
Maison >Périphériques technologiques >IA >Discussion approfondie sur l'application de l'algorithme de perception de fusion multimodale dans la conduite autonome
Discussion approfondie sur l'application de l'algorithme de perception de fusion multimodale dans la conduite autonome

- 王林avant
- 2023-11-22 11:29:161047parcourir
Veuillez contacter la source pour obtenir l'autorisation de réimprimer cet article. Cet article a été publié par le compte public Autonomous Driving Heart
1 Introduction
La fusion de capteurs multimodaux signifie complément d'information, stabilité et sécurité, ce qui existe depuis longtemps. été la clé de l'automatique Une partie importante de la perception de conduite. Cependant, une utilisation insuffisante des informations, le bruit dans les données d'origine et le désalignement entre les différents capteurs (tels qu'une désynchronisation des horodatages) ont tous entraîné des performances de fusion limitées. Cet article examine de manière exhaustive les algorithmes de perception de conduite autonome multimodaux existants. Les capteurs incluent le LiDAR et les caméras, en se concentrant sur la détection de cibles et la segmentation sémantique, et analyse plus de 50 documents. Différent de la méthode de classification traditionnelle des algorithmes de fusion, cet article classe ce domaine en deux grandes catégories et quatre sous-catégories en fonction des différentes étapes de fusion. De plus, cet article analyse les problèmes existants dans le domaine actuel et fournit une référence pour les orientations de recherche futures.
2 Pourquoi la multimodalité est-elle nécessaire ?
C'est parce que l'algorithme de perception monomodale présente des défauts inhérents. Par exemple, le lidar est généralement installé plus haut que la caméra. Dans des scénarios de conduite complexes et réels, des objets peuvent être bloqués dans la caméra frontale. Dans ce cas, il est possible d'utiliser le lidar pour capturer la cible manquante. Cependant, en raison des limites de la structure mécanique, le LiDAR a des résolutions différentes à différentes distances et est facilement affecté par des conditions météorologiques extrêmement extrêmes, telles que de fortes pluies. Bien que les deux capteurs puissent très bien fonctionner lorsqu'ils sont utilisés seuls, dans une perspective future, les informations complémentaires du LiDAR et des caméras rendront la conduite autonome plus sûre au niveau de la perception.
Récemment, les algorithmes de perception multimodale de conduite autonome ont fait de grands progrès. Ces avancées incluent une représentation intermodale des caractéristiques, des capteurs modaux plus fiables et des algorithmes et techniques de fusion multimodaux plus complexes et plus stables. Cependant, seules quelques revues [15, 81] se concentrent sur la méthodologie elle-même de la fusion multimodale, et la plupart de la littérature est classée selon les règles de classification traditionnelles, à savoir la pré-fusion, la