Quel sera l'effet de couper les poils d'alpaga du modèle Llama 2 ? Aujourd'hui, l'équipe Chen Danqi de l'Université de Princeton a proposé une méthode d'élagage de grands modèles appelée LLM-Shearing, qui permet d'obtenir de meilleures performances que les modèles de même taille avec une petite quantité de calcul et de coût.
Depuis l'émergence des grands modèles de langage (LLM), ils ont obtenu des résultats remarquables sur diverses tâches en langage naturel. Cependant, la formation des grands modèles de langage nécessite des ressources informatiques massives. En conséquence, l’industrie s’intéresse de plus en plus à la création de modèles de taille moyenne tout aussi puissants, avec l’émergence de LLaMA, MPT et Falcon, permettant une inférence et un réglage précis. Ces LLM de différentes tailles conviennent à différents cas d'utilisation, mais entraîner chaque modèle individuel à partir de zéro (même un petit modèle avec 1 milliard de paramètres) nécessite toujours beaucoup de ressources informatiques, ce qui est encore difficile pour la plupart des recherches scientifiques institutions. C’est un gros fardeau. Dans cet article, l'équipe Chen Danqi de l'Université de Princeton tente de résoudre le problème suivant : un LLM pré-entraîné existant peut-il être utilisé pour créer un LLM plus petit, à usage général et compétitif en termes de performances, tout en le formant à partir de zéro ? Nécessite beaucoup moins de calculs ? Les chercheurs explorent l'utilisation de la taille structurée pour atteindre leurs objectifs. Le problème ici est que pour les LLM à usage général, le modèle élagué connaîtra une dégradation des performances, surtout s'il n'y a pas d'investissement informatique significatif après l'élagage. La méthode d'élagage efficace qu'ils ont utilisée peut être utilisée pour développer des LLM plus petits mais toujours compétitifs en termes de performances, et la formation nécessite beaucoup moins d'effort de calcul qu'une formation à partir de zéro. 
