
Maison >Périphériques technologiques >IA >Nouveau titre : ADAPT : Une exploration préliminaire de l'explicabilité de la conduite autonome de bout en bout
Nouveau titre : ADAPT : Une exploration préliminaire de l'explicabilité de la conduite autonome de bout en bout

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-10-11 12:57:041209parcourir
Cet article est réimprimé avec l'autorisation du compte public Autonomous Driving Heart. Veuillez contacter la source pour la réimpression.
Réflexions personnelles de l'auteur
Le bout en bout est une direction très populaire cette année. Le meilleur article CVPR de cette année a également été attribué à UniAD, mais il y a aussi de nombreux problèmes de bout en bout, comme. en raison de la faible interprétabilité et de la difficulté de convergence de la formation, etc., certains chercheurs dans le domaine ont commencé à se tourner progressivement vers l'interprétabilité de bout en bout. Aujourd'hui, je vais partager avec vous les derniers travaux sur l'interprétabilité de bout en bout, ADAPT. Cette méthode est basée sur l'architecture Transformer et utilise le multitâche. La méthode de formation conjointe produit des descriptions d'actions du véhicule et un raisonnement pour chaque décision de bout en bout. Certaines des réflexions de l'auteur sur ADAPT sont les suivantes :
- Voici la prédiction utilisant la fonctionnalité 2D de la vidéo. Il est possible que l'effet soit meilleur après la conversion de la fonctionnalité 2D en fonctionnalité bev. peut être meilleur lorsqu'il est combiné avec LLM, par exemple, la partie génération de texte est remplacée par LLM.
- Le travail actuel utilise des vidéos historiques comme entrée, et les actions prédites et leurs descriptions sont également historiques. Cela peut être plus significatif si c'est le cas. modifié pour prédire les actions futures et les raisons des actions. .
- Le
- token obtenu en tokenisant l'image est un peu trop, et il peut y avoir beaucoup d'informations inutiles. Vous pouvez peut-être essayer Token-Learner..
La conduite autonome de bout en bout a un énorme potentiel dans l'industrie des transports, et la recherche dans ce domaine est actuellement en vogue. Par exemple, UniAD, le meilleur article du CVPR2023, propose une conduite automatique de bout en bout. Cependant, le manque de transparence et d’explicabilité du processus décisionnel automatisé entravera son développement. Après tout, la sécurité est la première priorité des vrais véhicules sur la route. Il y a eu quelques premières tentatives pour utiliser des cartes d'attention ou des volumes de coûts pour améliorer l'interprétabilité des modèles, mais ces méthodes sont difficiles à comprendre. Le point de départ de ce travail est donc de trouver une manière facile à comprendre d’expliquer la prise de décision. L'image ci-dessous est une comparaison de plusieurs méthodes. Évidemment, elle est plus facile à comprendre avec des mots.
