
Maison >Périphériques technologiques >IA >Dans la génération d'images et de vidéos, le modèle linguistique a vaincu le modèle de diffusion pour la première fois, et le tokenizer est la clé
Dans la génération d'images et de vidéos, le modèle linguistique a vaincu le modèle de diffusion pour la première fois, et le tokenizer est la clé

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-10-11 15:53:01950parcourir
Les modèles linguistiques à grande échelle (LLM ou LM) étaient à l'origine utilisés pour générer du langage, mais au fil du temps, ils ont été capables de générer du contenu dans de multiples modalités et sont utilisés dans l'audio, la parole, la génération de code, les applications médicales, la robotique, etc. Commencez à prendre le relais
Bien entendu, LM peut également générer des images et des vidéos. Au cours de ce processus, les pixels de l'image sont mappés en une série de jetons discrets par le tokeniseur visuel. Ces jetons sont ensuite introduits dans le transformateur LM et utilisés comme vocabulaires pour la modélisation générative. Malgré des progrès significatifs dans la génération visuelle, le LM est toujours moins performant que les modèles de diffusion. Par exemple, lorsqu'il est évalué sur l'ensemble de données ImageNet, la référence de référence en matière de génération d'images, le meilleur modèle de langage a obtenu des résultats 48 % moins bons que le modèle de diffusion (FID 3,41 contre 1,79 lors de la génération d'images à une résolution de 256ˆ256).
Pourquoi les modèles de langage sont-ils en retard par rapport aux modèles de diffusion dans la génération visuelle ? Les chercheurs de Google et de la CMU estiment que la raison principale est le manque d'une bonne représentation visuelle, similaire à notre système de langage naturel, pour modéliser efficacement le monde visuel. Pour confirmer cette hypothèse, ils ont mené une étude.

Lien papier : https://arxiv.org/pdf/2310.05737.pdf
Cette étude montre que sous les mêmes données de formation, une taille de modèle et un budget de formation comparables, en utilisant un bon tokenizer visuel, masqué les modèles de langage surpassent les modèles de diffusion SOTA en termes de fidélité de génération et d'efficacité sur les benchmarks d'images et de vidéos. Il s'agit de la première preuve qu'un modèle de langage bat un modèle de diffusion sur le benchmark emblématique ImageNet.
Il convient de souligner que le but des chercheurs n'est pas d'affirmer si le modèle de langage est meilleur que d'autres modèles, mais de promouvoir l'exploration des méthodes de tokenisation visuelle LLM. La différence fondamentale entre LLM et d'autres modèles (tels que les modèles de diffusion) est que LLM utilise des formats latents discrets, c'est-à-dire des jetons obtenus à partir d'un tokeniseur visuel. Cette recherche montre que la valeur de ces jetons visuels discrets ne doit pas être ignorée en raison de leurs avantages suivants :
1. Le principal avantage de la représentation du jeton est qu'elle partage la même forme que le jeton de langage, tirant ainsi directement parti des optimisations que la communauté a réalisées au fil des années pour développer le LLM, notamment des vitesses de formation et d'inférence plus rapides, des progrès dans l'infrastructure des modèles, des moyens d'étendre le modèle et des innovations telles que l’optimisation GPU/TPU. Unifier la vision et le langage via le même espace symbolique pourrait jeter les bases de LLM véritablement multimodaux, capables de comprendre, de générer et de raisonner au sein de nos environnements visuels.
2. Représentation compressée. Les jetons discrets peuvent offrir une nouvelle perspective sur la compression vidéo. Les jetons visuels peuvent être utilisés comme nouveau format de compression vidéo pour réduire le stockage sur disque et la bande passante occupée par les données lors de la transmission sur Internet. Contrairement aux pixels RVB compressés, ces jetons peuvent être introduits directement dans le modèle génératif, en contournant les étapes traditionnelles de décompression et de codage latent. Cela peut accélérer le traitement des applications de génération vidéo et s’avère particulièrement bénéfique dans les situations d’informatique de pointe.
