
Maison >Périphériques technologiques >IA >Le modèle de diffusion façon « matriochka » d'Apple réduit le nombre d'étapes d'entraînement de 70 % !
Le modèle de diffusion façon « matriochka » d'Apple réduit le nombre d'étapes d'entraînement de 70 % !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-10-25 14:13:01982parcourir
Une dernière recherche menée par Apple a considérablement amélioré les performances des modèles de diffusion sur les images haute résolution.
Grâce à cette méthode, le nombre d'étapes de formation pour des images de même résolution est réduit de plus de 70 %.
À la résolution de 1024 × 1024, la qualité d'image est directement complète et les détails sont clairement visibles.

Apple a nommé cette réalisation MDM, DM est l'abréviation de Diffusion Model, et le premier M signifie Matryoshka.
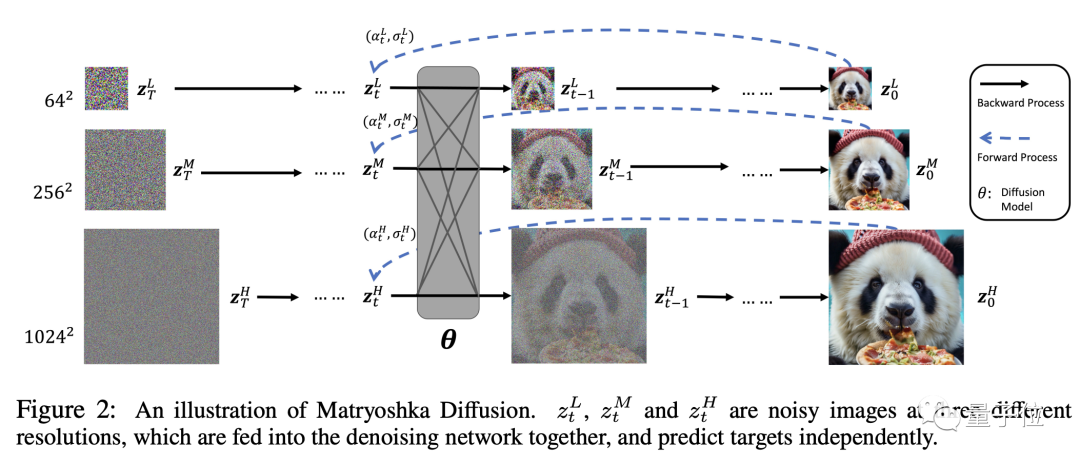
Tout comme une vraie poupée matriochka, MDM imbrique un processus basse résolution dans un processus haute résolution, et il est imbriqué dans plusieurs couches.
Les processus de diffusion haute et basse résolution sont effectués simultanément, ce qui réduit considérablement la consommation de ressources du modèle de diffusion traditionnel dans le processus haute résolution.

Pour une image de résolution 256×256, dans un environnement avec une taille de lot de 1024, le modèle de diffusion traditionnel nécessite 1,5 million d'étapes de formation, tandis que le MDM ne nécessite que 390 000 étapes, soit une réduction de plus de 70 % .
De plus, MDM utilise une formation de bout en bout et ne s'appuie pas sur des ensembles de données spécifiques ni sur des modèles pré-entraînés. Il améliore la vitesse tout en garantissant la qualité de la génération et est flexible à utiliser.

Non seulement vous pouvez dessiner des images haute résolution, mais vous pouvez également synthétiser des vidéos 16×256².

Certains internautes ont commenté qu'Apple avait enfin connecté le texte aux images.
Alors, comment fonctionne exactement la technologie « matriochka » de MDM ?
Combinant global et progressif
Avant de commencer la formation, les données doivent être prétraitées. Les images haute résolution seront rééchantillonnées à l'aide d'un certain algorithme pour obtenir des versions de différentes résolutions.
Ensuite, nous utilisons ces données de différentes résolutions pour une modélisation UNet conjointe. Le petit UNet gère la basse résolution et est imbriqué dans le grand UNet qui gère la haute résolution.
Grâce à des connexions à résolution croisée, les fonctionnalités et les paramètres peuvent être partagés entre des UNets de différentes tailles.

