
Maison >Périphériques technologiques >IA >Une photo génère une vidéo. Ouvrir la bouche, hocher la tête, les émotions, la colère, le chagrin et la joie peuvent tous être contrôlés en tapant.
Une photo génère une vidéo. Ouvrir la bouche, hocher la tête, les émotions, la colère, le chagrin et la joie peuvent tous être contrôlés en tapant.

- 王林avant
- 2023-12-03 11:17:21922parcourir
Récemment, une étude menée par Microsoft a révélé à quel point le logiciel de traitement vidéo PS est flexible
Dans cette étude, vous donnez simplement une photo à l'IA, et elle peut générer une vidéo des personnes sur la photo. , les expressions et les mouvements des personnages peuvent être contrôlés via le texte. Par exemple, si l'ordre que vous donnez est « ouvre la bouche », le personnage de la vidéo ouvrira réellement la bouche.

Si l'ordre que vous donnez est "triste", elle fera des expressions tristes et des mouvements de tête.
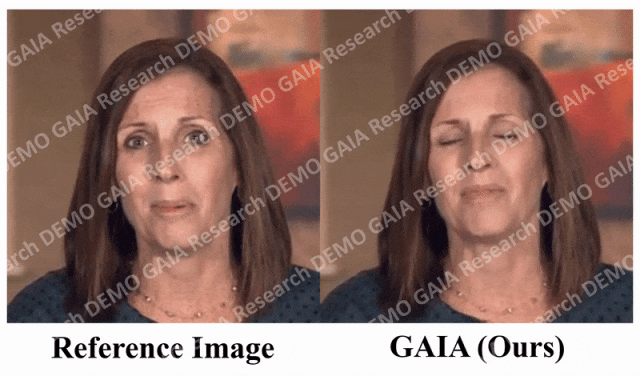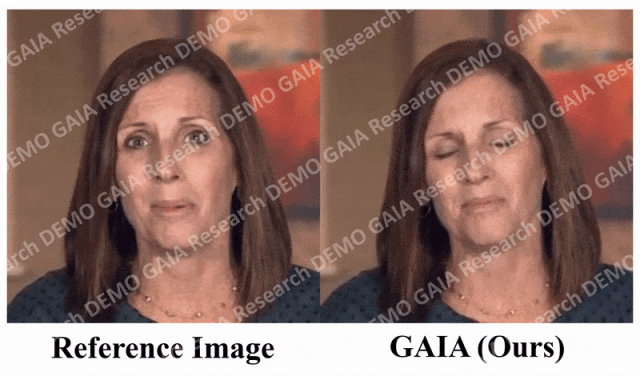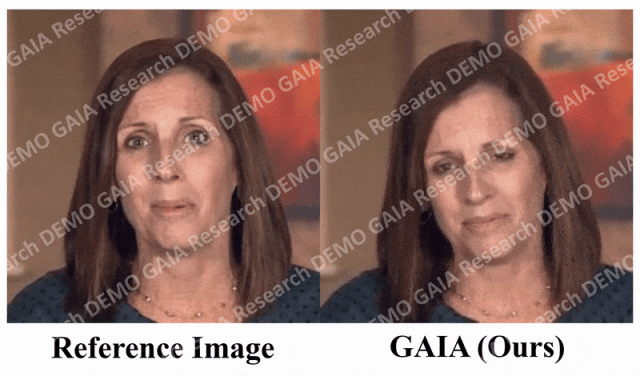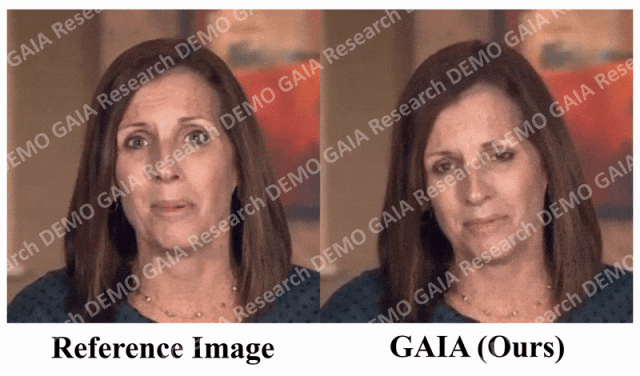
Lorsque la commande "surprise" est donnée, les lignes du front de l'avatar sont resserrées.

