
Maison >Périphériques technologiques >IA >La vitesse des images en temps réel a été multipliée par 5 à 10, Tsinghua LCM/LCM-LoRA est devenu populaire, avec plus d'un million de vues et plus de 200 000 téléchargements.
La vitesse des images en temps réel a été multipliée par 5 à 10, Tsinghua LCM/LCM-LoRA est devenu populaire, avec plus d'un million de vues et plus de 200 000 téléchargements.

- 王林avant
- 2023-11-18 08:25:041167parcourir
Les modèles génératifs entrent dans l'ère du « temps réel » ?
L'utilisation de diagrammes vincentiens et de diagrammes Tusheng n'est plus une nouveauté. Cependant, lors de l'utilisation de ces outils, nous avons constaté qu'ils fonctionnent souvent lentement, ce qui nous oblige à attendre un certain temps pour obtenir les résultats générés.
Mais récemment, un modèle appelé "LCM" a changé cette situation, et il est même capable pour obtenir une génération d'images continue en temps réel. " Le nom complet de LCM est Latent Consistency Models (modèle de cohérence latente), développé par Cross Information de l'Université Tsinghua. Recherche Construit par des chercheurs de l'institut. Avant la sortie de ce modèle, les modèles de diffusion latente (LDM) tels que Stable Diffusion étaient très lents à générer en raison de la complexité informatique du processus d'échantillonnage itératif. Grâce à certaines méthodes innovantes, LCM peut générer des images haute résolution avec seulement quelques étapes d'inférence. Selon les statistiques, le LCM peut augmenter de 5 à 10 fois l'efficacité des modèles graphiques vincentiens traditionnels, de sorte qu'il puisse montrer des effets en temps réel.

Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/pdf/2310.04378.pdf
Adresse du projet : https://github.com/luosiallen/latent-consistency-model
Le contenu a été visionné plus d'un million de fois dans le mois suivant sa publication, et l'auteur a également été invité à déployer le modèle LCM nouvellement développé et sa démonstration sur plusieurs plates-formes telles que Hugging Face, Replicate et Puyuan. Parmi eux, le modèle LCM a été téléchargé plus de 200 000 fois sur la plateforme Hugging Face, et le nombre d'appels d'API en ligne sur la plateforme Replicate a dépassé 540 000 fois Sur cette base, l'équipe de recherche a en outre proposé le LCM-LoRA. Cette méthode peut transférer les capacités d'échantillonnage rapide du LCM à d'autres modèles LoRA sans aucune formation supplémentaire. Cela fournit une solution directe et efficace aux nombreux styles de modèles différents qui existent déjà dans la communauté open source
Sur cette base, l'équipe de recherche a en outre proposé le LCM-LoRA. Cette méthode peut transférer les capacités d'échantillonnage rapide du LCM à d'autres modèles LoRA sans aucune formation supplémentaire. Cela fournit une solution directe et efficace aux nombreux styles de modèles différents qui existent déjà dans la communauté open source
- Lien du rapport technique : https://arxiv.org/pdf/2311.05556.pdf
- Cohérence potentielle Le rapide La capacité de génération de modèles ouvre de nouveaux domaines d'application pour la technologie de génération d'images. Ce modèle permet la génération d'images à grande vitesse en traitant et en restituant rapidement les images capturées en temps réel en fonction du texte saisi (invites). Cela signifie que les utilisateurs peuvent personnaliser les scènes ou les effets visuels qu'ils souhaitent afficherSur le , le rendu vidéo en temps réel et d'autres applications diverses.

