
Maison >développement back-end >Tutoriel Python >Explication détaillée de la formation par lots PyTorch et de la comparaison des optimiseurs
Explication détaillée de la formation par lots PyTorch et de la comparaison des optimiseurs

- 不言original
- 2018-04-28 09:46:385607parcourir
Cet article présente principalement l'explication détaillée de la formation par lots PyTorch et la comparaison des optimiseurs. Il présente en détail ce que sont la formation par lots PyTorch et l'optimiseur PyTorch. Il est d'une grande valeur pratique. Les amis dans le besoin peuvent s'y référer. 🎜 >
1. Formation par lots PyTorch
1. PrésentationPyTorch fournit un moyen de regrouper les données pour la formation par lots. Outil de formation - DataLoader. Lorsque nous l'utilisons, il nous suffit d'abord de convertir nos données sous la forme tensorielle de Torch, puis de les convertir dans un format d'ensemble de données que Torch peut reconnaître, puis de placer l'ensemble de données dans le DataLoader.
import torch
import torch.utils.data as Data
torch.manual_seed(1) # 设定随机数种子
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10)
y = torch.linspace(0.5, 5, 10)
# 将数据转换为torch的dataset格式
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 将torch_dataset置入Dataloader中
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE, # 批大小
# 若dataset中的样本数不能被batch_size整除的话,最后剩余多少就使用多少
shuffle=True, # 是否随机打乱顺序
num_workers=2, # 多线程读取数据的线程数
)
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
print('Epoch:', epoch, '|Step:', step, '|batch_x:',
batch_x.numpy(), '|batch_y', batch_y.numpy())
'''''
shuffle=True
Epoch: 0 |Step: 0 |batch_x: [ 6. 7. 2. 3. 1.] |batch_y [ 3. 3.5 1. 1.5 0.5]
Epoch: 0 |Step: 1 |batch_x: [ 9. 10. 4. 8. 5.] |batch_y [ 4.5 5. 2. 4. 2.5]
Epoch: 1 |Step: 0 |batch_x: [ 3. 4. 2. 9. 10.] |batch_y [ 1.5 2. 1. 4.5 5. ]
Epoch: 1 |Step: 1 |batch_x: [ 1. 7. 8. 5. 6.] |batch_y [ 0.5 3.5 4. 2.5 3. ]
Epoch: 2 |Step: 0 |batch_x: [ 3. 9. 2. 6. 7.] |batch_y [ 1.5 4.5 1. 3. 3.5]
Epoch: 2 |Step: 1 |batch_x: [ 10. 4. 8. 1. 5.] |batch_y [ 5. 2. 4. 0.5 2.5]
shuffle=False
Epoch: 0 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 0 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
Epoch: 1 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 1 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
Epoch: 2 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 2 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
'''2. TensorDataset
classtorch.utils.data.TensorDataset(data_tensor, target_tensor)
La classe TensorDataset est utilisée pour regrouper des échantillons et leurs étiquettes dans un data_tensor torch, et target_tensor sont tous deux des tenseurs.
3. DataLoader
Le code est le suivant : classtorch.utils .data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,num_workers=0, collate_fn=9ade065bd6c645402c3d08d2a19f19f6, pin_memory=False,drop_last=False)
l'ensemble de données est L'objet Dataset Format de Torch ; batch_size est le nombre d'échantillons pour chaque lot de formation, la valeur par défaut est : shuffle indique si les échantillons doivent être prélevés de manière aléatoire ; num_workers indique le nombre de threads pour lire les échantillons.
2. L'optimiseur de PyTorch Dans cette expérience, construisez d'abord un ensemble d'ensembles de données, convertissez le format et placez-le dans le DataLoader. de rechange. Définissez un réseau neuronal par défaut avec une structure fixe, puis créez un réseau neuronal pour chaque optimiseur. La différence entre chaque réseau neuronal réside uniquement dans l'optimiseur. En enregistrant la valeur de perte pendant le processus de formation, le processus d'optimisation de chaque optimiseur est enfin présenté sur l'image.
Implémentation du code :
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) # 设定随机数种子
# 定义超参数
LR = 0.01 # 学习率
BATCH_SIZE = 32 # 批大小
EPOCH = 12 # 迭代次数
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
#plt.scatter(x.numpy(), y.numpy())
#plt.show()
# 将数据转换为torch的dataset格式
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 将torch_dataset置入Dataloader中
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=2)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20)
self.predict = torch.nn.Linear(20, 1)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
# 为每个优化器创建一个Net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
# 初始化优化器
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
# 定义损失函数
loss_function = torch.nn.MSELoss()
losses_history = [[], [], [], []] # 记录training时不同神经网络的loss值
for epoch in range(EPOCH):
print('Epoch:', epoch + 1, 'Training...')
for step, (batch_x, batch_y) in enumerate(loader):
b_x = Variable(batch_x)
b_y = Variable(batch_y)
for net, opt, l_his in zip(nets, optimizers, losses_history):
output = net(b_x)
loss = loss_function(output, b_y)
opt.zero_grad()
loss.backward()
opt.step()
l_his.append(loss.data[0])
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_history):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()Résultats expérimentaux :
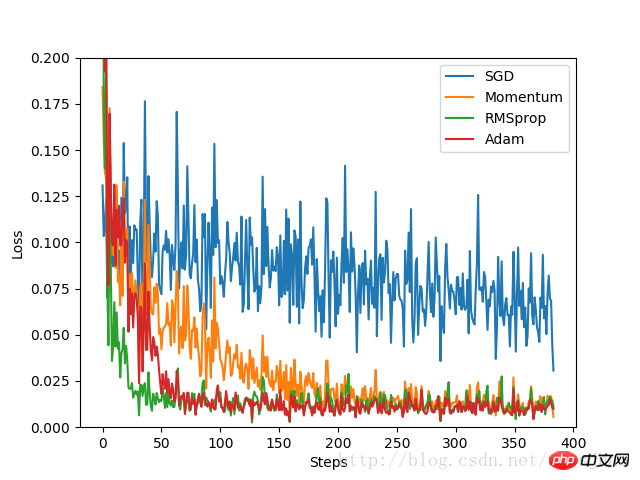 Par expérimentation Les résultats montrent que SGD a le pire effet d'optimisation et est très lent ; en tant que version améliorée de SGD, Momentum fonctionne bien mieux que RMSprop et Adam, la vitesse d'optimisation est très bonne ; Dans l'expérience, pour différents problèmes d'optimisation, les effets de différents optimiseurs ont été comparés avant de décider lequel utiliser.
Par expérimentation Les résultats montrent que SGD a le pire effet d'optimisation et est très lent ; en tant que version améliorée de SGD, Momentum fonctionne bien mieux que RMSprop et Adam, la vitesse d'optimisation est très bonne ; Dans l'expérience, pour différents problèmes d'optimisation, les effets de différents optimiseurs ont été comparés avant de décider lequel utiliser.
3. Autres suppléments
1. La fonction zip de Pythonla fonction zip accepte n'importe quel multiple. (y compris 0 et 1) les séquences sont prises comme paramètres et une liste de tuples est renvoyée.
x = [1, 2, 3] y = [4, 5, 6] z = [7, 8, 9] xyz = zip(x, y, z) print xyz [(1, 4, 7), (2, 5, 8), (3, 6, 9)] x = [1, 2, 3] x = zip(x) print x [(1,), (2,), (3,)] x = [1, 2, 3] y = [4, 5, 6, 7] xy = zip(x, y) print xy [(1, 4), (2, 5), (3, 6)]
Recommandations associées :
Introduction à l'exemple de classification mnist de PytorchCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!