3. Avantages de la compréhension visuelle. Des recherches antérieures ont montré la valeur des étiquettes discrètes en tant que cibles de pré-formation dans l'apprentissage des représentations auto-supervisé, comme discuté dans BEiT et BEVT. En outre, l'étude a révélé que l'utilisation de marqueurs comme entrées de modèle peut améliorer sa robustesse et ses performances de généralisation. tokens
Le contenu est réécrit comme suit : Ce modèle est basé sur une amélioration de MAGVIT, un tokenizer vidéo SOTA dans le framework VQ-VAE. Les chercheurs ont proposé deux nouvelles technologies : 1) une méthode de quantification innovante sans recherche qui permet d'apprendre un large vocabulaire, améliorant ainsi la qualité de la génération de modèles de langage ; 2) grâce à une analyse empirique approfondie, ils ont déterminé que les modifications apportées à MAGVIT améliorent non seulement la qualité de la génération. , mais permet également de tokeniser des images et des vidéos à l'aide d'un vocabulaire partagé
Les résultats expérimentaux montrent que le nouveau modèle surpasse le précédent segmenteur vidéo le plus performant dans trois domaines clés ——MAGVIT. Premièrement, le nouveau modèle améliore considérablement la qualité de génération de MAGVIT, en obtenant des résultats de pointe sur des tests d’image et vidéo courants. Deuxièmement, des études d'utilisateurs montrent que sa qualité de compression dépasse MAGVIT et la norme de compression vidéo actuelle HEVC. De plus, il est comparable au codec vidéo de nouvelle génération VVC. Enfin, les chercheurs montrent que leur nouvelle segmentation de mots fonctionne mieux que MAGVIT dans les tâches de compréhension vidéo dans deux contextes et trois ensembles de données
Introduction à la méthode
Cet article présente un nouveau tokeniseur vidéo, qui vise à cartographier la dynamique espace-temps dans les scènes visuelles en jetons discrets compacts adaptés aux modèles de langage. De plus, la méthode s'appuie sur MAGVIT.
Par la suite, l'étude met en évidence deux nouvelles conceptions : la quantification sans recherche (LFQ) et les améliorations apportées au modèle de tokenizer.
Quantisation sans recherche
Récemment, le modèle VQ-VAE a fait de grands progrès, mais cette méthode a un problème, c'est-à-dire que la relation entre l'amélioration de la qualité de la reconstruction et la qualité de la génération suivante est pas clair. Beaucoup de gens croient à tort qu'améliorer la reconstruction équivaut à améliorer la génération de modèles de langage, par exemple, élargir le vocabulaire peut améliorer la qualité de la reconstruction. Cependant, cette amélioration ne s'applique qu'à la génération avec un petit vocabulaire, et lorsque le vocabulaire est très volumineux, cela nuira aux performances du modèle de langage
Cet article réduit la dimension d'intégration du livre de codes VQ-VAE à 0, c'est-à-dire le Codebook 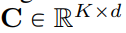 est remplacé par un ensemble d'entiers
est remplacé par un ensemble d'entiers 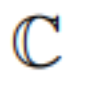 , où
, où 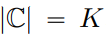 .
.