Le contenu qui doit être réécrit est : Source de l'image : https://twitter.com/javilopen/status/1724398708052414748
 Notre équipe a entièrement open source le code de LCM, et a divulgué les fichiers de poids du modèle et les démonstrations en ligne obtenues par distillation interne basées sur des modèles pré-entraînés tels que SD-v1.5 et SDXL. De plus, l'équipe de Hugging Face a intégré le modèle de cohérence potentielle dans le référentiel officiel des diffuseurs et a mis à jour les cadres de code pertinents de LCM et LCM-LoRA dans deux versions officielles consécutives v0.22.0 et v0.23.0, permettant ainsi de comprendre le potentiel modèle de cohérence. Bon support pour les modèles de cohérence. Le modèle publié sur Hugging Face s'est classé premier dans la liste de popularité d'aujourd'hui, devenant le modèle Wenshengtu le plus populaire sur toutes les plateformes et le troisième modèle le plus populaire dans toutes les catégories
Notre équipe a entièrement open source le code de LCM, et a divulgué les fichiers de poids du modèle et les démonstrations en ligne obtenues par distillation interne basées sur des modèles pré-entraînés tels que SD-v1.5 et SDXL. De plus, l'équipe de Hugging Face a intégré le modèle de cohérence potentielle dans le référentiel officiel des diffuseurs et a mis à jour les cadres de code pertinents de LCM et LCM-LoRA dans deux versions officielles consécutives v0.22.0 et v0.23.0, permettant ainsi de comprendre le potentiel modèle de cohérence. Bon support pour les modèles de cohérence. Le modèle publié sur Hugging Face s'est classé premier dans la liste de popularité d'aujourd'hui, devenant le modèle Wenshengtu le plus populaire sur toutes les plateformes et le troisième modèle le plus populaire dans toutes les catégories
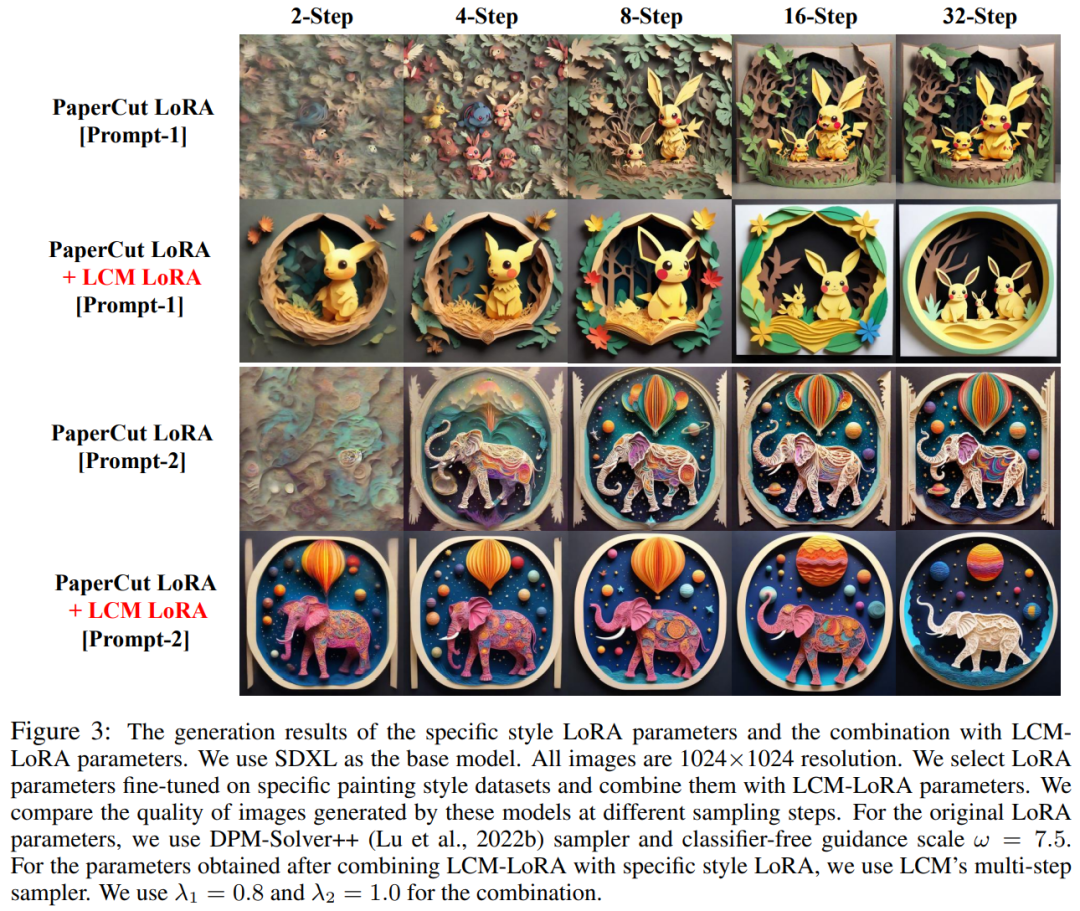
Ensuite, nous présenterons respectivement les deux résultats de recherche du LCM et du LCM-LoRA. LCM : générez des images haute résolution avec seulement quelques étapes d'inférence À l'ère de l'AIGC, les modèles de graphes vincentiens basés sur un modèle de diffusion, notamment Stable Diffusion et DALL-E 3, ont reçu une large attention. Les modèles de diffusion produisent des images de haute qualité en ajoutant du bruit aux données d'entraînement, puis en inversant le processus. Cependant, le modèle de diffusion nécessite un échantillonnage en plusieurs étapes pour générer des images, ce qui est un processus relativement lent et augmente le coût de l'inférence. Le problème de la lenteur de l’échantillonnage en plusieurs étapes constitue un goulot d’étranglement majeur lors du déploiement de tels modèles. Le modèle de cohérence (CM) proposé par le Dr Song Yang d'OpenAI cette année fournit une idée pour résoudre les problèmes ci-dessus. Il a été souligné que le modèle de cohérence est conçu pour pouvoir être généré en une seule étape, ce qui présente un grand potentiel pour accélérer la génération de modèles de diffusion. Cependant, comme le modèle de cohérence est limité à la génération d'images inconditionnelles, de nombreuses applications pratiques, notamment