
Maison >Périphériques technologiques >IA >Extraire le tableau de l'image à l'aide de Python
Extraire le tableau de l'image à l'aide de Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-17 22:15:071747parcourir
Il y a environ un an, on m'a confié la tâche d'extraire et de structurer des données à partir de fichiers, principalement des données contenues dans des tableaux. Je n'avais aucune connaissance préalable en vision par ordinateur et j'avais du mal à trouver une solution « plug and play » adaptée. Les options disponibles à l'époque étaient soit des solutions basées sur les derniers réseaux de neurones (NN), qui étaient volumineux et encombrants, soit des solutions plus simples basées sur OpenCV, qui n'étaient pas assez cohérentes.
Inspiré par les scripts OpenCV existants, j'ai développé un moyen simple et cohérent d'extraire des tables et l'ai transformé en une bibliothèque Python open source : img2table
Ce qui doit être réécrit est : Lien : https://github.com/ xavctn/img2table

Que fait ma bibliothèque ?
Comparé aux solutions de deep learning, ce package léger ne nécessite aucune formation et un paramétrage minimal. Il offre les fonctionnalités suivantes :
- Identifie les tableaux dans les images et les fichiers PDF, y compris les cadres de délimitation au niveau des cellules du tableau.
- Extractez le contenu du tableau en prenant en charge les services/outils OCR (Tesseract, PaddleOCR, AWS Textract, Google Vision et Azure OCR sont actuellement pris en charge).
- Gérez des structures de tableau complexes comme des cellules fusionnées.
- Implémenter des méthodes pour corriger l'inclinaison et la rotation des images.
- La table extraite est renvoyée sous la forme d'un objet simple, comprenant une représentation Pandas DataFrame.
- Option d'exporter le tableau extrait vers un fichier Excel, en préservant sa structure d'origine.
Comment l'utiliser ?
Vous pouvez utiliser pip pour installer cette bibliothèque, et vous pouvez l'utiliser une fois l'installation terminée
pip install img2table
Pour identifier la table dans le document, il vous suffit d'appeler une fonction :
从img2table.document导入Image类# 图像实例化 img = Image(src="myimage.jpg")# 表格识别 img_tables = img.extract_tables()# 表格识别结果 img_tables[ExtractedTable(title=None, bbox=(10, 8, 745, 314),shape=(6, 3)), ExtractedTable(title=None, bbox=(936, 9, 1129, 111),shape=(2, 2))]
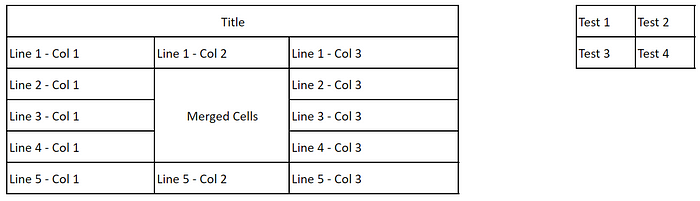
Le contenu qui doit être réécrit est : L'image utilisée dans l'exemple ci-dessus
Si nous voulons extraire le contenu du tableau, nous devons utiliser un outil OCR. Ceci peut être réalisé en suivant les étapes ci-dessous :
from img2table.document import PDFfrom img2table.ocr import TesseractOCR# Instantiation of the pdfpdf = PDF(src="mypdf.pdf")# Instantiation of the OCR, Tesseract, which requires prior installationocr = TesseractOCR(lang="eng")# Table identification and extractionpdf_tables = pdf.extract_tables(ocr=ocr)# We can also create an excel file with the tablespdf.to_xlsx('tables.xlsx',ocr=ocr)
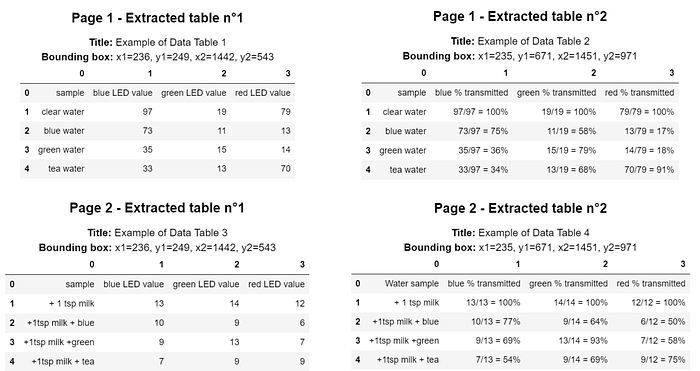
L'exemple de table est un exemple extrait d'un fichier PDF
Enfin, dans un cas simple, vous pouvez effectuer des "borderless_tables" en définissant le ` Paramètre borderless_tables "Extraction des tables. Cela permet la détection de tableaux dans lesquels les cellules n'ont pas besoin d'être complètement entourées de bordures.
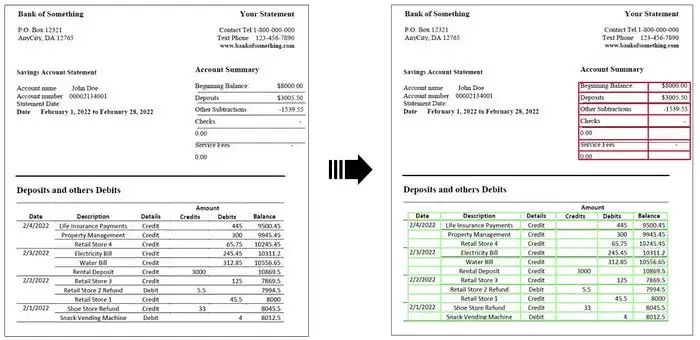
Pas besoin de changer le sens original, ce qui doit être réécrit c'est : Exemple d'extraction de table "Borderless"
C'est tout ! En fait, le référentiel n'est pas compliqué car notre objectif est de le simplifier autant que possible et d'éviter d'introduire d'autres solutions qui pourraient apporter de la complexité
Veuillez visiter la page GitHub du projet pour une documentation plus détaillée et des exemples : https:// / github.com/xavctn/img2table
Implémentation sous-jacente
Tout le traitement des images est effectué à l'aide des bibliothèques OpenCV et opencv-python. Cependant, cela reste assez basique.
Le cœur de l'algorithme est la transformée de Hough, qui est capable d'identifier les lignes droites dans l'image, nous permettant de détecter les lignes horizontales et verticales dans l'image
需要重写的内容是:cv2.HoughLinesP(img, rho, theta, threshold, None, minLinLength, maxLineGap)
Après cela, nous devons effectuer quelques traitements sur les lignes afin de les identifier hors des cellules et d'identifier davantage les tableaux à partir des cellules
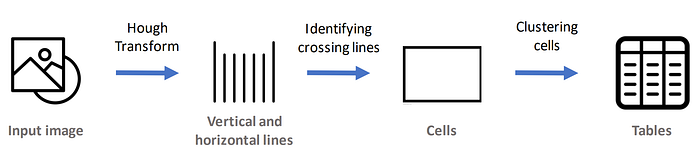
Implémentation simplifiée de la représentation algorithmique
La plupart des calculs sont effectués à l'aide de Polars pour de bonnes performances et rapidité.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!