
Maison >Périphériques technologiques >IA >Maîtrisez quatre algorithmes de limitation de courant couramment utilisés et vous réussirez certainement l'entretien
Maîtrisez quatre algorithmes de limitation de courant couramment utilisés et vous réussirez certainement l'entretien

- 王林avant
- 2023-11-15 11:22:111147parcourir

En cas d'accès simultané élevé, comme les promotions du commerce électronique, le trafic continue d'affluer et la fréquence des appels mutuels entre les services augmente soudainement, ce qui rend la charge du système trop élevée. services sur lesquels repose le système L'impact sur le système est très important et de nombreux facteurs incertains provoquent des avalanches, tels que des interruptions de connexion réseau, des temps d'arrêt de service, etc. Généralement, les composants tolérants aux pannes des microservices fournissent une limitation de courant, une isolation, une dégradation, un disjoncteur et d'autres moyens, qui peuvent protéger efficacement notre système de microservices. Cet article parle principalement de limitation de courant.
Limitation de courant signifie limiter le débit maximum pour éviter que la fréquence de fonctionnement ne dépasse la limite définie. La concurrence maximale que le système peut fournir est limitée et il y a trop de demandes en même temps, ce qui nécessite une limitation, comme des ventes flash et des promotions importantes. Lorsqu'un grand nombre de demandes affluent instantanément, le serveur ne peut pas les répondre. il doit donc y avoir une limitation. La limitation de débit protège les services contre une utilisation excessive accidentelle ou malveillante en limitant le nombre de requêtes pouvant atteindre l'API au cours d'une période de temps donnée. Sans limitation de débit, n'importe quel utilisateur peut bombarder votre serveur de requêtes, provoquant une situation où les autres utilisateurs meurent de faim.
Pourquoi limiter la vitesse ?
- Prévenir le manque de ressources : la raison la plus courante de limitation de débit est d'augmenter la disponibilité des services basés sur l'API en évitant le manque de ressources. Si vous appliquez une limitation de débit, vous pouvez empêcher les attaques par déni de service (doS) basées sur la charge. Même si un utilisateur bombarde l'API avec des tonnes de requêtes, les autres utilisateurs ne mourront pas de faim.
- Sécurité : La limitation du débit empêche les attaques par force brute sur les fonctionnalités à forte intensité de sécurité telles que les connexions, les codes promotionnels, etc. Le nombre de requêtes pour ces fonctions est limité au niveau de l'utilisateur, les algorithmes de force brute ne fonctionneront donc pas dans ces scénarios.
- Prévenir les coûts opérationnels : dans le cas d'une mise à l'échelle automatique des ressources dans un modèle de paiement à l'utilisation, la limitation du débit permet de contrôler les coûts opérationnels en plaçant une limite supérieure virtuelle sur l'expansion des ressources. Sans limitation de débit, les ressources peuvent évoluer de manière disproportionnée, entraînant des factures exponentielles.
Politique de limite de taux La limitation de taux peut être appliquée aux paramètres suivants :
- Utilisateurs : Limiter le nombre de requêtes autorisées à un utilisateur dans une période de temps donnée. La limitation de débit basée sur l'utilisateur est l'une des formes de limitation de débit les plus courantes et les plus intuitives.
- Concurrency : Cela limite le nombre de sessions parallèles qu'un utilisateur peut autoriser dans un laps de temps donné. Limiter le nombre de connexions parallèles permet également d'atténuer les attaques DDOS.
- Location/ID : cela permet de lancer des campagnes basées sur la localisation ou axées sur la démographie. Les demandes ne provenant pas du groupe démographique cible peuvent être limitées pour augmenter la disponibilité dans la zone cible
- Serveurs : la limitation du débit basée sur le serveur est une stratégie de niche. Ceci est généralement utilisé lorsqu'un serveur spécifique nécessite la plupart des requêtes, c'est-à-dire que le serveur est fortement couplé à une fonction spécifique
Ensuite, nous présenterons quatre algorithmes courants de limitation de courant
1. L'idée de l'algorithme de seau qui fuit est un algorithme simple et intuitif, qui est un seau qui fuit avec une capacité fixe qui s'écoule des gouttes d'eau à un débit fixe constant. Si le seau est vide, aucune goutte d’eau ne doit s’écouler. De toute façon, l’eau peut s’écouler dans le seau qui fuit. Si la goutte d'eau entrante dépasse la capacité du seau, la goutte d'eau entrante déborde (est jetée), tandis que la capacité du seau qui fuit reste inchangée.
L'avantage de cet algorithme est qu'il lisse la rafale de requêtes et les traite à un rythme constant. Il est également facile à mettre en œuvre sur un équilibreur de charge et est économe en mémoire pour chaque utilisateur. Maintient un trafic constant et quasi uniforme vers le serveur, quel que soit le nombre de requêtes.
