
Maison >Périphériques technologiques >IA >Microsoft a transformé GPT-4 en un expert médical avec juste le « Prompt Project » ! Plus d'une douzaine de modèles hautement peaufinés, la précision des tests professionnels a dépassé 90 % pour la première fois
Microsoft a transformé GPT-4 en un expert médical avec juste le « Prompt Project » ! Plus d'une douzaine de modèles hautement peaufinés, la précision des tests professionnels a dépassé 90 % pour la première fois

- 王林avant
- 2023-12-04 14:25:451402parcourir
Les dernières recherches de Microsoft prouvent une fois de plus la puissance de Prompt Engineering -
Pas besoin de réglages supplémentaires ou de planification experte, GPT-4 peut devenir un « expert » avec juste des invites.
Grâce à leur dernière stratégie d'invite Medprompt, dans le domaine professionnel de la santé, GPT-4 a obtenu les meilleurs résultats dans les neuf ensembles de tests de MultiMed QA.
Sur l'ensemble de données MedQA (questions de l'examen de licence médicale aux États-Unis), Medprompt a permis à la précision du GPT-4 de dépasser 90 % pour la première fois, surpassant BioGPT et Med-PaLM et d'autres méthodes de réglage fin.
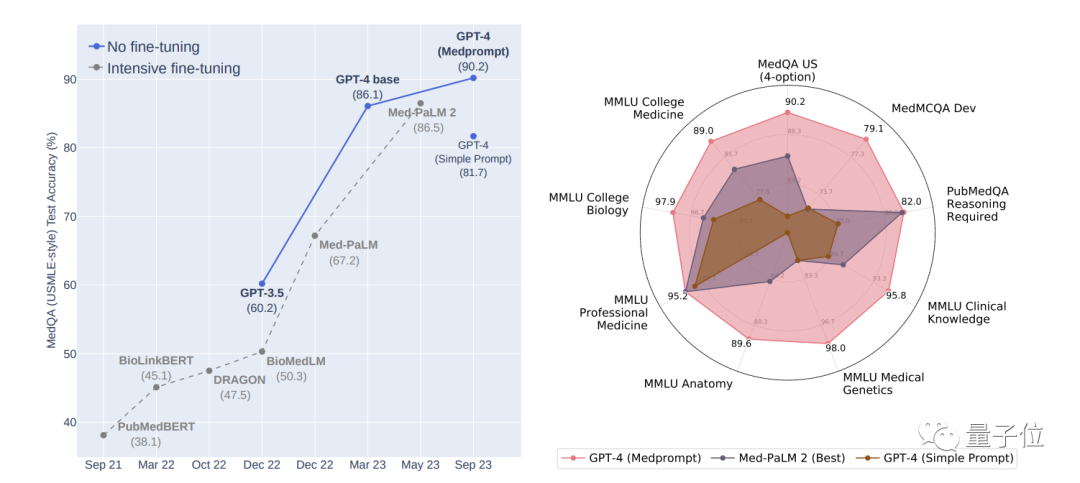
Les chercheurs ont également déclaré que la méthode Medprompt est universelle et n'est pas seulement applicable à la médecine, mais peut également être étendue au génie électrique, à l'apprentissage automatique, au droit et à d'autres disciplines.
Dès que cette étude a été partagée sur X (anciennement Twitter), elle a attiré l'attention de nombreux internautes.
Ethan Mollick, professeur à la Wharton School, Carlos E. Perez, auteur de l'intuition artificielle, etc. l'ont transmis et partagé.
Carlos E. Perez a déclaré qu'"une excellente stratégie d'incitation peut nécessiter beaucoup de peaufinage" :
Certains internautes ont déclaré qu'ils avaient cette intuition depuis longtemps, et maintenant ils peuvent voir les résultats sortir, ce qui est vraiment cool !

Certains internautes pensent que c'est vraiment "radical"
GPT-4 est une technologie qui peut changer l'industrie, et nous sommes loin d'atteindre la limite des invites, ni celle du réglage fin .