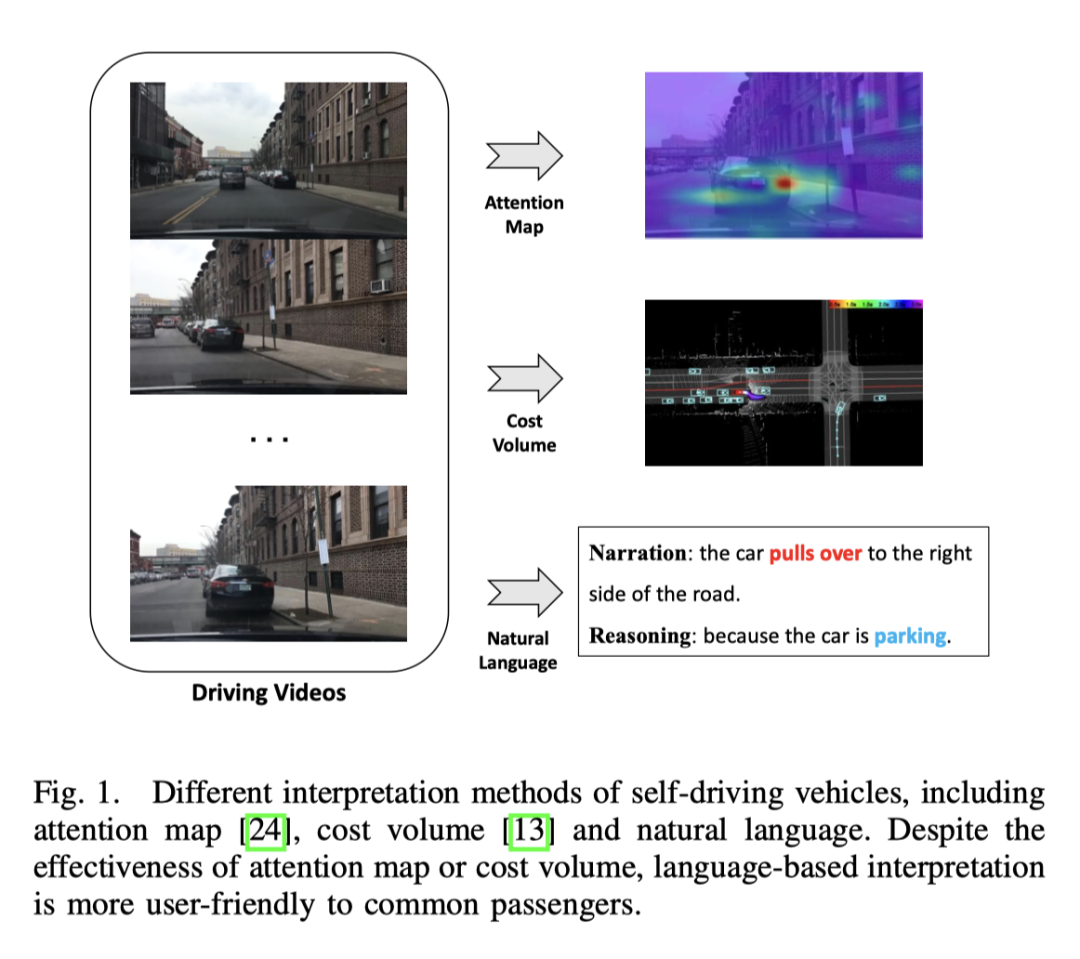
Capable de produire des descriptions d'actions du véhicule et un raisonnement pour chaque décision de bout en bout
- Cette méthode est basée sur la structure du réseau de transformateurs et effectue une formation conjointe via des méthodes multitâches ; DeepDrive eXplanation) a obtenu l'effet SOTA sur l'ensemble de données ;
- Afin de vérifier l'efficacité du système dans des scénarios réels, un système déployable a été établi. Ce système peut saisir la vidéo originale et produire la description et le raisonnement de l'action en réalité. ;
- Affichage de l'effet
L'effet est toujours très bon, surtout la troisième scène de nuit sombre, les feux de circulation sont remarqués.

Sous-titrage vidéo
L'objectif principal de la description vidéo est de décrire les objets et leurs relations d'une vidéo donnée en langage naturel. Les premiers travaux de recherche généraient des phrases avec des structures syntaxiques spécifiques en remplissant les éléments identifiés dans des modèles fixes, rigides et manquant de richesse. Afin de générer des phrases naturelles avec des structures syntaxiques flexibles, certaines méthodes adoptent des techniques d'apprentissage séquentiel. Plus précisément, ces méthodes utilisent des encodeurs vidéo pour extraire des fonctionnalités et des décodeurs de langue pour apprendre l'alignement visuel du texte. Pour enrichir les descriptions, ces méthodes utilisent également des représentations au niveau objet pour obtenir des fonctionnalités d'interaction détaillées sensibles aux objets dans les vidéos.
Bien que les architectures existantes aient obtenu certains résultats dans le sens général du sous-titrage vidéo, elles ne peuvent pas être directement appliquées à la représentation des actions, car simplement le transfert de descriptions vidéo vers des représentations d'actions de conduite autonome perdra certaines informations clés, telles que la vitesse du véhicule, etc., qui sont cruciales pour les tâches de conduite autonome. La manière d'utiliser efficacement ces informations multimodales pour générer des phrases est toujours à l'étude. PaLM-E fait du bon travail dans les phrases multimodales.