- Adresse papier : https://arxiv.org/abs/2310.06694
- Adresse code : https://github.com/princeton-nlp/LLM-Shearing
- ModelsSheared-LLaMA -1.3B, Sheared-LLaMA-2.7B
Avant d'élaguer LLM, les chercheurs ont identifié deux défis techniques clés. L'un est de savoir comment déterminer la structure d'élagage finale avec des performances puissantes et un raisonnement efficace. La technologie d'élagage structuré actuelle de LLM n'a pas de structure cible spécifiée, ce qui entraîne des performances et une vitesse d'inférence insatisfaisantes du modèle élagué. Deuxièmement, comment continuer à pré-entraîner le modèle élagué pour atteindre les performances attendues ? Ils ont observé que la formation avec des données brutes de pré-formation entraînait des réductions de pertes différentes selon les domaines par rapport à la formation du modèle à partir de zéro. Pour relever ces deux défis, les chercheurs ont proposé l'algorithme "LLM - cisaillement". Ce nouvel algorithme d'élagage, appelé « élagage structuré dirigé », élague le modèle source selon une architecture cible spécifiée, qui est déterminée par la configuration du modèle pré-entraîné existant. Ils montrent que la méthode d'élagage recherche les sous-structures dans le modèle source et maximise les performances sous contraintes de ressources. De plus, un algorithme de chargement par lots dynamique est conçu, qui peut charger les données d'entraînement de chaque domaine proportionnellement en fonction du taux de réduction des pertes, utilisant ainsi efficacement les données et accélérant l'amélioration globale des performances. Enfin, le chercheur a élagué le modèle LLaMA2-7B en deux LLM plus petits, à savoir Sheared-LLaMA-1.3B et Sheared-LLaMA-2.7B, confirmant l'efficacité de leur méthode. 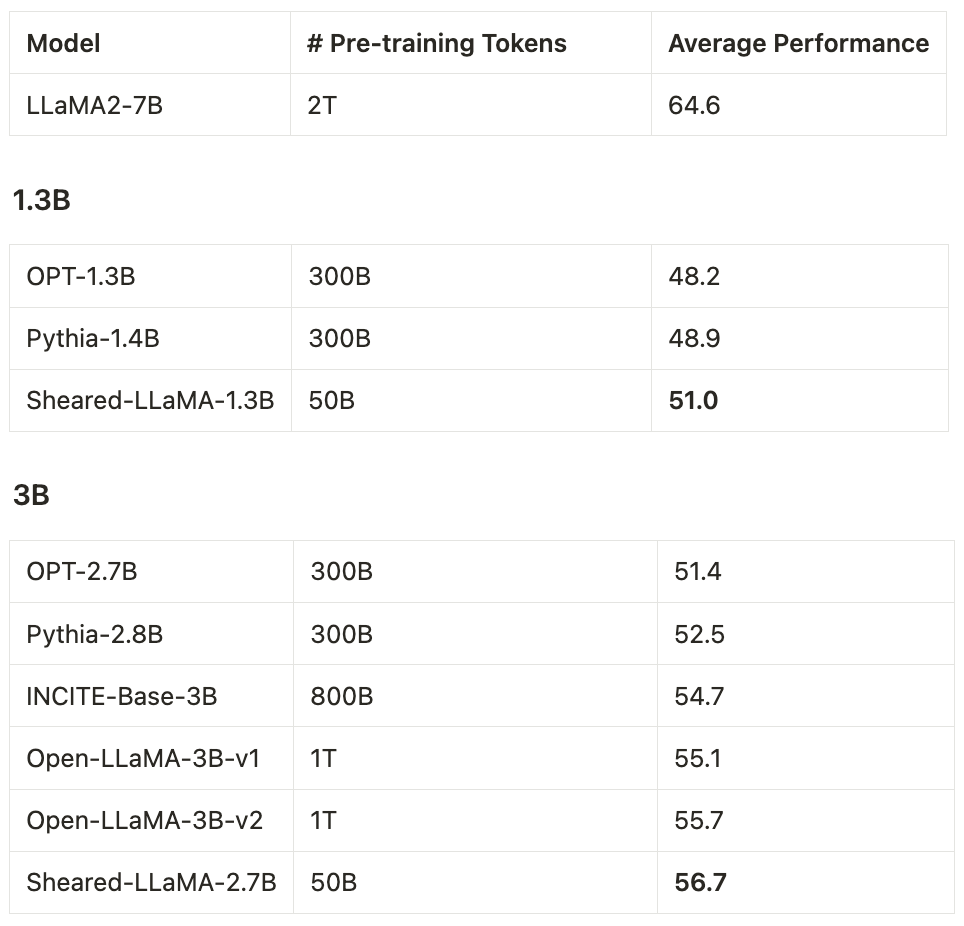
