
Maison >Périphériques technologiques >IA >Les vidéos composites 3D de qualité 4K ne se figent plus dans les diaporamas et la nouvelle méthode augmente la vitesse de rendu de plus de 30 fois.
Les vidéos composites 3D de qualité 4K ne se figent plus dans les diaporamas et la nouvelle méthode augmente la vitesse de rendu de plus de 30 fois.

- 王林avant
- 2023-10-19 14:21:04621parcourir
Bien que les vidéos de 60 images de qualité 4K ne puissent être visionnées que par les membres sur certaines applications, les chercheurs en IA ont déjà atteint une vidéo de synthèse dynamique 3D de niveau 4K et l'image est assez fluide.


Dans la vraie vie, la plupart des vidéos avec lesquelles nous entrons en contact sont en 2D. Lorsqu'on regarde ce genre de vidéo, on n'a aucun moyen de choisir l'angle de vue, comme marcher parmi les acteurs ou marcher vers un coin de l'espace. L’émergence des appareils VR et AR a comblé cette lacune. Les vidéos 3D qu’ils proposent nous permettent de changer de perspective et même de nous déplacer à volonté, améliorant grandement notre immersion.
Cependant, la synthèse de ce genre de scène dynamique 3D a toujours été une difficulté, tant en termes de qualité d'image que de finesse.
Récemment, des chercheurs de l'Université du Zhejiang, de Xiangyan Technology et d'Ant Group ont contesté ce problème. Dans un article intitulé « 4K4D : Real-Time 4D View Synthesis at 4K Resolution », ils ont proposé une méthode de représentation par nuage de points appelée 4K4D, qui améliore considérablement la vitesse de rendu de la synthèse de scènes dynamiques 3D haute résolution. Plus précisément, en utilisant un GPU RTX 4090, leur méthode peut restituer à une résolution 4K à une fréquence d'images allant jusqu'à 80 FPS et à une résolution 1080p à une fréquence d'images allant jusqu'à 400 FPS. Globalement, elle est plus de 30 fois plus rapide que la méthode précédente et la qualité du rendu atteint SOTA.

Ce qui suit est l'introduction du document.
Aperçu du papier

- Lien du papier : https://arxiv.org/pdf/2310.11448.pdf
- Lien du projet : https //z ju3dv. github .io/4k4d/
La synthèse de vues dynamiques vise à reconstruire des scènes 3D dynamiques à partir de vidéos capturées et à créer des lectures virtuelles immersives, ce qui constitue un problème de recherche à long terme en vision par ordinateur et en infographie. La clé de l’utilité de cette technologie réside dans sa capacité à restituer en temps réel avec une haute fidélité, ce qui lui permet d’être utilisée dans la VR/AR, les retransmissions sportives et la capture de performances artistiques. Les approches traditionnelles représentent des scènes 3D dynamiques sous forme de séquences de maillages texturés et utilisent un matériel complexe pour les reconstruire. Ils sont donc généralement limités aux environnements contrôlés.
Récemment, les représentations neuronales implicites ont obtenu un grand succès dans la reconstruction de scènes 3D dynamiques à partir de vidéos RVB grâce à un rendu différenciable. Par exemple, « Synthèse vidéo neuronale 3D à partir d'une vidéo multi-vues » modélise la scène cible comme un champ de rayonnement dynamique, utilise le rendu de volume pour synthétiser l'image, puis la compare et l'optimise avec l'image d'entrée. Malgré les résultats impressionnants de la synthèse de vue dynamique, les méthodes existantes nécessitent souvent des secondes, voire des minutes, pour restituer une image à une résolution de 1080p en raison d'une évaluation coûteuse du réseau.
Inspirées des méthodes de synthèse de vues statiques, certaines méthodes de synthèse de vues dynamiques améliorent la vitesse de rendu en réduisant le coût ou le nombre d'évaluations de réseau. Grâce à ces stratégies, MLP Maps est capable de restituer des figures dynamiques de premier plan à 41,7 ips. Cependant, des problèmes de vitesse de rendu subsistent, car les performances en temps réel de MLP Maps ne sont réalisables que lors de la composition d'images de résolution modérée (384 × 512). Lors du rendu d’une image en résolution 4K, elle a ralenti à seulement 1,3 FPS.
Dans cet article, les chercheurs proposent une nouvelle représentation neuronale - 4K4D, pour la modélisation et le rendu de scènes 3D dynamiques. Comme le montre la figure 1, 4K4D surpasse considérablement les précédentes méthodes de synthèse de vue dynamique en termes de vitesse de rendu tout en étant compétitif en termes de qualité de rendu.