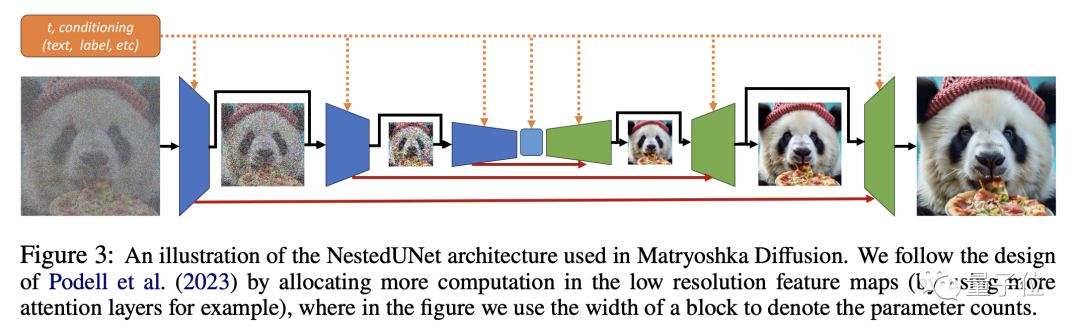
La formation MDM est un processus étape par étape.
Bien que la modélisation soit réalisée conjointement, le processus de formation ne sera pas effectué au début en haute résolution, mais s'étendra progressivement à partir de la basse résolution.
Cela peut éviter une énorme quantité de calculs et permet également la pré-formation de UNet basse résolution pour accélérer le processus de formation haute résolution.
Pendant le processus de formation, des données de formation à plus haute résolution seront progressivement ajoutées au processus global, permettant au modèle de s'adapter à la résolution progressivement croissante et de passer en douceur au processus final à haute résolution.
Cependant, dans l'ensemble, une fois le processus haute résolution ajouté progressivement, la formation MDM reste un processus conjoint de bout en bout.
Dans un entraînement conjoint à différentes résolutions, les fonctions de perte à plusieurs résolutions participent ensemble aux mises à jour des paramètres, évitant ainsi l'accumulation d'erreurs causées par un entraînement en plusieurs étapes.
Chaque résolution a une perte de reconstruction correspondante de l'élément de données. Les pertes de différentes résolutions sont pondérées et fusionnées afin de garantir la qualité de la génération, la perte basse résolution a un poids plus important.
En phase d'inférence, MDM adopte également une stratégie qui allie parallélisme et progression.
De plus, MDM utilise également un modèle de classification d'images (CFG) pré-entraîné pour guider l'optimisation des échantillons générés dans une direction plus raisonnable, et ajoute du bruit aux échantillons basse résolution pour les rapprocher de la distribution des échantillons haute résolution. des échantillons.
Alors, quel est l’effet du MDM ?
Moins de paramètres rivalisent avec SOTA
En termes d'images, sur les ensembles de données ImageNet et CC12M, les performances FID de MDM (plus la valeur est faible, meilleur est l'effet) et CLIP sont nettement meilleures que le modèle de diffusion ordinaire.
Parmi eux, FID est utilisé pour évaluer la qualité de l'image elle-même, et CLIP illustre le degré de correspondance entre l'image et les instructions textuelles.
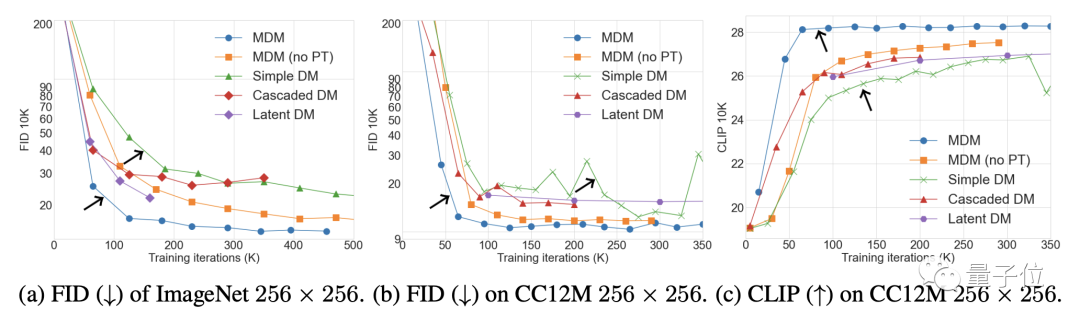
Par rapport aux modèles SOTA tels que DALL E et IMAGEN, les performances du MDM sont également très proches, mais les paramètres de formation du MDM sont bien inférieurs à ceux de ces modèles.