les images vincentiennes, les images générées par graphes, etc., ne parviennent toujours pas à profiter des avantages potentiels de ce modèle. Le modèle de cohérence latente (LCM) est né pour résoudre les problèmes ci-dessus. Le modèle de cohérence latente prend en charge les tâches de génération d'images dans des conditions données et combine le codage latent, le guidage sans classificateur et de nombreuses autres technologies largement utilisées dans les modèles de diffusion, accélérant considérablement le processus de débruitage conditionnel et fournissant de nombreuses applications pratiques. chemin. Détails techniques du LCM Plus précisément, le modèle de cohérence latente interprète le problème de débruitage du modèle de diffusion comme un processus de résolution de l'équation différentielle ordinaire à flux probabiliste augmenté illustré ci-dessous. L'efficacité de la solution peut être améliorée en améliorant le modèle de diffusion traditionnel. La méthode traditionnelle utilise l'itération numérique pour résoudre des équations différentielles ordinaires, mais même avec un solveur plus précis, la précision de chaque étape est limitée et il faut environ 10 itérations pour obtenir un résultat satisfaisant Différent de la solution itérative traditionnelle des équations différentielles ordinaires équations , le modèle de cohérence latente nécessite directement une solution en une seule étape de l'équation différentielle ordinaire, prédisant la solution finale de l'équation, et peut théoriquement générer une image en une seule étape Afin d'entraîner le modèle de cohérence latente , cette étude propose qu'il soit possible d'affiner les paramètres des modèles de diffusion pré-entraînés (par exemple, diffusion stable) pour obtenir une génération rapide de modèles avec une consommation de ressources minimale. Ce procédé de distillation est basé sur l'optimisation de la fonction de perte de consistance proposée par le Dr Song Yang. Afin d'obtenir de meilleures performances et de réduire la surcharge de calcul sur la tâche du graphe vincentien, cet article propose trois technologies clés : Contenu réécrit : (1) En utilisant un auto-encodeur pré-entraîné, l'image originale est encodée dans une représentation latente dans l'espace. pour réduire les informations redondantes lors de la compression des images et rendre les images plus cohérentes sémantiquement (2) Distiller le guidage sans classificateur en tant que paramètre d'entrée du modèle dans le modèle de cohérence latente et profiter du sans classe Tandis que le guidage du classificateur apporte une meilleure cohérence image-texte, puisque l'amplitude de guidage sans classificateur est distillée dans le modèle de consistance latente en tant que paramètre d'entrée, elle peut réduire la charge de calcul requise lors de l'inférence (3) L'utilisation de la stratégie de saut pour calculer la perte de cohérence accélère considérablement le processus de distillation du modèle de cohérence potentielle. Le pseudocode de l'algorithme de distillation du modèle de consistance latente est présenté dans la