
Maison >Périphériques technologiques >IA >FlashOcc : Nouvelles idées pour la prédiction d'occupation, nouveau SOTA en termes de précision, d'efficacité et d'utilisation de la mémoire !
FlashOcc : Nouvelles idées pour la prédiction d'occupation, nouveau SOTA en termes de précision, d'efficacité et d'utilisation de la mémoire !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-28 11:21:501007parcourir
Titre original : FlashOcc : Prédiction d'occupation rapide et efficace en mémoire via le plug-in Channel-to-Height
Lien papier : https://arxiv.org/pdf/2311.12058.pdf
Affiliation de l'auteur : Université de technologie de Dalian Houmo AI Ade Rider University

Idée de thèse :
La prédiction d'occupation est devenue un élément clé des systèmes de conduite autonome en raison de sa capacité à atténuer les défauts de longue traîne et les absences de forme complexes répandues dans la détection d'objets 3D. Cependant, le traitement des représentations tridimensionnelles au niveau des voxels introduit inévitablement une surcharge importante en termes de mémoire et de calcul, entravant le déploiement des méthodes de prédiction d'occupation à ce jour. Contrairement à la tendance à rendre les modèles plus grands et plus complexes, cet article soutient qu'un cadre idéal devrait être facile à déployer sur différentes puces tout en conservant une grande précision. À cette fin, cet article propose un paradigme plug-and-play, FlashOCC, pour consolider une prévision d'occupation rapide et économe en mémoire tout en conservant une grande précision. En particulier, notre FlashOCC apporte deux améliorations basées sur les méthodes contemporaines de prédiction d'occupation au niveau des voxels. Premièrement, les fonctionnalités sont préservées dans BEV, permettant l’utilisation de couches convolutives 2D efficaces pour l’extraction de fonctionnalités. Deuxièmement, une transformation canal-hauteur est introduite pour promouvoir les logits de sortie du BEV vers l'espace 3D. Cet article applique FlashOCC à diverses lignes de base de prévision d'occupation sur le benchmark difficile Occ3D-nuScenes et mène des expériences approfondies pour vérifier son efficacité. Les résultats confirment que notre paradigme plug-and-play surpasse les méthodes de pointe précédentes en termes de précision, d'efficacité d'exécution et de coût de mémoire, démontrant ainsi son potentiel de déploiement. Le code sera disponible pour utilisation.