fusion profonde (caractéristique) et la post-fusion, et principalement se concentre sur L'étape de fusion des fonctionnalités dans l'algorithme, qu'il s'agisse du niveau des données, du niveau des fonctionnalités ou du niveau de la proposition. Cette règle de classification pose deux problèmes : premièrement, la représentation des caractéristiques de chaque niveau n'est pas clairement définie ; deuxièmement, elle traite les deux branches du lidar et de la caméra dans une perspective symétrique, brouillant ainsi la relation entre la fusion de caractéristiques et la fusion de caractéristiques dans le Branche LiDAR. Le cas de la fusion de fonctionnalités au niveau des données dans la branche caméra. En résumé, bien que la méthode de classification traditionnelle soit intuitive, elle n'est plus adaptée au développement des algorithmes de fusion multimodaux actuels, ce qui empêche dans une certaine mesure les chercheurs de mener des recherches et des analyses dans une perspective système
3 tâches et publics compétitions
Les tâches de perception courantes incluent la détection de cibles, la segmentation sémantique, l'achèvement et la prédiction en profondeur, etc. Cet article se concentre sur la détection et la segmentation, telles que la détection d'obstacles, de feux de circulation, de panneaux de signalisation et la segmentation des lignes de voie et des espaces libres. La tâche de perception de la conduite autonome est illustrée dans la figure suivante :
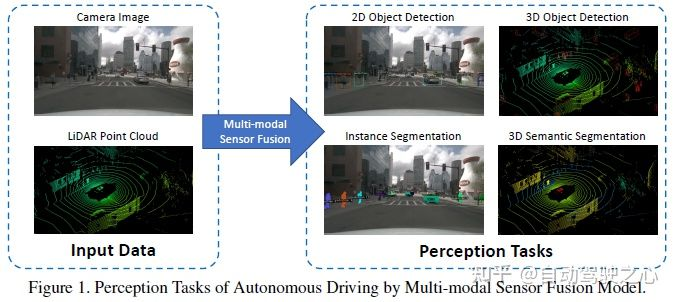
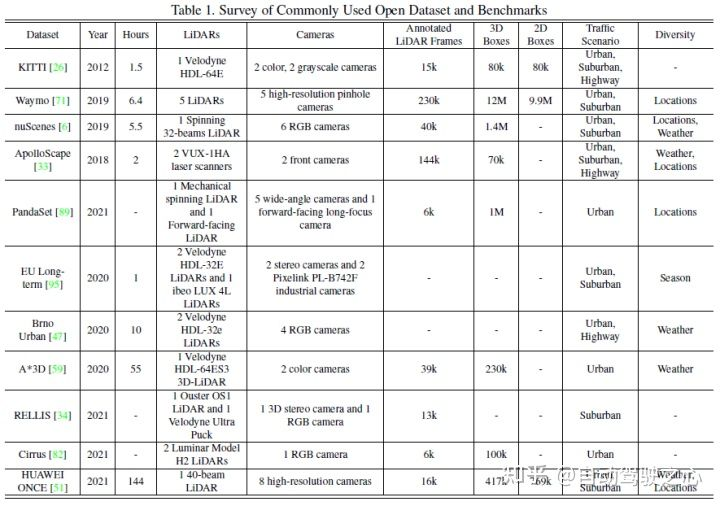
Les ensembles de données publiques courants incluent principalement KITTI, Waymo et nuScenes. La figure suivante résume les ensembles de données liés à la perception de la conduite autonome et leurs caractéristiques
4. Méthode de fusion
La fusion multimodale est indissociable de la forme d'expression des données. La représentation des données de la branche image est relativement simple, faisant généralement référence au format RVB ou à l'image en niveaux de gris. Cependant, la branche lidar dépend fortement des formats de données, et. différents formats de données sont dérivés. Une conception de modèle en aval complètement différente est proposée, qui comprend en résumé trois directions générales : représentation de nuages de points basée sur des points, cartographie basée sur des voxels et bidimensionnelle.
Les méthodes de classification traditionnelles divisent la fusion multimodale en trois types suivants :
- La pré-fusion (fusion au niveau des données) fait référence à la fusion directe de données brutes de capteurs de différentes modalités via l'alignement spatial.
- La fusion profonde (fusion au niveau des fonctionnalités) fait référence à la fusion de données intermodales dans l'espace des fonctionnalités par cascade ou multiplication d'éléments.
- La post-fusion (fusion au niveau cible) fait référence à la fusion des résultats de prédiction de chaque modèle modal pour prendre la décision finale.