Conduite autonome de bout en boutLa conduite autonome basée sur l'apprentissage est un domaine de recherche actif. Le récent meilleur article UniAD du CVPR2023, y compris le FusionAD ultérieur, et le travail basé sur le modèle Wayve's World, MILE, travaillent tous dans cette direction. Le format de sortie inclut des points de trajectoire, comme UniAD, et l'action directe du véhicule, comme MILE. De plus, certaines méthodes modélisent le comportement futur des usagers de la route tels que les véhicules, les cyclistes ou les piétons pour prédire les points de cheminement du véhicule, tandis que d'autres méthodes prédisent les signaux de commande du véhicule directement sur la base des entrées des capteurs, similaires à la sous-tâche de prédiction des signaux de commande dans cette travailler
Interprétabilité de la conduite autonome
Dans le domaine de la conduite autonome, la plupart des méthodes d'interprétabilité sont basées sur la vision, et certaines sont basées sur les travaux LiDAR. Certaines méthodes utilisent des cartes d'attention pour filtrer les régions d'image insignifiantes, ce qui donne au comportement des véhicules autonomes une apparence raisonnable et explicable. Cependant, la carte d’attention peut contenir des régions moins importantes. Il existe également des méthodes qui utilisent le lidar et des cartes de haute précision comme entrées, prédisent les cadres de délimitation des autres participants au trafic et utilisent l'ontologie pour expliquer le processus de raisonnement décisionnel. De plus, il existe un moyen de créer des cartes en ligne grâce à la segmentation afin de réduire le recours aux cartes HD. Bien que les méthodes basées sur la vision ou le lidar puissent fournir de bons résultats, le manque d’explication verbale donne l’impression que l’ensemble du système est complexe et difficile à comprendre. Une étude explore pour la première fois la possibilité d'interprétation de texte pour les véhicules autonomes, en extrayant des fonctionnalités vidéo hors ligne pour prédire les signaux de commande et effectuer la tâche de description vidéo
Apprentissage multitâche dans la conduite autonome
Cette étude de bout en bout cadre final L'apprentissage multitâche est adopté pour entraîner conjointement le modèle avec les deux tâches de génération de texte et de prédiction des signaux de contrôle. L’apprentissage multitâche est largement utilisé dans la conduite autonome. En raison d'une meilleure utilisation des données et des fonctionnalités partagées, la formation conjointe de différentes tâches améliore les performances de chaque tâche. Par conséquent, dans ce travail, une formation conjointe des deux tâches de prédiction du signal de contrôle et de génération de texte est utilisée.
Méthode ADAPT
Voici le diagramme de structure du réseau :
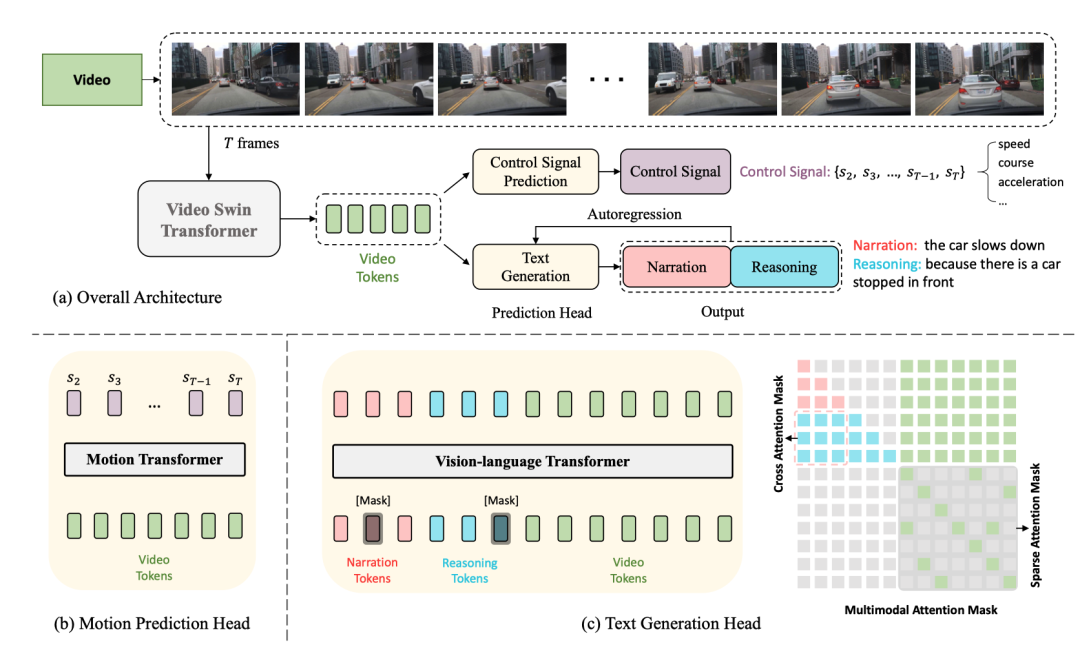
La structure entière est divisée en deux tâches :
- Génération de sous-titres de conduite (DCG) : entrée de vidéos, sortie de deux phrases, la première phrase description L'action de la voiture, la deuxième phrase décrit le raisonnement pour entreprendre cette action, comme "La voiture accélère, parce que les feux de circulation passent au vert."