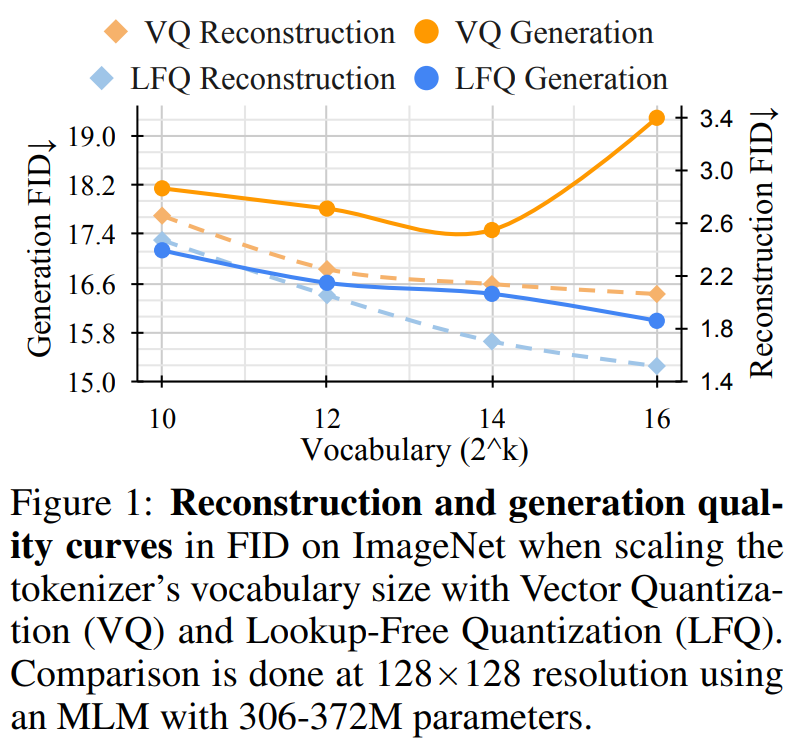
Contrairement au modèle VQ-VAE, cette nouvelle conception élimine complètement le besoin de recherches intégrées, d'où le nom LFQ. Cet article révèle que LFQ peut améliorer la qualité de la génération de modèles de langage en augmentant le vocabulaire. Comme le montre la courbe bleue de la figure 1, la reconstruction et la génération s'améliorent à mesure que la taille du vocabulaire augmente, une propriété non observée dans les méthodes VQ-VAE actuelles.
Il existe de nombreuses méthodes LFQ disponibles jusqu'à présent, mais cet article traite d'une variante simple. Plus précisément, l'espace latent de LFQ est décomposé en produit cartésien de variables unidimensionnelles, c'est-à-dire 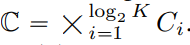 . En supposant qu'étant donné un vecteur caractéristique
. En supposant qu'étant donné un vecteur caractéristique 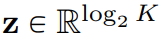 , chaque dimension de la représentation quantifiée q(z) est obtenue à partir de :
, chaque dimension de la représentation quantifiée q(z) est obtenue à partir de :
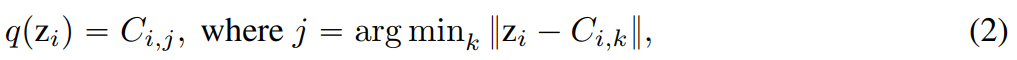
Par rapport à LFQ, l'indice symbolique de q(z) est :
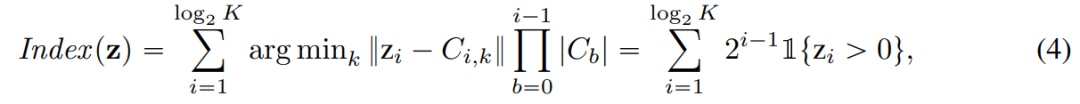
sauf De plus, cet article ajoute également une pénalité d'entropie pendant le processus de formation :
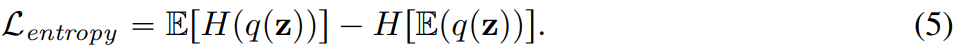
Amélioration du modèle de tokenizer visuel
Afin de construire un tokenizer commun image-vidéo, il doit être repensé . L'étude a révélé que par rapport au transformateur spatial, les performances du CNN 3D sont meilleures
Cet article explore deux solutions de conception réalisables : la figure 2b combine C-ViViT avec MAGVIT ; la figure 2c utilise la convolution 3D causale temporelle pour remplacer le CNN 3D conventionnel ; .