Ils n'ont utilisé que 50 milliards de tokens (soit 5% du budget de pré-formation d'OpenLLaMA) pour l'élagage et la poursuite de la pré-formation, mais pour 11 tâches représentatives en aval (telles que la culture générale, la compréhension écrite et la connaissance du monde) et open Même avec l'ajustement des instructions générées par la formule, les performances de ces deux modèles surpassent toujours les autres LLM populaires de même taille, notamment Pythia, INCITE et OpenLLaMA. 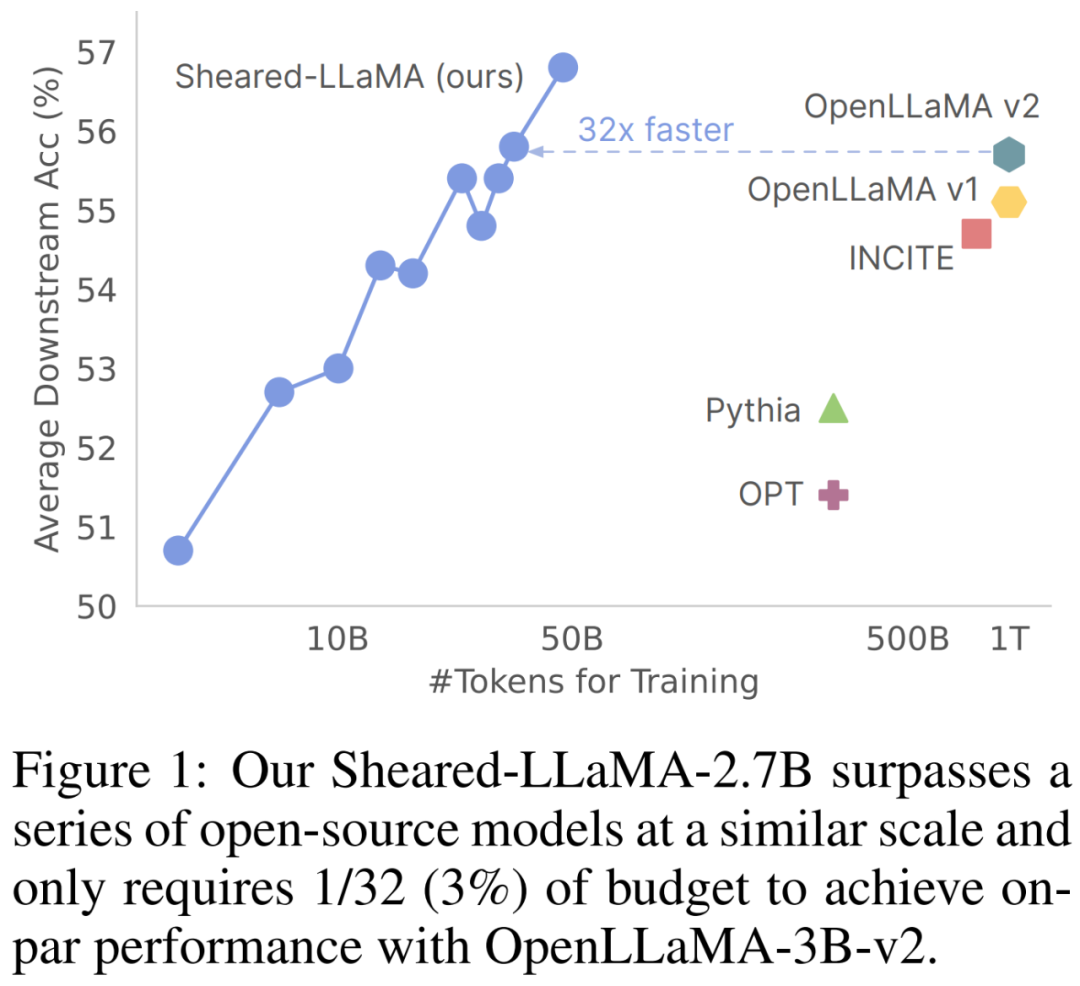
Mais il convient de mentionner que lorsque cet article a publié Sheared-LLaMA-3B, le record du modèle open source 3B le plus puissant avait été battu par StableLM-3B. 
De plus, les trajectoires de performance des tâches en aval indiquent que l'utilisation de davantage de jetons pour entraîner davantage le modèle élagué apportera de plus grands avantages. Les chercheurs n’ont expérimenté qu’avec des modèles comportant jusqu’à 7 milliards de paramètres, mais le cisaillement LLM est très général et peut être étendu à de grands modèles de langage de toute taille dans des travaux futurs. Introduction à la méthodeÉtant donné un grand modèle M_S existant (modèle source), le but de cet article est d'étudier comment générer efficacement un modèle M_T plus petit et plus fort (modèle cible). L'étude estime que cela nécessite deux étapes :
- La première étape élague M_S à M_T Bien que cela réduise le nombre de paramètres, cela conduit inévitablement à une dégradation des performances
- La deuxième étape Pré-entraîner en continu ; M_T pour renforcer ses performances. L'élagage structuré peut supprimer un grand nombre de paramètres du modèle, obtenant ainsi l'effet de compresser le modèle et d'accélérer l'inférence. Cependant, les méthodes d’élagage structuré existantes peuvent amener les modèles à s’écarter des configurations architecturales conventionnelles. Par exemple, la méthode CoFiPruning produit des modèles avec des configurations de couches non uniformes, ce qui entraîne une surcharge d'inférence supplémentaire par rapport aux configurations de couches unifiées standard.