Stratégies d'incitation combinées, "transformer" en un expert
Medprompt est une combinaison de plusieurs stratégies d'incitation, dont trois armes magiques :
- Sélection dynamique de quelques coups (Sélection dynamique de quelques coups)
- Auto -chaîne de pensée auto-générée
- Ensemble de mélange de choix
Ensuite, nous les présenterons un par un

Sélection dynamique de quelques coups
L'apprentissage de moins de coups consiste à rendre le modèle rapide Un moyen efficace pour apprendre le contexte. En termes simples, saisissez quelques exemples, laissez le modèle s'adapter rapidement à un domaine spécifique et apprenez à suivre le format de la tâche.
Ce type d'exemples de quelques échantillons utilisés pour des invites de tâches spécifiques sont généralement fixes, il existe donc des exigences élevées en matière de représentativité et d'étendue des exemples.
Une méthode précédente consistait à laisser les experts du domaine créer manuellement des exemples, mais même ainsi, rien ne garantit que les exemples fixes de quelques échantillons sélectionnés par les experts soient représentatifs dans chaque tâche.
Les chercheurs de Microsoft ont proposé une méthode d'exemples dynamiques en quelques plans, donc
L'idée est que l'ensemble d'entraînement aux tâches peut être utilisé comme source d'exemples en quelques plans, si l'ensemble d'entraînement est suffisamment grand, différents peuvent être sélectionnés. pour différentes entrées de tâches. Quelques exemples d’exemples.
En termes d'opérations spécifiques, les chercheurs ont d'abord utilisé le modèle text-embedding-ada-002 pour générer des représentations vectorielles pour chaque échantillon d'apprentissage et échantillon de test. Ensuite, pour chaque échantillon de test, en comparant la similarité des vecteurs, les k échantillons qui lui sont les plus similaires sont sélectionnés parmi les échantillons d'entraînement.
Par rapport à la méthode de réglage fin, la sélection dynamique en quelques coups utilise l'entraînement les données, mais ne nécessite pas de mises à jour approfondies des paramètres du modèle.
Chaîne de pensée auto-générée
La méthode de la chaîne de pensée (CoT) est une méthode qui permet au modèle de réfléchir étape par étape et de générer une série d'étapes de raisonnement intermédiaires
La méthode précédente reposait sur des experts pour écrire manuellement quelques exemples avec chaînes de pensées suscitées

Ici, les chercheurs ont découvert qu'on peut simplement demander à GPT-4 de générer des chaînes de pensée pour des exemples de formation en utilisant l'invite suivante :
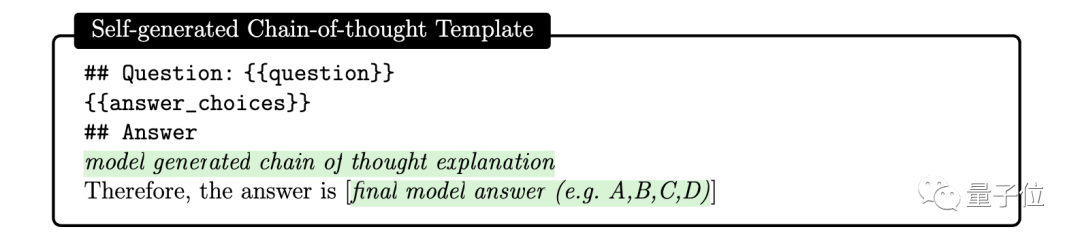
Mais les chercheurs ont également souligné que cette chaîne de pensée générée automatiquement peut contenir un raisonnement erroné. étape, donc une balise de vérification est définie comme filtre, ce qui peut réduire efficacement les erreurs.
