
Maison >Périphériques technologiques >IA >La prévision des bénéfices n'est plus difficile, la méthode de régression linéaire scikit-learn vous permet d'obtenir deux fois le résultat avec la moitié de l'effort
La prévision des bénéfices n'est plus difficile, la méthode de régression linéaire scikit-learn vous permet d'obtenir deux fois le résultat avec la moitié de l'effort

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-13 20:25:291086parcourir
1. Introduction
L'intelligence artificielle générative est sans aucun doute une technologie qui change la donne, mais pour la plupart des problèmes commerciaux, les modèles d'apprentissage automatique traditionnels tels que la régression et la classification restent le premier choix.
Contenu réécrit : imaginez comment des investisseurs tels que le capital-investissement ou le capital-risque peuvent tirer parti de l'apprentissage automatique. Pour répondre à cette question, vous devez d’abord comprendre quelles données intéressent les investisseurs et comment elles sont utilisées. Les décisions d'investissement dans les entreprises reposent non seulement sur des données quantifiables telles que les dépenses, la croissance et les taux de consommation de trésorerie, mais également sur des données qualitatives telles que les dossiers des fondateurs, les commentaires des clients et l'expérience produit.
Cet article présentera les bases de la régression linéaire, qui peut être trouvé sur Trouvez le code complet ici.
