
Maison >Périphériques technologiques >IA >Dépasser la limite de résolution : Byte et l'Université des sciences et technologies de Chine révèlent un grand modèle de document multimodal
Dépasser la limite de résolution : Byte et l'Université des sciences et technologies de Chine révèlent un grand modèle de document multimodal

- 王林avant
- 2023-12-04 14:14:591071parcourir
Il existe désormais même de gros documents multimodaux haute résolution !
Cette technologie peut non seulement identifier avec précision les informations dans les images, mais également appeler sa propre base de connaissances pour répondre aux questions en fonction des besoins des utilisateurs
Par exemple, lorsque vous voyez l'interface Mario sur l'image, vous pouvez directement répondre qu'elle vient Nintendo fonctionne.

Ce modèle a été étudié conjointement par ByteDance et l'Université des sciences et technologies de Chine, et téléchargé sur arXiv le 24 novembre 2023
Dans cette recherche, l'équipe de l'auteur a proposé DocPedia, un haute résolution unifié Document multimodal grand modèle DocPedia.

Dans cette étude, l'auteur a utilisé une nouvelle façon de résoudre le problème des modèles existants qui ne peuvent pas analyser les images de documents haute résolution.
DocPedia a une résolution allant jusqu'à 2560 × 2560. Cependant, les grands modèles multimodaux avancés de l'industrie actuelle, tels que LLaVA et MiniGPT-4, ont une limite supérieure de résolution de traitement d'image de 336 × 336 et ne peuvent pas analyser de documents haute résolution. images.
Alors, comment ce modèle fonctionne-t-il et quel type de méthode d'optimisation est utilisé ?
Amélioration significative de divers scores d'évaluation
Dans cet article, l'auteur montre un exemple de compréhension d'images et de textes haute résolution DocPedia. On peut observer que DocPedia a la capacité de comprendre le contenu de la commande et d'extraire avec précision les informations graphiques et textuelles pertinentes à partir d'images de documents haute résolution et d'images de scènes naturelles. Par exemple, dans cet ensemble d'images, DocPedia a facilement extrait le numéro de plaque d'immatriculation, Les informations textuelles telles que la configuration de l'ordinateur et même le texte manuscrit peuvent être jugées avec précision.
 Combiné avec des informations textuelles dans les images, DocPedia peut également utiliser des capacités de raisonnement sur de grands modèles pour analyser des problèmes en fonction du contexte.
Combiné avec des informations textuelles dans les images, DocPedia peut également utiliser des capacités de raisonnement sur de grands modèles pour analyser des problèmes en fonction du contexte.
 Après avoir lu les informations sur l'image, DocPedia répondra également au contenu étendu non affiché dans l'image sur la base de sa riche base de connaissances mondiale
Après avoir lu les informations sur l'image, DocPedia répondra également au contenu étendu non affiché dans l'image sur la base de sa riche base de connaissances mondiale
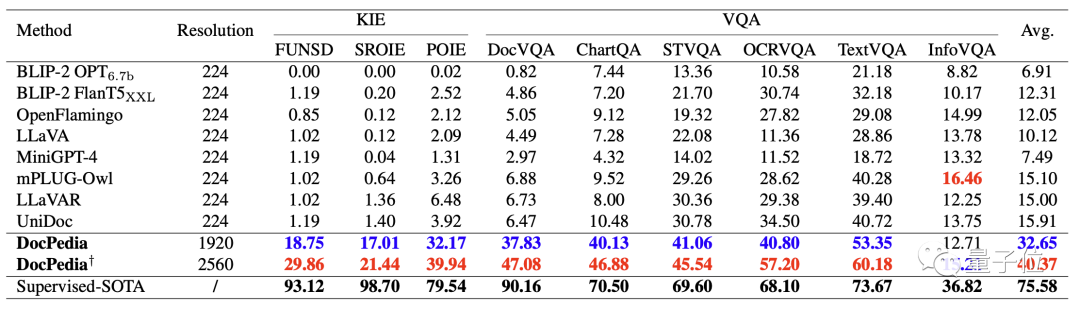
 Le tableau suivant compare quantitativement certains grands modèles multimodaux existants et la clé de DocPedia capacités d’extraction d’informations (KIE) et de réponse visuelle aux questions (VQA).
Le tableau suivant compare quantitativement certains grands modèles multimodaux existants et la clé de DocPedia capacités d’extraction d’informations (KIE) et de réponse visuelle aux questions (VQA).
En augmentant la résolution et en adoptant des méthodes de formation efficaces, nous pouvons voir que DocPedia a réalisé des améliorations significatives sur divers tests de référence
 Alors, comment DocPedia obtient-il un tel effet ?
Alors, comment DocPedia obtient-il un tel effet ?
Résoudre le problème de résolution dans le domaine fréquentiel
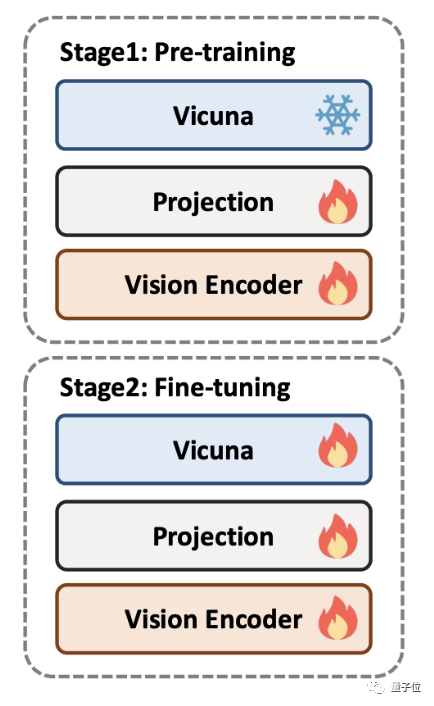