L'article utilise la méthode de classification de la figure ci-dessous, qui est généralement divisée en fusion forte et fusion faible. La fusion forte peut être subdivisée en fusion frontale, fusion profonde, fusion asymétrique et post-fusion
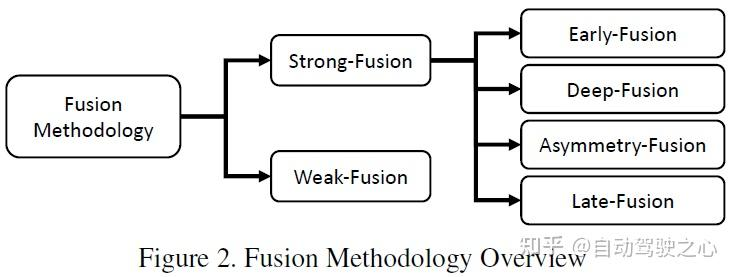
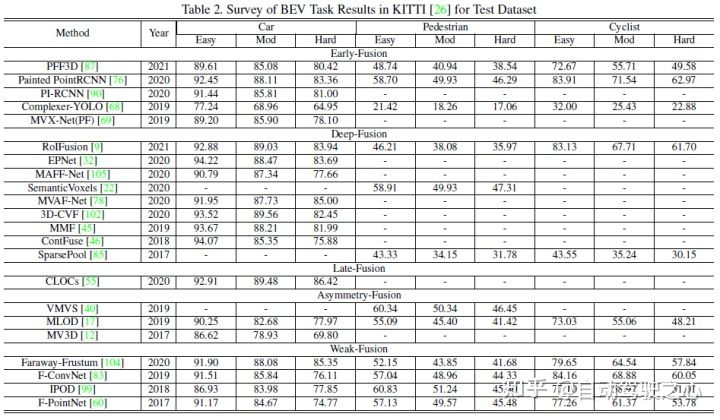
Cet article. utilise la détection 3D de KITTI Les performances de chaque algorithme de fusion multimodale sont comparées horizontalement avec la tâche de détection BEV. L'image suivante est le résultat de l'ensemble de tests de détection BEV :
Ce qui suit est un exemple du résultat de la. Coffret de test de détection 3D :
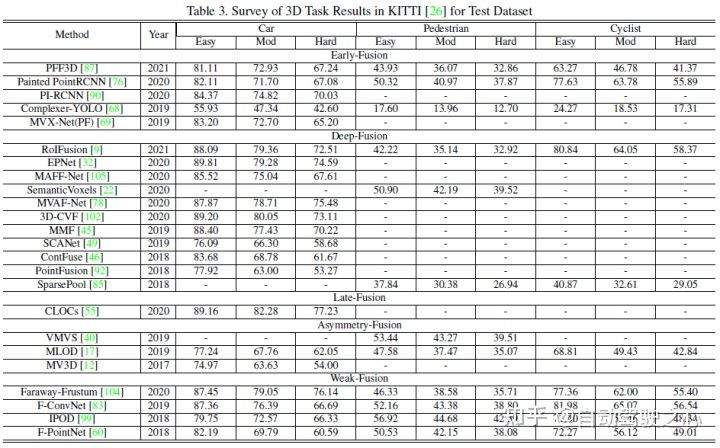
5 Fusion forte
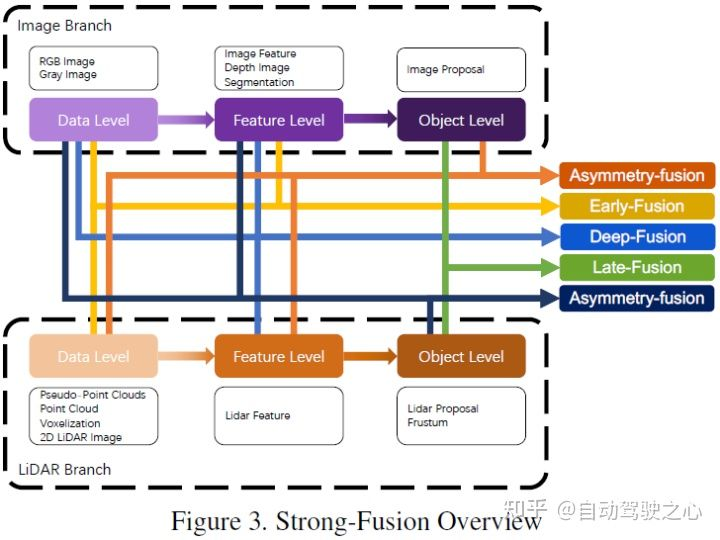
Selon les différentes étapes de combinaison représentées par les données lidar et caméra, cet article subdivise la fusion forte en : fusion frontale, fusion profonde, fusion asymétrique et post-fusion. Comme le montre la figure ci-dessus, on peut voir que chaque sous-module de fusion forte dépend fortement du nuage de points lidar plutôt que des données de la caméra.