Conception du réseau :
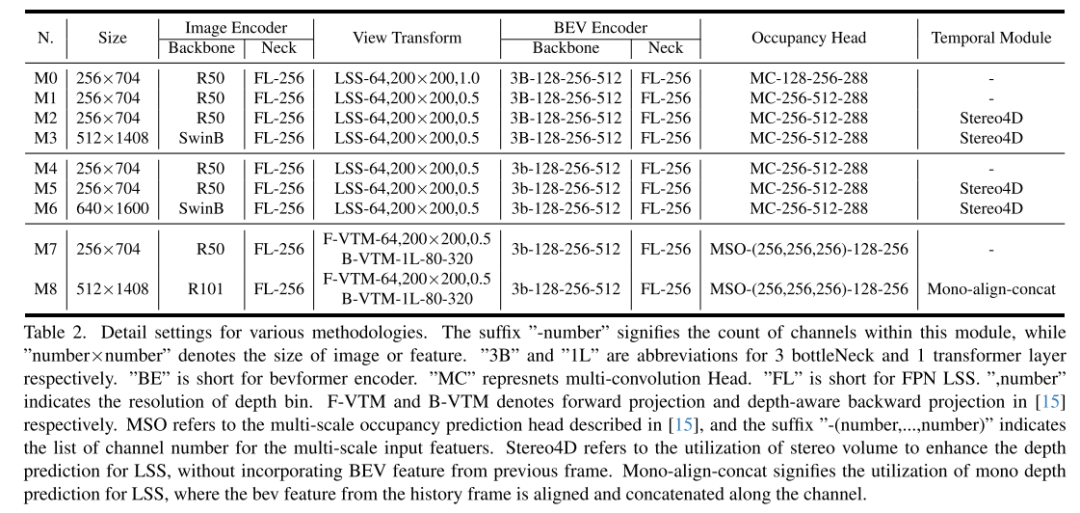
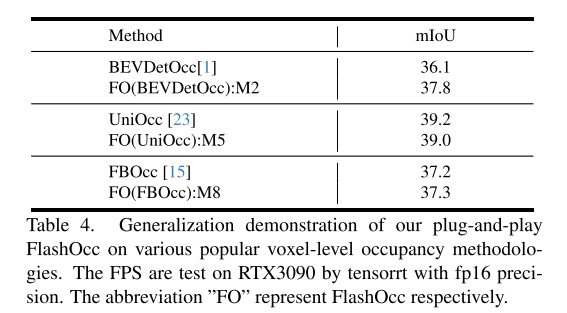
Inspirés par la technologie de convolution sous-pixel [26], nous remplaçons le suréchantillonnage d'image par un réarrangement de canal pour obtenir une conversion de fonctionnalités de canal en espace. Dans cette étude, nous visons à réaliser efficacement une conversion des caractéristiques canal en hauteur. Compte tenu du développement des tâches de perception BEV, dans lesquelles chaque pixel de la représentation BEV contient des informations sur l'objet en colonne correspondant dans la dimension hauteur, nous utilisons intuitivement la transformation canal-hauteur pour aplatir les caractéristiques BEV en logits d'occupation 3D au niveau du voxel. . Par conséquent, nos recherches se concentrent sur l’amélioration des modèles existants de manière générique et plug-and-play plutôt que sur le développement de nouvelles architectures de modèles, comme le montre la figure 1(a). Plus précisément, nous utilisons directement les convolutions 2D au lieu des convolutions 3D dans les méthodes contemporaines et remplaçons les logits d'occupation dérivés des sorties de convolution 3D par des transformations canal en hauteur des caractéristiques de niveau BEV obtenues grâce aux convolutions 2D. Ces modèles permettent non seulement d'obtenir le meilleur compromis entre précision et consommation de temps, mais démontrent également une excellente compatibilité de déploiement.
FlashOcc a réalisé avec succès une prévision d'occupation 3D en temps réel avec une précision extrêmement élevée, ce qui représente le meilleur dans ce domaine. Des contributions révolutionnaires. En outre, il démontre une polyvalence accrue pour le déploiement sur différentes plates-formes de véhicules, car il ne nécessite pas de traitement coûteux des caractéristiques au niveau du voxel, où les transformateurs de vue ou les opérateurs de convolution 3D (déformables) sont évités. Comme le montre la figure 2, les données d'entrée