figure ci-dessous. Les résultats qualitatifs et quantitatifs montrent que le modèle de cohérence latente a la capacité de générer rapidement des images de haute qualité. Ce modèle peut générer des images de haute qualité en 1 à 4 étapes. En comparant le temps d'inférence réel et l'indicateur de qualité de génération FID, on peut voir que par rapport au solveur DPM++, l'un des échantillonneurs existants les plus rapides, le modèle de cohérence potentielle peut accélérer le temps d'inférence réel d'environ 4 fois tout en conservant la même qualité de génération. . Sur la base du modèle de cohérence, l'équipe d'auteurs a ensuite publié son rapport technique sur LCM-LoRA. Étant donné que le processus de distillation du modèle de cohérence latente peut être considéré comme un processus de réglage fin du modèle pré-entraîné d'origine, des techniques de réglage fin efficaces telles que LoRA peuvent être utilisées pour former le modèle de cohérence latente. Grâce aux économies de ressources apportées par la technologie LoRA, l'équipe de l'auteur a effectué une distillation sur le modèle SDXL avec le plus grand nombre de paramètres de la série Stable Diffusion et a réussi à obtenir un consensus potentiel pouvant être généré en très peu d'étapes et comparable à des dizaines d'étapes SDXL. Dans l'introduction de l'article, l'étude souligne que bien que le modèle de diffusion latente (LDM) ait réussi à générer des images de texte et des images de dessin au trait, son lent processus d'échantillonnage inverse limite les applications en temps réel et a un impact sur l'expérience utilisateur. . Les modèles open source et les technologies d'accélération actuels ne peuvent pas encore réaliser une génération en temps réel sur des GPU grand public ordinaires. Les méthodes permettant d'accélérer le LDM sont généralement divisées en deux catégories : la première catégorie implique des solveurs ODE avancés, tels que DDIM, DPMSolver et DPM-Solver++. et Accélérer le processus de génération. La deuxième catégorie consiste à distiller du LDM pour simplifier ses fonctionnalités. ODE - Solver réduit les étapes d'inférence mais nécessite toujours une surcharge de calcul importante, en particulier lors de l'utilisation d'un guidage sans classificateur. Pendant ce temps, les méthodes de distillation telles que la distillation guidée, bien que prometteuses, sont confrontées à des limites pratiques en raison de leurs exigences informatiques intensives. Trouver un équilibre entre la vitesse et la qualité des images générées par LDM reste un défi dans le domaine. Récemment, inspiré du modèle de cohérence (CM), le modèle de cohérence latente (LCM) est apparu comme une solution au problème d'échantillonnage lent dans la génération d'images. LCM considère le processus de rétrodiffusion comme un problème d'ODE à flux de probabilité amélioré (PF-ODE). Ce type de modèle prédit de manière innovante des solutions dans l'espace latent sans avoir besoin de solutions itératives via des solveurs ODE numériques. En conséquence, ils permettent une synthèse efficace d’images haute résolution avec