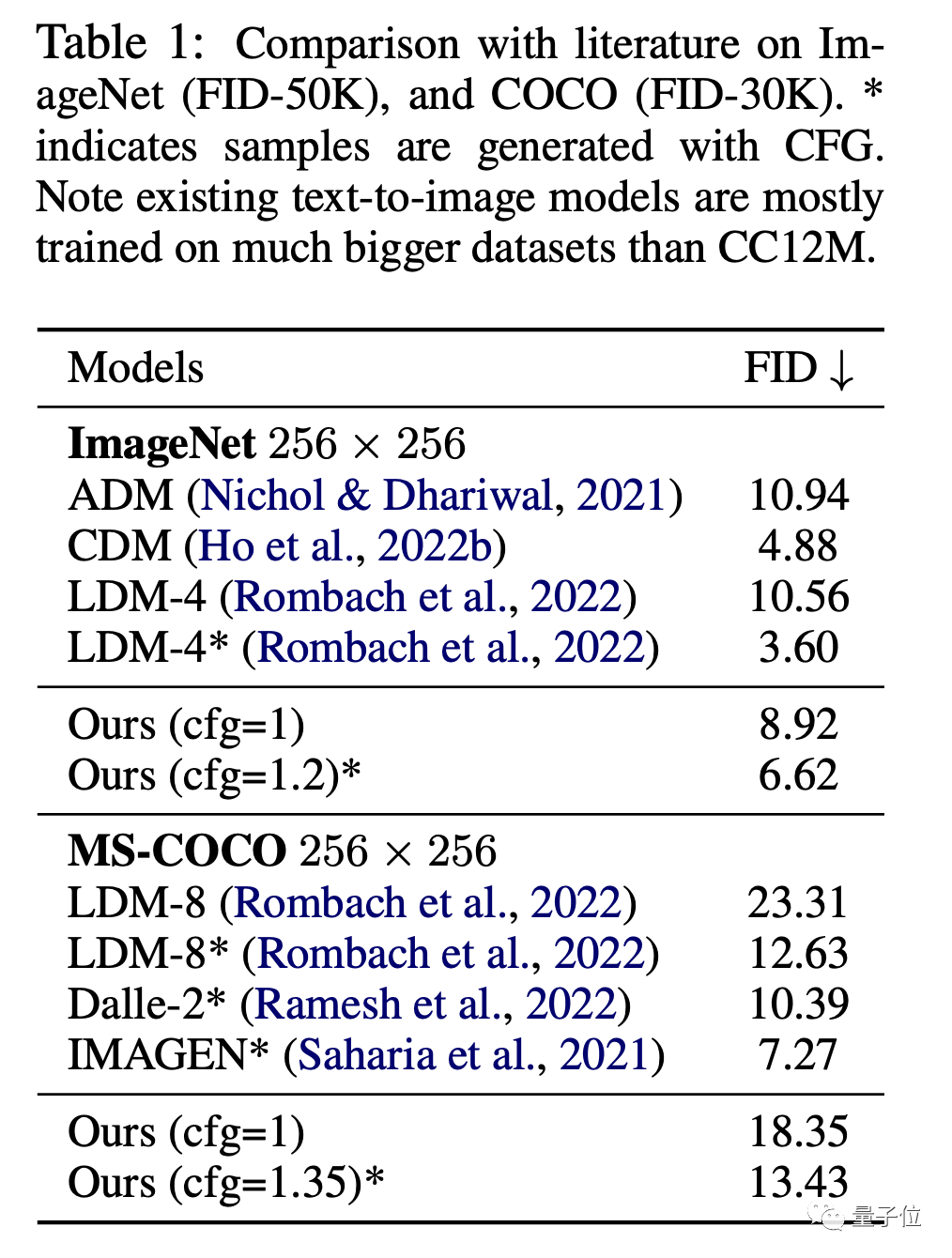
Non seulement il est meilleur que le modèle de diffusion ordinaire, mais les performances du MDM dépassent également les autres modèles de diffusion en cascade.
