
Maison >Périphériques technologiques >IA >Méthode d'estimation du cadre intérieur à l'aide d'un modèle d'auto-attention visuelle panoramique
Méthode d'estimation du cadre intérieur à l'aide d'un modèle d'auto-attention visuelle panoramique

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-10-07 09:37:01901parcourir

1. Contexte de recherche
Cette méthode se concentre principalement sur la tâche d'estimation du cadre intérieur (estimation de la disposition de l'estimation intérieure). La tâche saisit une image 2D et génère un modèle tridimensionnel de la scène décrite par l'image. . Compte tenu de la complexité de la sortie directe d'un modèle 3D, cette tâche se décompose généralement en la sortie des informations de trois lignes : les lignes des murs, les lignes du plafond et les lignes du sol dans l'image 2D, puis en la reconstruction du modèle 3D de la pièce par post-production. opérations de traitement basées sur les informations de la ligne. Le modèle tridimensionnel peut ensuite être utilisé dans des scénarios d'application spécifiques tels que la reproduction de scènes intérieures et la visualisation de maisons en réalité virtuelle. Différente de la méthode d'estimation de la profondeur, cette méthode restaure la structure géométrique spatiale sur la base de l'estimation des lignes des murs intérieurs. L'avantage est qu'elle peut rendre la structure géométrique du mur plus plate. L'inconvénient est qu'elle ne peut pas restaurer les informations géométriques détaillées. des objets tels que des canapés et des chaises dans des scènes d'intérieur.
En fonction de l'image d'entrée, elle peut être divisée en méthodes basées sur la perspective et basées sur le panorama. Par rapport aux vues en perspective, les panoramas ont un angle de vision plus grand et des informations d'image plus riches. Avec la popularisation des équipements d'acquisition panoramique, les données panoramiques deviennent de plus en plus abondantes, il existe donc actuellement de nombreux algorithmes pour l'estimation du cadre intérieur basés sur des images panoramiques qui ont été largement étudiés
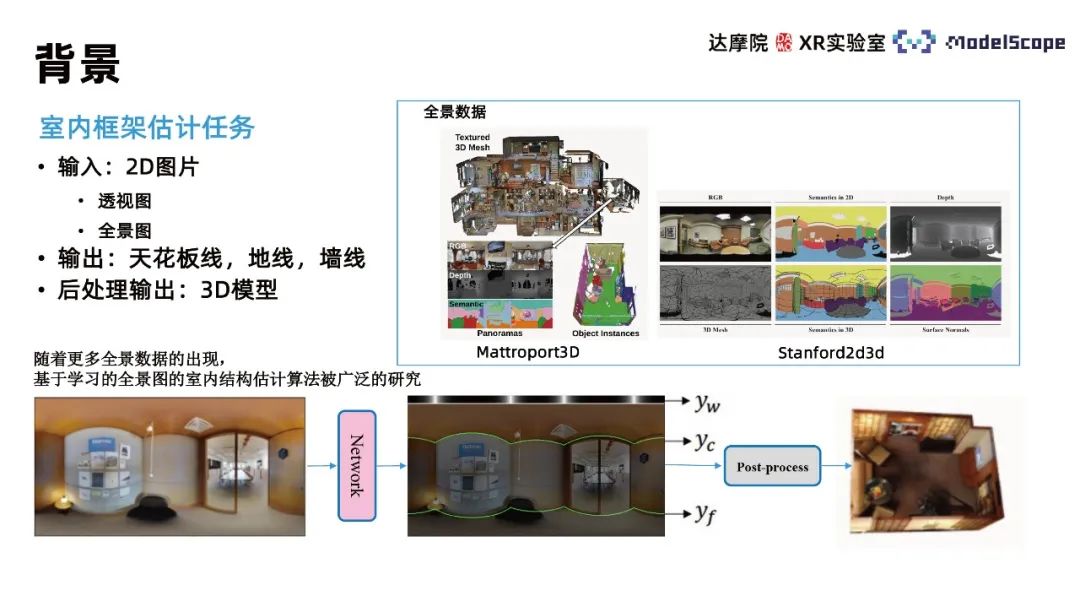
Les algorithmes associés incluent principalement LayoutNet, HorizonNet , HohoNet et Led2 -Net, etc. La plupart de ces méthodes sont basées sur des réseaux neuronaux convolutifs et l'effet de prédiction des lignes de mur est médiocre dans les endroits dotés de structures complexes. Par exemple, en cas d'interférence sonore, d'auto-occlusion, etc. des résultats de prédiction tels que la discontinuité de la ligne de mur et les erreurs de position de la ligne de mur se produiront. Dans la tâche d'estimation de la position de la ligne de mur, se concentrer uniquement sur les informations sur les caractéristiques locales entraînera l'apparition de ce type d'erreur. Il est nécessaire d'utiliser les informations globales dans le panorama pour considérer la distribution de position de l'ensemble de la ligne de mur à des fins d'estimation. La méthode CNN est plus performante dans la tâche d'extraction de caractéristiques locales et la méthode Transformer est meilleure pour capturer des informations globales. Par conséquent, la méthode Transformer peut être appliquée aux tâches d'estimation de cadre intérieur pour améliorer les performances des tâches.