Les auteurs ont déclaré que leur principale innovation réside dans la représentation des nuages de points 4D et le modèle d'apparence hybride. Plus précisément, pour les scènes dynamiques, ils utilisent un algorithme de sculpture spatiale pour obtenir une séquence grossière de nuages de points et modéliser la position de chaque point sous forme de vecteur apprenable. Ils ont également introduit une grille de caractéristiques 4D pour attribuer des vecteurs de caractéristiques à chaque point et l'ont introduite dans le réseau MLP pour prédire le rayon, la densité et les coefficients d'harmoniques sphériques (SH) des points. Les maillages d'entités 4D appliquent naturellement une régularisation spatiale sur le nuage de points, rendant l'optimisation plus robuste. Basé sur 4K4D, les chercheurs ont développé un algorithme de peeling en profondeur différenciable qui utilise la rastérisation matérielle pour atteindre des vitesses de rendu sans précédent.
Les chercheurs ont découvert que le modèle SH basé sur MLP est difficile à représenter l'apparence de scènes dynamiques. Pour atténuer ce problème, ils ont également introduit un modèle de mélange d'images à combiner avec le modèle SH pour représenter l'apparence de la scène. Une conception importante est qu’ils rendent le réseau de fusion d’images indépendant de la direction de visualisation, de sorte qu’il puisse être précalculé après l’entraînement pour améliorer la vitesse de rendu. En tant qu'épée à double tranchant, cette stratégie rend le modèle de mélange d'images discret dans la direction de visualisation. Ce problème peut être résolu en utilisant un modèle SH continu. Comparé au Splatting gaussien 3D qui utilise uniquement des modèles SH, le modèle d'apparence hybride proposé par les chercheurs utilise pleinement les informations capturées par l'image d'entrée, améliorant ainsi efficacement la qualité du rendu.
Pour vérifier l'efficacité de la nouvelle méthode, les chercheurs ont évalué 4K4D sur plusieurs ensembles de données de synthèse de nouvelles vues dynamiques multi-vues largement utilisés, notamment NHR, ENeRF-Outdoo, DNA-Rendering et Neural3DV. Des expériences approfondies ont montré que le 4K4D est non seulement plusieurs fois plus rapide en termes de vitesse de rendu, mais également nettement meilleur que la technologie SOTA en termes de qualité de rendu. En utilisant un GPU RTX 4090, la nouvelle méthode atteint 400 FPS sur l’ensemble de données de rendu ADN à une résolution de 1080p et 80 FPS sur l’ensemble de données ENeRF-Outdoor à une résolution de 4k.
Introduction à la méthode
À partir d'une vidéo multi-vues capturant une scène 3D dynamique, cet article vise à reconstruire la scène cible et à effectuer une synthèse de vues en temps réel. Le diagramme d'architecture du modèle est présenté dans la figure 2 :
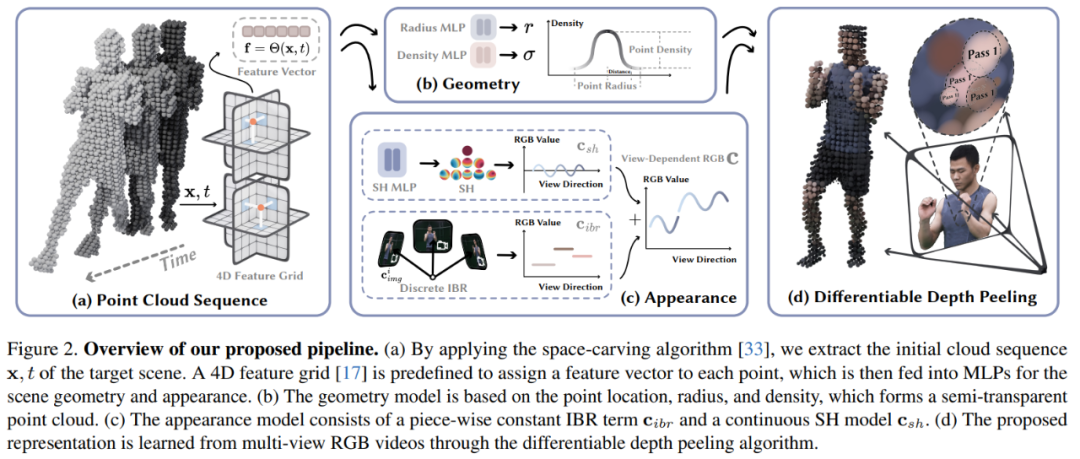
Ensuite, l'article présente les connaissances pertinentes sur l'utilisation de nuages de points pour modéliser des scènes dynamiques. Elles partent des perspectives de l'intégration 4D, du modèle géométrique et du modèle d'apparence.