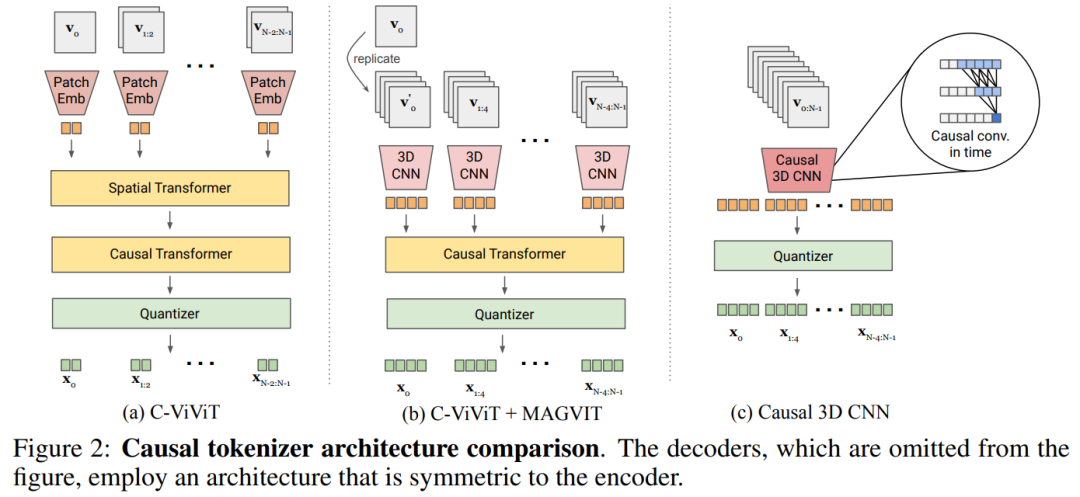
Le tableau 5a compare empiriquement les conceptions de la figure 2 et constate que le CNN 3D causal fonctionne le mieux.
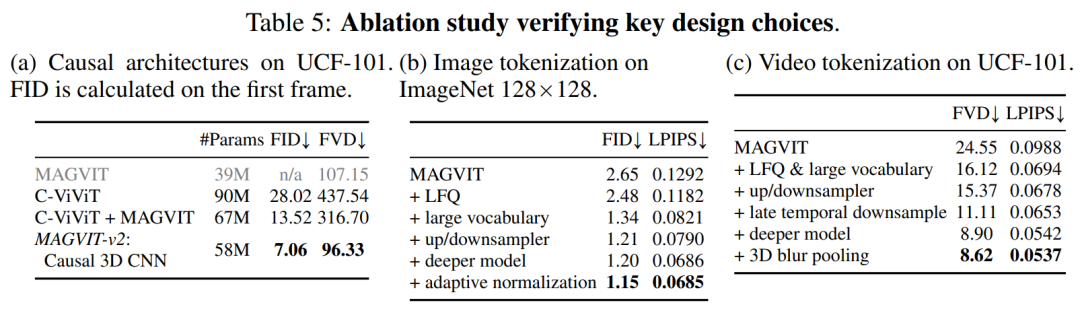
Cet article apporte d'autres modifications architecturales pour améliorer les performances de MAGVIT. En plus d'utiliser des couches CNN 3D causales, cet article modifie également le sous-échantillonneur de l'encodeur d'un regroupement moyen à une convolution striée et ajoute une normalisation de groupe adaptative avant le bloc résiduel à chaque résolution dans les couches du décodeur, etc.