Pré-fusion
Différente de la définition traditionnelle de fusion au niveau des données, qui est une méthode permettant de fusionner directement les données de chaque modalité via l'alignement spatial et la projection au niveau des données brutes, la fusion précoce fusionne les données LiDAR et les données LiDAR au niveau des données brutes. niveau de données Niveau de données données de la caméra ou niveau de fonctionnalité. Un exemple de fusion précoce pourrait être le modèle de la figure 4. Contenu réécrit : Différent de la définition traditionnelle de fusion au niveau des données, qui est une méthode permettant de fusionner directement les données de chaque modalité via l'alignement spatial et la projection au niveau des données d'origine. La fusion précoce fait référence à la fusion des données LiDAR et des données de caméra ou des données au niveau des fonctionnalités au niveau des données. Le modèle de la figure 4 est un exemple de fusion précoce
Différent de la pré-fusion définie par les méthodes de classification traditionnelles, la pré-fusion définie dans cet article fait référence à la méthode de fusion directe de chaque donnée modale par alignement spatial et projection au niveau du Niveau des données d'origine. Au niveau des données, il s'agit de la fusion des données lidar, et au niveau des données ou des fonctionnalités, les données d'image sont fusionnées :
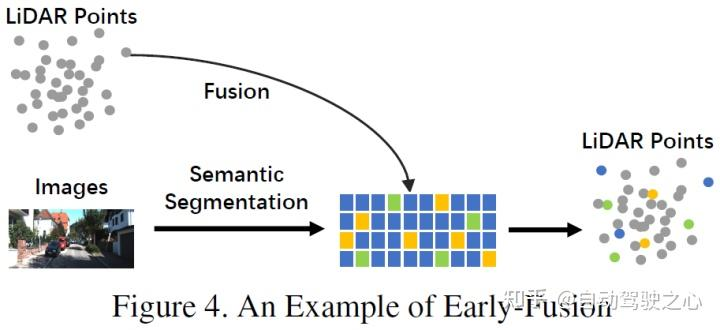
Dans le LiDAR. branche, les nuages de points ont de nombreuses méthodes d'expression, telles que les cartes de réflexion et les images voxélisées, la vue de face/vue de distance/vue BEV et le pseudo nuage de points, etc. Bien que ces données aient des caractéristiques intrinsèques différentes selon les différents réseaux fédérateurs, à l’exception des pseudo-nuages de points [79], la plupart des données sont générées via certains traitements de règles. De plus, par rapport à l'intégration de l'espace de fonctionnalités, ces données LiDAR sont hautement interprétables et peuvent être directement visualisées dans la branche image, la définition au niveau des données au sens strict fait référence aux images RVB ou en niveaux de gris, mais cette définition manque d'universalité et de rationalité. Par conséquent, cet article étend la définition des données d’image au niveau des données dans l’étape de pré-fusion pour inclure les données au niveau des données et des fonctionnalités. Il convient de mentionner que cet article considère également les résultats de prédiction de la segmentation sémantique comme un type de pré-fusion (au niveau des caractéristiques de l'image), d'une part, ils sont utiles pour la détection de cibles 3D, et d'autre part, ils le sont parce que. du « niveau cible » de la segmentation sémantique. Les fonctionnalités sont différentes de la proposition finale au niveau cible de l'ensemble de la tâche
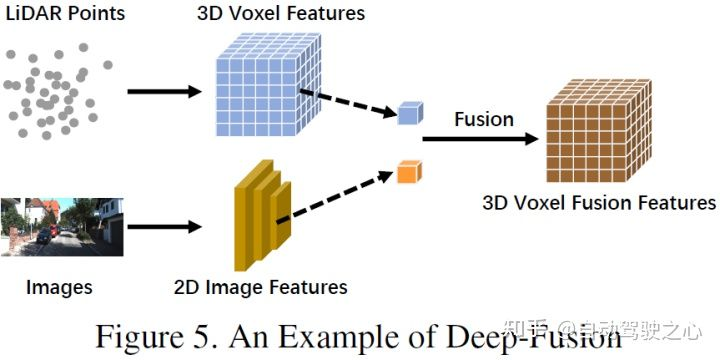