Le contenu qui doit être réécrit est : [Code] : https://github.com/RoyiHD/linear-regression
2 Paramètres du projet
Cet article utilisera Jupyter Notebook pour ce projet. Importez d’abord quelques bibliothèques.
Importer une bibliothèque
# 绘制图表import matplotlib.pyplot as plt# 数据管理和处理from pandas import DataFrame# 绘制热力图import seaborn as sns# 分析from sklearn.metrics import r2_score# 用于训练和测试的数据管理from sklearn.model_selection import train_test_split# 导入线性模型from sklearn.linear_model import LinearRegression# 代码注释from typing import List
3. Données
Pour simplifier le problème, cet article utilisera des données régionales. Les données représentent les catégories de dépenses et les bénéfices de l'entreprise. Vous pouvez voir quelques exemples de différents points de données. Cet article espère utiliser les données de dépenses pour former un modèle de régression linéaire et prédire les bénéfices.
Il est important de comprendre que les données décrites dans cet article concernent les dépenses d’une entreprise. Une puissance de prévision significative n'est possible que lorsque les données des dépenses sont combinées avec des données telles que la croissance des revenus, les taxes locales, l'amortissement et les conditions du marché Marketing
Le contenu qui doit être réécrit est : 165349.2 |
136897.8 |
Le le contenu qui doit être réécrit est : 471784.1 |
Le contenu à réécrire est : 192261.83 |
162597.7 |
Le contenu à réécrire est : 151377.59 | 4 43898.53 |
191792.06 |
153441.51 |
101145.55 |
Ce qui doit être réécrit est : 407934.54 |