Résultats expérimentaux
.Cet article vérifie les performances du segmenteur de mots proposé à travers trois parties d'expériences : la génération de vidéos et d'images, la compression vidéo et la reconnaissance d'actions. La figure 3 compare visuellement le tokenizer aux résultats de recherches précédentes

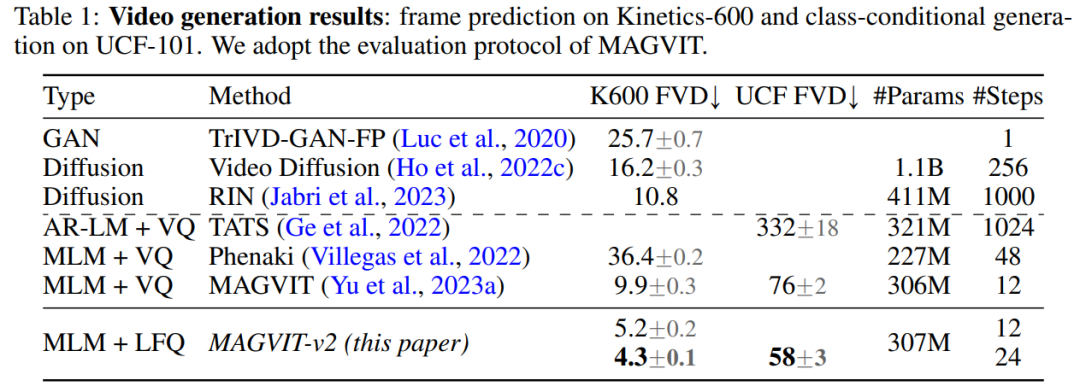
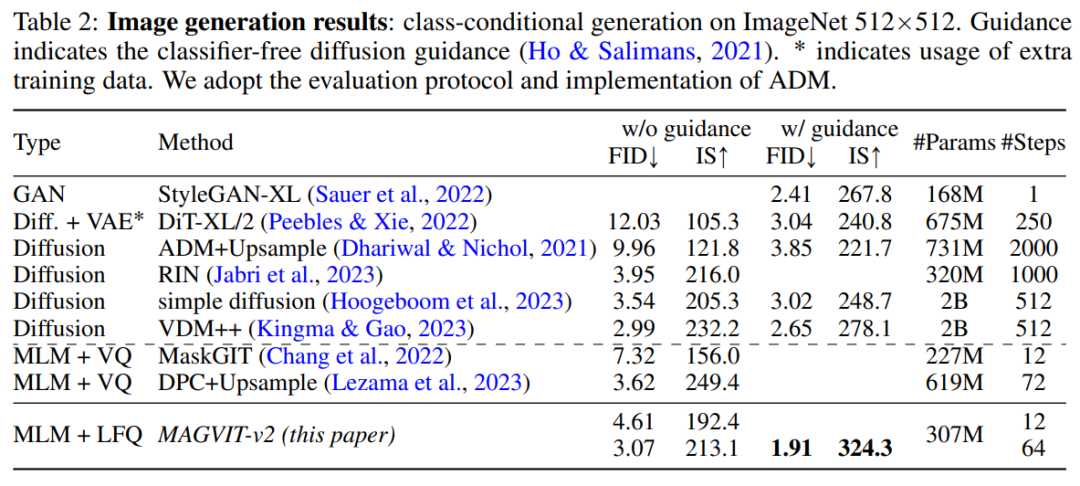
génération vidéo. Le tableau 1 montre que notre modèle surpasse toutes les techniques existantes sur les deux benchmarks, prouvant qu'un bon tokenizer visuel joue un rôle important en permettant à LM de générer des vidéos de haute qualité. En évaluant les résultats de génération d'images de MAGVIT-v2, cette étude a révélé que notre modèle dépasse les performances du meilleur modèle de diffusion en termes de qualité d'échantillonnage (ID et IS) et d'efficacité du temps d'inférence (étape d'échantillonnage). résultats.
Compression vidéo. Les résultats sont présentés dans le tableau 3. Notre modèle surpasse MAGVIT sur tous les indicateurs et surpasse toutes les méthodes sur LPIPS.

Comme le montre le tableau 4, MAGVIT-v2 surpasse le meilleur MAGVIT précédent dans ces évaluations
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment construire un modèle mathématique en utilisant Python
- À quoi fait référence le modèle Python IPO ?
- Dans la conception de bases de données, quel est le processus de conversion du diagramme ER en modèle de données relationnelles ?
- Quels sont les protocoles appartenant à la couche application dans le modèle de référence TCP IP ?
- Zoom garantit la transparence dans l'utilisation des données et garantit que la formation en IA est soumise à l'autorisation de l'utilisateur