Fusion profondeLa fusion profonde, également appelée fusion au niveau des fonctionnalités, fait référence à la fusion multimodale. données au niveau des fonctionnalités de la branche lidar, mais pas les données de la fusion de la branche d'image aux niveaux de l'ensemble et des fonctionnalités. Par exemple, certaines méthodes utilisent le levage de caractéristiques pour obtenir des représentations intégrées de nuages de points et d'images LiDAR respectivement, et fusionnent les caractéristiques des deux modalités via une série de modules en aval. Cependant, contrairement à d’autres fusions fortes, la fusion profonde fusionne parfois des fonctionnalités en cascade, les deux exploitant des informations sémantiques brutes et de haut niveau. Le diagramme schématique est le suivant :
La post-fusion, qui peut également être appelée fusion au niveau cible, fait référence à la fusion de résultats de prédiction (ou de propositions) de plusieurs modalités. Par exemple, certaines méthodes de post-fusion utilisent la sortie de nuages de points et d’images LiDAR pour la fusion [55]. Le format des données proposées pour les deux branches doit être cohérent avec les résultats finaux, mais il peut y avoir des différences en termes de qualité, de quantité et d'exactitude. La post-fusion peut être considérée comme une méthode d'intégration pour l'optimisation des informations multimodales de la proposition finale. Le diagramme schématique est le suivant :
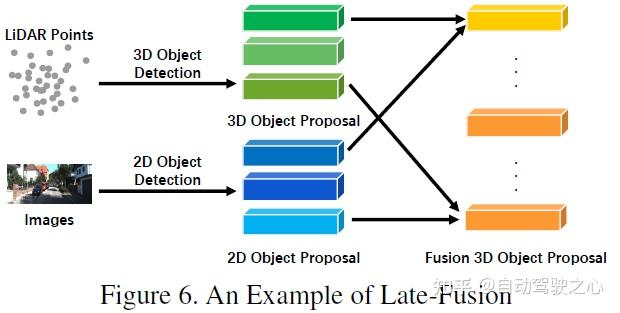
Le dernier type de fusion forte est la fusion asymétrique, qui fait référence à Il s'agit de fusionner les informations au niveau cible d'une branche avec les informations au niveau des données ou des fonctionnalités d'autres branches. Les trois méthodes de fusion ci-dessus traitent chaque branche de la multimodalité de la même manière, tandis que la fusion asymétrique souligne qu'au moins une branche est dominante et que les autres branches fournissent des informations auxiliaires pour prédire le résultat final. La figure ci-dessous est un diagramme schématique de la fusion asymétrique. Au stade de la proposition, la fusion asymétrique n'a que la proposition d'une branche, puis la fusion est la proposition de toutes les branches.
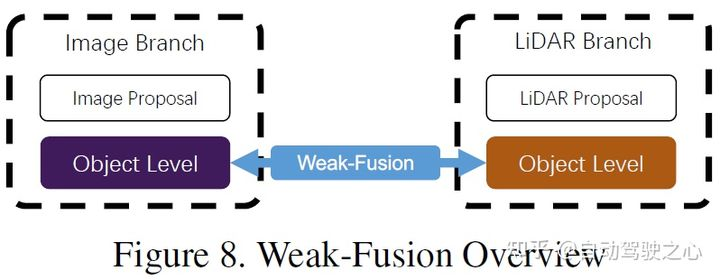
6 La différence entre la fusion faible
et la fusion forte est que la méthode de fusion faible ne fusionne pas directement les données, les caractéristiques ou les cibles des branches multimodales, mais traite les données sous d'autres formes. La figure ci-dessous montre le cadre de base de l'algorithme de fusion faible. Les méthodes basées sur une fusion faible utilisent généralement certaines méthodes basées sur des règles pour utiliser les données d'une modalité comme signal de supervision pour guider l'interaction d'une autre modalité. Par exemple, la proposition 2D de CNN dans la branche image peut provoquer une troncature dans le nuage de points LiDAR d'origine, et une fusion faible entre directement le nuage de points LiDAR d'origine dans le squelette LiDAR pour produire la proposition finale.
