
Maison >Périphériques technologiques >IA >Le modèle 13B a-t-il l'avantage dans une confrontation complète avec GPT-4 ? Y a-t-il des circonstances inhabituelles derrière cela ?
Le modèle 13B a-t-il l'avantage dans une confrontation complète avec GPT-4 ? Y a-t-il des circonstances inhabituelles derrière cela ?

- PHPzavant
- 2023-11-18 11:39:051334parcourir
Un modèle avec des paramètres 13B peut réellement battre le top GPT-4 ? Comme le montre la figure ci-dessous, afin de garantir la validité des résultats, ce test a également suivi la méthode de débruitage des données d'OpenAI, et aucune preuve de contamination des données n'a été trouvée
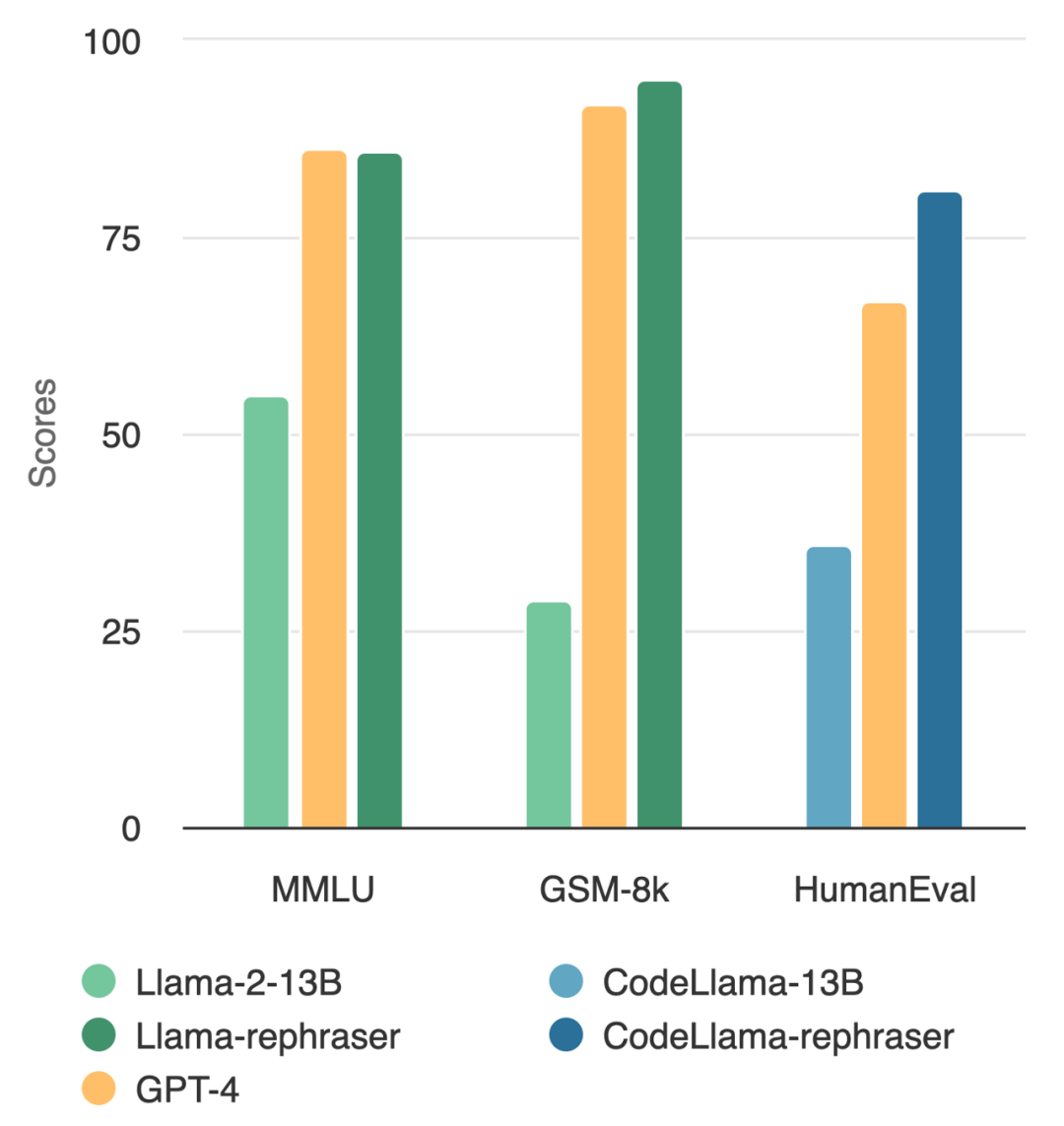
En observant le modèle dans la figure, vous J'ai trouvé que tant que le mot « reformuler » est inclus, les performances du modèle sont relativement élevées
Quelle est l'astuce derrière cela ? Il s'avère que les données sont contaminées, c'est-à-dire que les informations de l'ensemble de test sont divulguées dans l'ensemble de formation, et cette contamination n'est pas facile à détecter. Malgré l’importance cruciale de cette question, comprendre et détecter la contamination reste un casse-tête ouvert et difficile.
À ce stade, la méthode de décontamination la plus couramment utilisée est le chevauchement de n-grammes et la recherche de similarité intégrée : le chevauchement de n-grammes repose sur la correspondance de chaînes pour détecter la contamination et est couramment utilisé dans des modèles tels que GPT-4, PaLM. et méthode Llama-2 ; la recherche de similarité par intégration utilise des intégrations à partir d'un modèle pré-entraîné (par exemple, BERT) pour trouver des exemples similaires et potentiellement contaminés.
Cependant, des recherches de l'UC Berkeley et de l'Université Jiao Tong de Shanghai montrent que de simples modifications des données de test (par exemple, réécriture, traduction) peuvent facilement contourner les méthodes de détection existantes. Ils font référence à ces variations de cas de test sous le nom d'« échantillons reformulés ».