de FlashOcc sont constituées d'images surround, tandis que la sortie est constituée de résultats de prédiction d'occupation denses. Bien que FlashOcc de cet article se concentre sur l'amélioration des modèles existants de manière polyvalente et plug-and-play, il peut toujours être divisé en cinq modules de base : (1) Encodeur d'image 2D, chargé d'extraire les caractéristiques de l'image à partir d'images multi-caméras. (2) Un module de transformation de vue qui permet de mapper les caractéristiques de l'image de vue perceptuelle 2D aux représentations BEV 3D. (3) Encodeur BEV, responsable du traitement des informations sur les fonctionnalités BEV. (4) Occupez le module de prédiction pour prédire l'étiquette de segmentation de chaque voxel. (5) Un module de fusion temporelle optionnel conçu pour intégrer des informations historiques afin d'améliorer les performances.
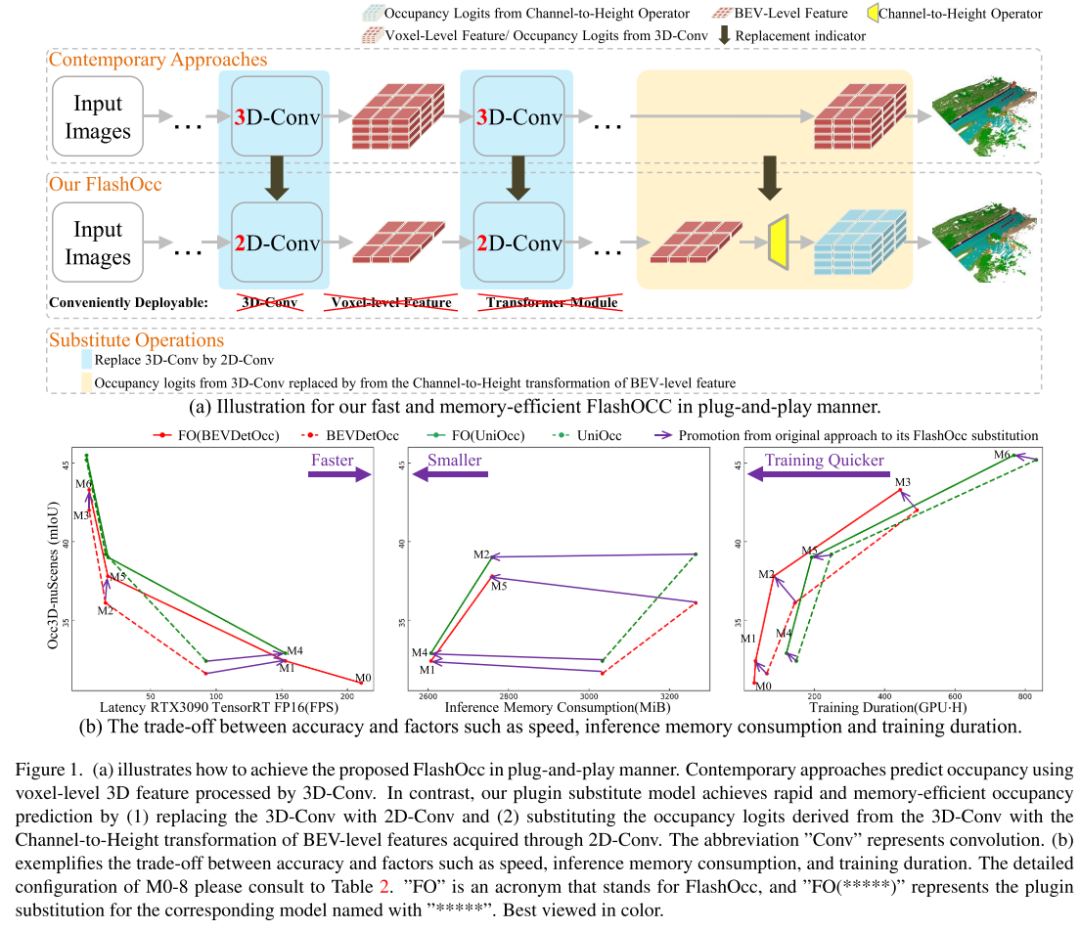
La figure 1.(a) illustre comment le FlashOcc proposé peut être implémenté de manière plug-and-play. Les méthodes modernes utilisent des fonctionnalités 3D au niveau voxel traitées par 3D-Conv pour prédire l'occupation. En revanche, notre modèle de remplacement de plug-in est implémenté en (1) remplaçant 3D-Conv par 2D-Conv et (2) remplaçant les logits d'occupation dérivés de 3D-Conv par une transformation canal-hauteur rapide et économe en mémoire. prédiction d'occupation des caractéristiques de niveau BEV obtenues via 2D-Conv. L'abréviation « Conv » signifie convolution. (b) illustre le compromis entre la précision et des facteurs tels que la vitesse, la consommation de mémoire d'inférence et la durée de l'entraînement.
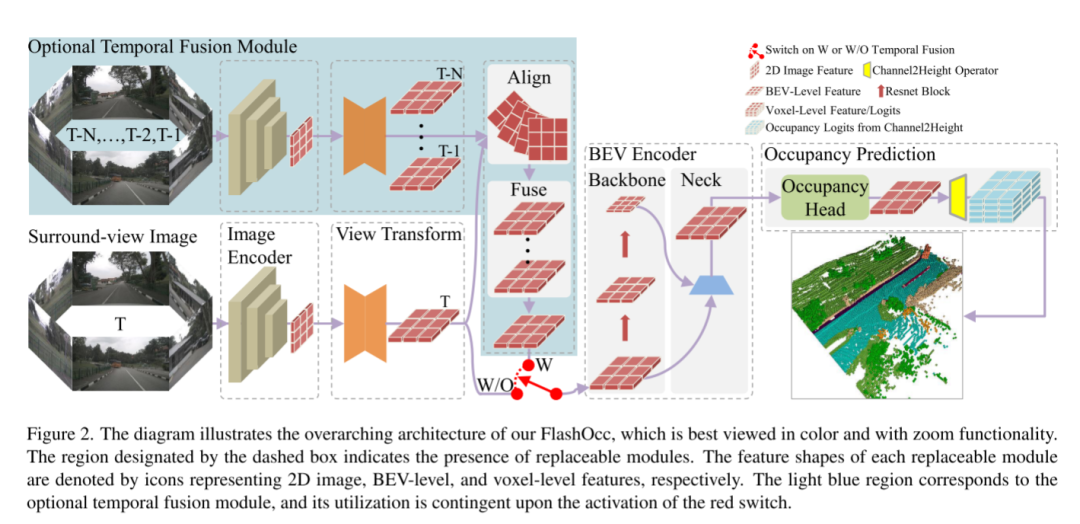
Figure 2. Cette figure illustre l'architecture globale de FlashOcc et est mieux visualisée en couleur avec la fonctionnalité de zoom. La zone désignée par la case en pointillés indique la présence de modules remplaçables. La forme des caractéristiques de chaque module remplaçable est représentée par des icônes représentant respectivement les caractéristiques de l'image 2D, du niveau BEV et du voxel. La zone bleu clair correspond au module optionnel de fusion temporelle dont l'utilisation dépend de l'activation de l'interrupteur rouge.
