
Maison >Périphériques technologiques >IA >Apprentissage supervisé ou non supervisé : les experts définissent l'écart
Apprentissage supervisé ou non supervisé : les experts définissent l'écart

- 王林avant
- 2023-11-23 18:09:221025parcourir
Ce qui doit être réécrit, c'est : Comprendre les caractéristiques de l'apprentissage supervisé, de l'apprentissage non supervisé et de l'apprentissage semi-supervisé, et comment elles sont appliquées dans les projets d'apprentissage automatique.

Lorsque l'on parle de technologie d'intelligence artificielle, l'apprentissage supervisé est souvent est la méthode qui retient le plus l'attention car elle constitue souvent la dernière étape de la création d'un modèle d'IA et peut être utilisée pour des choses comme la reconnaissance d'images, de meilleures prédictions, des recommandations de produits et la notation des prospects.
En revanche, aucun apprentissage supervisé n'a tendance à travailler en coulisses au début du cycle de vie du développement de l'IA : il est souvent utilisé pour jeter les bases du déploiement de la magie de l'apprentissage supervisé, tout comme le gros travail qui permet aux managers de briller. Comme expliqué plus loin, les deux modèles d’apprentissage automatique peuvent être appliqués efficacement aux problèmes commerciaux.
Sur le plan technique, la différence entre l'apprentissage supervisé et non supervisé est de savoir si les données brutes utilisées pour créer l'algorithme sont pré-étiquetées (apprentissage supervisé) ou non (apprentissage non supervisé).
Commençons
Qu'est-ce que l'apprentissage supervisé ?
Dans l'apprentissage supervisé, les data scientists fournissent des données d'entraînement étiquetées à l'algorithme et définissent les variables dont ils souhaitent que l'algorithme évalue la pertinence.
Les données d'entrée et les variables de sortie de l'algorithme sont spécifiées via les données d'entraînement. Par exemple, si vous souhaitez utiliser l'apprentissage supervisé pour entraîner un algorithme afin de déterminer si une image contient un chat, vous pouvez créer une étiquette pour chaque image utilisée dans les données d'entraînement afin d'indiquer si l'image contient un chat
Comme nous expliquez dans notre définition de l'apprentissage supervisé : « [Un] algorithme informatique est formé sur des données d'entrée étiquetées pour une sortie spécifique. Le modèle est entraîné jusqu'à ce qu'il soit capable de détecter les données d'entrée et les étiquettes de sortie, les modèles fondamentaux et les relations entre eux, permettant ainsi. pour produire des résultats d'étiquetage précis lorsqu'ils sont présentés avec des données inédites. Les types courants d'algorithmes supervisés incluent la classification, les arbres de décision, la régression et la modélisation prédictive, que vous pouvez apprendre des machines d'Arcitura Education .
Les techniques d'apprentissage automatique supervisé sont utilisées dans diverses applications commerciales, notamment les suivantes :
- Marketing personnalisé
- Décisions de souscription d'assurance/crédit
- F. détection de bruit.
- Filtrage du spam
Qu'est-ce que l'apprentissage non supervisé ?
Il existe un algorithme pour cette méthode (par exemple, le clustering K-means), qui est entraîné sur des données non étiquetées. analyse l'ensemble de données à la recherche d'associations significatives. En d'autres termes, l'apprentissage non supervisé identifie des modèles de similarité dans les données au lieu de les relier à une mesure externe
Cette approche est utile lorsque vous ne savez pas ce que vous êtes. vous recherchez, mais pas si utile lorsque vous le faites. Vous montrez à un algorithme non supervisé des milliers ou des millions d'images, et il peut classer un sous-ensemble d'images comme celles que les humains reconnaissent comme félins, par rapport aux données étiquetées sur les chats et les chiens supervisés. Les algorithmes sur lesquels ils sont entraînés sont capables d'identifier des images de chats avec un degré élevé de confiance, mais cette approche s'accompagne d'un compromis : si un projet d'apprentissage supervisé nécessite des millions d'images étiquetées pour développer un modèle, les prédictions générées par la machine nécessitent beaucoup d'efforts. effort humain