L'inconvénient est qu'une explosion de demandes peut remplir le seau, conduisant à une pénurie de nouvelles demandes. Cela ne garantit pas non plus que la demande sera complétée dans un délai donné.
Avantages :
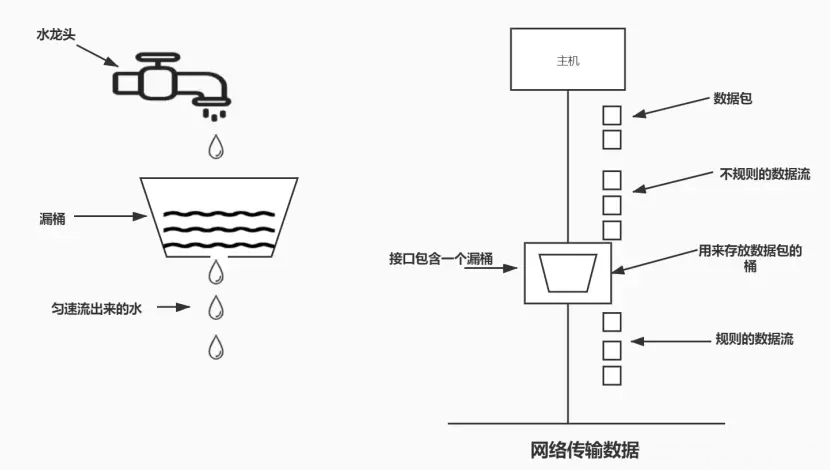
Circulation fluide.
Étant donné que l'algorithme du bucket à fuites traite les demandes à un rythme fixe, il peut efficacement lisser et façonner le trafic et éviter les rafales et les fluctuations du trafic (similaire à l'effet d'écrêtement des pics et de remplissage des vallées des files d'attente de messages).- Evitez les surcharges. Lorsque les requêtes entrantes dépassent la capacité du compartiment, les requêtes peuvent être rejetées directement pour éviter une surcharge du système.
-
Inconvénients :
- Impossible de gérer le trafic en rafale : Étant donné que la vitesse d'exportation du bucket qui fuit est fixe, il ne peut pas gérer le trafic en rafale. Par exemple, les demandes ne peuvent pas être traitées plus rapidement même lorsque le trafic est faible.
- Perte de données possible : Si le trafic d'entrée est trop important et dépasse la capacité du compartiment, certaines requêtes doivent être rejetées. Cela peut poser un problème dans certains scénarios où les demandes manquantes ne peuvent être tolérées.
2. Algorithme de compartiment de jetons
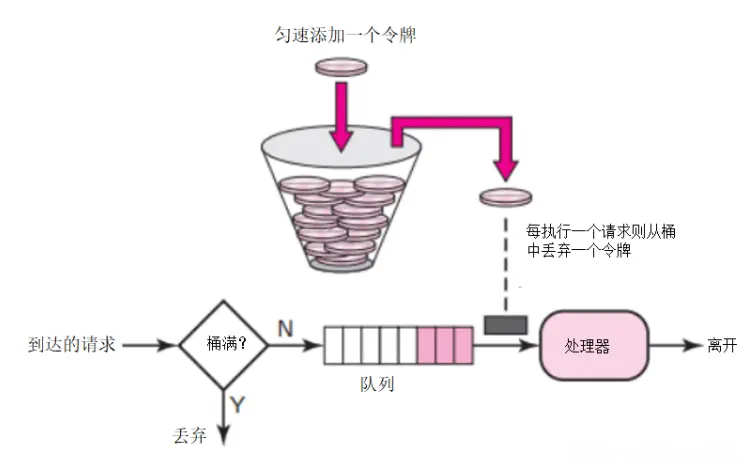
Algorithme de compartiment de jetons : En supposant que la limite est de 2r/s, les jetons sont ajoutés au compartiment à un rythme fixe de 500 millisecondes. Un maximum de b jetons peuvent être stockés dans le compartiment. Lorsque le compartiment est plein, les jetons nouvellement ajoutés sont supprimés ou rejetés. Lorsqu'un paquet de taille n octets arrive, n jetons sont supprimés du compartiment et le paquet est envoyé au réseau. S'il y a moins de n jetons dans le compartiment, le jeton ne sera pas supprimé et le paquet sera limité en débit (soit rejeté, soit mis en mémoire tampon). Le principe de limitation du courant du compartiment à jetons est tel qu'illustré sur la figure.

Le compartiment à jetons du côté du serveur de limitation actuel peut ajuster la vitesse de génération des jetons et la capacité du compartiment en fonction des performances réelles du service et de la période de temps. Lorsque le taux doit être augmenté, le taux de jetons mis dans le seau peut être augmenté sur demande.
