
Maison >Périphériques technologiques >IA >Une astuce pour distinguer les modèles de triche à grande échelle, le « miroir démoniaque » mathématique IA open source du frère du médecin
Une astuce pour distinguer les modèles de triche à grande échelle, le « miroir démoniaque » mathématique IA open source du frère du médecin

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-17 12:38:44785parcourir
De nos jours, de nombreux grands mannequins prétendent être bons en mathématiques, Qui a un vrai talent ? Qui a « triché » sur les questions consécutives du test ?
Cette année, quelqu'un a effectué un test complet sur les questions qui viennent d'être publiées pour l'examen final national hongrois de mathématiques
De nombreux modèles ont soudainement "révélé leur forme originale".
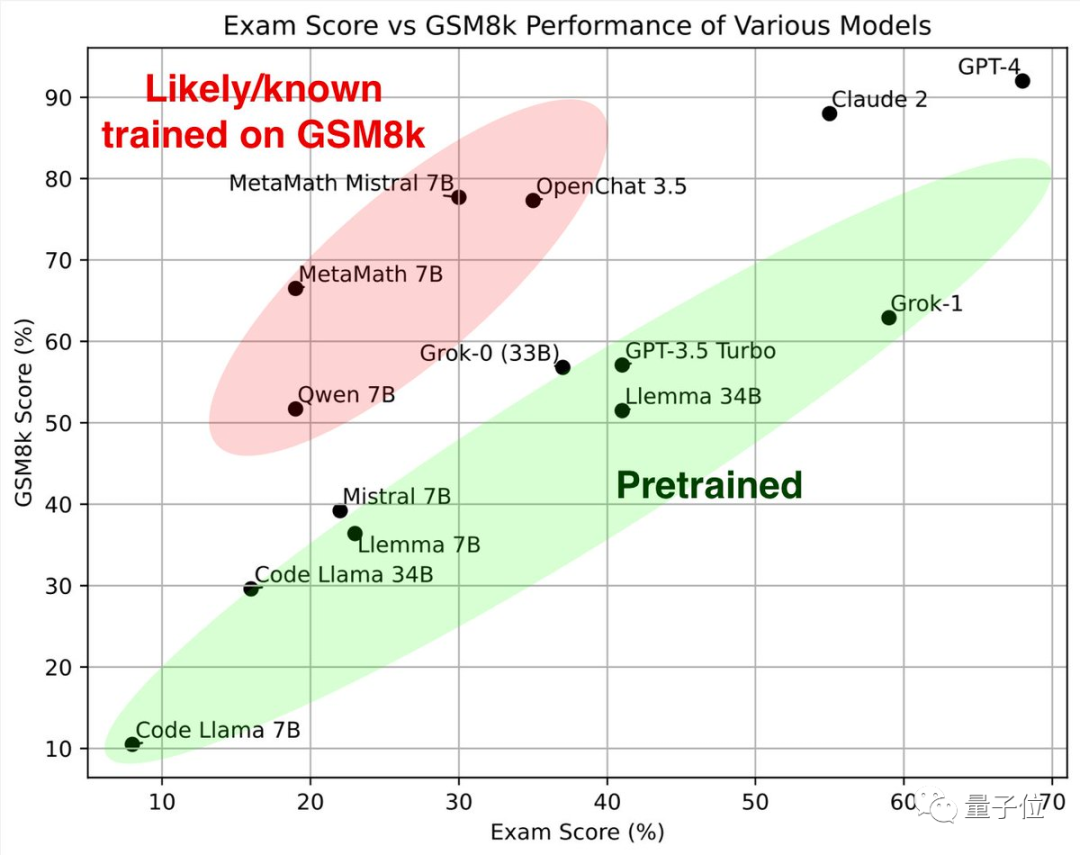
Regardez d'abord la partie verte Ces grands modèles ont des résultats similaires sur l'ensemble de tests de mathématiques classique GSM8k et le nouveau papier, ensemble, ils forment la norme de référence.
En regardant la partie rouge, le score sur GSM8K est nettement supérieur à celui du grand modèle avec la même échelle de paramètres Le score a considérablement baissé sur le nouveau papier, qui est presque le même. comme le grand modèle de la même échelle.
Les chercheurs les ont classés comme "suspectés ou connus pour avoir été formés au GSM8k".