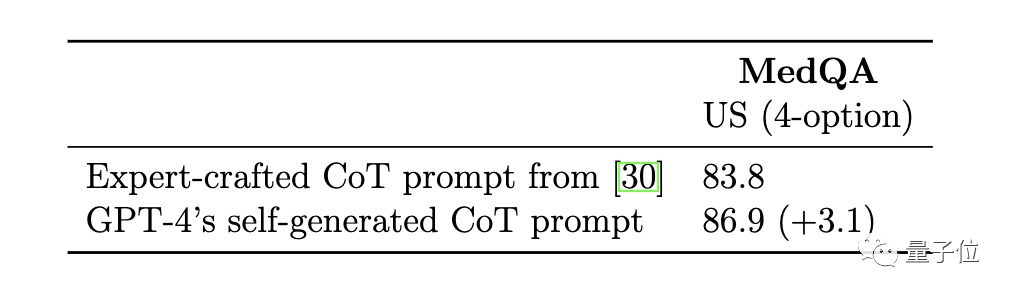
Par rapport aux exemples de chaîne de pensée élaborés à la main par des experts du modèle Med-PaLM 2, les principes de base de la chaîne de pensée générée par GPT-4 sont plus longs et la logique de raisonnement étape par étape est plus fine.
Intégration du mélange d'options
GPT-4 peut avoir un biais lors du traitement des questions à choix multiples, c'est-à-dire que quel que soit le contenu de l'option, il a tendance à toujours choisir A ou toujours B. C'est le biais de position
Pour résoudre ce problème, les chercheurs ont décidé de réorganiser l'ordre des options d'origine afin de réduire l'impact. Par exemple, l'ordre initial des options est ABCD, qui peut être modifié en BCDA, CDAB, etc. Laissez ensuite GPT-4 effectuer plusieurs tours de prédictions, en utilisant un ordre d'options différent à chaque tour. Cela « oblige » GPT-4 à considérer le contenu des options.
Enfin, votez sur les résultats de plusieurs tours de pronostics et choisissez l'option la plus cohérente et la plus correcte.
La combinaison des stratégies d'invite ci-dessus est Medprompt. Jetons un coup d'œil aux résultats des tests.
Optimal dans plusieurs tests
Dans le test, les chercheurs ont utilisé le référentiel d'évaluation MultiMed QA.
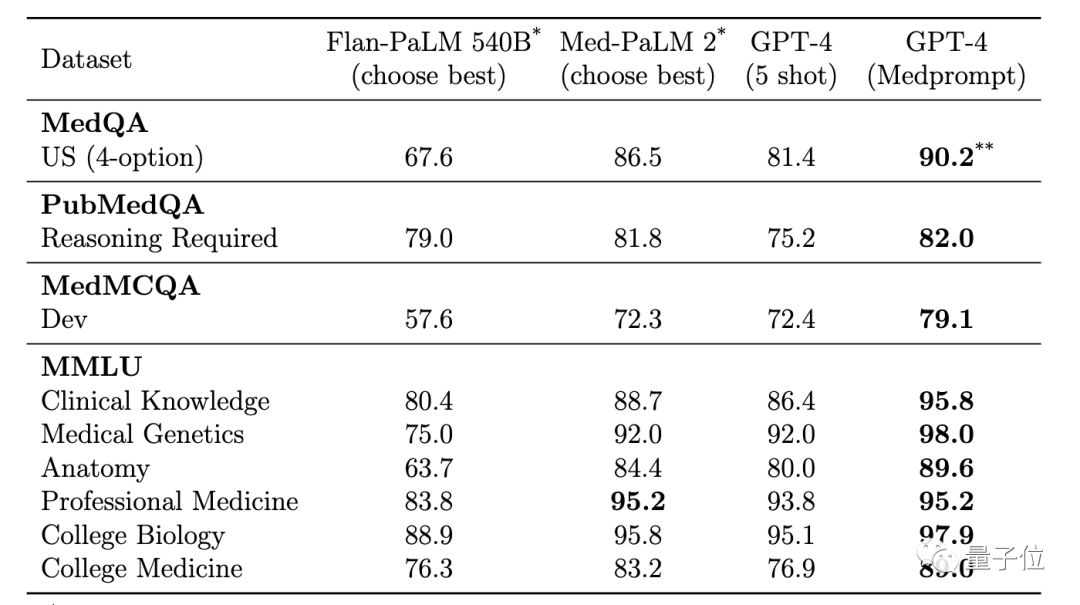 GPT-4 utilisant la stratégie d'invite Medprompt a obtenu les scores les plus élevés dans les neuf ensembles de données de référence de MultiMedQA, surpassant Flan-PaLM 540B et Med-PaLM 2.
