparons les poids LoRA et les poids pré-entraînés et les rejoignons à chaque passage vers l'avant. En supposant que dans le monde réel, il existe une application avec plusieurs ensembles de poids LoRA, et que chaque ensemble de poids correspond à un utilisateur de l'application, il est alors logique de stocker ces poids séparément pour économiser de l'espace disque. De plus, les poids pré-entraînés et les poids LoRA peuvent être fusionnés après l'entraînement pour créer un modèle unique. De cette façon, nous n'avons pas besoin d'appliquer des poids LoRA à chaque passe avant. weight += (lora_B @ lora_A) * scaling
Nous pouvons mettre à jour les poids en utilisant la méthode indiquée ci-dessus et enregistrer les poids combinés. De même, nous pouvons continuer à ajouter de nombreux ensembles de poids LoRA : weight += (lora_B_set1 @ lora_A_set1) * scaling_set1weight += (lora_B_set2 @ lora_A_set2) * scaling_set2weight += (lora_B_set3 @ lora_A_set3) * scaling_set3...
Je n'ai pas fait d'expériences pour évaluer cette méthode, mais via le script scripts/merge_lora.py fourni dans Lit-GPT. déjà possible. Lien de script : https://github.com/Lightning-AI/lit-gpt/blob/main/scripts/merge_lora.pyQ10 : Comment sont les performances de la couche par couche couche d'adaptation de rang optimale ? Pour simplifier, dans les réseaux de neurones profonds, nous définirons généralement le même taux d'apprentissage pour chaque couche. Le taux d'apprentissage est un hyperparamètre que nous devons optimiser, et de plus, nous pouvons choisir un taux d'apprentissage différent pour chaque couche (dans PyTorch, ce n'est pas une chose très compliquée). Cependant, dans la pratique, cela est rarement fait car cette approche ajoute des coûts supplémentaires et il existe de nombreux autres paramètres qui peuvent être réglés dans les réseaux de neurones profonds. Semblable au choix de différents taux d'apprentissage pour différentes couches, nous pouvons également choisir différentes valeurs LoRA r pour différentes couches. Je ne l'ai pas encore essayé, mais il existe un document qui détaille cette méthode : "LLM Optimization: Layer-wise Optimal Rank Adaptation (LORA)". En théorie, cette approche semble prometteuse, offrant de nombreuses possibilités d'optimisation des hyperparamètres. Lien papier : https://medium.com/@tom_21755/llm-optimization-layer-wise-optimal-rank-adaptation-lora-1444dfbc8e6aLien original : https:// magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms?continueFlag=0c2e38ff6893fba31f1492d815bf928bCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!