7 Autres méthodes de fusion
Il existe également certains travaux qui n'appartiennent à aucun des paradigmes ci-dessus car ils utilisent plusieurs méthodes de fusion dans le cadre de la conception de modèles, comme [39] qui combine des méthodes profondes fusion et post-traitement Fusion,[77] combine la pré-fusion. Ces méthodes ne sont pas les méthodes traditionnelles de conception d’algorithmes de fusion et sont classées dans d’autres méthodes de fusion dans cet article.
8 Opportunités de fusion multimodale
Ces dernières années, les méthodes de fusion multimodale pour les tâches de perception de la conduite autonome ont fait des progrès rapides, depuis des représentations de fonctionnalités plus avancées jusqu'à des modèles d'apprentissage en profondeur plus complexes. Cependant, il reste encore quelques problèmes en suspens qui doivent être résolus. Cet article résume plusieurs pistes d'amélioration futures possibles comme suit.
Méthodes de fusion plus avancées
Les modèles de fusion actuels souffrent de problèmes de désalignement et de perte d'informations [13, 67, 98]. De plus, les opérations de fusion à plat entravent également l’amélioration des performances des tâches de perception. Le résumé est le suivant :
- Dislocation et perte d'informations : Les différences internes et externes entre les caméras et le LiDAR sont très importantes et les données des deux modes doivent être alignées. Les méthodes traditionnelles de fusion frontale et de fusion en profondeur utilisent les informations d'étalonnage pour projeter tous les points LiDAR directement dans le système de coordonnées de la caméra et vice versa. Cependant, en raison de l'emplacement d'installation et du bruit du capteur, cet alignement pixel par pixel n'est pas assez précis. Par conséquent, certains travaux utilisent les informations environnantes pour les compléter afin d’obtenir de meilleures performances. De plus, d'autres informations sont perdues lors du processus de conversion des espaces d'entrée et de fonctionnalités. Habituellement, la projection d'opérations de réduction de dimensionnalité entraîne inévitablement une grande perte d'informations, comme la perte d'informations sur la hauteur lors de la cartographie des nuages de points LiDAR 3D sur des images BEV 2D. Par conséquent, vous pouvez envisager de mapper des données multimodales vers un autre espace de grande dimension conçu pour la fusion, afin d'utiliser efficacement les données d'origine et de réduire la perte d'informations.
- Opérations de fusion plus raisonnables : de nombreuses méthodes actuelles utilisent la multiplication en cascade ou en éléments pour la fusion. Ces opérations simples peuvent ne pas réussir à fusionner des données avec des distributions très différentes, ce qui rend difficile l'ajustement des chiens rouges sémantiques entre les deux modalités. Certains travaux tentent d'utiliser des structures en cascade plus complexes pour fusionner les données et améliorer les performances. Dans les recherches futures, des mécanismes tels que la cartographie bilinéaire peuvent intégrer des entités présentant des caractéristiques différentes et constituent également des orientations pouvant être envisagées.
Utilisation d'informations multi-sources
L'image prospective à image unique est un scénario typique pour les tâches de perception de la conduite autonome. Cependant, la plupart des cadres ne peuvent utiliser que des informations limitées et ne conçoivent pas de tâches auxiliaires en détail pour faciliter la compréhension des scénarios de conduite. Le résumé est le suivant :
- Utilisez davantage d'informations potentielles : les méthodes existantes ne permettent pas une utilisation efficace des informations provenant de multiples dimensions et sources. La plupart se concentrent sur les données multimodales à image unique dans la vue de face. Il en résulte que d’autres données significatives sont sous-utilisées, telles que les informations sémantiques, spatiales et contextuelles de la scène. Certains travaux tentent d'utiliser les résultats de la segmentation sémantique pour faciliter la tâche, tandis que d'autres modèles exploitent potentiellement les fonctionnalités des couches intermédiaires du squelette CNN. Dans les scénarios de conduite autonome, de nombreuses tâches en aval comportant des informations sémantiques explicites peuvent améliorer considérablement les performances de détection d'objets, telles que la détection des lignes de voie, des feux de circulation et des panneaux de signalisation. Les recherches futures pourront combiner des tâches en aval pour construire conjointement un cadre complet de compréhension sémantique des scènes urbaines afin d'améliorer les performances de perception. De plus, [63] intègre des informations inter-trames pour améliorer les performances. Les informations sur les séries chronologiques contiennent des signaux de surveillance sérialisés, qui peuvent fournir des résultats plus stables par rapport aux méthodes à image unique. Par conséquent, les travaux futurs pourraient envisager d’exploiter plus en profondeur les informations temporelles, contextuelles et spatiales pour réaliser des avancées en matière de performances.