Ce qui doit être réécrit est : 1 91050.39 |
加载数据
companies: DataFrame = pd.read_csv("companies.csv", header = 0)
4、数据可视化
了解数据对于确定要使用的特征、需要进行归一化和转换的特征、从数据中删除异常值以及对特定数据点进行的处理是很重要的。
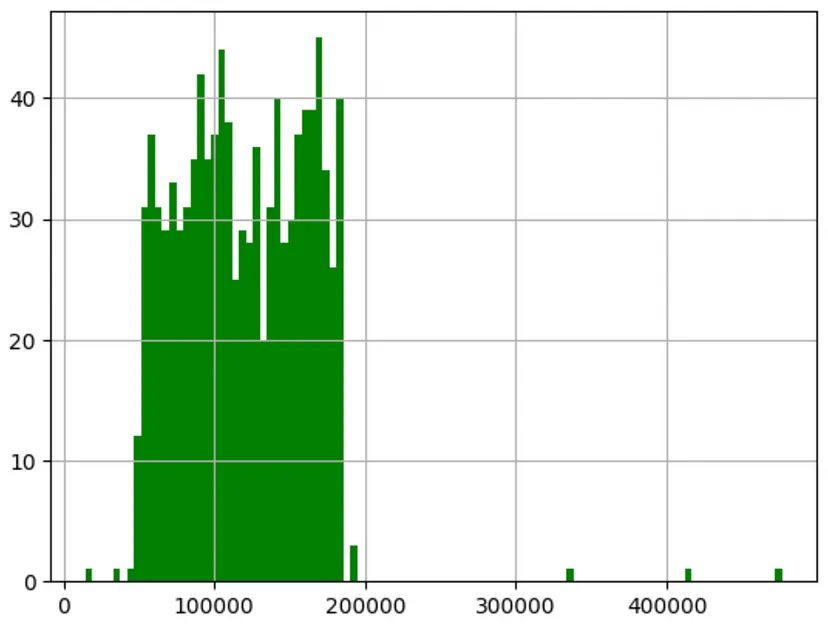
目标(利润)直方图
可以直接使用DataFrame绘制直方图(Pandas使用Matplotlib来绘制数据帧),可以直接访问利润并绘制它。
companies['Profit'].hist( color='g', bins=100);
 图片
图片
从数据中可以清楚地看出,利润超过20万美元的异常值非常罕见。这表明本文所涉及的数据代表的是规模较大的公司。鉴于异常值数量较少,可以将其保留
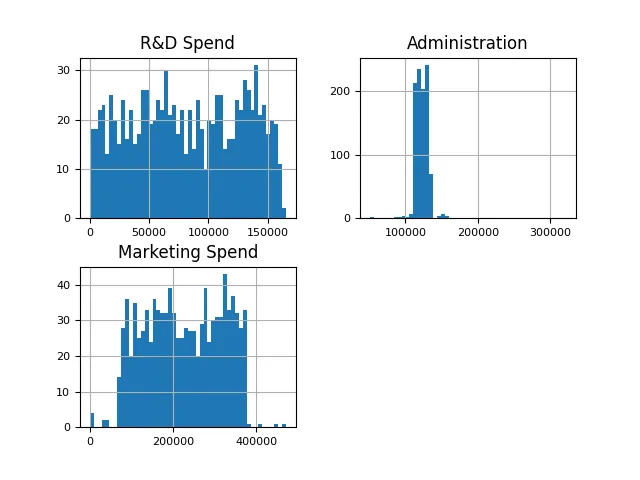
特征(支出)直方图
在这里,本文旨在使用特征的直方图,并观察其分布情况。Y轴表示数字频率,X轴表示支出
companies[["R&D Spend", "行政管理", "Marketing Spend"]].hist(figsize=(16, 20), bins=50, xlabelsize=8, ylabelsize=8)
 图片
图片
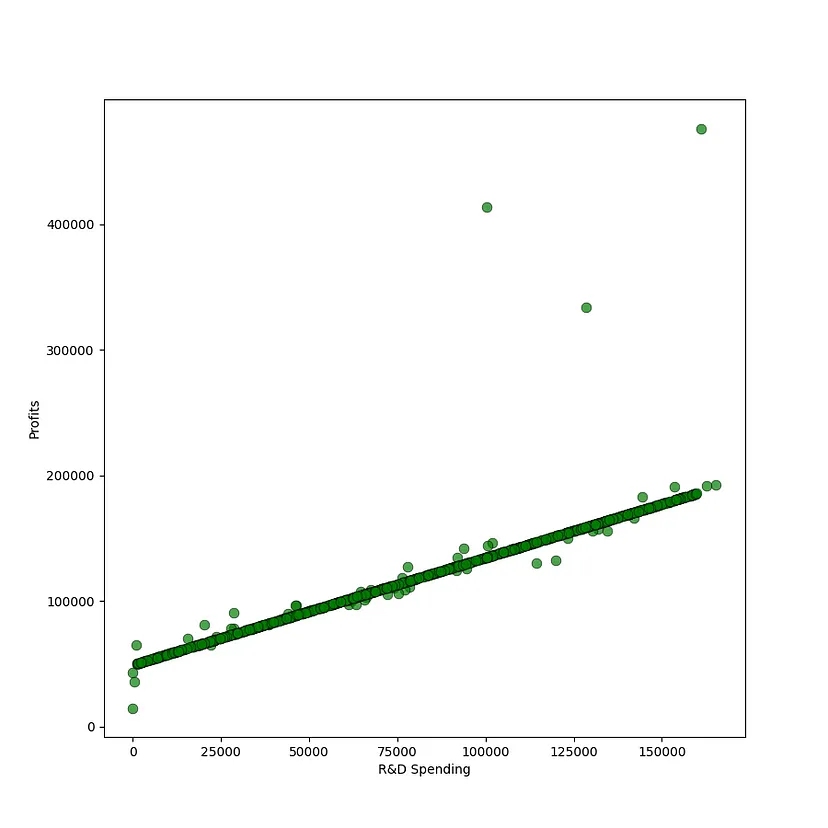
可以观察到一个健康的分布,只有很少的异常值。根据直觉,可以预期投入更多资金在研发和市场营销上的公司会获得更高的利润。从下面的散点图中可以看出,研发支出和利润之间存在明显的相关性
profits: DataFrame = companies[["Profit"]]research_and_development_spending: DataFrame = companies[["R&D Spend"]]figure, ax = plt.subplots(figsize = (9, 9))plt.xlabel("R&D Spending")plt.ylabel("Profits")ax.scatter(research_and_development_spending, profits, s=60, alpha=0.7, edgecolors="k",color='g',linewidths=0.5)
 图片
图片
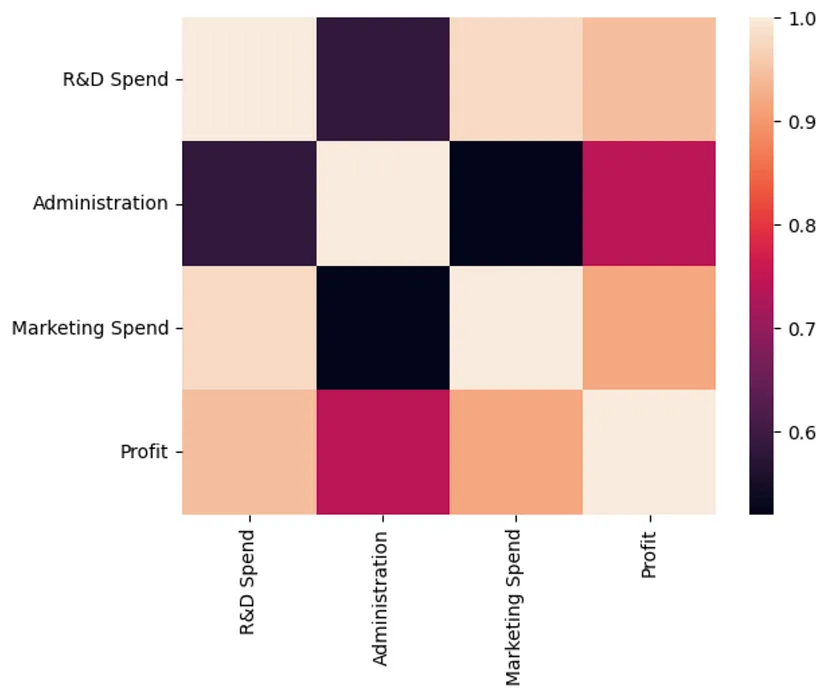
可以使用相关的热图来进一步探索支出和利润之间的关系。从图中可以观察到研发和市场营销支出与利润之间的相关性比行政支出更高
sns.heatmap(companies.corr())
 图片
图片
5、模型训练
首先需要将数据集分割为训练集和测试集两部分。Sklearn提供了一个辅助方法来完成这个任务。鉴于本文的数据集很简单且足够小,可以按照以下方式将特征和目标分离开来。
数据集
features: DataFrame = companies[["R&D Spend", "行政管理", "Marketing Spend",]]targets: DataFrame = companies[["Profit"]]train_features, test_features, train_targets, test_targets = train_test_split(features, targets,test_size=0.2)