Voici ce qui doit être réécrit dans le test de référence MMLU : les résultats de démonstration de l'échantillon réécrit. Les résultats montrent que le modèle 13B peut atteindre des performances très élevées (MMLU 85.9) si l'ensemble d'apprentissage contient de tels échantillons. Malheureusement, les méthodes de détection existantes telles que le chevauchement des n-grammes et l’intégration de la similarité ne peuvent pas détecter cette contamination. Par exemple, les méthodes de similarité intégrées ont du mal à distinguer les problèmes de reformulation des autres problèmes dans le même sujet

Avec des techniques de reformulation similaires, cet article observe des résultats cohérents sur des benchmarks de codage et de mathématiques largement utilisés, tels que HumanEval et GSM-8K. (montré sur l'image au début de l'article). Par conséquent, être capable de détecter un tel contenu qui doit être réécrit : des échantillons réécrits devient crucial.
Voyons ensuite comment cette étude a été menée.

- Adresse papier : https://arxiv.org/pdf/2311.04850.pdf
- Adresse du projet : https://github.com/lm-sys/llm -decontaminator#detect
Paper introduction
Avec le développement rapide des grands modèles (LLM), les gens accordent de plus en plus d'attention au problème de la pollution des ensembles de test. De nombreuses personnes ont exprimé des inquiétudes quant à la crédibilité des références publiques
Pour résoudre ce problème, certaines personnes utilisent des méthodes de décontamination traditionnelles, telles que la correspondance de chaînes (telles que le chevauchement n-grammes), pour supprimer les données de référence. Cependant, ces opérations sont loin d'être suffisantes, car ces mesures de nettoyage peuvent être facilement contournées en apportant simplement quelques modifications simples aux données de test (par exemple, réécriture, traduction)
Si ces modifications des données de test ne sont pas éliminées, 13B Ce qui est plus important, c'est que le modèle dépasse facilement le test de référence et atteint des performances comparables à celles de GPT-4. Les chercheurs ont vérifié ces observations dans des tests de référence tels que MMLU, GSK8k et HumanEval
Dans le même temps, afin de faire face à ces risques croissants, cet article propose également une méthode de décontamination plus puissante basée sur LLM, le décontaminateur LLM, et son application. aux ensembles de données populaires de pré-formation et de réglage fin, les résultats montrent que la méthode LLM proposée dans cet article est nettement meilleure que les méthodes existantes pour supprimer les échantillons réécrits.
