
Maison >Périphériques technologiques >IA >Alignement précis des fonctionnalités pour améliorer la détection d'objets 3D multimodaux : application de GraphAlign
Alignement précis des fonctionnalités pour améliorer la détection d'objets 3D multimodaux : application de GraphAlign

- 王林avant
- 2023-10-27 11:17:041081parcourir
Titre original : GraphAlign : Enhancing Accurate Feature Alignment by Graph matching for Multi-Modal 3D Object Detection
Le contenu qui doit être réécrit est : Lien papier : https://arxiv.org/pdf/2310.08261.pdf
Auteur affiliation : Université Jiaotong de Pékin Université des sciences et technologies du Hebei Université Tsinghua

Idée de thèse :
Le LiDAR et les caméras sont des capteurs complémentaires pour la détection de cibles 3D en conduite autonome. Cependant, l’étude des interactions non naturelles entre les nuages de points et les images est un défi, et la clé réside dans la manière d’effectuer l’alignement des caractéristiques de modalités hétérogènes. Actuellement, de nombreuses méthodes parviennent uniquement à l'alignement des caractéristiques via l'étalonnage de la projection et ignorent le problème des erreurs de précision de conversion des coordonnées entre les capteurs, ce qui entraîne des performances sous-optimales. Cet article propose une stratégie d'alignement de caractéristiques plus précise appelée GraphAlign pour la détection d'objets 3D via la correspondance de graphiques. Plus précisément, cet article fusionne les caractéristiques d'image de l'encodeur de segmentation sémantique dans la branche image avec les caractéristiques de nuage de points du CNN clairsemé 3D dans la branche LiDAR. Afin de réduire la quantité de calcul, cet article utilise le calcul de la distance euclidienne pour construire la relation de voisin le plus proche dans le sous-espace des entités de nuage de points. Grâce à l'étalonnage de la projection entre l'image et le nuage de points, les voisins les plus proches des entités du nuage de points sont projetés sur les entités de l'image. Nous recherchons ensuite un alignement de caractéristiques plus approprié en faisant correspondre le voisin le plus proche d'un seul nuage de points à plusieurs images. En outre, cet article fournit également un module d'auto-attention pour renforcer le poids des relations importantes afin d'affiner l'alignement des caractéristiques entre des modalités hétérogènes. Un grand nombre d'expériences ont été menées dans le benchmark nuScenes pour prouver l'efficacité et l'efficience de GraphAlign proposé dans cet article
Principales contributions :
Cet article propose GraphAlign, un framework d'alignement de fonctionnalités basé sur la correspondance de graphes (graph matching) , pour résoudre le problème de désalignement dans la détection d'objets 3D multimodaux.
Cet article propose des modules d'alignement de caractéristiques graphiques (GFA) et d'alignement de caractéristiques d'auto-attention (SAFA) pour obtenir un alignement précis des caractéristiques de l'image et des caractéristiques des nuages de points, ce qui peut améliorer davantage les nuages de points et l'alignement des caractéristiques entre les modalités d'image, améliorant ainsi la précision de détection. .
En menant des expériences en utilisant deux benchmarks, KITTI et nuScenes, nous prouvons que GraphAlign peut améliorer efficacement la précision de la détection des nuages de points, en particulier dans la détection de cibles à longue distance
Conception du réseau :
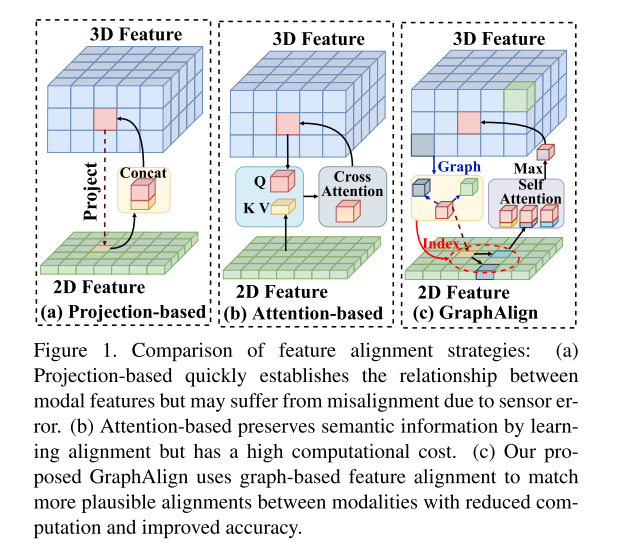
Figure 1. Caractéristiques Comparaison des stratégies d'alignement
(a) Les méthodes basées sur la projection peuvent établir rapidement des relations entre les caractéristiques modales, mais peuvent souffrir d'un désalignement dû à des erreurs de capteur. (b) Les méthodes basées sur l'attention préservent les informations sémantiques en apprenant l'alignement, mais sont coûteuses en termes de calcul. (c) GraphAlign proposé dans cet article utilise l'alignement de caractéristiques basé sur un graphique pour faire correspondre des alignements plus raisonnables entre les modalités, réduisant ainsi l'effort de calcul et améliorant la précision.
