
 Périphériques technologiquesIAL'équipe de recherche de l'Académie chinoise des sciences a publié deux articles importants : la publication du premier modèle à grande échelle des bases de la vie entre les espèces et la publication d'un nouveau modèle d'IA pour la prédiction du devenir des cellules.
Périphériques technologiquesIAL'équipe de recherche de l'Académie chinoise des sciences a publié deux articles importants : la publication du premier modèle à grande échelle des bases de la vie entre les espèces et la publication d'un nouveau modèle d'IA pour la prédiction du devenir des cellules.
Auteur | Équipe de recherche multidisciplinaire, Académie chinoise des sciences
Éditeur | ScienceAI
Le projet du génome humain, connu comme l'un des trois projets scientifiques majeurs de l'humanité au 20e siècle, a lancé une analyse approfondie des mystères de la vie. Les processus vitaux étant multidimensionnels et hautement dynamiques, il est difficile pour les méthodes de recherche expérimentale traditionnelles de déchiffrer systématiquement et avec précision les lois communes sous-jacentes du code génétique. Il est urgent d’utiliser une technologie informatique puissante pour réaliser une modélisation des représentations et la découverte de connaissances génétiques. données.
Actuellement, la technologie de l'intelligence artificielle basée sur de grands modèles a déclenché des révolutions dans des domaines tels que la vision par ordinateur et la compréhension du langage naturel, démontrant une compréhension approfondie des données et des connaissances. Elle devrait être appliquée dans le domaine de la recherche en sciences de la vie. pour déchiffrer systématiquement et avec précision les gènes. Les lois communes sous-jacentes de la cryptographie
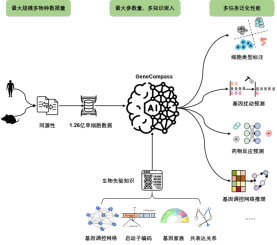
Récemment, le « Consortium Xcompass », composé d'une équipe de recherche interdisciplinaire multidisciplinaire de l'Académie chinoise des sciences, a réalisé avec succès des percées importantes dans l'intelligence artificielle renforçant la recherche en sciences de la vie. construire le premier grand modèle de base de sciences de la vie inter-espèces au monde - GeneCompass. Ce modèle intègre les données du transcriptome de plus de 126 millions de cellules uniques d'humains et de souris, et intègre quatre types de connaissances antérieures, notamment les séquences promotrices et les relations de co-expression des gènes. Le nombre de paramètres de base du modèle atteint 130 millions, réalisant le contrôle des gènes. L'apprentissage panoramique et la compréhension des lois de régulation soutiennent simultanément la prédiction des changements d'état cellulaire et l'analyse précise de divers processus vitaux, démontrant le grand potentiel de l'intelligence artificielle pour renforcer la recherche en sciences de la vie.
L'étude s'intitule « GeneCompass : Déchiffrer les mécanismes universels de régulation des gènes avec un modèle de fondation inter-espèces fondé sur la connaissance » et a été publiée sur bioRxiv.

Lien papier : https://www.biorxiv.org/content/10.1101/2023.09.26.559542v1
De plus, l'équipe a également publié simultanément un modèle de génération de réseau de régulation génique basé sur l'apprentissage par transfert, CellPolaris , ce modèle peut identifier avec précision les facteurs fondamentaux de la conversion du destin cellulaire et a la capacité de simuler les perturbations des facteurs de transcription.
L'étude s'intitule « CellPolaris : Decoding Cell Fate through Generalization Transfer Learning of Gene Regulatory Networks » et a été publiée sur bioRxiv.