- Prédiction du signal de contrôle (CSP) : saisissez les mêmes vidéos et produisez un série de signaux de contrôle, par exemple la vitesse, la direction, l'accélération.
Parmi eux, les deux tâches DCG et CSP partagent l'encodeur vidéo, mais utilisent des têtes de prédiction différentes pour produire des sorties finales différentes.
Pour la tâche DCG, l'encodeur du transformateur vision-langage est utilisé pour générer deux phrases en langage naturel.
Pour les tâches CSP, utilisez l'encodeur de transformation de mouvement pour prédire la séquence des signaux de contrôle
Encodeur vidéo
Le transformateur Swin vidéo est utilisé ici pour convertir les images vidéo d'entrée en jetons de fonctionnalités vidéo.
Entrée 桢image, la forme est , la taille de la fonctionnalité est , où est la dimension du canal
Prediction Heads
Text Generation Head
. ci-dessus Cette fonctionnalité , Après la tokenisation, des jetons vidéo avec des dimensions sont obtenus, puis un MLP est utilisé pour ajuster les dimensions afin de les aligner sur l'intégration des jetons de texte, puis les jetons de texte et les jetons vidéo sont transmis à la vision- encodeur de transformateur de langage ensemble pour générer des descriptions d'actions et un raisonnement.
Tête de prédiction du signal de contrôle
et l'entrée 桢vidéo correspondent au signal de contrôle La sortie de la tête CSP est Chaque signal de contrôle ici n'est pas nécessairement unidimensionnel, mais peut être multi. -dimensionnel, comme la vitesse, l'accélération, la direction, etc. L'approche ici consiste à tokeniser les fonctionnalités vidéo et à générer une série de signaux de sortie via le transformateur de mouvement. La fonction de perte est MSE,
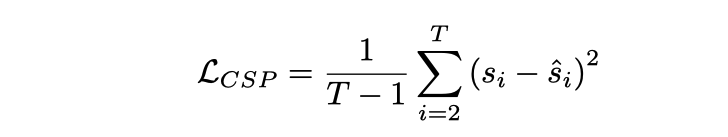
Il convient de noter que la première image n'est pas incluse ici car la première image y fournit. il y a trop peu d'informations dynamiques
Formation conjointe
Dans ce cadre, en raison de l'encodeur vidéo partagé, il est en fait supposé que les deux tâches de CSP et DCG sont alignées au niveau de la représentation vidéo. Le point de départ est que les descriptions d’actions et les signaux de commande sont des expressions différentes des actions fines du véhicule, et les explications du raisonnement des actions se concentrent principalement sur l’environnement de conduite qui affecte les actions du véhicule.
Formation utilisant une formation conjointe
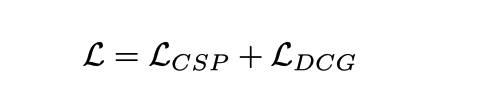
Il convient de noter que bien qu'il s'agisse d'un lieu de formation conjointe, elle peut être exécutée indépendamment lors de l'inférence. La tâche CSP est facile à comprendre selon l'organigramme et. contrôle de sortie Le signal est suffisant. Pour la tâche DCG, la vidéo est directement entrée et la description et le raisonnement sont générés mot par mot sur la base de la méthode autorégressive, en commençant par [CLS] et en terminant par [SEP] ou. atteignant le seuil de longueur.