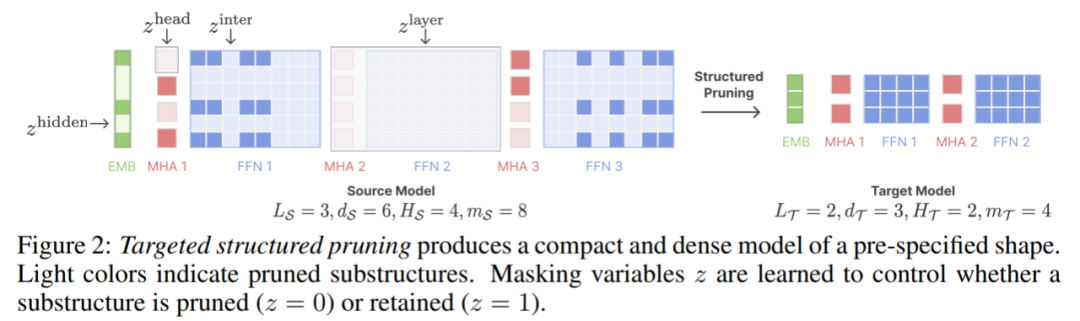
Cet article étend CoFiPruning pour permettre l'élagage du modèle source sur n'importe quelle configuration cible spécifiée. Par exemple, cet article utilise l'architecture INCITE-Base-3B comme structure cible lors de la génération du modèle 2.7B. De plus, cet article apprend également un ensemble de masques d'élagage (masques d'élagage) sur les paramètres du modèle de différentes granularités. Les variables de masque sont les suivantes :
Chaque variable de masque contrôle s'il faut élaguer ou sous-structures pertinentes. sont préservés. Par exemple, si le z^layer correspondant= 0, ce calque doit être supprimé. La figure 2 ci-dessous illustre comment les masques d'élagage contrôlent quelles structures sont élaguées.
Après l'élagage, nous finalisons l'architecture élaguée en conservant les composants les plus performants liés aux variables de masque dans chaque sous-structure, et continuons à pré-élaguer le modèle élagué à l'aide du train d'objectifs de modélisation du langage.
Chargement dynamique par lots
 Cette étude estime qu'une pré-formation approfondie des modèles élagués est nécessaire afin de restaurer les performances du modèle.
Cette étude estime qu'une pré-formation approfondie des modèles élagués est nécessaire afin de restaurer les performances du modèle.
Inspiré par d'autres recherches, cet article propose un algorithme plus efficace, le chargement dynamique par lots, qui peut simplement ajuster dynamiquement l'échelle du domaine en fonction des performances du modèle. L'algorithme est le suivant :
Configuration du modèle : Cet article utilise le modèle LLaMA2-7B comme modèle source, puis mène des expériences d'élagage structurées. Ils ont compressé LLaMA2-7B en. deux plus petits. La taille cible est de 2,7B et 1,3B, et les performances du modèle cisaillé sont comparées à des modèles de même taille, notamment OPT-1.3B, Pythia-1.4B, OPT-2.7B, Pythia-2.8. B, INCITE-Base-3B, OpenLLaMA-3B-v1, OpenLLaMA-3B-v2. Le tableau 8 résume les détails de l'architecture du modèle pour tous ces modèles.  Données : Les données d'entraînement de LLaMA2 n'étant pas accessibles au public, cet article utilise l'ensemble de données RedPajama. Le tableau 1 fournit les données de pré-formation utilisées par le modèle de cet article et le modèle de base.
Données : Les données d'entraînement de LLaMA2 n'étant pas accessibles au public, cet article utilise l'ensemble de données RedPajama. Le tableau 1 fournit les données de pré-formation utilisées par le modèle de cet article et le modèle de base.