GeneCompass : Le premier modèle à grande échelle des bases de la vie à travers les espèces
Les individus mammifères contiennent généralement des dizaines de milliers à des dizaines de milliards de cellules. Bien que toutes les cellules d’un individu contiennent la même séquence génétique, le destin et la fonction de chaque cellule varient considérablement en raison de son contexte spatio-temporel unique. Ces processus vitaux sophistiqués sont contrôlés par des systèmes complexes de régulation de l'expression des gènes.
Afin d'améliorer notre compréhension des lois essentielles de la vie et d'innover dans le diagnostic et le traitement de diverses maladies majeures, il est nécessaire de mener une exploration approfondie de la régulation des gènes. mécanismes omniprésents dans la vie. Cependant, les méthodes de recherche traditionnelles ont un faible débit et sont limitées à un seul organisme modèle, et ne peuvent pas révéler des mécanismes complexes de régulation des gènes. Ces dernières années, les percées dans la technologie omique unicellulaire ont produit un grand nombre de données sur le profil d’expression génique de différents types de gènes. les cellules, fournissant une base pour l’interprétation des gènes. -Les interactions génétiques fournissent la base des données. Dans le même temps, le développement de l’apprentissage profond, en particulier l’émergence de grands modèles génératifs, peut résumer de manière exhaustive les mécanismes de régulation non linéaires de quantités massives de données dans différents états cellulaires, ouvrant ainsi des opportunités sans précédent à la recherche en sciences de la vie.
Un grand modèle des bases de la vie à travers les espèces, comprenant 120 millions de nombres de cellules et 130 millions de paramètresActuellement, l'échelle des données de transcriptome unicellulaire obtenues sur une seule espèce dans le monde n'est que de plusieurs dizaines de millions. , il est difficile de prendre pleinement en charge la formation de grands modèles de modèles de vie de base utilisés pour analyser des processus vitaux complexes.
L'équipe a collecté des données open source sur le transcriptome unicellulaire de différentes espèces et, après des processus de prétraitement tels que le criblage, le nettoyage et la normalisation, a établi les plus grandes données d'entraînement connues de haute qualité, comprenant plus de 126 millions de cellules chez la souris et l'homme. . Collection scCompass-126M ; adopte une architecture d'apprentissage en profondeur basée sur le mécanisme d'auto-attention du Transformer, qui peut capturer la corrélation dynamique à long terme entre différents gènes dans différents milieux cellulaires, et la taille des paramètres du modèle atteint 130 millions. Afin de parvenir à une caractérisation à haute résolution des processus vitaux, GeneCompass code pour la première fois les numéros de gènes et les niveaux d'expression, permettant une extraction efficace et sensible des corrélations entre les gènes. Cela permet à GeneCompass de fournir une analyse plus précise des interactions gène-gène dans diverses conditions spécifiques, telles que les types de cellules et les états de perturbation.
L'intégration de connaissances préalables pendant la pré-formation peut améliorer efficacement les performances du modèle
Le modèle ajoute des êtres humains en intégrant efficacement quatre connaissances biologiques préalables : la séquence du promoteur, le réseau de régulation des gènes connu, les informations sur la famille de gènes et la relation de co-expression des gènes. Informations d'annotation le codage améliore la compréhension des corrélations de caractéristiques complexes entre les données biologiques. Grâce à la formation et à l'intégration des données et des connaissances préalables sur différentes espèces, GeneCompass devrait améliorer l'efficacité et la précision de la recherche biologique traditionnelle et ouvrir de nouveaux points d'entrée à des problèmes complexes des sciences de la vie qui ne peuvent pas encore être résolus.
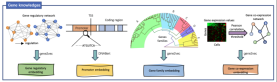
L'effet d'échelle incite l'entraînement du modèle à capturer les lois conservatrices de l'évolution biologique