De plus, vous pouvez également fournir une voix pour synchroniser la forme de la bouche et les mouvements du personnage virtuel avec la voix. Alternativement, vous pouvez fournir une vidéo en direct que l'avatar pourra imiter
Si vous avez des besoins d'édition plus personnalisés pour les mouvements de l'avatar, comme lui faire hocher la tête, tourner ou incliner la tête, cette technologie est également prise en charge

Cette recherche s'appelle GAIA (Generative AI for Avatar, generative AI for avatars), et sa démo a commencé à se répandre sur les réseaux sociaux. Beaucoup de gens admirent son effet et espèrent l’utiliser pour « ressusciter » les morts.
Mais certaines personnes craignent que l'évolution continue de ces technologies rende les vidéos en ligne plus difficiles à distinguer entre les authentiques et les fausses, ou qu'elles soient utilisées par des criminels à des fins frauduleuses. Il semble que les mesures antifraude continueront à être renforcées.
Qu'est-ce qui est innovant chez GAIA ?
La technologie de génération de personnages virtuels parlants à échantillon nul vise à synthétiser des vidéos naturelles basées sur la parole, en garantissant que les formes de bouche, les expressions et les postures de la tête générées sont cohérentes avec le contenu de la parole. Les recherches antérieures nécessitent généralement une formation spécifique ou le réglage de modèles spécifiques pour chaque personnage virtuel, ou l'utilisation de modèles de vidéos lors de l'inférence pour obtenir des résultats de haute qualité. Récemment, des chercheurs se sont concentrés sur la conception et l’amélioration de méthodes permettant de générer des avatars parlants sans tir en utilisant simplement un portrait de l’avatar cible comme référence d’apparence. Cependant, ces méthodes utilisent généralement des domaines a priori tels que la représentation de mouvement basée sur la déformation et le modèle 3D Morphable (3DMM) pour réduire la difficulté de la tâche. De telles heuristiques, bien qu’efficaces, peuvent limiter la diversité et conduire à des résultats peu naturels. Par conséquent, l'apprentissage direct à partir de la distribution de données est au centre des recherches futures.
Dans cet article, des chercheurs de Microsoft ont proposé GAIA (Generative AI for Avatar), qui peut synthétiser des personnes parlant naturellement à partir de discours et de vidéos de portraits uniques. Les priorités de domaine sont éliminées pendant le processus de génération.

Adresse du projet : https://microsoft.github.io/GAIA/Les détails des projets associés peuvent être trouvés sur ce lien
Lien papier : https://arxiv.org/pdf/ 2311.15230 .pdf
Gaia révèle deux informations clés :
-
Utilisez la voix pour piloter le mouvement du personnage virtuel, tandis que l'arrière-plan et l'apparence du personnage virtuel restent inchangés tout au long de la vidéo. Inspiré par cela, cet article sépare le mouvement et l'apparence de chaque image, l'apparence étant partagée entre les images, tandis que le mouvement est unique à chaque image. Afin de prédire le mouvement à partir de la parole, cet article code les séquences de mouvement en séquences latentes de mouvement et utilise un modèle de diffusion conditionné par la parole d'entrée pour prédire la séquence latente
- Lorsqu'une personne prononce un contenu donné, il Il existe une grande diversité d’expressions et de poses de tête, ce qui nécessite un ensemble de données diversifiées à grande échelle. Par conséquent, cette étude a collecté un ensemble de données d'avatar parlant de haute qualité composé de 16 000 locuteurs uniques d'âges, de sexes, de types de peau et de styles de parole différents, rendant les résultats de génération naturels et diversifiés.