Incorporation 4D : étant donné un nuage de points grossier d'une scène cible, cet article utilise des réseaux de neurones et des maillages de fonctionnalités pour représenter sa géométrie et son apparence dynamiques. Plus précisément, cet article définit d'abord six plans caractéristiques θ_xy, θ_xz, θ_yz, θ_tx, θ_ty et θ_tz, et utilise la stratégie K-Planes pour utiliser ces six plans pour modéliser un champ caractéristique 4D Θ(x, t) :
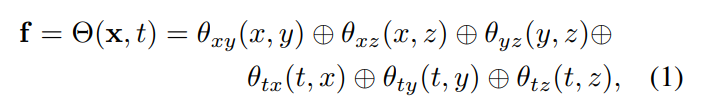
Modèle géométrique : Basé sur le nuage de points grossier, la géométrie dynamique de la scène est représentée par l'apprentissage de trois attributs (entrées) sur chaque point, à savoir la position p ∈ R^3, le rayon r ∈ R et la densité σ ∈ R. Ensuite, à l'aide de ces points, la densité volumique du point x dans l'espace est calculée. La position du point p est modélisée comme un vecteur optimisable. Le rayon r et la densité σ sont prédits en introduisant le vecteur caractéristique f dans l'équation (1) dans le réseau MLP.
Modèle d'apparence : comme le montre la figure 2c, cet article utilise la technologie de fusion d'images et le modèle de fonction harmonique sphérique (SH) pour créer un modèle d'apparence hybride, où la technologie de fusion d'images représente l'apparence de vue discrète c_ibr et le modèle SH. représente l'apparence continue dépendante de la vue. L'apparence de c_sh. Pour le point x à la t-ième image, sa couleur dans la direction de vue d est :
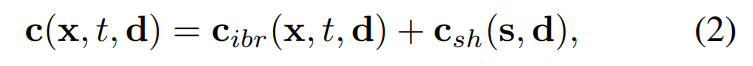
pelage en profondeur différentiable
La représentation dynamique de la scène proposée dans cet article peut être rendue avec l'aide de l'algorithme de peeling en profondeur dans une image.
Les chercheurs ont développé un shader personnalisé pour implémenter l'algorithme de peeling en profondeur composé de K passes de rendu. Autrement dit, pour un pixel u spécifique, le chercheur a effectué un traitement en plusieurs étapes. Finalement, après K rendus, le pixel u a obtenu un ensemble de points de tri {x_k|k = 1, ..., K}.
Sur la base de ces points {x_k|k = 1, ..., K}, la couleur du pixel u en rendu volumique s'exprime comme suit :
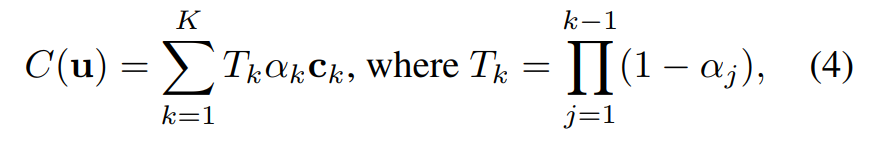
Pendant le processus de formation, étant donné la couleur du pixel rendue C (u), cet article la compare à la couleur réelle du pixel C_gt (u) et optimise le modèle de bout en bout en utilisant la fonction de perte suivante :
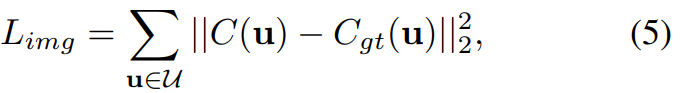
De plus, cet article s'applique également à la perte de perception :
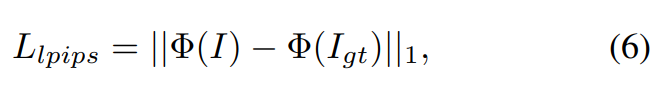
et à la perte de masque :
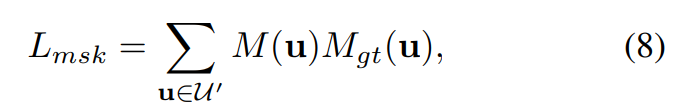
La fonction de perte finale est définie comme :
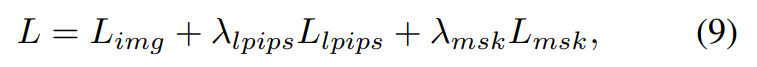
Expérience et résultats
Cet article évalue la méthode 4K4D sur les ensembles de données DNA-Rendering, ENeRF-Outdoor, NHR et Neural3DV. Les résultats de
sur l'ensemble de données DNA-Rendering sont présentés dans le tableau 1. Les résultats montrent que la vitesse de rendu 4K4D est plus de 30 fois plus rapide que celle d'ENeRF avec les performances SOTA et que la qualité de rendu est meilleure.