Cette approche a également révélé un chevauchement de tests jusqu'alors inconnu. Par exemple, dans les ensembles de pré-formation tels que RedPajamaData-1T et StarCoder-Data, nous trouvons un chevauchement de 8 à 18 % avec le benchmark HumanEval. De plus, cet article a également constaté cette contamination dans l’ensemble de données synthétiques généré par GPT-3.5/4, ce qui illustre également le risque potentiel de contamination accidentelle dans le domaine de l’IA.
Nous espérons qu'à travers cet article, nous appellerons la communauté à adopter une méthode de purification plus puissante lors de l'utilisation de benchmarks publics et à développer activement de nouveaux cas de tests ponctuels pour évaluer avec précision le modèle
Ce qui doit être réécrit est : réécrire l'échantillon
L'objectif de cet article est de déterminer si un simple changement dans l'inclusion de l'ensemble de test dans l'ensemble de formation affectera les performances de référence finales, et appelle ce changement dans le scénario de test "ce qui doit être réécrit est : réécrire l'échantillon". Divers domaines du référentiel, notamment les mathématiques, les connaissances et le codage, ont été pris en compte dans les expériences. L'exemple 1 est le contenu du GSM-8k qui doit être réécrit : un échantillon réécrit dans lequel un chevauchement de 10 grammes ne peut pas être détecté et le texte modifié conserve la même sémantique que le texte original.

Il existe de légères différences dans la technologie de réécriture pour différentes formes de contamination de base. Dans le test de référence basé sur du texte, cet article réécrit les cas de test en réorganisant l'ordre des mots ou en utilisant la substitution de synonymes pour atteindre l'objectif de ne pas changer la sémantique. Dans le test de référence basé sur le code, cet article est réécrit en modifiant le style de codage, la méthode de dénomination, etc. Comme indiqué ci-dessous, un algorithme simple est proposé dans l'algorithme 1 pour l'ensemble de test donné. Cette méthode peut aider les échantillons testés à échapper à la détection.
 Ensuite, cet article propose une nouvelle méthode de détection de contamination qui peut supprimer avec précision le contenu qui doit être réécrit de l'ensemble de données par rapport à la ligne de base : les échantillons réécrits.
Ensuite, cet article propose une nouvelle méthode de détection de contamination qui peut supprimer avec précision le contenu qui doit être réécrit de l'ensemble de données par rapport à la ligne de base : les échantillons réécrits.
Plus précisément, cet article présente le décontaminateur LLM. Premièrement, pour chaque cas de test, il utilise une recherche de similarité intégrée pour identifier les k éléments de formation présentant la similarité la plus élevée, après quoi chaque paire est évaluée par un LLM (par exemple, GPT-4) pour savoir si elles sont identiques. Cette approche permet de déterminer la quantité de l'ensemble de données qui doit être réécrite : l'échantillon de réécriture.