- Apprentissage des représentations auto-supervisé : des signaux mutuellement supervisés existent naturellement dans les données multimodales échantillonnées à partir de la même scène du monde réel mais sous des angles différents. Cependant, en raison du manque de compréhension approfondie des données, les méthodes actuelles ne peuvent pas exploiter les interrelations entre les différentes modalités. Les recherches futures pourraient se concentrer sur la manière d’utiliser les données multimodales pour l’apprentissage auto-supervisé, y compris la pré-formation, le réglage fin ou l’apprentissage contrastif. Grâce à ces mécanismes de pointe, les algorithmes de fusion approfondiront la compréhension plus approfondie des données par le modèle tout en obtenant de meilleures performances.
Problèmes inhérents aux capteurs
Les scènes du monde réel et la hauteur du capteur peuvent affecter le biais et la résolution du domaine. Ces lacunes entraveront la formation à grande échelle et le fonctionnement en temps réel des modèles d'apprentissage profond de conduite autonome
- Biais de domaine : dans les scénarios de perception de conduite autonome, les données brutes extraites par différents capteurs sont accompagnées de fonctionnalités sévères liées au domaine. Différentes caméras ont des propriétés optiques différentes, et le LiDAR peut varier des structures mécaniques aux structures à semi-conducteurs. De plus, les données elles-mêmes présenteront des biais de domaine, tels que la météo, la saison ou l'emplacement géographique, même si elles ont été capturées par le même capteur. Cela affecte la généralisation du modèle de détection et ne peut pas s'adapter efficacement aux nouveaux scénarios. De telles failles entravent la collecte d'ensembles de données à grande échelle et la réutilisation des données de formation originales. Par conséquent, l’avenir peut se concentrer sur la recherche d’une méthode permettant d’éliminer les biais de domaine et d’intégrer de manière adaptative différentes sources de données.
- Conflit de résolution : différents capteurs ont généralement des résolutions différentes. Par exemple, la densité spatiale du LiDAR est nettement inférieure à celle des images. Quelle que soit la méthode de projection utilisée, une perte d'informations se produira car la relation correspondante ne peut pas être trouvée. Cela peut conduire à ce que le modèle soit dominé par des données d'une modalité spécifique, que ce soit en raison de résolutions différentes des vecteurs de caractéristiques ou d'un déséquilibre dans les informations brutes. Par conséquent, les travaux futurs pourraient explorer un nouveau système de représentation des données compatible avec des capteurs de différentes résolutions spatiales.
9 Référence
[1] https://zhuanlan.zhihu.com/p/470588787
[2] Fusion de capteurs multimodaux pour la perception de la conduite automobile : une enquête

Lien original : https https://mp.weixin.qq.com/s/usAQRL18vww9YwMXRvEwLw
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment implémenter un algorithme de tri par sélection en langage C (exemple de code)
- Qu'est-ce qu'un algorithme bien connu pour éviter les impasses ?
- Méthode d'adaptation de domaine virtuel-réel pour la détection et la classification de voies de conduite autonomes
- Résumé des ressources d'ensembles de données open source pour la conduite autonome
- Façons de corriger l'erreur de réinitialisation du pilote automatique Windows 0x80070032