GPT-4 utilisant la stratégie d'invite Medprompt a obtenu les scores les plus élevés dans les neuf ensembles de données de référence de MultiMedQA, surpassant Flan-PaLM 540B et Med-PaLM 2.
De plus, les chercheurs ont également discuté des performances de la stratégie Medprompt sur les données « Eyes-Off ». Les données dites « Eyes-Off » font référence à des données que le modèle n'a jamais vues pendant le processus de formation ou d'optimisation. Elles sont utilisées pour tester si le modèle surajuste les données de formation
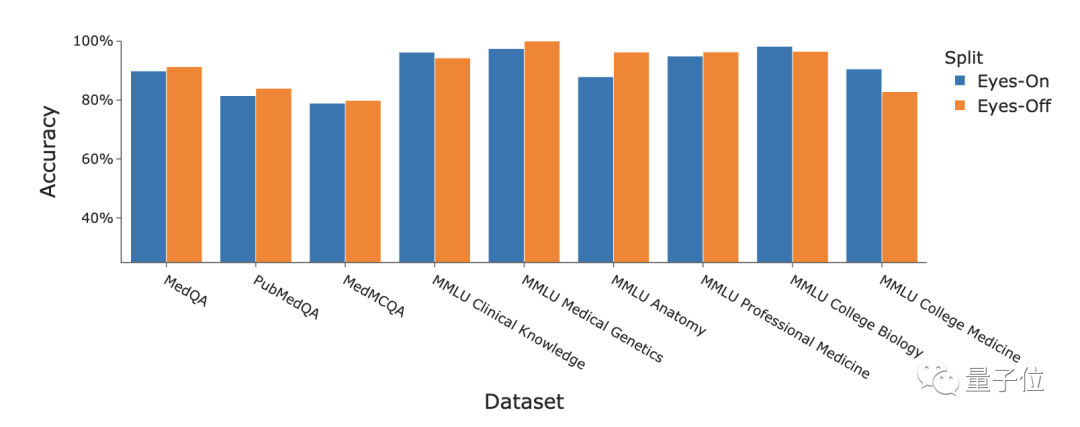 Résultats GPT-4 combinés avec. la stratégie Medprompt a été utilisée dans plusieurs domaines médicaux. Elle a obtenu de bons résultats sur l'ensemble de données de référence, avec une précision moyenne de 91,3 %.
Résultats GPT-4 combinés avec. la stratégie Medprompt a été utilisée dans plusieurs domaines médicaux. Elle a obtenu de bons résultats sur l'ensemble de données de référence, avec une précision moyenne de 91,3 %.