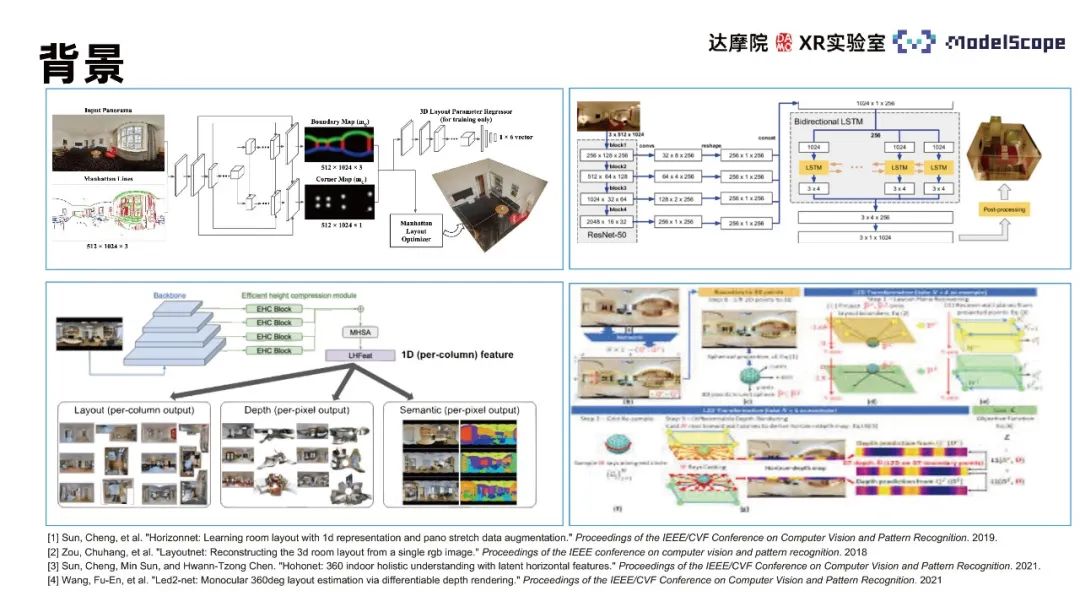
En raison de la dépendance des données d'entraînement, l'effet de l'estimation du cadre intérieur du panorama en appliquant le transformateur basé uniquement sur la pré-entraînement en perspective n'est pas idéal. Le modèle PanoViT mappe à l'avance le panorama à l'espace des fonctionnalités, utilise le transformateur pour apprendre les informations globales du panorama dans l'espace des fonctionnalités et considère les informations de structure apparente du panorama pour terminer la tâche d'estimation du cadre intérieur.