Le diagramme de Venn des différentes contaminations et des différentes méthodes de détection est présenté dans la figure 4
Expérience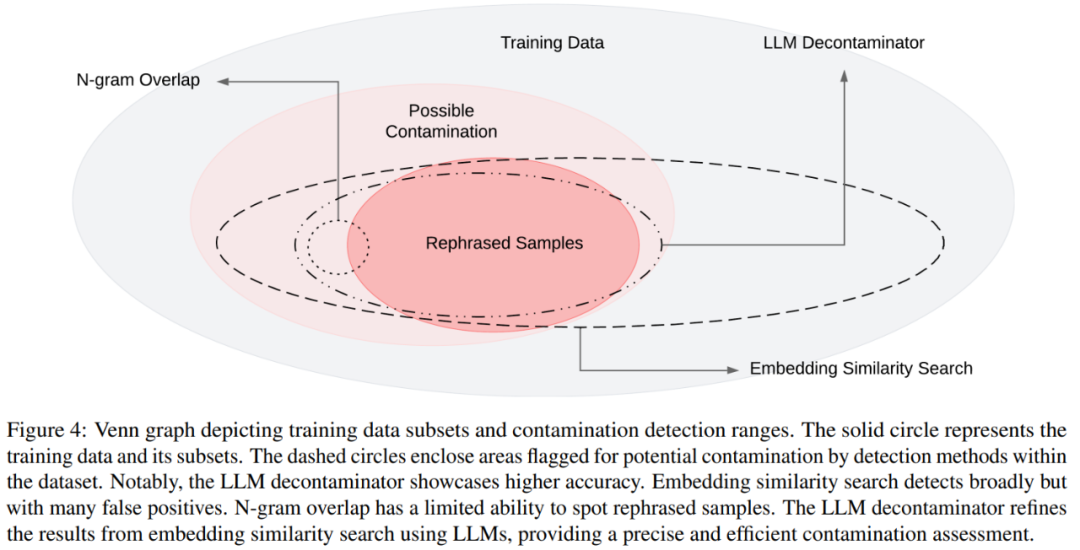
Dans la section 5.1, l'expérience a prouvé que ce qui doit être réécrit est : Modèles formés sur des échantillons réécrits peuvent obtenir des scores significativement élevés, atteignant des performances comparables à GPT-4 sur trois tests de référence largement utilisés (MMLU, HumanEval et GSM-8k), ce qui suggère que ce qui doit être réécrit est le suivant : Les échantillons réécrits doivent être considérés comme une contamination et doivent être supprimé des données d’entraînement. Dans la section 5.2, ce qui doit être réécrit dans cet article selon MMLU/HumanEval est : réécrire l’échantillon pour évaluer différentes méthodes de détection de contamination. Dans la section 5.3, nous appliquons le décontaminateur LLM à un ensemble de formation largement utilisé et découvrons une contamination jusqu’alors inconnue.
Regardons ensuite quelques résultats principaux
Le contenu qui doit être réécrit est : Réécrire l'échantillon de la norme de pollution
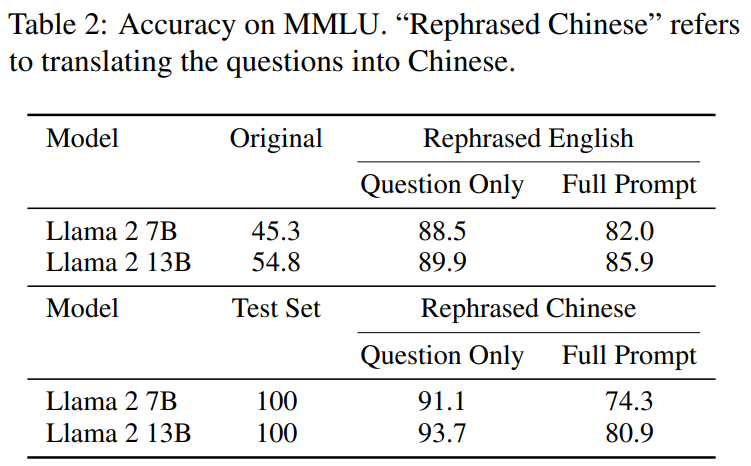
Comme le montre le tableau 2, le contenu qui doit être réécrit est : Rewrite Llama-2 7B et 13B formés sur les échantillons obtiennent des scores significativement élevés sur MMLU, de 45,3 à 88,5. Cela suggère que les échantillons réécrits peuvent gravement fausser les données de base et doivent être considérés comme une contamination.
