
Maison >Périphériques technologiques >IA >Les images peuvent être rendues sur les téléphones mobiles en 0,2 seconde. Google crée le modèle de diffusion mobile le plus rapide, MobileDiffusion.
Les images peuvent être rendues sur les téléphones mobiles en 0,2 seconde. Google crée le modèle de diffusion mobile le plus rapide, MobileDiffusion.

- PHPzavant
- 2023-12-04 08:44:011212parcourir
L'exécution de grands modèles d'IA génératifs tels que Stable Diffusion sur les téléphones mobiles et autres appareils mobiles est devenue l'un des points chauds de l'industrie, où la vitesse de génération est la principale contrainte.
Récemment, un article de Google « MobileDiffusion : Subsecond Text-to-Image Generation on Mobile Devices » a proposé la génération de texte en image la plus rapide sur les appareils mobiles, qui ne prend que 0,2 seconde sur iPhone 15 Pro. L'article provient de la même équipe qu'UFOGen. Tout en créant un modèle de diffusion ultra-petit, il adopte également la technologie Diffusion GAN actuellement populaire pour l'accélération de l'échantillonnage.

Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/abs/2311.16567
Ce qui suit est le résultat généré par MobileDiffusion en une seule étape.

Alors, comment MobileDiffusion est-il optimisé ?
Tout d'abord, commençons par le problème et explorons pourquoi l'optimisation est nécessaire
La technologie de génération de texte en image la plus populaire à l'heure actuelle est basée sur le modèle de diffusion. En raison des solides capacités de génération d'images de base de son modèle pré-entraîné et de sa robustesse sur les tâches de réglage fin en aval, nous avons constaté les excellentes performances des modèles de diffusion dans des domaines tels que l'édition d'images, la génération contrôlable, la génération personnalisée et la génération vidéo
Cependant, en tant que modèle de base, ses défauts sont également évidents, principalement sur deux aspects : premièrement, le grand nombre de paramètres du modèle de diffusion conduit à une vitesse de calcul lente, en particulier lorsque les ressources sont limitées ; deuxièmement, le modèle de diffusion nécessite de nombreux paramètres ; L'échantillonnage comporte plusieurs étapes, ce qui entraîne en outre une inférence lente. En prenant comme exemple le très attendu Stable Diffusion 1.5 (SD), son modèle de base contient près d'un milliard de paramètres. Nous avons quantifié le modèle et effectué une inférence sur l'iPhone 15 Pro. 50 étapes d'échantillonnage ont pris près de 80 secondes. Des besoins en ressources aussi coûteux et une expérience utilisateur lente limitent considérablement ses scénarios d'application sur le terminal mobile
Afin de résoudre les problèmes ci-dessus, MobileDiffusion optimise le point à point. (1) En réponse au problème de la grande taille du modèle, nous avons principalement mené de nombreuses expériences et optimisations sur son composant principal UNet, notamment en plaçant des opérations de simplification de convolution et d'attention coûteuses en termes de calcul sur les couches inférieures, et en ciblant l'optimisation du fonctionnement des appareils mobiles, comme fonctions d'activation, etc. (2) En réponse au problème selon lequel les modèles de diffusion nécessitent un échantillonnage en plusieurs étapes, MobileDiffusion explore et met en pratique des technologies d'inférence en une étape telles que la distillation progressive et l'UFOGen de pointe actuel.
Optimisation du modèle
MobileDiffusion est optimisé sur la base du SD 1.5 UNet le plus populaire dans la communauté open source aujourd'hui. Après chaque opération d'optimisation, la perte de performances par rapport au modèle UNet d'origine sera mesurée en même temps. Les indicateurs de mesure incluent deux métriques couramment utilisées : FID et CLIP.
Planification globale
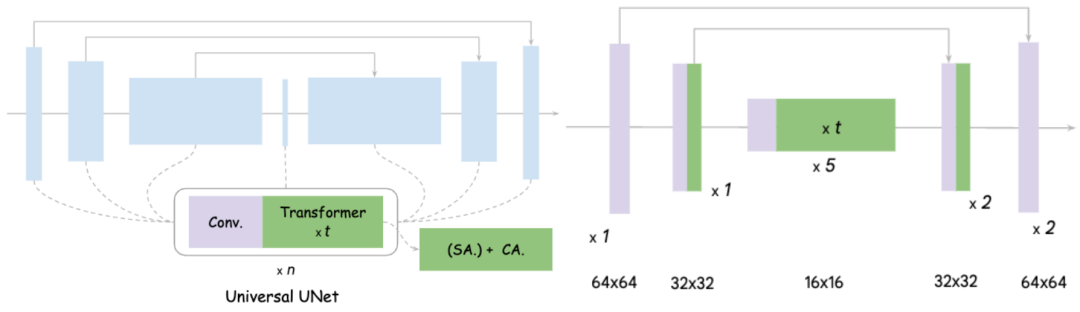
Sur le côté gauche de l'image se trouve le schéma de conception de l'UNet original. On peut voir qu'il comprend essentiellement la convolution et le Transformer, et que Transformer inclut l'auto-. Mécanisme de force d'attention et mécanisme d'attention croisée
Les idées principales de MobileDiffusion pour l'optimisation d'UNet sont divisées en deux points : 1) Streamlining Convolution Comme nous le savons tous, la convolution sur l'espace de fonctionnalités haute résolution prend beaucoup de temps et. Le nombre de paramètres est grand, il fait ici référence à Full Convolution ; 2) Amélioration de l'efficacité de l'attention. Comme la convolution, une attention élevée nécessite le calcul de la longueur de l'ensemble de l'espace des fonctionnalités. La complexité de l'auto-attention est directement liée à la longueur aplatie de l'espace des fonctionnalités, et l'attention croisée est également proportionnelle à la longueur de l'espace.
Des expériences ont prouvé que déplacer l'ensemble des 16 transformateurs d'UNet vers la couche interne avec la résolution de caractéristiques la plus basse et supprimer une convolution dans chaque couche n'a aucun impact évident sur les performances. L'effet obtenu est le suivant : MobileDiffusion réduit les 22 convolutions et 16 transformateurs d'origine à seulement 11 convolutions et environ 12 transformateurs, et ces attentions sont toutes effectuées sur des cartes de fonctionnalités basse résolution. L'efficacité de celui-ci est grandement améliorée, ce qui se traduit par une amélioration de l'efficacité de 40 % et un cisaillement des paramètres de 40 %. Le modèle final est présenté à droite. Ce qui suit est une comparaison avec d'autres modèles :