Il existe un juste milieu : l'apprentissage semi-supervisé
Qu'est-ce que l'apprentissage semi-supervisé
L'apprentissage semi-supervisé est une méthode efficace qui combine l'apprentissage non supervisé et l'apprentissage supervisé à travers un certain. flux de travail. L'algorithme d'apprentissage non supervisé génère automatiquement des étiquettes, qui sont ensuite introduites dans l'algorithme d'apprentissage supervisé. Dans cette méthode, les humains étiquetent manuellement certaines images, tandis que l'algorithme d'apprentissage non supervisé devine les étiquettes d'autres images, et finalement toutes les étiquettes et images sont alimentées. en algorithmes d'apprentissage supervisé pour créer des modèles d'IA
L'un des avantages de l'apprentissage semi-supervisé est qu'il peut réduire le coût de l'utilisation d'ensembles de données à grande échelle dans l'apprentissage automatique, selon Aaron, co-fondateur et responsable de l'innovation. responsable de la plateforme de catalogue de données d'entreprise Alation. Selon Kalb, si les humains peuvent étiqueter 0,01 % de millions d'échantillons, les ordinateurs peuvent utiliser ces étiquettes pour améliorer considérablement la précision de leurs prédictions
.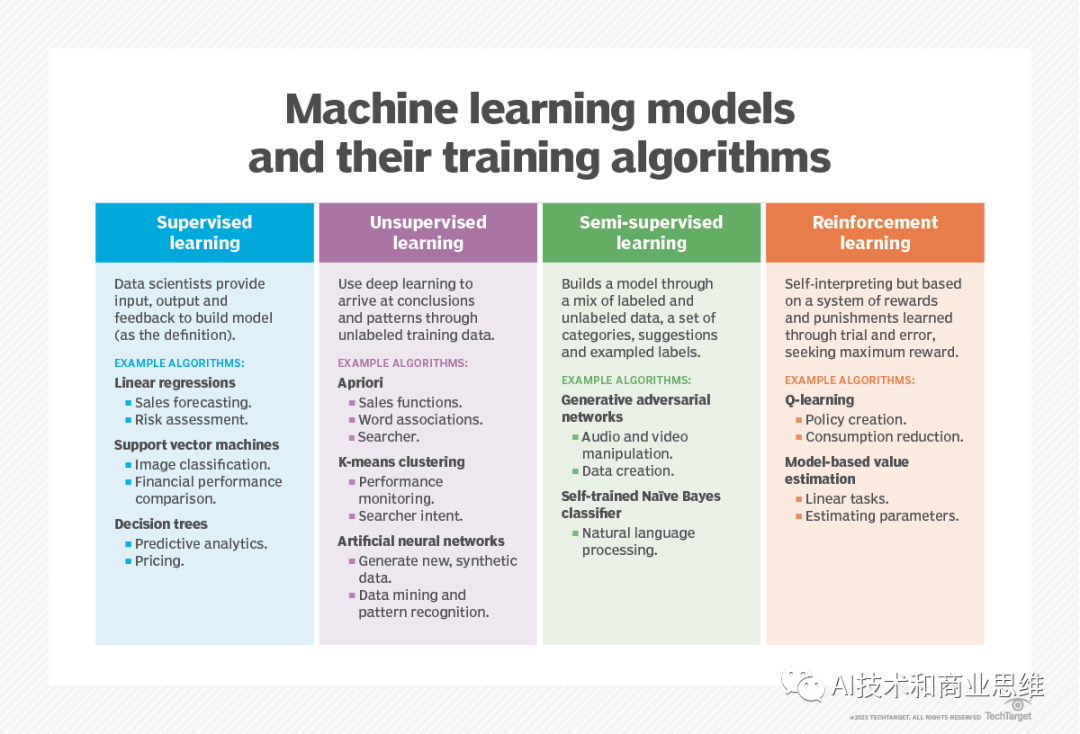
Qu'est-ce que l'apprentissage par renforcement ?
Une autre méthode d'apprentissage automatique est l'apprentissage par renforcement. L'apprentissage par renforcement est généralement utilisé pour apprendre à une machine à effectuer une séquence d'étapes et diffère de l'apprentissage supervisé et non supervisé. Les data scientists programment des algorithmes pour effectuer des tâches, donnant des indices ou des renforcements positifs ou négatifs lorsqu'ils déterminent comment accomplir les tâches. Le programmeur définit les règles de la récompense, mais laisse l'algorithme décider des étapes à suivre pour maximiser la récompense afin d'accomplir la tâche.
Quand devriez-vous utiliser l’apprentissage supervisé par rapport à l’apprentissage non supervisé ?
Shivani Rao, responsable de l'apprentissage automatique chez LinkedIn, a déclaré que les meilleures pratiques pour adopter des méthodes d'apprentissage automatique supervisées ou non supervisées dépendent souvent de l'environnement, des hypothèses que vous pouvez faire sur les données et l'application.
Rao a déclaré que le choix d'utiliser des algorithmes d'apprentissage automatique supervisés ou non supervisés changera également avec le temps. Dans les premières étapes du processus de création du modèle, les données sont souvent non étiquetées, alors que des données étiquetées peuvent émerger dans les étapes ultérieures de la modélisation.
Par exemple, pour le problème de prédire si les membres de LinkedIn regarderont les vidéos de cours, le premier modèle utilise des techniques non supervisées. Une fois ces suggestions fournies, une métrique qui enregistre si quelqu'un clique sur la suggestion fournira de nouvelles données pour générer des étiquettes
LinkedIn utilise également cette technique pour étiqueter les cours en ligne pour les compétences que les étudiants pourraient vouloir acquérir. Les marqueurs humains, tels que les auteurs, les éditeurs ou les étudiants, peuvent fournir une liste précise et précise des compétences enseignées dans un cours, mais il est peu probable qu'ils fournissent une liste exhaustive de ces compétences. Par conséquent, ces étiquettes de données peuvent être considérées comme incomplètes. Ces types de problèmes peuvent utiliser des techniques semi-supervisées pour aider à construire un ensemble d'étiquettes plus exhaustif.