L'équipe a constaté que le modèle pré-entraîné sur des données inter-espèces à grande échelle était conforme à la loi d'échelle sur la sous-tâche d'une seule espèce : c'est-à-dire que plus les données de pré-entraînement multi-espèces à grande échelle peuvent produire de meilleures représentations pré-entraînées et améliorer encore les performances sur les tâches en aval. Cette découverte montre qu'il existe des modèles de régulation génétique conservés entre les espèces et que ces modèles peuvent être appris et compris par des modèles pré-entraînés. Dans le même temps, cela signifie également qu'avec l'expansion des espèces et des données, les performances du modèle devraient continuer à s'améliorer
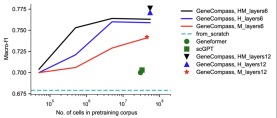
Avantages en termes de performances multitâches démontrer les puissantes capacités de généralisation des grands modèles de base
En tant que plus grand modèle de vie de base pré-entraîné inter-espèces avec intégration de connaissances à ce jour, GeneCompass peut mettre en œuvre l'apprentissage par transfert pour plusieurs tâches en aval inter-espèces et peut être utilisé dans le type de cellule annotation, prédiction quantitative des perturbations génétiques, analyse de sensibilité aux médicaments, etc. En termes de performances, elle atteint de meilleures performances que les méthodes existantes. Cela démontre pleinement les avantages stratégiques de la pré-formation basée sur des mégadonnées multi-espèces non étiquetées, puis de l'utilisation de différentes données de sous-tâches pour affiner le modèle. Elle devrait devenir une solution universelle pour analyser et prédire divers problèmes biologiques liés aux gènes. -caractéristiques des cellules.
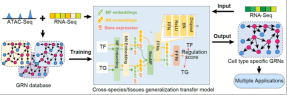
Polarisation cellulaire : l'apprentissage par transfert décode les réseaux de régulation génique et prédit les changements du destin cellulaire
Utilisation de l'apprentissage par transfert pour générer des réseaux de régulation génique spécifiques aux cellules
L'équipe a également développé un ensemble d'apprentissage par transfert généralisé basé sur Le réseau de régulation génétique construit un modèle d’IA appelé CellPolaris. Le modèle trie d'abord des centaines d'ensembles de données d'accessibilité du transcriptome et de la chromatine dans des scénarios cellulaires correspondants pour créer un réseau de régulation génique de haute qualité, puis utilise le modèle d'apprentissage par transfert généralisé pour générer davantage de gènes dans des scénarios cellulaires en utilisant uniquement les données du transcriptome. . Ensuite, en utilisant le réseau de régulation génique de haute confiance généré, nous avons développé un outil pour identifier les principaux facteurs de transcription pour les transitions du destin cellulaire et un outil de simulation de perturbation des facteurs de transcription basé sur un modèle graphique probabiliste. Ce modèle peut identifier efficacement les facteurs fondamentaux de la conversion du destin cellulaire et réaliser la simulation de la perturbation des facteurs de transcription. Il présente une valeur d'application importante dans l'analyse des mécanismes de régulation des gènes et la découverte de gènes responsables de maladies.
Le réseau de régulation génique généré par le modèle CellPolaris fournit une richesse de molécules Les informations sur les interactions peuvent être utilisées comme connaissances préalables pour les grands modèles d’apprentissage profond. Les vecteurs d'intégration de faible dimension générés par les grands modèles d'apprentissage profond fourniront des informations importantes pour l'analyse des mécanismes de régulation des gènes et la découverte de gènes responsables de maladies.
Les deux études ci-dessus ont été réalisées par l'équipe "Compass Alliance". L'équipe "Compass Alliance" est actuellement principalement composée du Centre commun d'information sur les réseaux informatiques de l'Institut de zoologie, de l'Académie chinoise des sciences, de l'Institut d'automatisation, de l'Institut de zoologie. Institute of Computing Technology, Institute of Mathematics and Systems Science, etc. , l'objectif de l'alliance est d'établir un nouveau paradigme de recherche en sciences de la vie piloté par l'intelligence numérique et d'analyser les lois essentielles de la vie.
Intelligence Artificielle × [Biologie Neurosciences Mathématiques Physique Chimie Matériaux]
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Les plus utilisés à 10 graphiques BI - Analytics vidhyaApr 16, 2025 pm 12:05 PM
Les plus utilisés à 10 graphiques BI - Analytics vidhyaApr 16, 2025 pm 12:05 PMExploitation de la puissance de la visualisation des données avec les graphiques Microsoft Power BI Dans le monde actuel axé sur les données, la communication efficace des informations complexes à un public non technique est cruciale. La visualisation des données comble cet écart, transformant les données brutes i