Formation : Les chercheurs ont utilisé jusqu'à 16 GPU Nvidia A100 (80 Go) dans toutes les expériences.
SHEARED-LLAMA surpasse les LM de taille comparable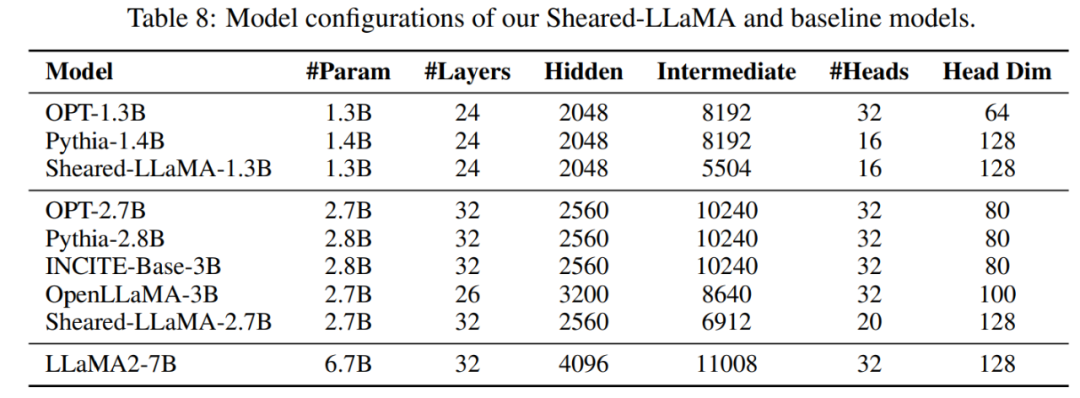
 Cet article montre que Sheared-LLaMA surpasse considérablement les LLM existants de taille similaire tout en n'utilisant qu'une fraction du budget de calcul pour entraîner à partir de zéro ces modèles.
Cet article montre que Sheared-LLaMA surpasse considérablement les LLM existants de taille similaire tout en n'utilisant qu'une fraction du budget de calcul pour entraîner à partir de zéro ces modèles.
Tâches en aval : le tableau 2 montre les performances sans tir et en quelques tirs de Sheared-LLaMA et des modèles pré-entraînés existants de taille similaire sur les tâches en aval. Optimisation des instructions : comme le montre la figure 3, le Sheared-LLaMA optimisé pour les instructions atteint un taux de victoire plus élevé par rapport à tous les autres modèles pré-entraînés de la même échelle. 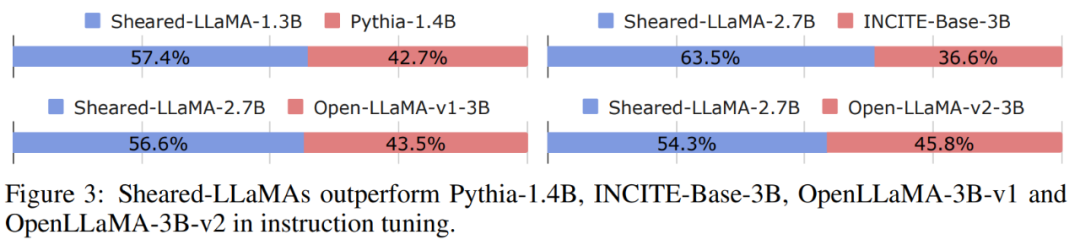