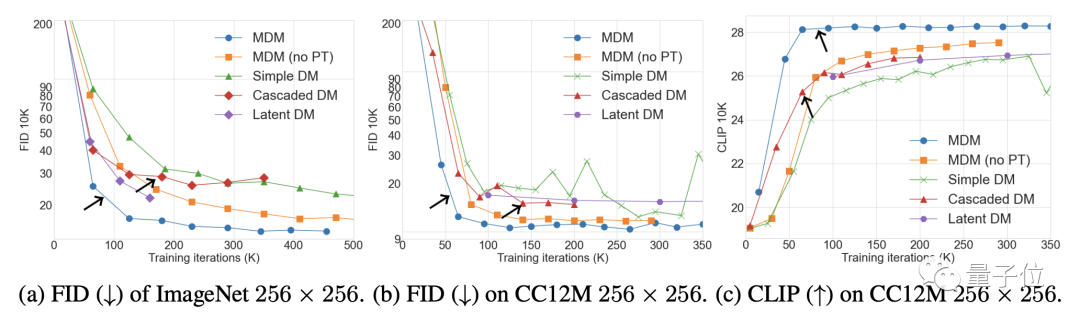
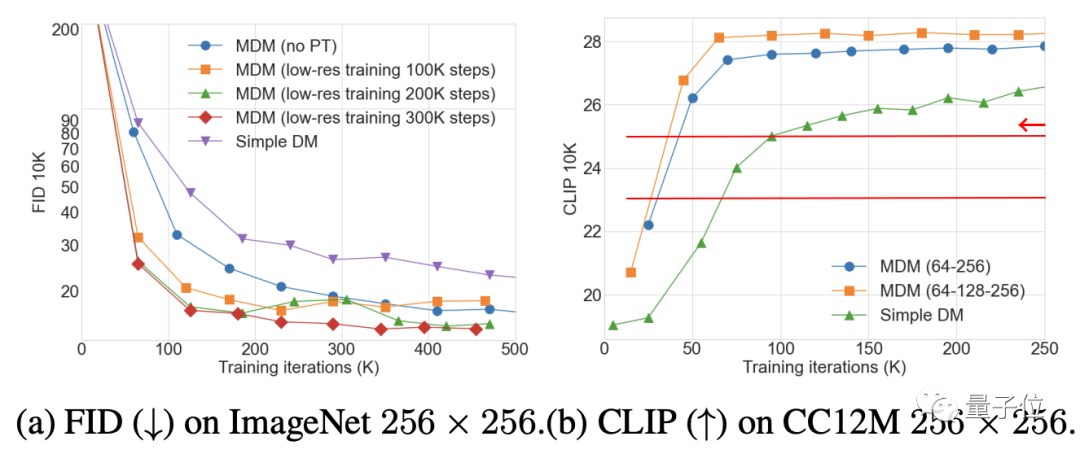
Les résultats de l'expérience d'ablation montrent que plus il y a d'étapes d'entraînement à basse résolution, plus l'amélioration de l'effet MDM est évidente, par contre, plus il y a de niveaux d'imbrication, moins le nombre d'étapes d'entraînement requis pour obtenir le même CLIP est important ; score. .
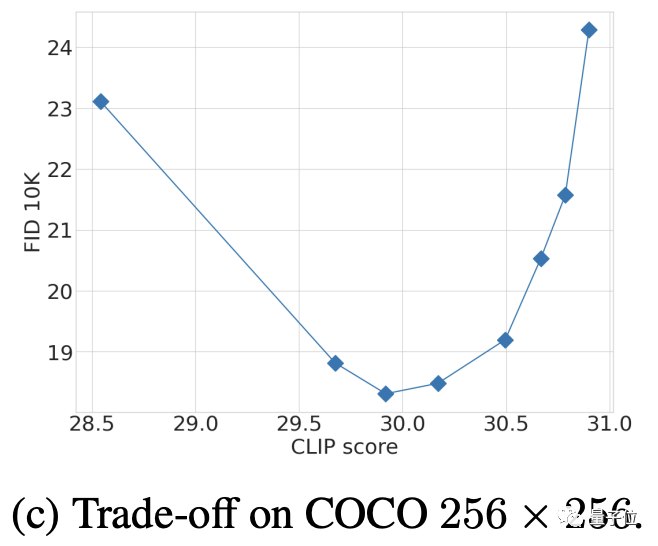
La sélection des paramètres CFG est le résultat d'un compromis entre FID et CLIP après plusieurs tests (un score CLIP élevé correspond à une augmentation de la force CFG).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Fonctions du modèle TCP/IP à quatre couches
- Quels sont les modèles de données couramment utilisés ?
- Comment calculer la taille du modèle de boîte CSS
- Comment importer la mise en page du modèle CAO
- Une autre révolution dans l'apprentissage par renforcement ! DeepMind propose une « distillation d'algorithmes » : un transformateur d'apprentissage par renforcement pré-entraîné explorable