Après avoir regardé ce test, certaines personnes ont dit qu'elles devraient commencer à évaluer des questions qu'elles n'avaient jamais vues auparavant

Certaines personnes pensent que ce type de test et l'expérience réelle de chacun dans l'utilisation de grands modèles sont les seuls actuellement Évaluation fiable méthode
Musk Grok est juste derrière GPT-4, et le Llemma open source a d'excellents résultats
Le testeurKeiran Paster est un doctorant à l'Université de Toronto, un étudiant chercheur de Google et un grand modèle de lemme dans le test de l'un des auteurs.
Laissez le grand mannequin passer l'examen final de mathématiques du lycée national hongrois. Cette astuce vient de Musk's xAI.
Afin d'exclure le problème selon lequel le grand modèle Grok de xAI a accidentellement vu des questions de test dans les données réseau, en plus de plusieurs ensembles de tests courants, ce test a également été effectué
Cet examen n'a été terminé qu'à la fin du mois de mai de cette année. Actuellement, la plupart des modèles n'ont pratiquement jamais eu l'occasion de voir cet ensemble de questions de test.
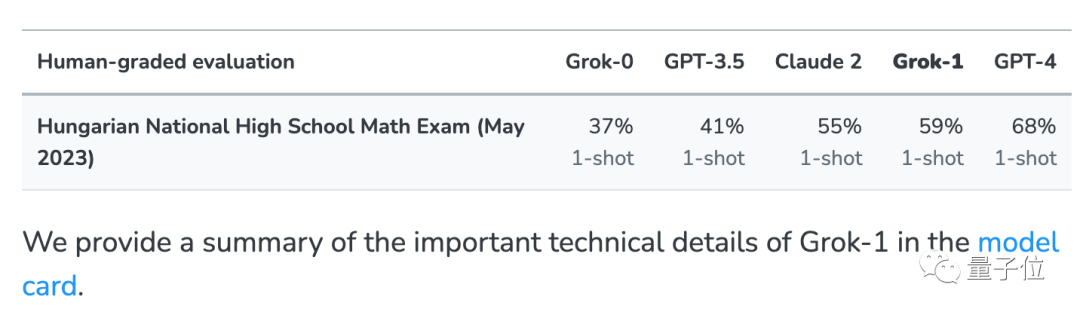
xAI a également annoncé les résultats de GPT-3.5, GPT-4 et Claude 2 lors de sa publication à des fins de comparaison.
Sur la base de cet ensemble de données, Paster a effectué des tests supplémentaires. Les objets de test étaient plusieurs modèles open source avec de fortes capacités de génération mathématique
, et les questions de test, les scripts de test et les résultats de réponse de chaque modèle étaient tous . Il est open source sur Huggingface pour que tout le monde puisse vérifier et tester davantage d'autres modèles.
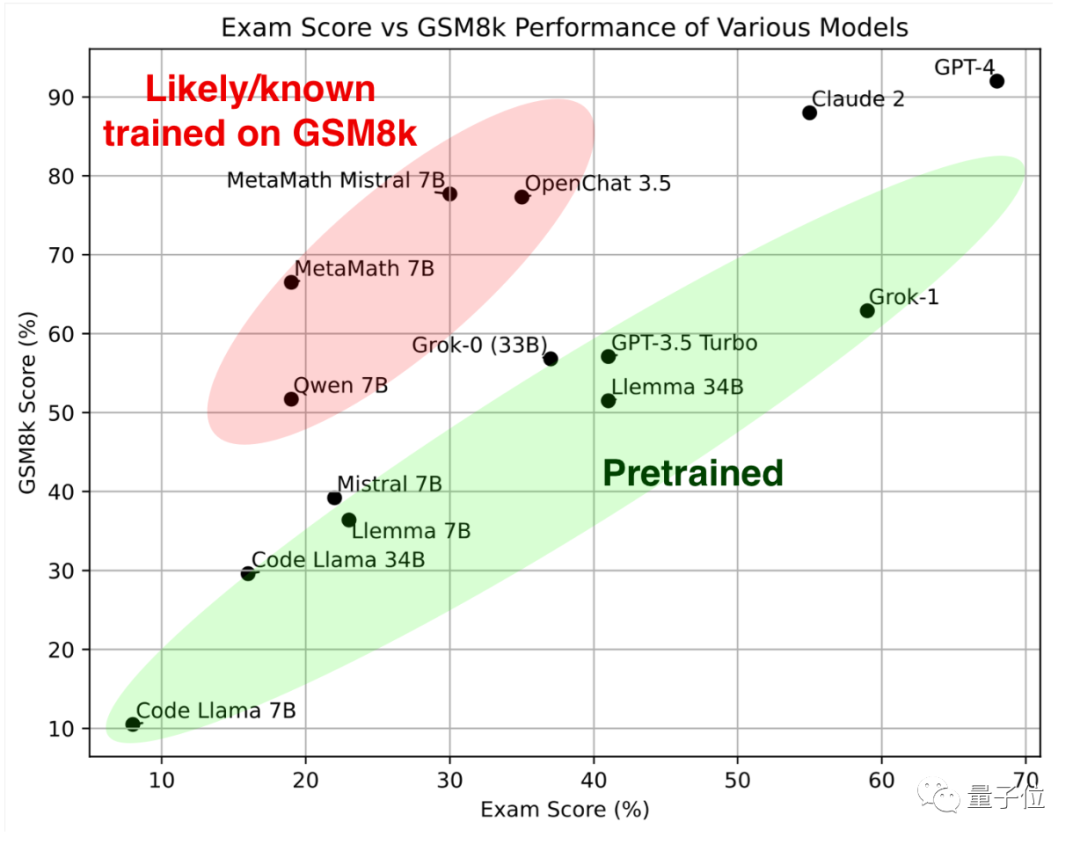
À en juger par les résultats, GPT-4 et Claude-2 forment le premier échelon, avec des résultats très élevés sur GSM8k et le nouveau papier.
Bien que cela ne signifie pas qu'il n'y a pas de questions de fuite GSM8k dans les données d'entraînement de GPT-4 et Claude 2, mais au moins ils ont une bonne capacité de généralisation et peuvent résoudre correctement de nouvelles questions, donc ils s'en moquent.
Ensuite, Grok-0 (33B) et Grok-1 (échelle de paramètres inopinée) de Musk xAI ont tous deux bien fonctionné.
Grok-1 a le score le plus élevé du "groupe des non-tricheurs", et le nouveau score papier est encore plus élevé que Claude 2.
Les performances de Grok-0 sur GSM8k sont proches de GPT3.5-Turbo, et légèrement pires sur le nouveau papier.