La figure 4 montre que le modèle INCITEBase-3B démarre avec une précision beaucoup plus élevée, mais que ses performances se stabilisent au cours du processus de pré-entraînement en cours. 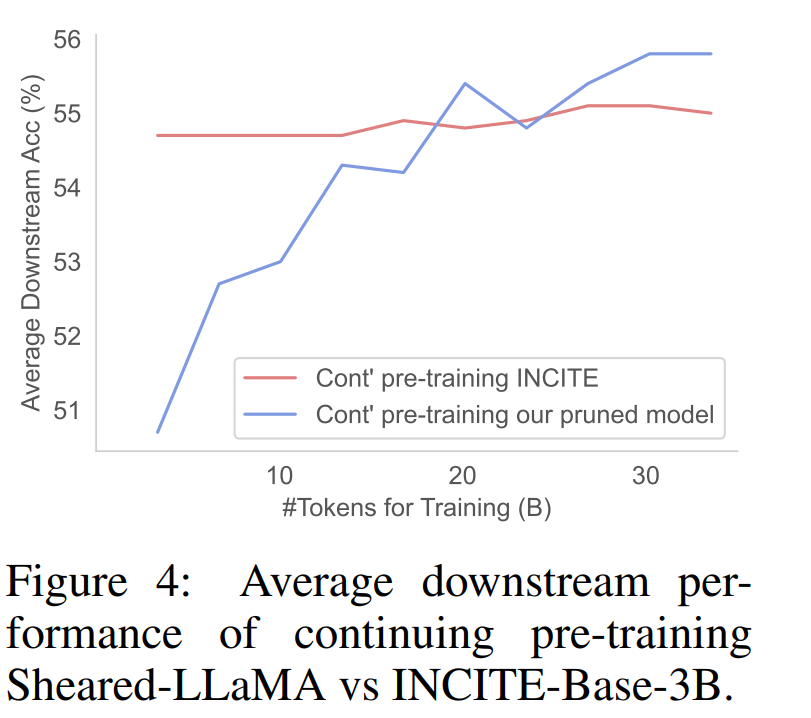
Enfin, le chercheur a analysé les avantages de cette méthode. Efficacité du chargement dynamique par lotsParmi eux, les chercheurs analysent l'efficacité du chargement dynamique par lots sous les trois aspects suivants : (1) perte finale de LM inter-domaines, (2) utilisation des données pour chaque domaine tout au long du processus de formation, (3) exécution des tâches en aval. Les résultats sont basés sur l'algorithme Sheared-LaMA-1.3B. Différence de perte entre domaines. Le but du chargement dynamique par lots est d'équilibrer le taux de réduction des pertes de chaque domaine afin que la perte atteigne la valeur de référence à peu près dans le même temps. La différence entre la perte du modèle (chargement par lots d'origine et chargement par lots dynamique) et la perte de référence est représentée dans la figure 5. En revanche, le chargement par lots dynamique réduit la perte de manière uniforme et la différence de perte entre les domaines est également très similaire, ce qui montre que les données Utilisation plus efficace. 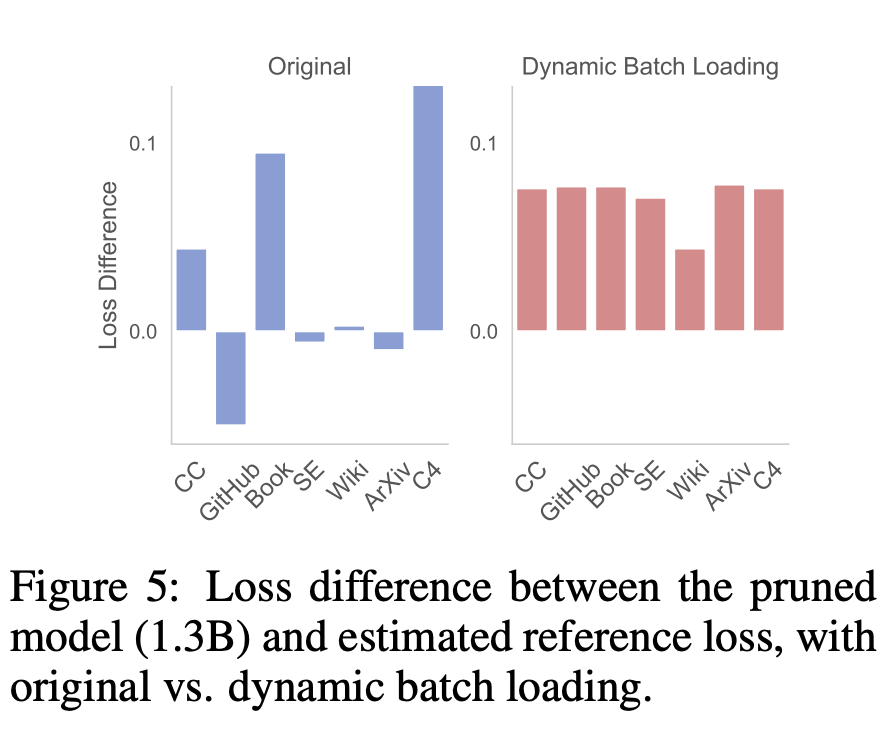