 Systèmes experts en IAApr 16, 2025 pm 12:00 PM
Systèmes experts en IAApr 16, 2025 pm 12:00 PMSystèmes experts: une plongée profonde dans le pouvoir de prise de décision de l'IA Imaginez avoir accès à des conseils d'experts sur n'importe quoi, des diagnostics médicaux à la planification financière. C'est le pouvoir des systèmes experts en intelligence artificielle. Ces systèmes imitent le pro
 Trois des meilleurs codeurs d'ambiance décomposent cette révolution de l'IA dans le codeApr 16, 2025 am 11:58 AM
Trois des meilleurs codeurs d'ambiance décomposent cette révolution de l'IA dans le codeApr 16, 2025 am 11:58 AMTout d'abord, il est évident que cela se produit rapidement. Diverses entreprises parlent des proportions de leur code actuellement écrites par l'IA, et elles augmentent à un clip rapide. Il y a déjà beaucoup de déplacement de l'emploi
 Gen-4 de la piste AI: Comment Ai Montage peut-il aller au-delà de l'absurditéApr 16, 2025 am 11:45 AM
Gen-4 de la piste AI: Comment Ai Montage peut-il aller au-delà de l'absurditéApr 16, 2025 am 11:45 AML'industrie cinématographique, aux côtés de tous les secteurs créatifs, du marketing numérique aux médias sociaux, se dresse à un carrefour technologique. Alors que l'intelligence artificielle commence à remodeler tous les aspects de la narration visuelle et à changer le paysage du divertissement
 Comment s'inscrire pendant 5 jours ISRO AI Free Courses? - Analytique VidhyaApr 16, 2025 am 11:43 AM
Comment s'inscrire pendant 5 jours ISRO AI Free Courses? - Analytique VidhyaApr 16, 2025 am 11:43 AMCours en ligne GRATUIT AI / ML d'ISRO: Une passerelle vers l'innovation technologique géospatiale L'Organisation indienne de recherche spatiale (ISRO), par le biais de son Institut indien de télédétection (IIRS), offre une opportunité fantastique aux étudiants et aux professionnels de
 Algorithmes de recherche locaux dans l'IAApr 16, 2025 am 11:40 AM
Algorithmes de recherche locaux dans l'IAApr 16, 2025 am 11:40 AMAlgorithmes de recherche locaux: un guide complet La planification d'un événement à grande échelle nécessite une distribution efficace de la charge de travail. Lorsque les approches traditionnelles échouent, les algorithmes de recherche locaux offrent une solution puissante. Cet article explore l'escalade et le simul
 Openai change de mise au point avec GPT-4.1, priorise le codage et la rentabilitéApr 16, 2025 am 11:37 AM
Openai change de mise au point avec GPT-4.1, priorise le codage et la rentabilitéApr 16, 2025 am 11:37 AMLa version comprend trois modèles distincts, GPT-4.1, GPT-4.1 Mini et GPT-4.1 Nano, signalant une évolution vers des optimisations spécifiques à la tâche dans le paysage du modèle grand langage. Ces modèles ne remplacent pas immédiatement les interfaces orientées utilisateur comme
 L'invite: Chatgpt génère de faux passeportsApr 16, 2025 am 11:35 AM
L'invite: Chatgpt génère de faux passeportsApr 16, 2025 am 11:35 AMLe géant de la puce Nvidia a déclaré lundi qu'il commencerait à fabriquer des superordinateurs d'IA - des machines qui peuvent traiter de grandes quantités de données et exécuter des algorithmes complexes - entièrement aux États-Unis pour la première fois. L'annonce intervient après le président Trump Si


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

VSCode Windows 64 bits Télécharger
Un éditeur IDE gratuit et puissant lancé par Microsoft

DVWA
Damn Vulnerable Web App (DVWA) est une application Web PHP/MySQL très vulnérable. Ses principaux objectifs sont d'aider les professionnels de la sécurité à tester leurs compétences et leurs outils dans un environnement juridique, d'aider les développeurs Web à mieux comprendre le processus de sécurisation des applications Web et d'aider les enseignants/étudiants à enseigner/apprendre dans un environnement de classe. Application Web sécurité. L'objectif de DVWA est de mettre en pratique certaines des vulnérabilités Web les plus courantes via une interface simple et directe, avec différents degrés de difficulté. Veuillez noter que ce logiciel

SublimeText3 Linux nouvelle version
Dernière version de SublimeText3 Linux

Dreamweaver CS6
Outils de développement Web visuel

MantisBT
Mantis est un outil Web de suivi des défauts facile à déployer, conçu pour faciliter le suivi des défauts des produits. Cela nécessite PHP, MySQL et un serveur Web. Découvrez nos services de démonstration et d'hébergement.