À l'exception des modèles fermés mentionnés ci-dessus, les autres modèles du test sont tous open source
La série Code Llama est le propre réglage fin de Meta basé sur Llama 2, axé sur la génération de code basé sur le langage naturel, Regardez maintenant La capacité mathématique est légèrement pire que celle des modèles de la même échelle.

Basé sur Code Llama, de nombreuses universités et instituts de recherche ont lancé conjointement la Série Llemma, et elle a été open source par EleutherAI.
L'équipe a collecté l'ensemble de données Proof-Pile-2 à partir d'articles scientifiques, de données réseau contenant des mathématiques et du code mathématique. Après la formation, Llemma peut utiliser des outils et effectuer des preuves formelles de théorèmes sans aucun réglage supplémentaire.
Sur le nouveau papier, les performances du Llemma 34B sont proches du niveau GPT-3.5 Turbo
La
Mistral series est formée par la licorne française d'IA Mistral AI. L'accord open source Apache2.0 est plus lâche que Llama et est devenu le modèle de base le plus populaire dans la communauté open source après la famille alpaga.
"Overfitting Group" OpenChat 3.5 et MetaMath Mistral sont tous deux affinés sur la base de l'écosystème Mistral.
MetaMath et MAmmoTH Code sont basés sur l'écosystème Code Llama.
Ceux qui choisissent d'adopter de grands modèles open source dans leur activité réelle doivent faire attention à éviter ce groupe, car ils sont susceptibles d'obtenir de bons résultats juste pour gagner des classements, mais leurs capacités réelles peuvent ne pas être aussi fortes que celles d'autres modèles du même type. échelle

Non De nombreux internautes ont exprimé leur gratitude à Paster pour cette expérience, estimant que c'est exactement ce qui est nécessaire pour comprendre la situation réelle du modèle.
Certaines personnes ont exprimé leurs inquiétudes :
À partir de ce jour, tous ceux qui entraînent de grands modèles incluront les questions de l'examen de mathématiques hongrois des années précédentes.
Dans le même temps, il estime que la solution pourrait être d'avoir une société spécialisée dans l'évaluation de grands modèles avec des tests exclusifs.
Une autre proposition consiste à établir un référentiel de test qui est mis à jour d'année en année pour atténuer le problème de surapprentissage.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!