Conception expérimentale et comparaison
Ensemble de données
L'ensemble de données utilisé est BDD-X Cet ensemble de données contient 7000 vidéos appariées et signaux de contrôle. Chaque vidéo dure environ 40 secondes, la taille de l'image est de et la fréquence est de FPS. Chaque vidéo comporte 1 à 5 comportements de véhicule, tels que l'accélération, le virage à droite et la fusion. Toutes ces actions sont annotées de texte, y compris des récits d'action (par exemple, « La voiture s'est arrêtée ») et un raisonnement (par exemple, « Parce que le feu de circulation est rouge »). Il existe au total environ 29 000 paires d’annotations comportementales.
Détails spécifiques de mise en œuvre
- Le transformateur vidéo swin est pré-entraîné sur Kinetics-600
- Le transformateur de langage de vision et le transformateur de mouvement sont initialisés de manière aléatoire
- Il n'y a pas de paramètres de swin vidéo fixes, donc toute la formation est terminée. jusqu'à la fin La
- taille de l'image vidéo d'entrée est redimensionnée et recadrée, et l'entrée finale sur le réseau est de 224 x 224
- Pour la description et le raisonnement, les intégrations WordPièce [75] sont utilisées à la place de mots entiers (par exemple, « s'arrête » est coupé en « stop » et « #s »), la longueur maximale de chaque phrase est de 15.
- Pendant la formation, la modélisation du langage masqué masquera aléatoirement 50 % des jetons, et le jeton de chaque masque a une probabilité de 80 % de devenant le jeton [MASK], il y a une probabilité de 10 % qu'un mot soit sélectionné au hasard, et les 10 % de probabilité restants restent inchangés.
- L'optimiseur AdamW est utilisé, et dans les premiers 10 % des étapes d'entraînement, il y a un mécanisme d'échauffement
- Il faut environ 13 heures pour s'entraîner avec 4 GPU V100
L'impact de l'entraînement conjoint
Trois expériences sont comparées ici pour illustrer l'efficacité de l'entraînement conjoint.
Single
fait référence à la suppression de la tâche CSP et à la conservation de la tâche DCG, ce qui équivaut à entraîner uniquement le modèle de sous-titrage
Single+
Bien que CSP Le. La tâche n'existe toujours pas, mais lors de la saisie du module DCG, en plus des balises vidéo, des balises de signal de contrôle doivent également être saisies
La comparaison des effets est la suivante
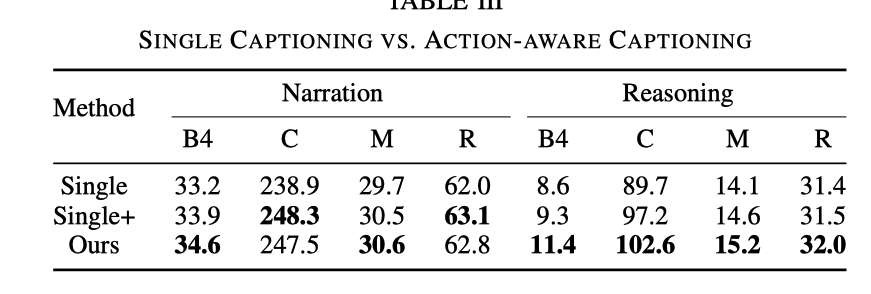
Par rapport à la tâche DCG uniquement, le raisonnement d'ADAPT l'effet est nettement meilleur. Bien que l'effet soit amélioré lorsqu'il y a une entrée de signal de contrôle, il n'est toujours pas aussi bon que l'effet de l'ajout de tâches CSP. Après avoir ajouté la tâche CSP, la capacité d'exprimer et de comprendre la vidéo est plus forte
De plus, le tableau ci-dessous montre également que l'effet de l'entraînement conjoint sur le CSP est également amélioré.