2. Introduction de la méthode et affichage des résultats
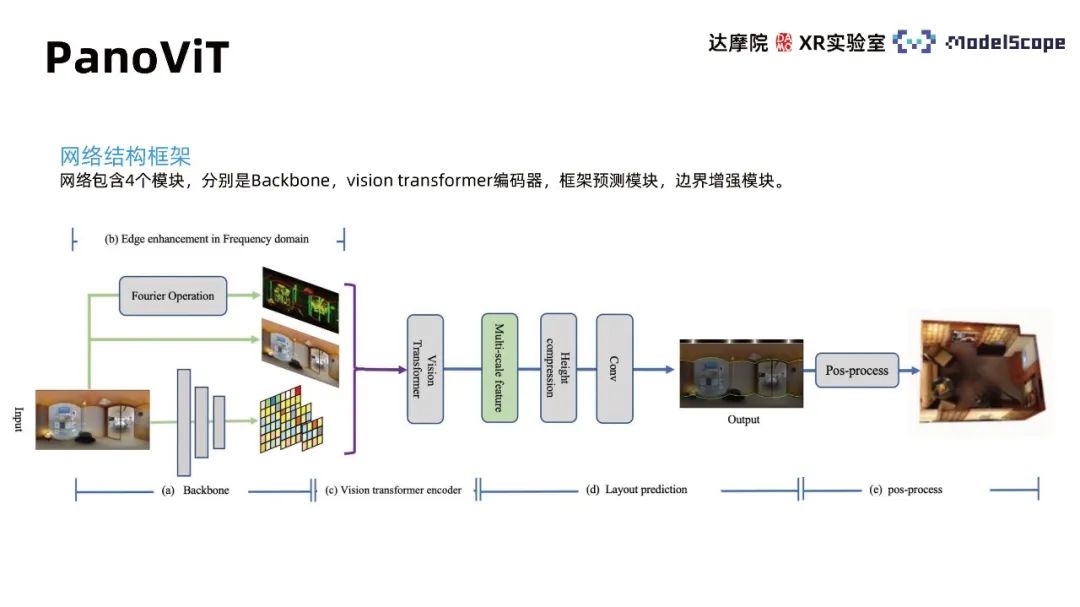
1. PanoViT
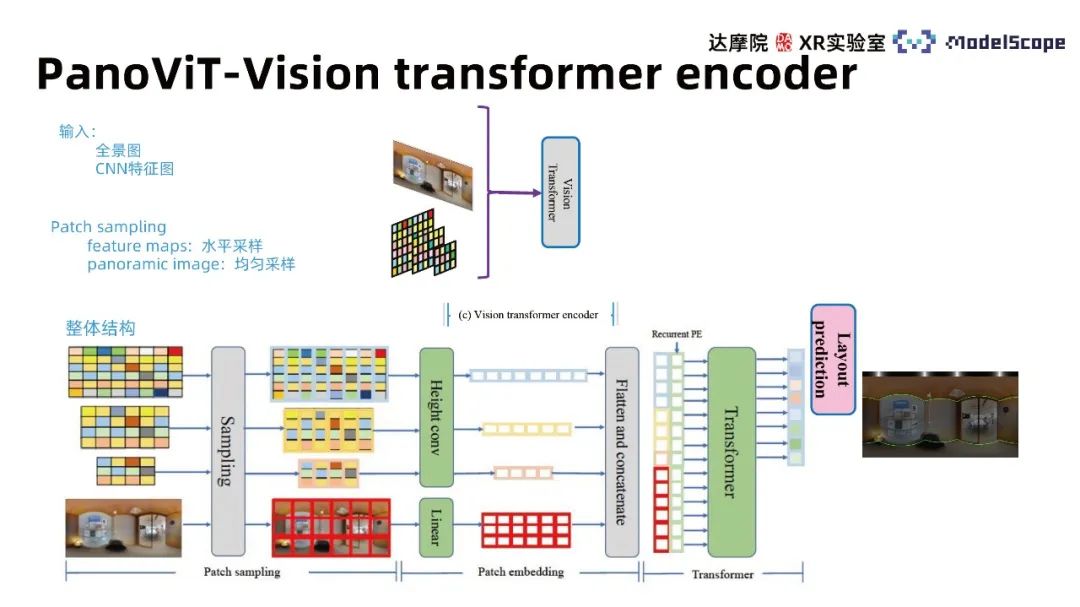
Le cadre de structure du réseau contient 4 modules, à savoir Backbone, décodeur de transformateur de vision, module de prédiction de trame et module d'amélioration des limites. Le module Backbone mappe le panorama sur l'espace des caractéristiques, l'encodeur du transformateur de vision apprend la corrélation globale dans l'espace des caractéristiques et le module de prédiction de trame convertit les caractéristiques en informations sur les lignes de mur, de plafond et de sol. Le post-traitement peut ensuite obtenir. le modèle tridimensionnel de la pièce et de ses limites. Le module d'amélioration met en évidence le rôle des informations sur les limites dans les images panoramiques pour l'estimation du cadre intérieur.