Le contenu qui doit être réécrit est : micro design
Seuls quelques nouveaux designs seront présentés ici, les lecteurs intéressés peuvent lire le le texte principal sera présenté plus en détail.
Découplage de l'attention personnelle et de l'attention croisée
Transformer dans UNet traditionnel contient à la fois l'attention personnelle et l'attention croisée. Place toute l'attention personnelle sur la carte des fonctionnalités de résolution la plus basse, mais conserve une attention croisée dans. la couche intermédiaire, on constate que cette conception améliore non seulement l'efficacité informatique mais garantit également la qualité des dessins du modèle
Finetune softmax dans relu
Comme nous le savons tous, dans la plupart des cas non optimisés, le softmax la fonction est très difficile à effectuer un traitement parallèle et l'efficacité est faible. MobileDiffusion propose une nouvelle méthode, qui consiste à ajuster (affiner) directement la fonction softmax à la fonction relu, car la fonction relu est plus efficace pour l'activation de chaque point de données. Étonnamment, avec seulement environ 10 000 étapes de réglage fin, les paramètres du modèle se sont améliorés et la qualité des images générées a été maintenue. Par conséquent, par rapport à la fonction softmax, les avantages de la fonction relu sont évidents
Convolution séparable (convolution séparable)
MobileDiffuson La clé de la rationalisation des paramètres est également l'utilisation de la convolution séparable. Cette technologie s'est avérée extrêmement efficace grâce à des travaux tels que MobileNet, notamment du côté mobile, mais elle est généralement rarement utilisée dans les modèles génératifs. Les expériences MobileDiffusion ont révélé que la convolution séparable est très efficace pour réduire les paramètres, en particulier lorsqu'elle est placée dans la couche la plus interne d'UNet. L'analyse prouve qu'il n'y a aucune perte de qualité du modèle.
Optimisation de l'échantillonnage
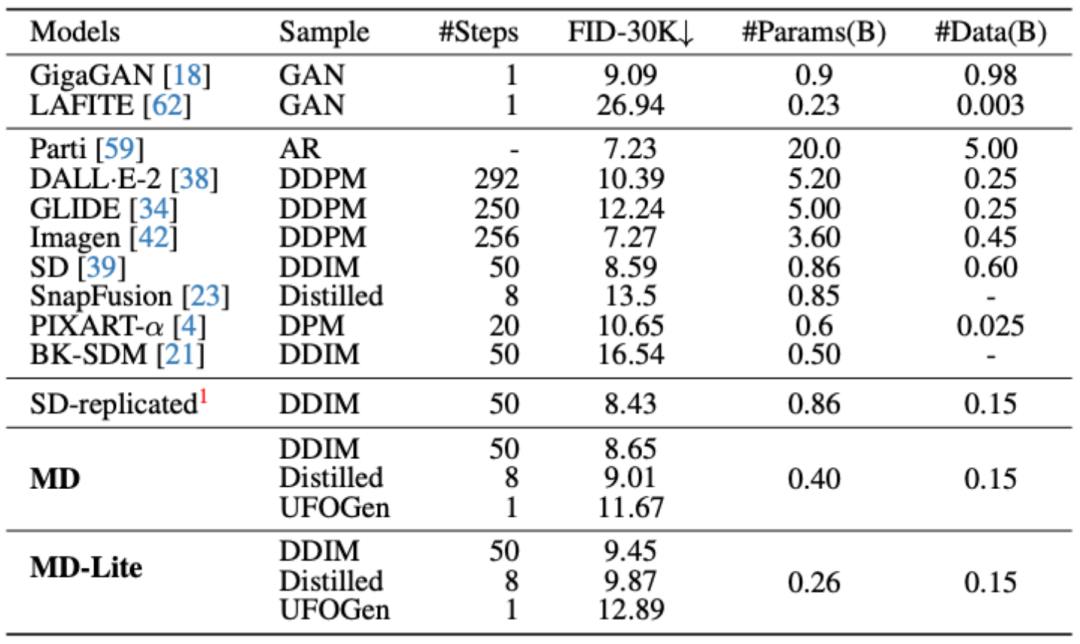