Les chercheurs ont mené des expériences d'ablation sur l'ensemble de données MedQA pour explorer les contributions relatives des trois composants à la performance globale
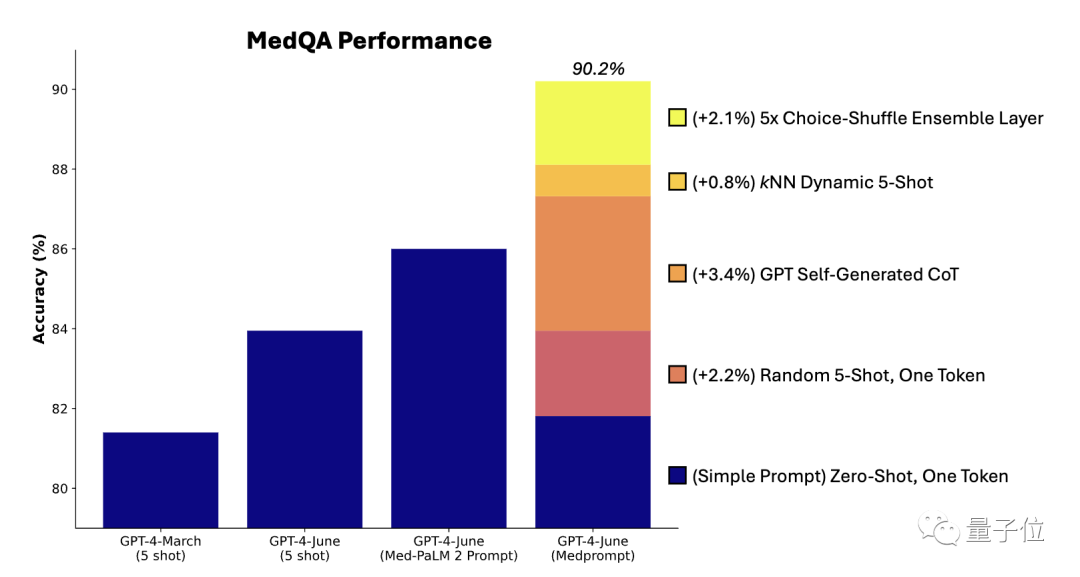 Parmi eux, la génération automatique d'étapes de la chaîne de pensée joue le rôle le plus important dans l'amélioration des performances
Parmi eux, la génération automatique d'étapes de la chaîne de pensée joue le rôle le plus important dans l'amélioration des performances
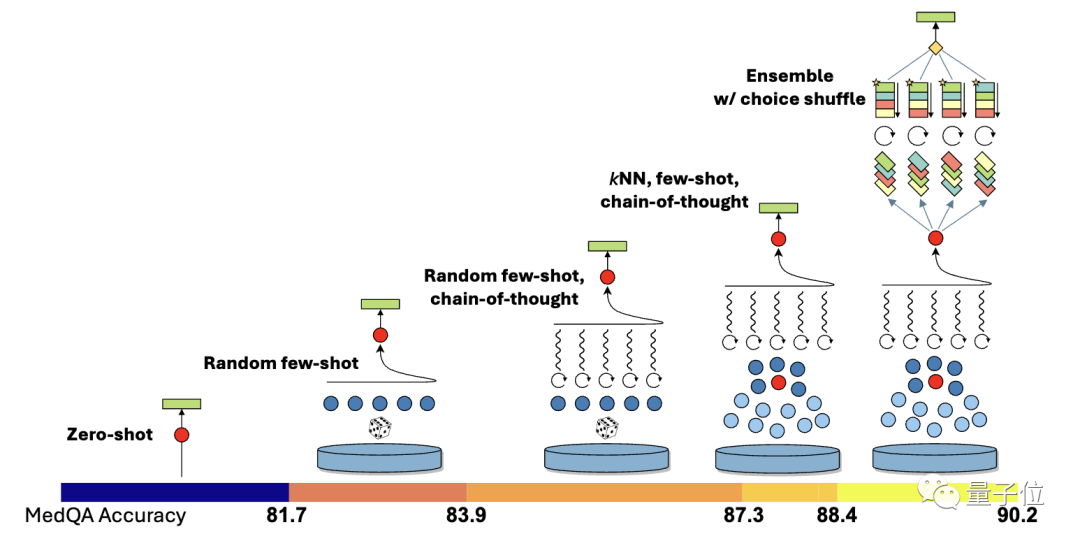 Le score de la chaîne de pensée générée automatiquement par GPT-4 est supérieur au score sélectionné par les experts de Med-PaLM 2, et aucune intervention manuelle n'est requise
Le score de la chaîne de pensée générée automatiquement par GPT-4 est supérieur au score sélectionné par les experts de Med-PaLM 2, et aucune intervention manuelle n'est requise
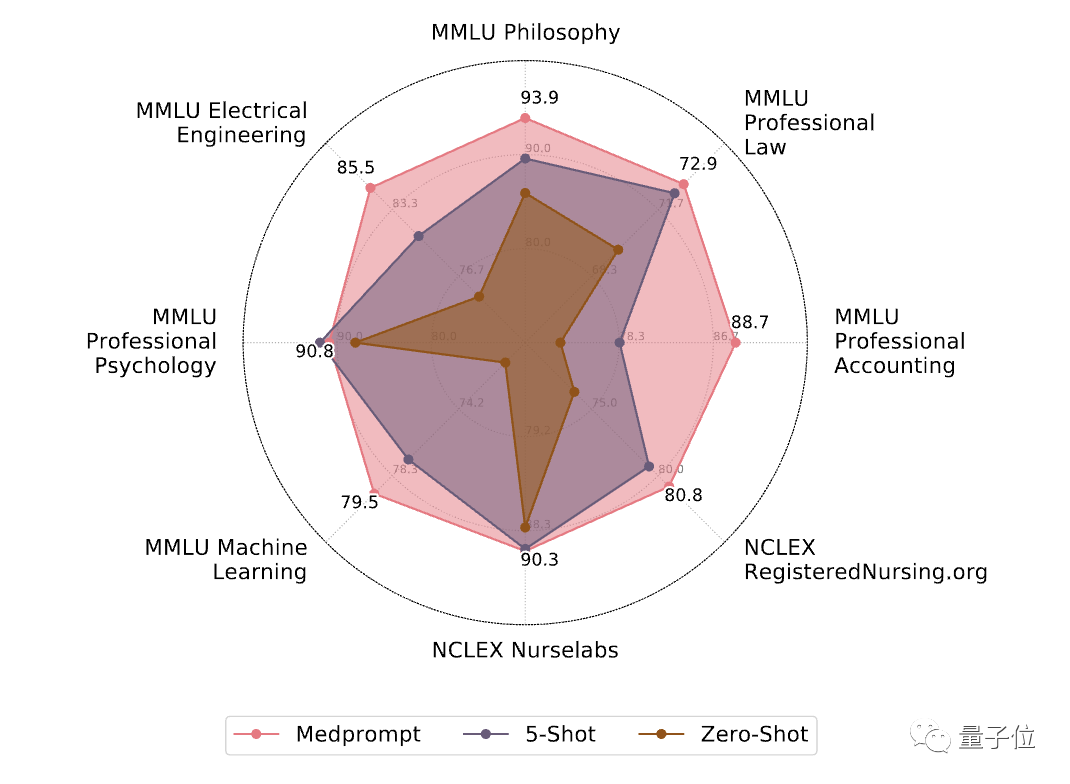
 Enfin, les chercheurs ont également exploré les capacités de généralisation inter-domaines. de Medprompt, utilisant six ensembles de données différents du benchmark MMLU sont inclus, couvrant des problèmes de génie électrique, d'apprentissage automatique, de philosophie, de comptabilité professionnelle, de droit professionnel et de psychologie professionnelle.
Enfin, les chercheurs ont également exploré les capacités de généralisation inter-domaines. de Medprompt, utilisant six ensembles de données différents du benchmark MMLU sont inclus, couvrant des problèmes de génie électrique, d'apprentissage automatique, de philosophie, de comptabilité professionnelle, de droit professionnel et de psychologie professionnelle.
Deux ensembles de données supplémentaires contenant des questions NCLEX (National Nursing Licensure Examination) ont également été ajoutés.
Les résultats montrent que l'effet de Medprompt sur ces ensembles de données est similaire à l'amélioration de l'ensemble de données médicales MultiMedQA, avec une précision moyenne augmentée de 7,3 %.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!