Sur la base des deux idées ci-dessus, cet article propose le cadre GAIA, qui se compose d'un auto-encodeur variationnel (VAE) (module orange) et d'un modèle de diffusion (modules bleu et vert).
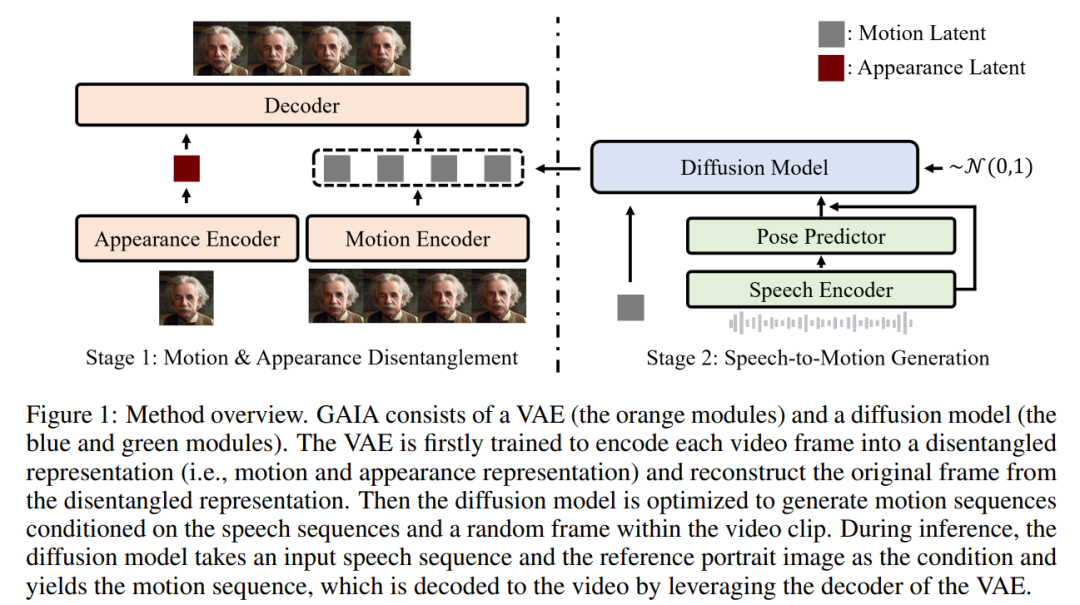
La fonction principale du VAE est de décomposer le mouvement et l’apparence. Il se compose de deux encodeurs (encodeur de mouvement et encodeur d'apparence) et d'un décodeur. Pendant l'entraînement, l'entrée de l'encodeur de mouvement est l'image actuelle des repères du visage, tandis que l'entrée de l'encodeur d'apparence est une image échantillonnée aléatoirement dans le clip vidéo actuel
Sur la base de la sortie de ces deux encodeurs, il est ensuite décodeur optimisé pour reconstruire la trame actuelle. Une fois que vous obtenez le VAE formé, vous obtenez les actions potentielles (c'est-à-dire la sortie de l'encodeur de mouvement) pour toutes les données d'entraînement
Ensuite, cet article utilise un modèle de diffusion entraîné pour prédire le mouvement sur la base d'images échantillonnées aléatoirement à partir de la parole et clips vidéo Séquence latente de mouvement, fournissant ainsi des informations d'apparence pour le processus de génération
Dans le processus d'inférence, étant donné une image de portrait de référence du personnage virtuel cible, le modèle de diffusion prend l'image et la séquence vocale d'entrée comme conditions pour générer un séquence de mouvement latente conforme au contenu de la parole. La séquence de mouvement latente générée et l'image de portrait de référence sont ensuite transmises à travers un décodeur VAE pour synthétiser la sortie vidéo parlante.