Le taux auquel les jetons sont générés est constant, alors qu'il n'y a aucune limite sur le taux auquel les demandes peuvent être faites pour obtenir des jetons. . Cela signifie que face à un trafic important instantané, l'algorithme peut obtenir un grand nombre de jetons en peu de temps, et le processus d'obtention de jetons ne consomme pas beaucoup de ressources
Lorsque chaque nouvelle demande arrive sur le serveur , il sera exécuté Deux opérations :
- Get Tokens : Obtenez le nombre actuel de tokens pour cet utilisateur. Si elle est supérieure à la limite définie, la demande est abandonnée.
- Mise à jour du jeton : Si le jeton obtenu est inférieur à la limite de durée d, acceptez la demande et joignez le jeton.
L'algorithme est économe en mémoire car nous économisons moins de données par utilisateur pour notre application. Le problème ici est que cela peut conduire à des conditions de concurrence dans les environnements distribués. Cela se produit lorsque deux requêtes provenant de deux serveurs d'applications différents tentent d'obtenir le jeton en même temps.
Avantages :
- peut gérer le trafic en rafale : l'algorithme de compartiment de jetons peut gérer le trafic en rafale. Lorsque le bucket est plein, les requêtes peuvent être traitées à vitesse maximale. Ceci est très utile pour les scénarios d’application qui doivent gérer un trafic en rafale.
- Limiter le débit moyen : À long terme, le débit de transfert de données sera limité au débit moyen prédéfini (c'est-à-dire le débit auquel les jetons sont générés).
- Flexibilité : Comparé à l'algorithme du bucket à fuite, l'algorithme du bucket à jetons offre une plus grande flexibilité. Par exemple, la vitesse à laquelle les jetons sont générés peut être ajustée dynamiquement.
Inconvénients :
- Peut provoquer une surcharge : Si les jetons sont générés trop rapidement, cela peut provoquer une grande quantité de trafic en rafale, ce qui peut surcharger le réseau ou le service.
- Nécessite un espace de stockage : Le compartiment à jetons nécessite une certaine quantité d'espace de stockage pour enregistrer les jetons, ce qui peut entraîner un gaspillage de ressources mémoire.
- La mise en œuvre est légèrement compliquée : Par rapport à l'algorithme du compteur, la mise en œuvre de l'algorithme du compartiment à jetons est légèrement plus compliquée.
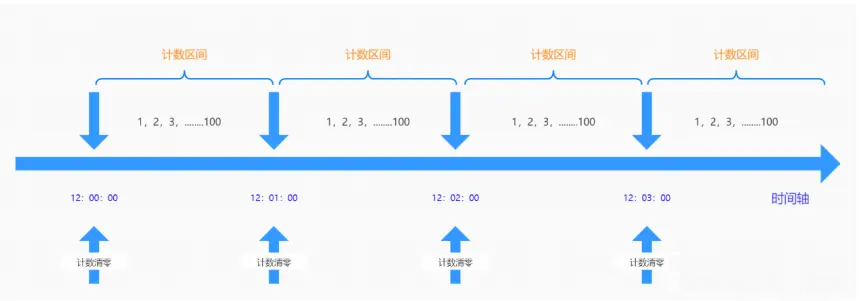
3. L'algorithme de fenêtre de temps fixe
permet d'entrer un certain nombre de requêtes dans une fenêtre de temps fixe. Si la quantité est dépassée, elle sera rejetée ou mise en file d'attente pour attendre la période suivante. Cette limitation à contre-courant est mise en œuvre par une limitation dans un intervalle de temps. Si l'utilisateur envoie une requête avant la fin de l'intervalle précédent (mais ne dépasse pas la limite) et envoie également une requête au début de l'intervalle en cours (ne dépasse pas non plus la limite), alors ces requêtes seront normales pour leur intervalles respectifs. Cependant, lorsque les requêtes dépassent les limites du système pendant des périodes critiques, cela peut provoquer une surcharge du système
En raison du défaut de point critique de temps de l'algorithme du compteur, il est vulnérable aux attaques dans un laps de temps très court autour du point critique de temps. Par exemple, il est configuré pour demander une certaine interface jusqu'à 100 fois par minute. Par exemple, il n'y a pas de demande de données entre 12:00:00 et 12:00:59, mais il y a une demande simultanée soudaine. la période de 12:00:59 à 12:01:00, puis en entrant dans le cycle de comptage suivant, le compteur est effacé et il y a 100 demandes entre 12:01:00 et 12:01:01. En d'autres termes, au moment critique, il peut y avoir deux fois plus de requêtes que le seuil en même temps, provoquant une surcharge de requêtes de traitement en arrière-plan, entraînant des capacités de fonctionnement insuffisantes du système, voire provoquant un crash du système.