Utilisation des données. Le tableau 3 compare les proportions de données brutes de RedPajama et l'utilisation des données de domaine chargées dynamiquement (la figure 7 montre les changements dans les pondérations de domaine tout au long du processus de formation). Le chargement groupé dynamique augmente le poids des domaines Book et C4 par rapport aux autres domaines, ce qui indique que ces domaines sont plus difficiles à récupérer à partir du modèle élagué. 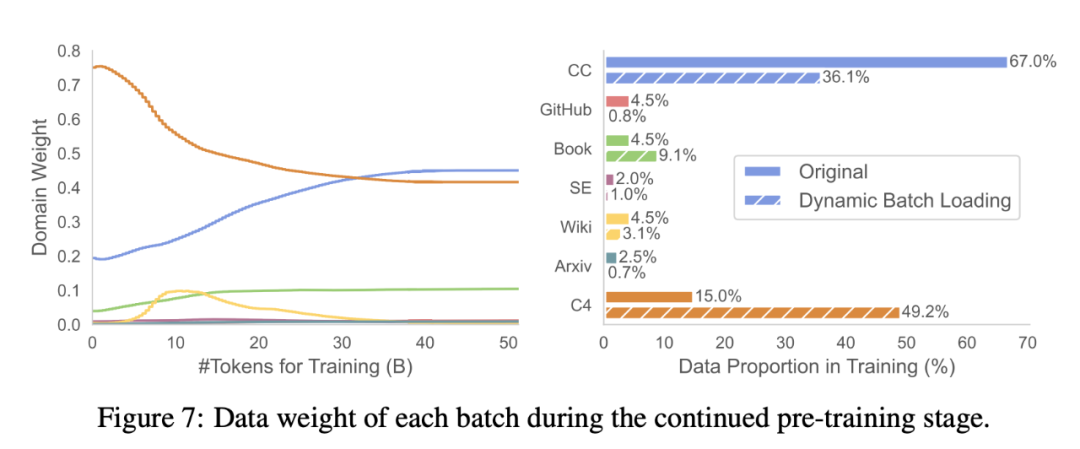
Performances en aval. Comme le montre la figure 6, le modèle élagué formé à l'aide du chargement dynamique par lots a obtenu de meilleures performances en aval par rapport au modèle formé sur la distribution RedPajama d'origine. Cela suggère que la réduction plus équilibrée des pertes provoquée par le chargement dynamique des lots peut améliorer les performances en aval. 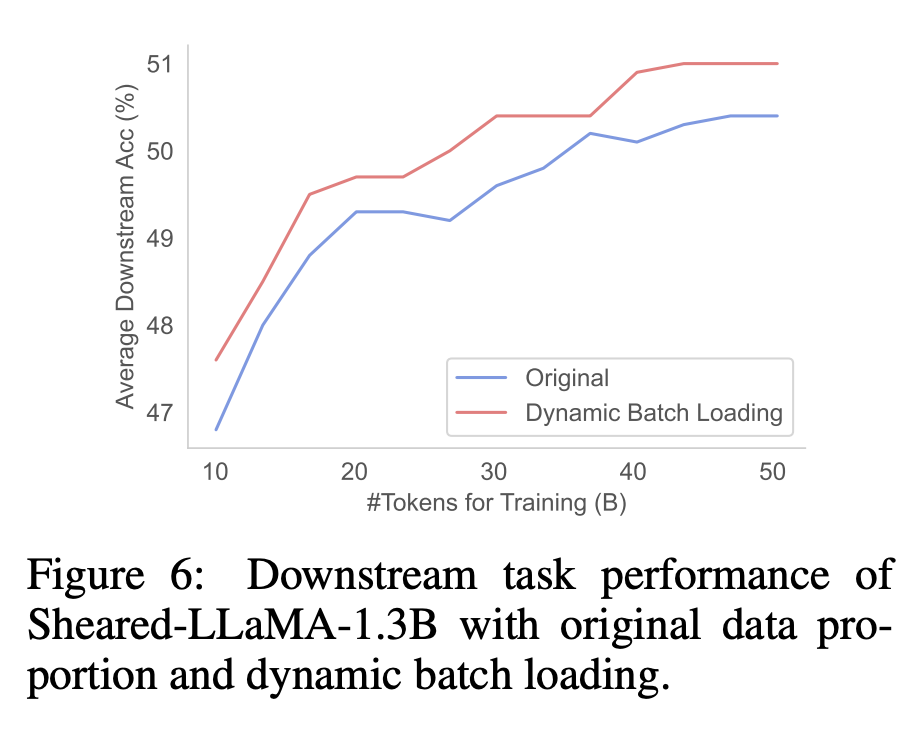