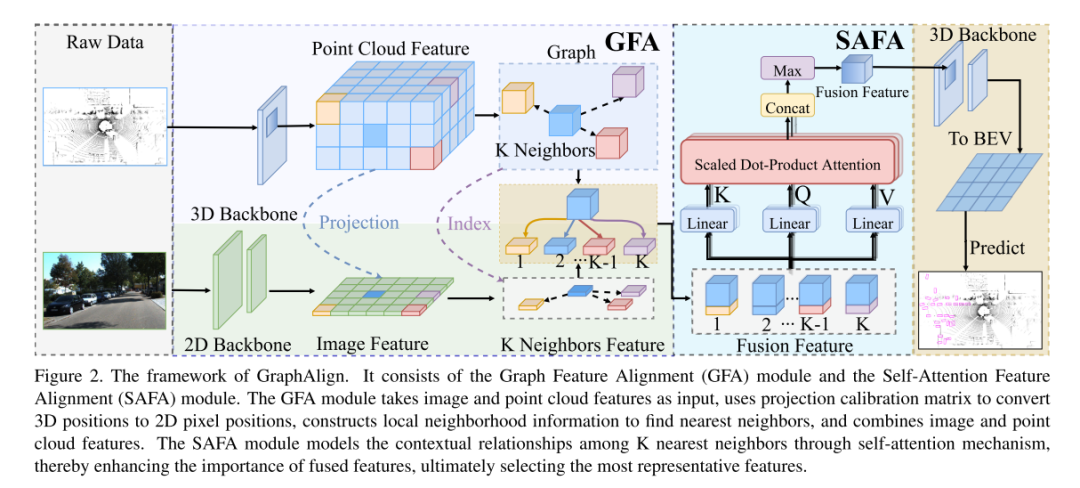
Figure 2. Le framework de GraphAlign.
Réécrit en chinois comme suit : il se compose du module d'alignement des fonctionnalités graphiques (GFA) et du module d'alignement des fonctionnalités d'auto-attention (SAFA). Le module GFA reçoit des caractéristiques d'image et de nuage de points en entrée, utilise une matrice d'étalonnage de projection pour convertir les positions 3D en positions de pixels 2D, génère des informations sur le quartier local pour trouver les voisins les plus proches et combine les caractéristiques d'image et de nuage de points. Le module SAFA modélise la relation contextuelle entre les K voisins les plus proches via le mécanisme d'auto-attention pour améliorer l'importance des caractéristiques fusionnées, et sélectionne enfin les caractéristiques les plus représentatives
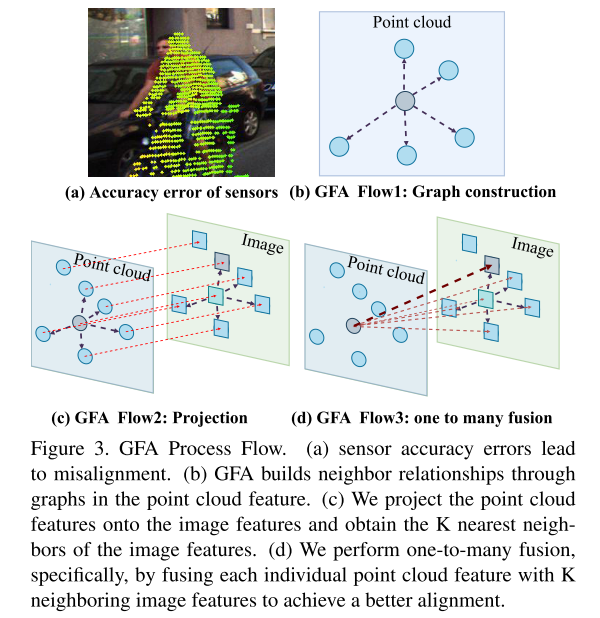
Figure 3. Flux de traitement GFA
( a) Précision du capteur erreur provoquant un désalignement. (b) GFA établit des relations de proximité au moyen de graphiques dans des entités de nuages de points. (c) Cet article projette les caractéristiques du nuage de points sur les caractéristiques de l'image et obtient les K voisins les plus proches des caractéristiques de l'image. (d) Cet article effectue une fusion un-à-plusieurs, en particulier en fusionnant chaque caractéristique de nuage de points individuel avec K caractéristiques d'image voisines pour obtenir un meilleur alignement.