Inconvénients :
- La limite actuelle n'est pas assez fluide. Par exemple : la limite actuelle est de 3 par seconde, et 3 requêtes sont envoyées dans la première milliseconde. Si la limite actuelle est atteinte, toutes les requêtes pour le temps restant de la fenêtre seront rejetées, ce qui entraînera une mauvaise expérience.
- Impossible de gérer les problèmes de bordure de fenêtre. Étant donné que le contrôle de flux est effectué dans une certaine fenêtre temporelle, un effet de limite de fenêtre peut se produire, c'est-à-dire qu'un grand nombre de requêtes peuvent être autorisées à passer à la limite de la fenêtre temporelle, ce qui entraîne un trafic en rafale.
Par exemple : la limite actuelle est de 3 par seconde, 3 requêtes sont envoyées dans la dernière milliseconde de la première seconde et 3 requêtes sont envoyées dans la première milliseconde de la deuxième seconde. Six demandes ont été traitées dans ces deux millimètres, mais la limite actuelle n'a pas été déclenchée. S'il y a une explosion de trafic, cela peut submerger le serveur.
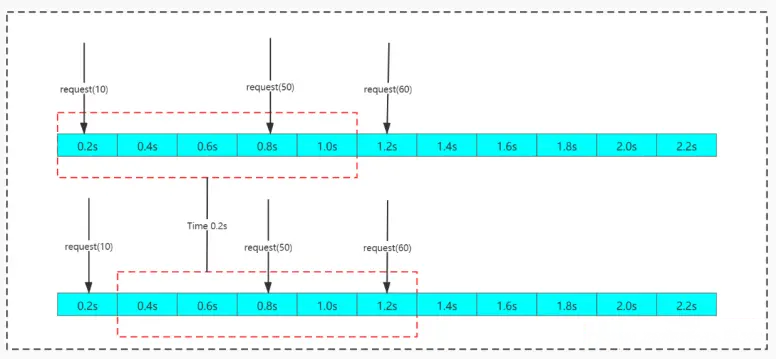
4. Algorithme de fenêtre temporelle glissante
L'algorithme de fenêtre coulissante divise une période de temps fixe et la déplace avec le temps. La méthode de mouvement consiste à ce que le point temporel de départ devienne le deuxième point temporel dans la liste de temps et le point temporel final. un point temporel et le répéter continuellement peut intelligemment éviter le problème du point critique du compteur.
L'algorithme de fenêtre glissante peut efficacement éviter le problème du point critique de temps dans l'algorithme du compteur, mais il existe toujours le concept de segments temporels. Dans le même temps, l'opération de comptage de l'algorithme à fenêtre glissante prend également plus de temps que l'algorithme à fenêtre temporelle fixe.
Inconvénients : Il y a toujours un problème : la limite actuelle n'est pas assez fluide. Par exemple : la limite actuelle est de 3 par seconde et 3 requêtes sont envoyées dans la première milliseconde. Si la limite actuelle est atteinte, toutes les requêtes dans la fenêtre de temps restante seront rejetées, ce qui entraînera une mauvaise expérience.
Résumé
Introduit quatre algorithmes de limitation de courant couramment utilisés : l'algorithme de fenêtre fixe, l'algorithme de fenêtre glissante, l'algorithme de seau à fuite et l'algorithme de seau à jetons. Chaque algorithme a ses propres caractéristiques et scénarios applicables. Résumons-les brièvement et comparons-les ci-dessous.
- Token Bucket Algorithm peut à la fois fluidifier le trafic et gérer le trafic en rafale, et convient aux scénarios dans lesquels le trafic en rafale doit être traité. L'avantage de l'
- Leaky Bucket Algorithm est que le traitement du trafic est plus fluide, mais il ne peut pas faire face à un trafic en rafale et convient aux scénarios qui nécessitent un trafic fluide.
- L'algorithme de fenêtre fixe est simple à mettre en œuvre, mais la limite actuelle n'est pas assez fluide et présente des problèmes de limite de fenêtre. Il convient aux scénarios qui nécessitent une mise en œuvre simple de la limite actuelle.
- L'algorithme de fenêtre coulissante résout le problème des limites de fenêtre, mais il reste toujours le problème de la fluidité insuffisante de la limitation de courant. Il convient aux scénarios où le taux de demande moyen doit être contrôlé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- PHP utilise un algorithme de compartiment à jetons pour implémenter un contrôle de flux basé sur Redis
- Comment implémenter l'algorithme du bucket de jetons en utilisant php
- Comment implémenter l'algorithme du token bucket à l'aide de Redis ? (avec code)
- Quels sont les algorithmes de limitation de courant courants en Java ?
- Explication détaillée de l'implémentation Redis de l'algorithme de limitation de courant