Comparaison avec d'autres méthodes d'élagageDe plus, les chercheurs ont comparé la méthode de tonte LLM avec d'autres méthodes d'élagage et ont signalé la perplexité de validation, qui est une mesure de la capacité globale du modèle et un indicateur puissant. En raison de limitations de calcul, les expériences suivantes contrôlent le budget de calcul total de toutes les méthodes comparées au lieu d'exécuter chaque méthode jusqu'à la fin. Comme le montre le tableau 4, sous la même parcimonie, le débit d'inférence du modèle d'élagage cible dans cet article est supérieur au modèle d'élagage non uniforme CoFiPruning, mais la perplexité est légèrement plus élevée. 
Le tableau 5 montre que l'augmentation des frais généraux d'élagage peut améliorer continuellement la perplexité tout en contrôlant le nombre total de jetons. Cependant, comme l’élagage coûte plus cher que la pré-formation continue, les chercheurs allouent 0,4 milliard de jetons à l’élagage. 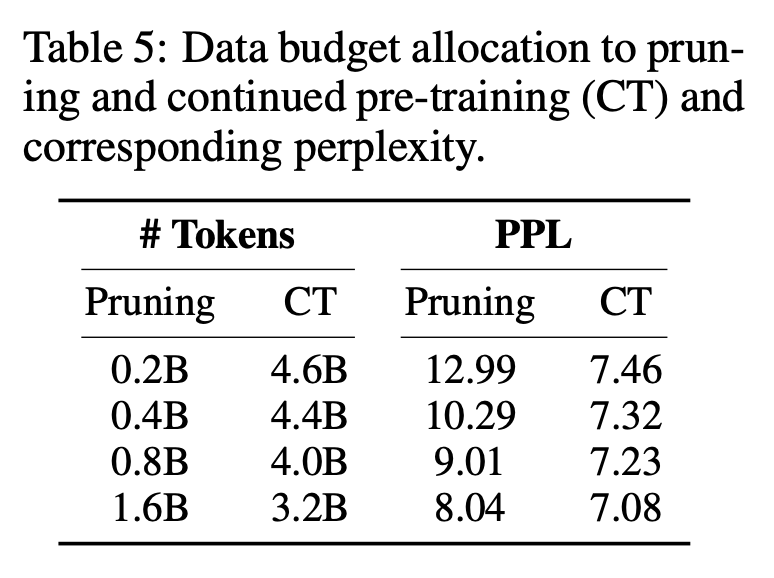
Pour plus de détails sur la recherche, veuillez vous référer à l'article original. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