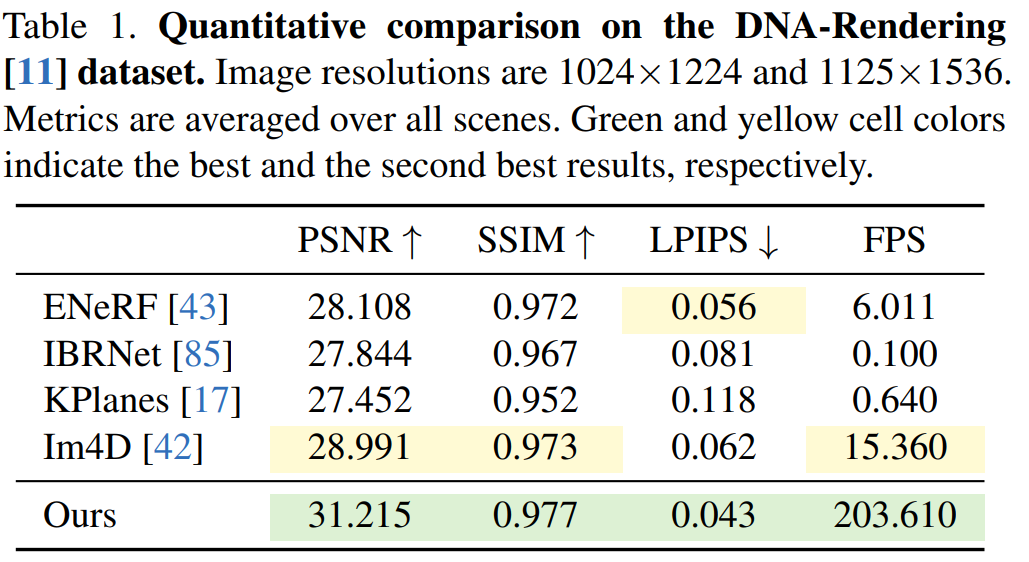
Les résultats qualitatifs sur l'ensemble de données de rendu ADN sont présentés dans la figure 5. KPlanes ne peut pas récupérer l'apparence détaillée et la géométrie des scènes dynamiques 4D, tandis que d'autres méthodes basées sur l'image produisent une apparence de haute qualité. Cependant, ces méthodes ont tendance à produire des résultats flous autour des occlusions et des bords, ce qui entraîne une qualité visuelle réduite, alors que le 4K4D peut produire des rendus plus fidèles à plus de 200 FPS.

Ensuite, les expériences montrent les résultats qualitatifs et quantitatifs de différentes méthodes sur l'ensemble de données ENeRFOutdoor. Comme le montre le tableau 2, le 4K4D a quand même obtenu des résultats nettement meilleurs lors d'un rendu à plus de 140 FPS.
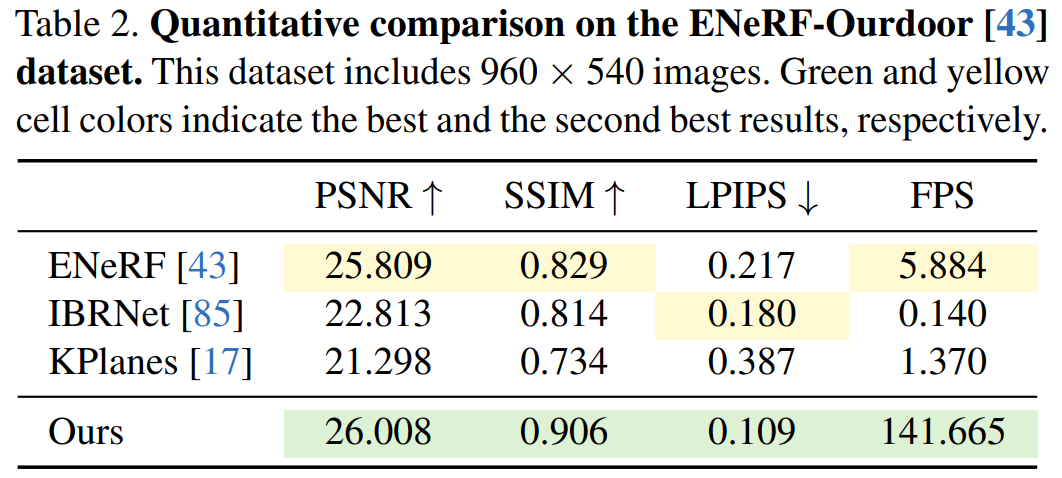
Alors que d'autres méthodes, telles que ENeRF, produisent des résultats flous ; les résultats de rendu d'IBRNet contiennent des artefacts noirs sur les bords de l'image, comme le montre la figure 3 ; .