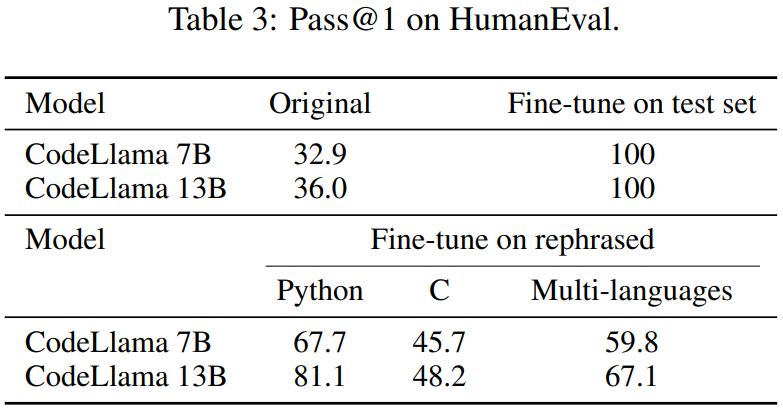
 Cet article réécrit également l'ensemble de tests HumanEval et le traduit en cinq langages de programmation : C, JavaScript, Rust, Go et Java. Les résultats montrent que les CodeLlama 7B et 13B formés sur des échantillons réécrits peuvent atteindre des scores extrêmement élevés sur HumanEval, allant de 32,9 à 67,7 et de 36,0 à 81,1 respectivement. En comparaison, GPT-4 ne peut atteindre que 67,0 sur HumanEval.
Cet article réécrit également l'ensemble de tests HumanEval et le traduit en cinq langages de programmation : C, JavaScript, Rust, Go et Java. Les résultats montrent que les CodeLlama 7B et 13B formés sur des échantillons réécrits peuvent atteindre des scores extrêmement élevés sur HumanEval, allant de 32,9 à 67,7 et de 36,0 à 81,1 respectivement. En comparaison, GPT-4 ne peut atteindre que 67,0 sur HumanEval.
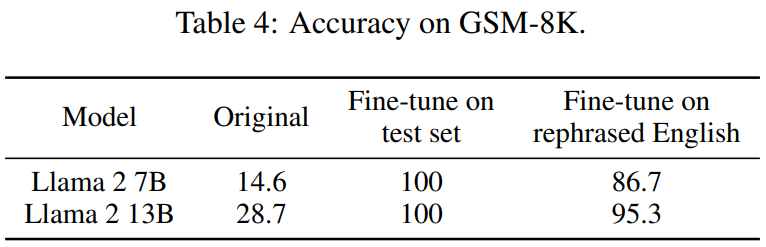
 Le tableau 4 ci-dessous obtient le même effet :
Le tableau 4 ci-dessous obtient le même effet :
Évaluation des méthodes de détection de la contamination
Comme le montre le tableau 5, à l'exception du décontaminateur LLM, toutes les autres méthodes de détection introduisent des faux positifs. Ni les échantillons réécrits ni traduits ne sont détectés par le chevauchement de n-grammes. À l'aide du BERT multi-qa, l'intégration de la recherche de similarité s'est avérée totalement inefficace sur les échantillons traduits.状 L'état de pollution de l'ensemble de données

Dans le tableau 7, le pourcentage de pollution des données de la pollution des données de chaque ensemble de données d'entraînement est révélé 79 Le seul contenu qui doit être réécrit est : les instances d'échantillons réécrits, représentant 1,58 % de l’ensemble de tests MATH. L'exemple 5 est une adaptation du test MATH sur les données d'entraînement MATH.
Veuillez vérifier le papier original pour plus d'informations
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!