seulement 1 à 4 étapes d’inférence. De plus, le LCM a également obtenu de bons résultats en termes d'efficacité de distillation, et il n'a fallu que 32 heures de formation avec A100 pour compléter l'inférence de la plus petite étape Sur cette base, une méthode appelée réglage fin de la consistance latente (LCF) a été développée , qui peut affiner le LCM pré-formé sans partir d'un modèle de diffusion par les enseignants. Pour les ensembles de données spécialisés, tels que les ensembles de données d'anime, de photos réelles ou d'images fantastiques, des étapes supplémentaires sont nécessaires, telles que la distillation du LDM pré-entraîné en LCM à l'aide de la distillation latente cohérente (LCD) ou le réglage fin du LCM directement à l'aide du LCF. Cependant, cette formation supplémentaire peut entraver le déploiement rapide de LCM sur différents ensembles de données, ce qui soulève une question clé : si une inférence rapide et sans formation peut être réalisée sur des ensembles de données personnalisés Pour répondre à la question ci-dessus, les chercheurs ont proposé LCM-LoRA. LCM-LoRA est un module d'accélération général sans formation qui peut être directement branché sur divers modèles affinés à diffusion stable (SD) ou SD LoRA pour prendre en charge une inférence rapide avec un minimum d'étapes. Comparé aux premiers solveurs d'ODE à flux probabiliste numérique (PF-ODE) tels que DDIM, DPM-Solver et DPM-Solver++, LCM-LoRA représente une nouvelle classe de modules de solveur PF-ODE basés sur des réseaux de neurones. Il démontre de fortes capacités de généralisation à travers divers modèles SD affinés et un tracé de présentation LoRA LCM-LoRA. En introduisant LoRA dans le processus de distillation du LCM, l’étude a considérablement réduit la surcharge de mémoire liée à la distillation, ce qui leur a permis d’utiliser des ressources limitées pour former des modèles plus grands tels que SDXL et SSD-1B. Plus important encore, les paramètres LoRA (vecteur d'accélération) obtenus grâce à la formation LCM-LoRA peuvent être directement combinés avec d'autres paramètres LoRA (style vetcor) obtenus en affinant un ensemble de données de style spécifique. Sans aucune formation, le modèle obtenu par la combinaison linéaire du vecteur d'accélération et du vecteur de style peut générer des images d'un style de peinture spécifique avec des étapes d'échantillonnage minimales. De manière générale, le modèle de consistance latente est formé à l'aide d'une méthode de distillation guidée en une seule étape, qui utilise l'espace latent de l'auto-encodeur pré-entraîné pour la distillation du modèle de diffusion guidée. dans LCM. Ce processus consiste à augmenter le flux probabiliste ODE, que nous pouvons considérer comme une formule mathématique garantissant que les échantillons générés suivent une trajectoire produisant des images de haute qualité. Il est à noter que l'objectif de la distillation est de maintenir la fidélité de ces trajectoires tout en réduisant considérablement le nombre d'étapes d'échantillonnage requises. L'algorithme 1 fournit le pseudocode