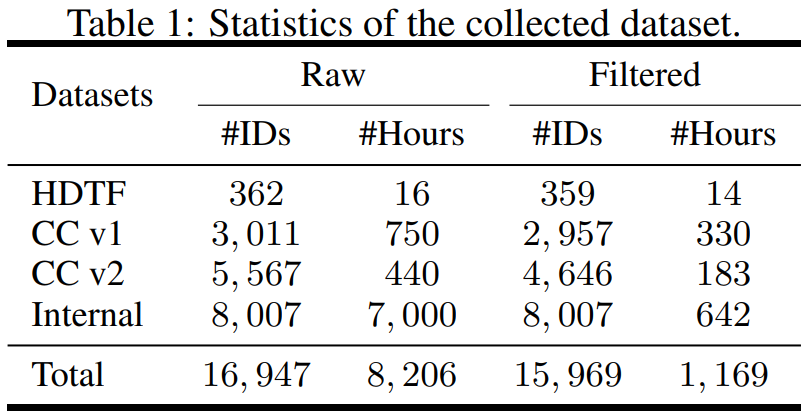
L'étude est structurée en termes de données, collectant des ensembles de données provenant de différentes sources, notamment l'ensemble de données sur les visages parlants haute définition (HDTF) et les ensembles de données de conversations occasionnelles v1 et v2 (CC v1 et v2). En plus de ces trois ensembles de données, la recherche a également collecté un ensemble de données d'avatar parlant interne à grande échelle contenant 7 000 heures de vidéo et 8 000 identifiants de locuteurs. L'aperçu statistique de l'ensemble de données est présenté dans le tableau 1
Afin d'apprendre les informations requises, l'article propose plusieurs stratégies de filtrage automatique pour garantir la qualité des données d'entraînement :
- Pour faire des lèvres mouvements visibles, la direction avant de l'avatar doit être vers la caméra ;
- Afin de garantir la stabilité, les mouvements du visage dans la vidéo doivent être fluides et ne peuvent pas trembler rapidement ;
- Afin de filtrer les cas extrêmes ; lorsque les mouvements des lèvres et la parole sont incohérents, l'avatar doit être supprimé. Portez un masque ou restez silencieux.
Cet article entraîne des modèles de VAE et de diffusion sur des données filtrées. À partir des résultats expérimentaux, cet article a obtenu trois conclusions clés :
- GAIA est capable de générer des personnages virtuels parlant sans échantillon, avec des performances supérieures en termes de naturel, de diversité, de qualité de synchronisation labiale et de qualité visuelle. Selon l'évaluation subjective des chercheurs, GAIA a largement dépassé toutes les méthodes de base ;
- La taille des modèles de formation variait de 150 M à 2B, et les résultats ont montré que GAIA est évolutif car des modèles plus grands produisent de meilleurs résultats ;
- GAIA est un cadre général et flexible qui permet différentes applications, notamment la génération d'avatars parlants contrôlables et la génération d'avatars par commande textuelle.
Comment est l'effet de GAIA ?
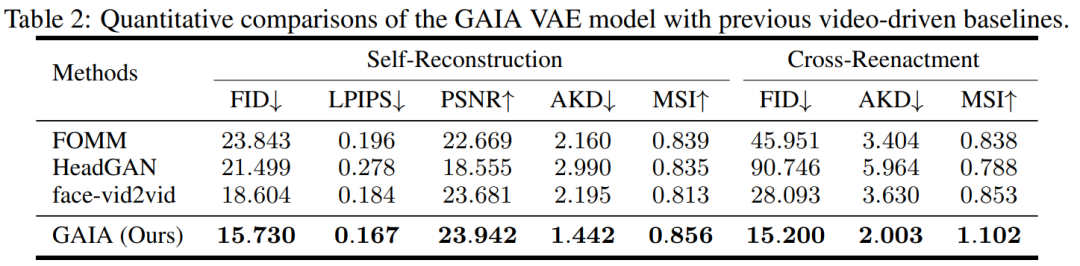
Au cours de l'expérience, l'étude a comparé GAIA à trois lignes de base puissantes, dont FOMM, HeadGAN et Face-vid2vid. Les résultats sont présentés dans le tableau 2 : VAE dans GAIA réalise des améliorations constantes par rapport aux précédentes références vidéo, démontrant que GAIA décompose avec succès les représentations d'apparence et de mouvement.