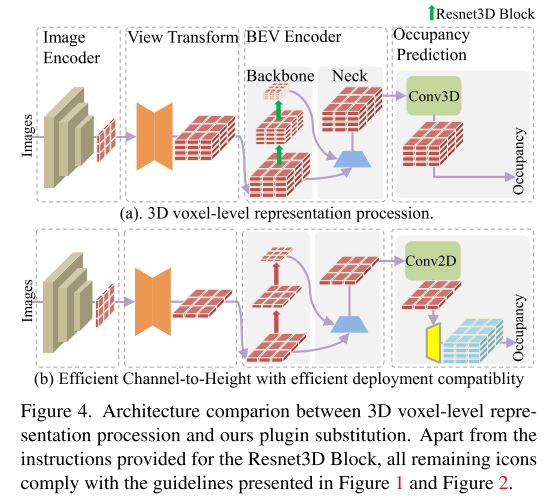
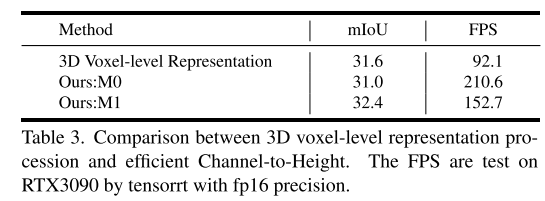
La figure 4 montre la comparaison architecturale entre le traitement de la représentation 3D au niveau des voxels et le remplacement du plug-in proposé dans cet article.
 Résumé :
Résumé : 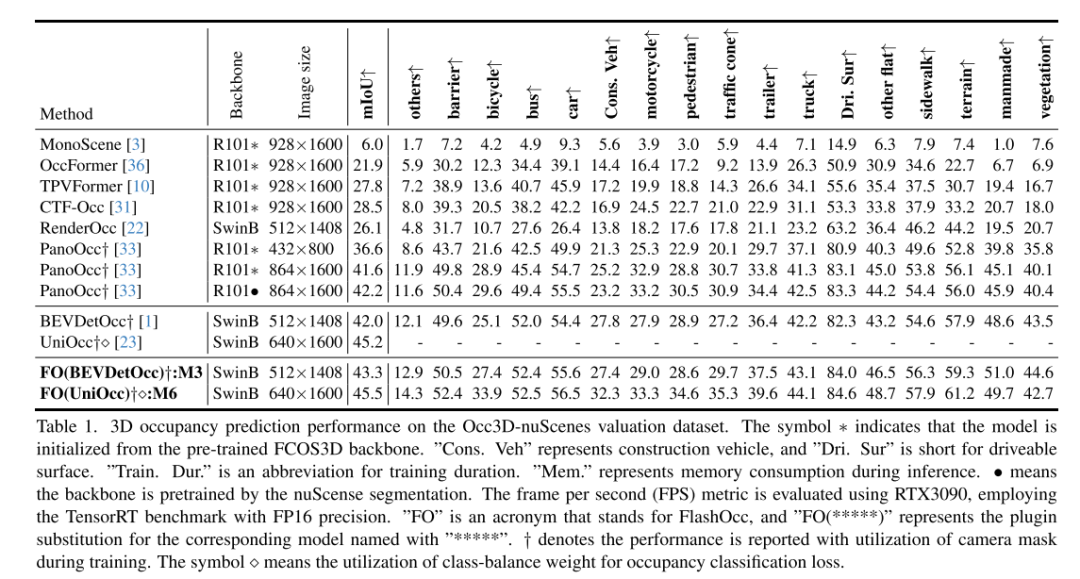
 Lien original : https://mp.weixin.qq.com/s/JDPlWj8FnZffJZc9PIsvXQ
Lien original : https://mp.weixin.qq.com/s/JDPlWj8FnZffJZc9PIsvXQ
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Three.js implémente le partage d'instances de carte 3D
- Comment quitter le mode PS3D
- Quel langage est utilisé pour développer unity3d ?
- Démontage physique du matériel Tesla Autopilot 4.0 : ajout d'un radar et fourniture de plus de caméras
- Combien de temps faudra-t-il pour parvenir à la conduite autonome ?