de l'écran LCD. LoRA met à jour la matrice de poids pré-entraînée en appliquant une décomposition de bas rang. Plus précisément, étant donné une matrice de poids h représente le vecteur de sortie. À partir de la formule (1), on peut observer qu'en décomposant la matrice de paramètres complète en produit de deux faibles. matrices de classement, LoRA a considérablement réduit le nombre de paramètres pouvant être entraînés, réduisant ainsi l'utilisation de la mémoire. Le tableau ci-dessous compare le nombre total de paramètres dans le modèle complet aux paramètres pouvant être entraînés lors de l'utilisation de la technologie LoRA. Évidemment, en incorporant la technologie LoRA dans le processus de distillation LCM, le nombre de paramètres pouvant être entraînés est considérablement réduit, réduisant ainsi les besoins en mémoire pour l'entraînement. Cette étude montre à travers une série d'expériences que le paradigme LCD peut être bien adapté aux modèles plus grands tels que SDXL et SSD-1B. Les résultats de génération de différents modèles sont présentés dans la figure 2. L'auteur a découvert que l'utilisation de la technologie LoRA peut améliorer l'efficacité du processus de distillation. Il a également constaté que les paramètres LoRA obtenus grâce à la formation peuvent être utilisés comme module d'accélération général qui peut être directement combiné avec d'autres paramètres LoRA . Comme le montre la figure 1 ci-dessus, l'équipe d'auteurs a découvert qu'en combinant simplement de manière linéaire les « paramètres de style » obtenus en affinant un ensemble de données de style spécifique et les « paramètres d'accélération » obtenus par distillation de cohérence latente, il est possible d'obtenir à la fois capacités de génération rapide et styles spécifiques. Un nouveau modèle de cohérence latente. Cette découverte donne un fort coup de pouce au grand nombre de modèles open source qui existent déjà dans la communauté open source existante, permettant même à ces modèles de profiter des effets d'accélération apportés par le modèle de cohérence latente sans aucune formation supplémentaire. montre l'effet de la nouvelle génération de modèle après avoir utilisé cette méthode pour améliorer le modèle "style papier découpé", comme le montre la figure ci-dessous En bref, LCM-LoRA est un modèle pour Stable-Diffusion (SD ) Module d'accélération universel sans formation. Il fonctionne comme un module de résolution autonome et efficace basé sur un réseau neuronal pour prédire les solutions à PF-ODE, permettant une inférence rapide avec des étapes minimales sur divers modèles SD affinés et SD LoRA. Un grand nombre d'expériences de génération de texte en image ont prouvé la forte capacité de généralisation et la supériorité de LCM-LoRA Présentation de l'équipe Les auteurs de l'article sont tous de l'Université Tsinghua et les deux co-auteurs sont Luo Simian et Tan Yiqin. Luo Simian est étudiant en deuxième année de maîtrise au Département d'informatique et de technologie de l'Université Tsinghua, et son superviseur est le professeur Zhao Xing. Il est diplômé