大多数数据科学家会使用不同的命名约定,如X_train、y_train或其他类似的变体。
模型训练
现在可以创建并训练模型了。Sklearn使事情变得非常简单。
model: LinearRegression = LinearRegression()model.fit(train_features, train_targets)
6、模型评估
本文希望对模型的性能及其可用性进行评估。首先查看一下计算得到的系数。在机器学习中,系数是用来与每个特征相乘的学习到的权重或数值。期望看到每个特征都有一个学习系数。
coefficients = model.coef_"""We should see the following in our consoleCoefficients[[0.55664299 1.08398919 0.07529883]]"""
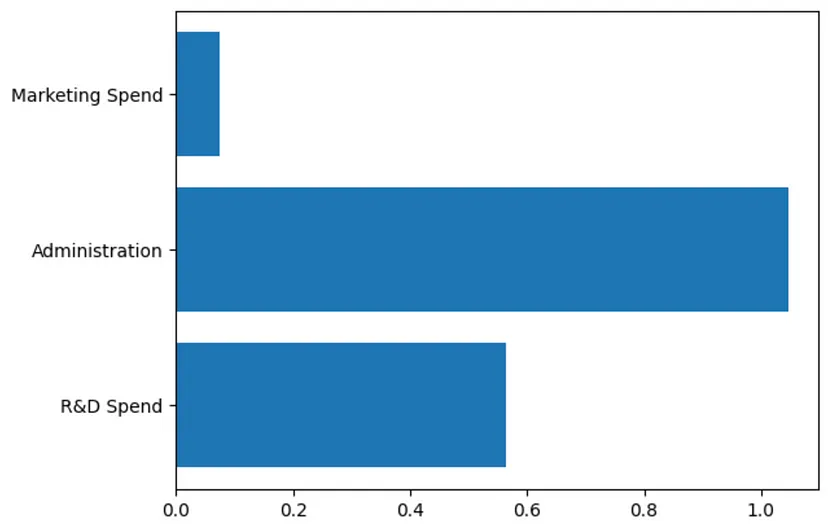
正如上述所看到的,有3个系数,每个特征对应一个系数(“研发支出”、“行政支出”、“市场营销支出”)。还可以将其绘制成图表,以便更直观地了解每个系数。
plt.figure()plt.barh(train_features.columns, coefficients[0])plt.show()
 图片
图片
计算误差
希望了解模型的误差率,我们将使用Sklearn的R2得分
test_predictions: List[float] = model.predict(test_features)root_squared_error: float = r2_score(test_targets, test_predictions)"""floatWe should see an ouput similar to this0.9781424529214315"""
离1越近,模型就越准确。实际上可以用一种非常简单的方式对这一点进行测试。
使用下面的支出模型来预测利润,并希望得到一个接近192261美元的数字,可以提取数据集的第一行
"R&D Spend" |"行政管理" |"Marketing Spend" | "Profit"需要进行重写的内容是:165349.2 136897.8需要重写的内容是:471784.1需要改写的内容是:192261.83
接下来创建一个推理请求。
inference_request: DataFrame = pd.DataFrame([{"R&D Spend":需要进行重写的内容是:165349.2, "行政管理":136897.8, "Marketing Spend":需要重写的内容是:471784.1 }])
运行模型。
inference: float = model.predict(inference_request)"""We should get a number that is around199739.88721901"""
现在可以看到的误差率是abs(199739-192261)/192261=0.0388。这是非常准确的。
7、结论
处理数据、搭建模型和分析数据有很多方法。没有一种解决方案适用于所有情况,当用机器学习解决业务问题时,其中一个关键过程是搭建多个旨在解决同一个问题的模型,并选择最有前途的模型
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!