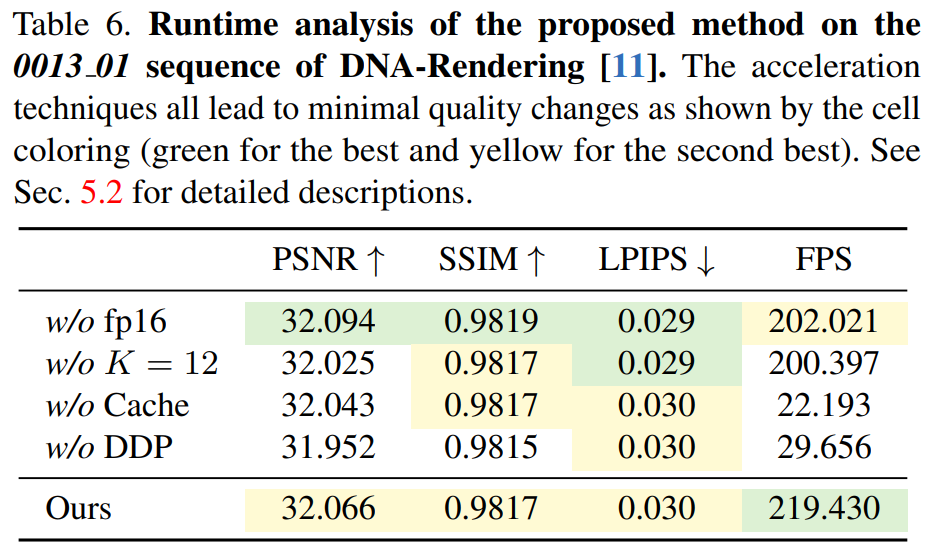
Le Tableau 6 montre l'efficacité de l'algorithme de peeling en profondeur différenciable, le 4K4D étant plus de 7 fois plus rapide que la méthode basée sur CUDA.
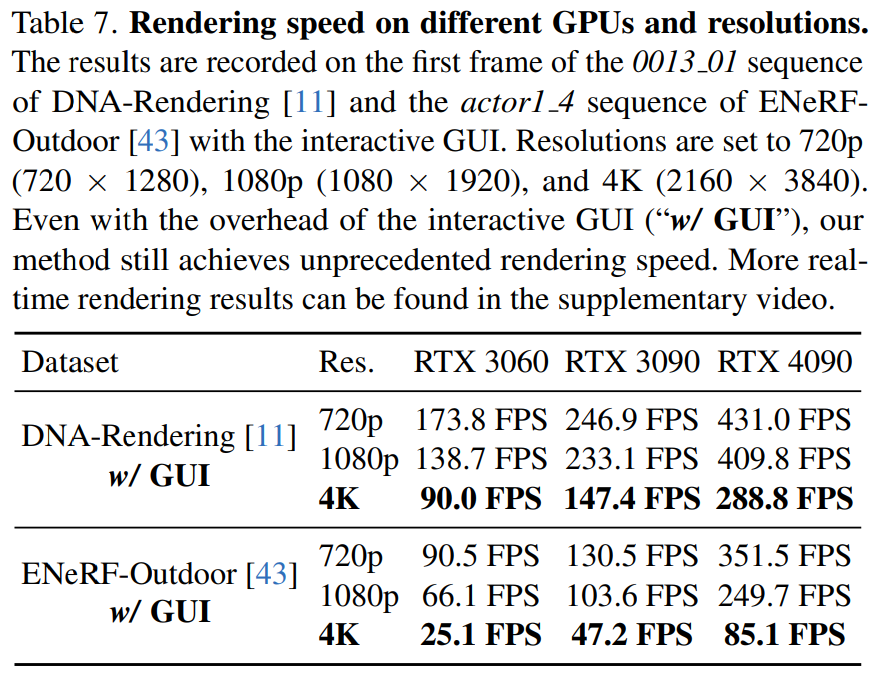
Cet article rapporte également la vitesse de rendu du 4K4D sur différents matériels (RTX 3060, 3090 et 4090) à différentes résolutions dans le tableau 7.
Veuillez consulter le document original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!