de la Big Data School de l'Université de Fudan avec un baccalauréat. Son domaine de recherche porte sur les modèles génératifs multimodaux. Il s'intéresse aux modèles de diffusion, aux modèles de cohérence et à l'accélération AIGC, et s'engage à développer la prochaine génération de modèles génératifs. Auparavant, il a publié de nombreux articles en tant que premier auteur lors de conférences de premier plan telles que ICCV et NeurIPS. Tan Yiqin est étudiant en deuxième année de maîtrise à l'Université Tsinghua et son superviseur est M. Huang Longbo. En tant qu'étudiant de premier cycle, il a étudié au Département de génie électronique de l'Université Tsinghua. Ses intérêts de recherche portent principalement sur les modèles d’apprentissage par renforcement profond et de diffusion. Dans des recherches antérieures, il a publié des articles de grande envergure en tant que premier auteur lors de conférences universitaires telles que l'ICLR et a donné des rapports oraux Il convient de mentionner que l'un des deux est un enseignant de l'École de médecine Li Jian Dans le domaine avancé cours de théorie informatique, l'idée du LCM a été proposée et finalement présentée comme projet de cours final. Parmi les trois instructeurs, Li Jian et Huang Longbo sont professeurs associés à l'Institut d'information interdisciplinaire Tsinghua, et Zhao Xing est professeur adjoint à l'Institut d'information interdisciplinaire Tsinghua. La première rangée (de gauche à droite) : Luo Simian, Tan Yiqin. Deuxième rangée (de gauche à droite) : Huang Longbo, Li Jian, Zhao Xing. 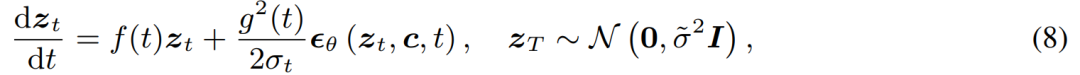


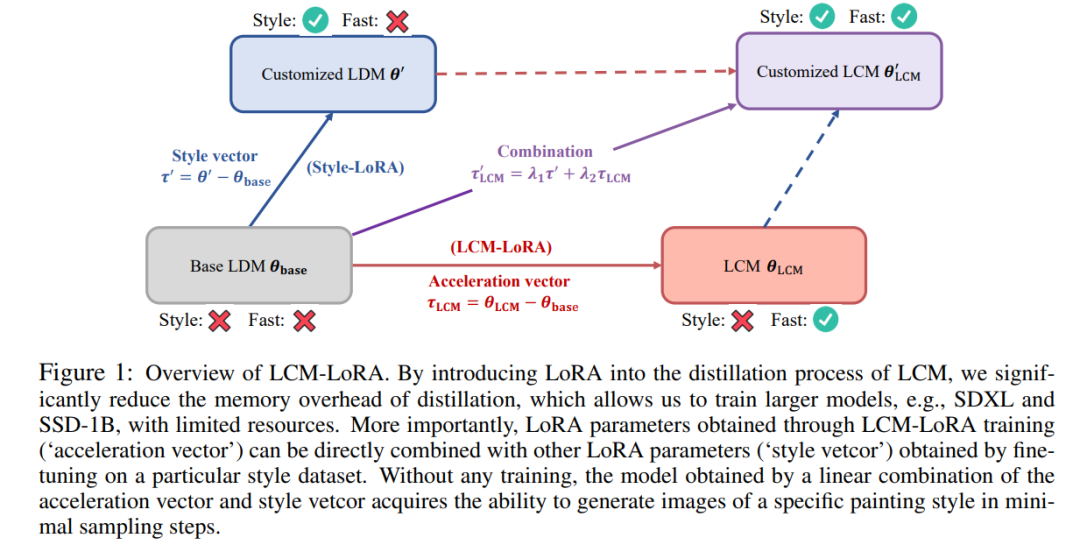
 Étant donné que le processus de distillation du LCM est effectué sur les paramètres du modèle de diffusion pré-entraîné, nous pouvons considérer la distillation à consistance latente comme un processus de réglage fin du modèle de diffusion, afin que nous puissions utiliser un paramètre efficace méthodes de réglage, telles que LoRA.
Étant donné que le processus de distillation du LCM est effectué sur les paramètres du modèle de diffusion pré-entraîné, nous pouvons considérer la distillation à consistance latente comme un processus de réglage fin du modèle de diffusion, afin que nous puissions utiliser un paramètre efficace méthodes de réglage, telles que LoRA. 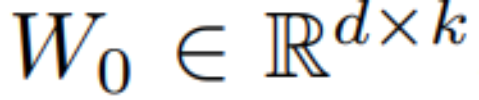 , sa méthode de mise à jour est exprimée par
, sa méthode de mise à jour est exprimée par 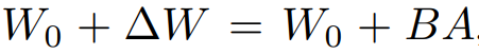 , où
, où 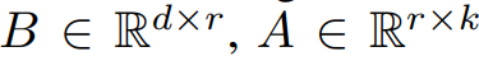 , pendant le processus d'entraînement, W_0 reste inchangé et la mise à jour du gradient n'est appliquée qu'aux deux paramètres A et B. Ainsi pour l'entrée x, le changement de propagation vers l'avant est exprimé comme suit :
, pendant le processus d'entraînement, W_0 reste inchangé et la mise à jour du gradient n'est appliquée qu'aux deux paramètres A et B. Ainsi pour l'entrée x, le changement de propagation vers l'avant est exprimé comme suit : 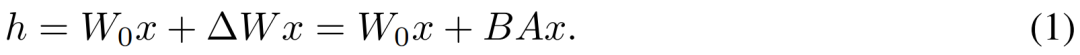



Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!