Ici peut être compris comme précision, plus précisément ce sera Le signal de contrôle prédit est tronqué et la formule est la suivante
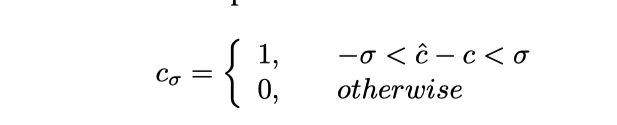
L'influence des différents types de signaux de contrôle
Dans l'expérience, les signaux de base utilisés sont la vitesse et le cap. Cependant, des expériences ont montré que lorsqu'un seul des signaux est utilisé, l'effet n'est pas aussi bon que l'utilisation des deux signaux en même temps. Les données spécifiques sont présentées dans le tableau suivant :
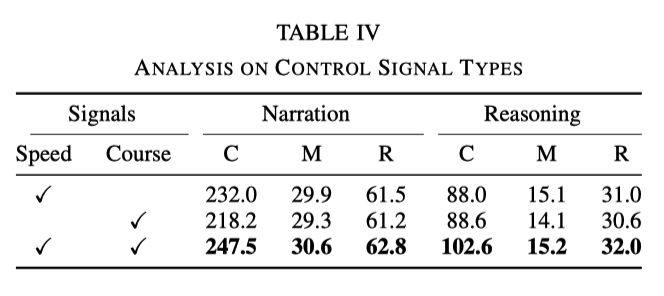
Cela montre que les deux signaux. de vitesse et de direction peuvent aider le réseau à mieux apprendre la description d'action et le raisonnement
Interaction entre la description d'action et le raisonnement
Par rapport aux tâches de description générale, la génération de tâches de description de conduite comprend deux phrases, à savoir la description d'action et le raisonnement. On le trouve dans le tableau suivant :
- Les lignes 1 et 3 indiquent que l'effet de l'utilisation de l'attention croisée est meilleur, ce qui est facile à comprendre. L'inférence basée sur la description est bénéfique pour modéliser la formation
- Les lignes 2 et 3 illustrent ; échange d'inférence L'ordre de la description et de la description sera également dans le désordre, ce qui montre que le raisonnement dépend de la description
- En comparant les trois lignes suivantes, afficher uniquement la description et afficher uniquement le raisonnement n'est pas aussi bon que les deux ;
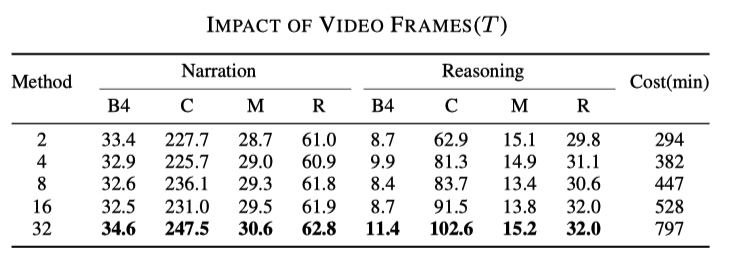
L'impact des taux d'échantillonnage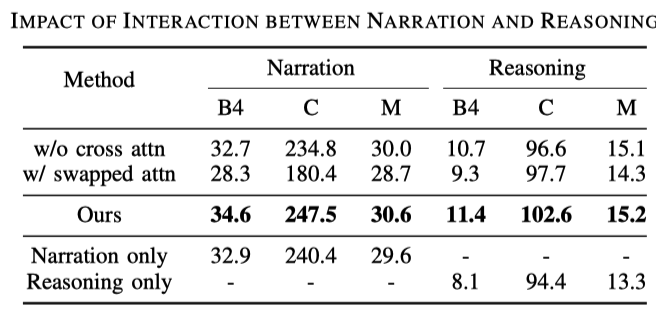
Ce résultat peut être deviné. Plus il y a d'images utilisées, meilleur est le résultat, mais la vitesse correspondante deviendra également plus lente, comme le montre le tableau suivant
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Analyse de la technologie de positionnement global basée sur des points caractéristiques de la conduite autonome
- La conduite autonome est difficile à attaquer par la réduction de dimensionnalité
- Discutez de l'état actuel et des tendances de développement de la technologie de prédiction de trajectoire de conduite autonome
- Comment développer la conduite autonome et l'Internet des véhicules en PHP ?
- Explication détaillée de l'évitement d'obstacles, de la planification de trajectoire et de la technologie de contrôle pour les véhicules autonomes