Les méthodes d'optimisation d'échantillonnage les plus populaires incluent actuellement la distillation progressive et l'UFOGen, qui peuvent réaliser respectivement 8 étapes et 1 étape. Afin de prouver que ces méthodes d'échantillonnage sont toujours efficaces même après que le modèle ait été extrêmement simplifié, MobileDiffusion a procédé à une vérification expérimentale de ces deux méthodes
L'échantillonnage optimisé a été comparé au modèle de base, et on constate que les 8 les étapes après l'optimisation de l'échantillonnage et les indicateurs de modèle en 1 étape ont été considérablement améliorés
Expériences et applications
Benchmarks mobiles
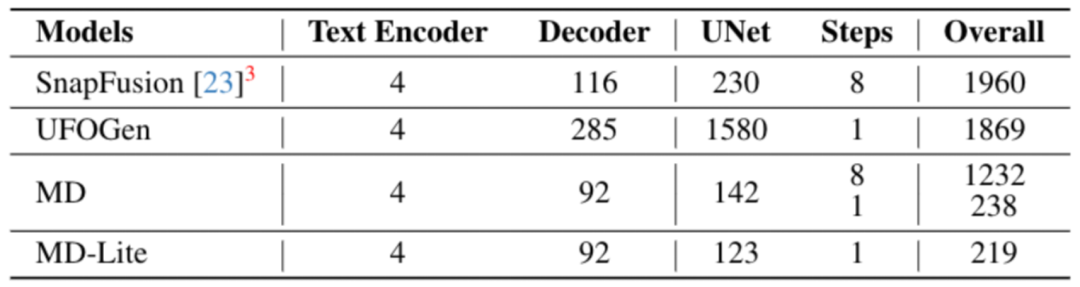
Sur iPhone 15 Pro, MobileDiffusion peut fonctionner le plus rapidement possible vitesse actuelle Le traçage est aussi rapide que 0,2 seconde !
Test de tâches en aval
MobileDiffusion a exploré les tâches en aval, notamment ControlNet/Plugin et LoRA Finetune. Comme le montre la figure ci-dessous, après l'optimisation du modèle et de l'échantillonnage, MobileDiffusion conserve toujours d'excellentes capacités de réglage fin du modèle.

Résumé
MobileDiffusion a exploré une variété de modèles et de méthodes d'optimisation d'échantillonnage, et a finalement atteint des capacités de génération d'images inférieures à la seconde du côté mobile tout en garantissant la stabilité des applications de réglage fin en aval. Nous pensons que cela aura un impact sur la conception efficace des modèles de diffusion à l'avenir et élargira les cas d'application pratiques pour les applications mobiles
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment ajouter des informations de localisation Google à votre site Web
- Que dois-je faire si Google Chrome ne prend pas en charge les paramètres CSS pour le texte de moins de 12 px ?
- Papier de 30 pages ! Nouveau travail de l'équipe de Yu Shilun : enquête complète de l'AIGC, historique du développement du GAN à ChatGPT
- 'Technologie de génération d'images' errant à la limite du droit : cet article vous apprend à éviter de devenir 'accusé'