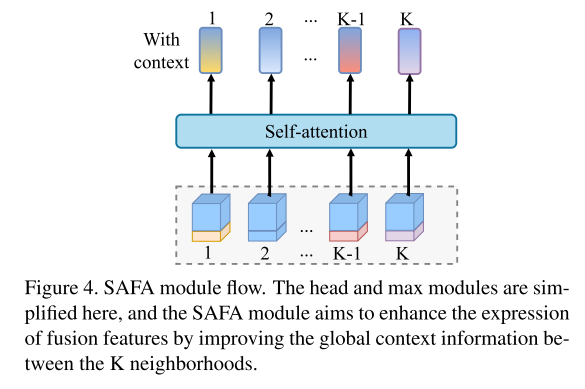
Figure 4. Processus du module SAFA
Nous avons simplifié les modules head et max. Le but du module SAFA est d'améliorer les informations de contexte global entre K voisins pour améliorer la représentation des fonctionnalités fusionnées


Résultats expérimentaux :
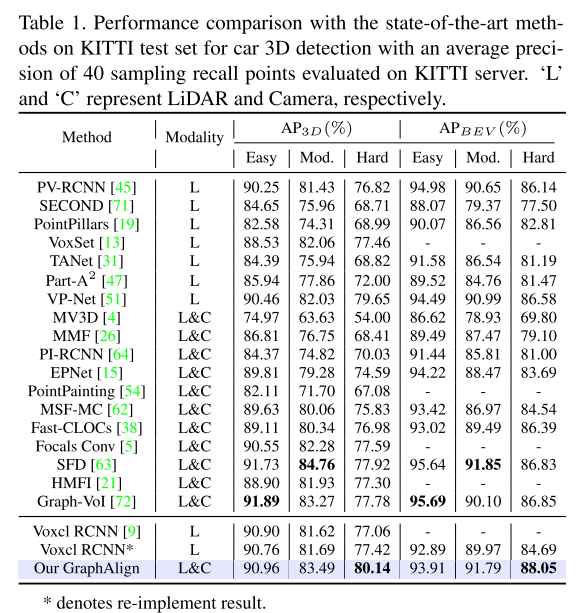
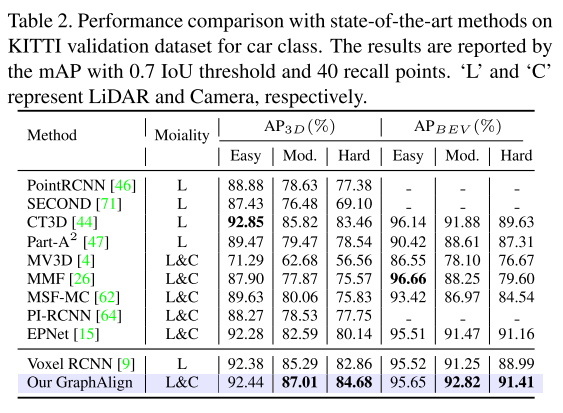
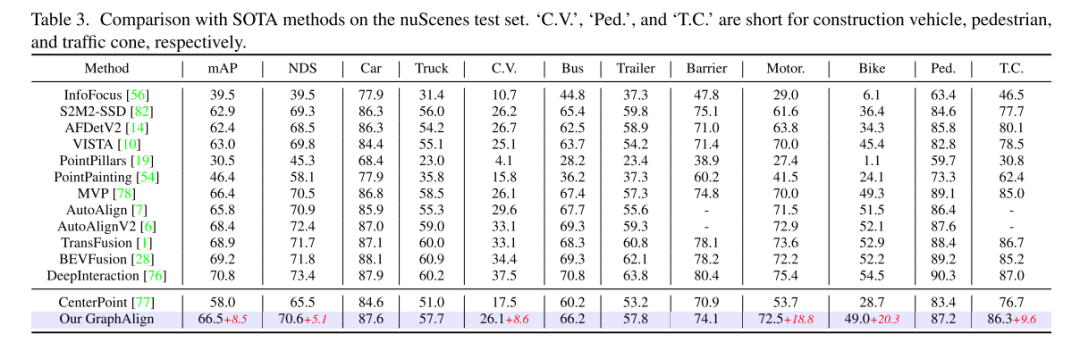
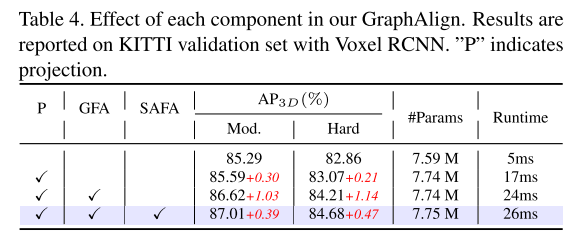



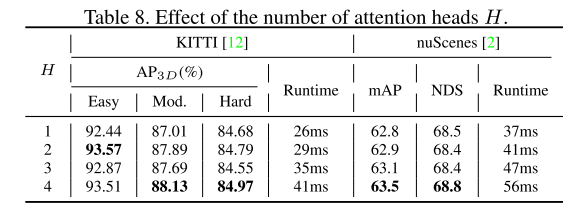
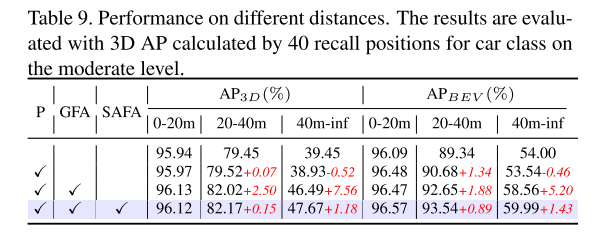
Citation :
Chanson, Z., Wei , H., Bai, L., Yang, L. et Jia, C. (2023). GraphAlign : Amélioration de l'alignement précis des fonctionnalités grâce à la correspondance graphique pour la détection d'objets 3D multimodaux. /abs/2310.08261
.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!