Bharath Thota, expert en science des données et en analyse avancée et associé du cabinet de conseil Kearney, a déclaré que lorsque son équipe choisit d'utiliser l'apprentissage supervisé ou non supervisé, elle a également tendance à prendre en compte des facteurs pratiques.
Thota a déclaré : « Lorsque des données étiquetées sont disponibles, nous choisissons l'apprentissage supervisé comme application, dans le but de prédire ou de classer les observations futures. Lorsqu'il n'y a pas de données étiquetées disponibles, nous utilisons l'apprentissage non supervisé, dans le but de développer. stratégies en identifiant des modèles ou des extraits de données. Par exemple, ils ont développé un processus collaboratif homme-machine pour traduire des noms d'objets de données obscurs en langage humain, par exemple « na_gr_rvnu_ps » en « chiffre d'affaires total des services professionnels en Amérique du Nord ». Dans ce cas, la machine devine, les humains confirment, la machine apprend
"Vous pouvez le considérer comme un apprentissage semi-supervisé dans une boucle itérative, créant un cercle vertueux de précision améliorée", a déclaré Kalb.
5 Techniques d'apprentissage non supervisé
À un niveau élevé, les techniques d'apprentissage supervisé ont tendance à se concentrer sur la régression linéaire (ajuster un modèle à un ensemble de points de données pour faire des prédictions) ou sur des problèmes de classification (l'image a-t-elle un chat ?
Les techniques d'apprentissage non supervisé complètent souvent le travail d'apprentissage supervisé en découpant et en découpant des ensembles de données brutes de diverses manières, notamment :
Regroupement de données de points de données ayant des caractéristiques similaires regroupées pour aider à comprendre et à comprendre. explorez les données plus efficacement, par exemple, une entreprise peut utiliser des méthodes de regroupement de données pour segmenter les clients en groupes en fonction de leurs données démographiques, de leurs intérêts, de leur comportement d'achat et d'autres facteurs.
Chaque variable d'un ensemble de données est traitée comme une dimension distincte. Cependant, de nombreux modèles fonctionnent mieux en analysant des relations spécifiques entre les variables. Un exemple simple de réduction de dimensionnalité consiste à utiliser le profit comme une seule dimension, qui représente les revenus moins les dépenses. Toutefois, de nouveaux types de variables plus complexes peuvent être générés. des algorithmes tels que l'analyse des composantes principales, les auto-encodeurs, les algorithmes qui convertissent le texte en vecteurs ou l'intégration de quartiers stochastiques distribués en T.La réduction de dimensionnalité peut aider à réduire le problème du surajustement, où un modèle fonctionne bien sur de petits ensembles de données mais ne se généralise pas. bien aux nouvelles données. La technique permet également aux entreprises de visualiser en 2D ou en 3D des données de grande dimension que les humains peuvent facilement comprendre
Détection d'anomalies ou de valeurs aberrantes L'apprentissage non supervisé peut aider à identifier et à supprimer les anomalies en tant qu'étape de préparation des données. cela peut améliorer les modèles d'apprentissage automatique. Transférer l'apprentissage. Ces algorithmes exploitent des modèles formés sur des tâches connexes mais différentes. Par exemple, les techniques d'apprentissage par transfert permettent d'affiner facilement un classificateur formé sur les articles Wikipédia pour étiqueter tout type de nouveau texte avec les sujets corrects. Rao de LinkedIn affirme qu'il s'agit de l'un des moyens les plus efficaces et les plus rapides de résoudre le problème des données non étiquetées. Algorithme basé sur un graphique. Rao a déclaré que ces techniques tentent de créer un graphique qui capture la relation entre les points de données. Par exemple, si chaque point de données représente un membre LinkedIn possédant une compétence, vous pouvez représenter les membres à l'aide d'un graphique, où les bords représentent le chevauchement des compétences entre les membres. Les algorithmes graphiques peuvent également aider à transférer des étiquettes de points de données connus vers des points de données inconnus mais étroitement liés. L'apprentissage non supervisé peut également être utilisé pour construire des graphiques entre différents types d'entités (sources et cibles). Plus l’arête est forte, plus l’affinité du nœud source avec le nœud cible est élevée. Par exemple, LinkedIn les utilise pour proposer aux membres des cours basés sur les compétences.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Parmi les affirmations suivantes concernant l'intelligence artificielle, laquelle est incorrecte ?
- Quelles sont les nouveautés de l'intelligence artificielle ?
- Quelles sont les orientations de développement de l'intelligence artificielle ?
- Quelle est l'importance de l'intelligence artificielle
- Problème d'apprentissage en vedette dans l'apprentissage non supervisé