La formation DocPedia est divisée en deux étapes : la pré-formation et la mise au point. Afin de former DocPedia, l'équipe d'auteurs a collecté une grande quantité de données graphiques contenant différents types de documents et a construit un ensemble de données de mise au point des instructions.
Dans la phase de pré-formation, le grand modèle de langage sera figé, et seule la partie de l'encodeur visuel sera optimisée pour rendre son espace de représentation de jeton de sortie cohérent avec le grand modèle de langage
A ce stade, l'équipe d'auteur propose de former principalement les capacités perceptuelles de DocPedia, y compris la perception du texte et des scènes naturelles.
Les tâches de pré-formation incluent la détection de texte, la reconnaissance de texte, l'OCR de bout en bout, la lecture de paragraphes, la lecture de texte intégral et le sous-titrage d'images.
Dans la phase de mise au point, le modèle de langage à grande échelle est dégelé et effectué une optimisation globale de bout en bout
L'équipe de l'auteur a proposé une stratégie d'entraînement conjointe perception-compréhension : basée sur les tâches originales de perception de bas niveau , deux types de compréhension de documents et d'images de scènes ont été ajoutés Tâches de compréhension sémantique partielle d'ordre élevé
Une telle stratégie de formation conjointe perception-compréhension améliore encore les performances de DocPedia.
 En termes de stratégie de résolution des problèmes, contrairement aux méthodes existantes, DocPedia le résout du point de vue du
En termes de stratégie de résolution des problèmes, contrairement aux méthodes existantes, DocPedia le résout du point de vue du
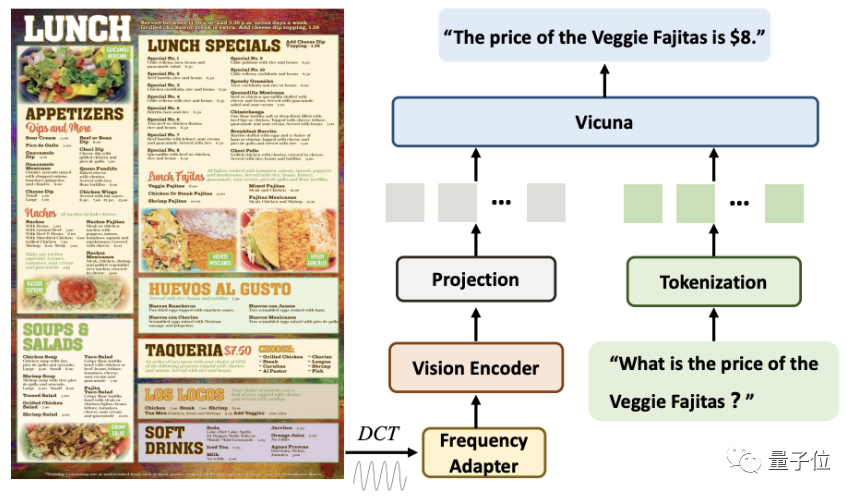
. Lors du traitement d'images de documents haute résolution, DocPedia extrait d'abord sa matrice de coefficients DCT. Cette matrice peut sous-échantillonner la résolution spatiale 8 fois sans perdre les informations textuelles de l'image originale.
Après cette étape, nous utiliserons l'adaptateur de domaine fréquentiel en cascade (adaptateur de fréquence) pour transmettre le signal d'entrée à l'encodeur Vision pour une compression de résolution plus profonde et extraction de fonctionnalités
Avec cette méthode, une image 2560×2560 peut être représentée par 1600 jetons.
Par rapport à la saisie directe de l'image originale dans un encodeur visuel (tel que Swin Transformer), cette méthode réduit le nombre de jetons de 4 fois.
Enfin, ces jetons sont concaténés avec les jetons convertis à partir des instructions dans la dimension de séquence et saisis dans le grand modèle pour réponse.
Les résultats de l'expérience d'ablation montrent que l'augmentation de la résolution et la réalisation d'un réglage précis de la perception et de la compréhension conjointes sont deux facteurs importants pour améliorer les performances de DocPedia
La figure suivante compare les performances de DocPedia sur une image papier et la même commande sur différentes entrées Réponses à l'échelle. On voit que DocPedia répond correctement si et seulement si la résolution est augmentée à 2560×2560.

L'image ci-dessous compare les réponses du modèle DocPedia à la même image de texte de scène et à la même instruction sous différentes stratégies de réglage fin.
Cet exemple montre que le modèle qui a été affiné conjointement par la perception et la compréhension peut effectuer avec précision la reconnaissance de texte et les questions et réponses sémantiques

Veuillez cliquer sur le lien suivant pour consulter l'article : https https://arxiv.org/abs/ 2311.11810
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Explication détaillée de la formation par lots PyTorch et de la comparaison des optimiseurs
- Comment supprimer une table dans la base de données dans MySQL
- Les programmeurs sont en danger ! On dit qu'OpenAI recrute des troupes d'externalisation dans le monde entier et forme étape par étape les agriculteurs de code ChatGPT.
- Yunshenchen et Shengteng CANN travaillent ensemble pour ouvrir un camp d'entraînement de développement de chiens robots à quatre pattes ROS