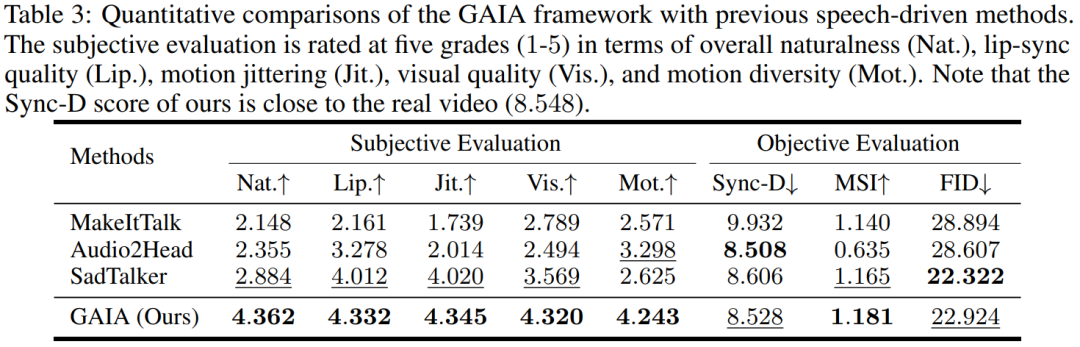
Résultats vocaux. La génération d'avatars parlants basée sur la parole est obtenue en prédisant le mouvement à partir de la parole. Le tableau 3 et la figure 2 fournissent des comparaisons quantitatives et qualitatives de GAIA avec les méthodes MakeItTalk, Audio2Head et SadTalker.
Il ressort clairement des données que GAIA surpasse de loin toutes les méthodes de base en termes d'évaluation subjective. Plus précisément, comme le montre la figure 2, même si l'image de référence a les yeux fermés ou une pose de tête inhabituelle, les résultats de génération des méthodes de base dépendent généralement fortement de l'image de référence. En revanche, GAIA présente de bonnes performances sur diverses images de référence ; Robuste et génère des résultats avec un naturel plus élevé, une synchronisation labiale élevée, une meilleure qualité visuelle et une diversité de mouvements

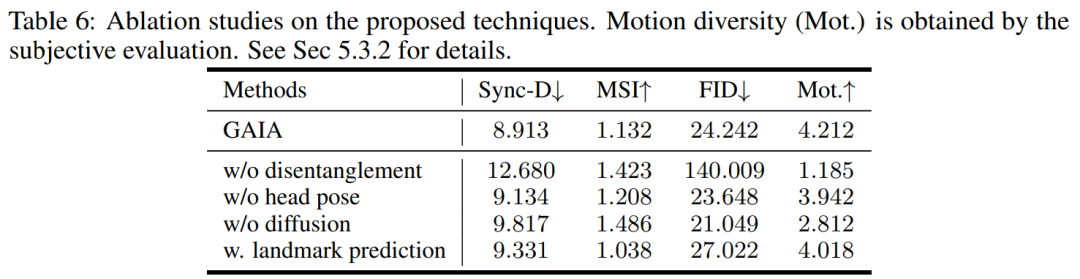
Selon le tableau 3, le meilleur score MSI montre que la vidéo générée par GAIA possède une excellente stabilité de mouvement. Le score Sync-D de 8,528 est proche du score vidéo réel (8,548), indiquant que la vidéo générée présente une excellente synchronisation labiale. L'étude a obtenu des scores FID comparables à la ligne de base, qui peuvent avoir été affectés par différentes poses de tête, car l'étude a révélé que le modèle sans formation de diffusion a obtenu de meilleurs scores FID, comme détaillé dans le tableau 6
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce que le modèle de données relationnelles
- Comment construire un modèle mathématique en utilisant Python
- Microsoft publie discrètement un aperçu de Visual Studio Code pour le Web
- Démonstration graphique de la façon de définir le navigateur Microsoft Edge comme page d'accueil par défaut
- Adresse de téléchargement officielle de l'image ISO originale de Microsoft Win7