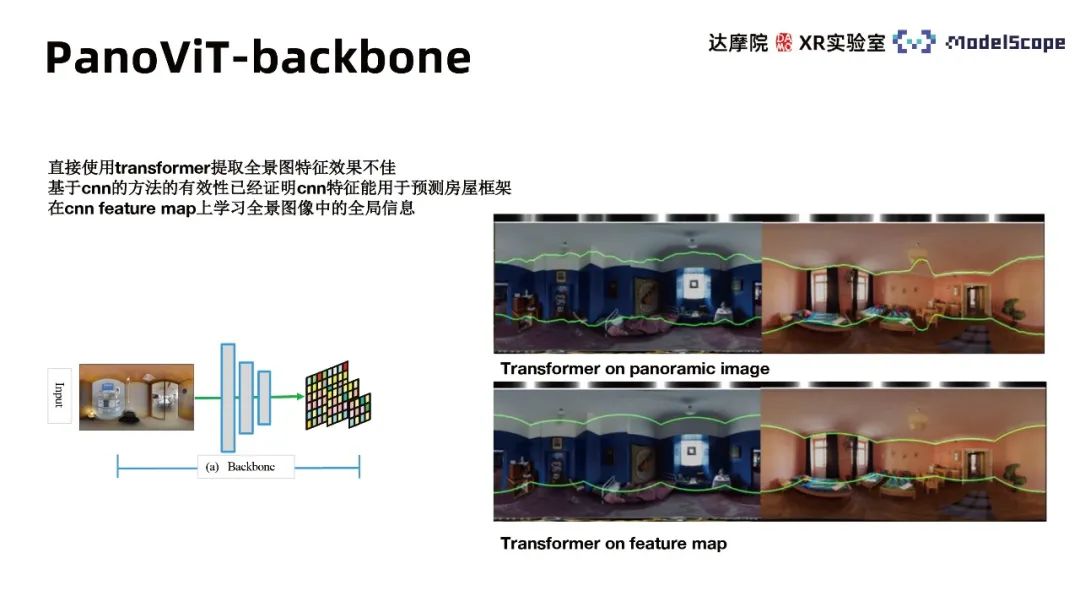
① Module Backbone
Étant donné que l'utilisation directe du transformateur pour extraire les caractéristiques panoramiques ne fonctionne pas bien, l'efficacité des méthodes basées sur CNN a été prouvée, c'est-à-dire que les caractéristiques CNN peuvent être utilisées pour prédire les cadres de maison . Par conséquent, nous utilisons l’épine dorsale de CNN pour extraire des cartes de caractéristiques à différentes échelles du panorama et apprendre les informations globales de l’image panoramique dans les cartes de caractéristiques. Les résultats expérimentaux montrent qu'il est nettement préférable d'utiliser le transformateur dans l'espace des fonctionnalités que de l'appliquer directement sur le panorama
② Module d'encodeur de transformateur de vision
L'architecture principale de Transformer peut être principalement divisée en trois modules, y compris l'échantillonnage de patchs, l'intégration de patchs et l'attention multi-têtes du transformateur. L'entrée prend en compte à la fois la carte des caractéristiques de l'image panoramique et l'image originale et utilise différentes méthodes d'échantillonnage de patch pour différentes entrées. L'image originale utilise la méthode d'échantillonnage uniforme et la carte caractéristique utilise la méthode d'échantillonnage horizontal. La conclusion d'HorizonNet estime que les caractéristiques horizontales sont d'une plus grande importance dans la tâche d'estimation des lignes de mur. En référence à cette conclusion, les caractéristiques de la carte des caractéristiques sont compressées dans la direction verticale pendant le processus d'intégration. La méthode PE récurrente est utilisée pour combiner des caractéristiques de différentes échelles et apprendre dans le modèle de transformateur d'attention multi-têtes pour obtenir un vecteur de caractéristiques de même longueur que la direction horizontale de l'image d'origine. La distribution des lignes de mur correspondante peut être obtenue via. différentes têtes de décodeur.
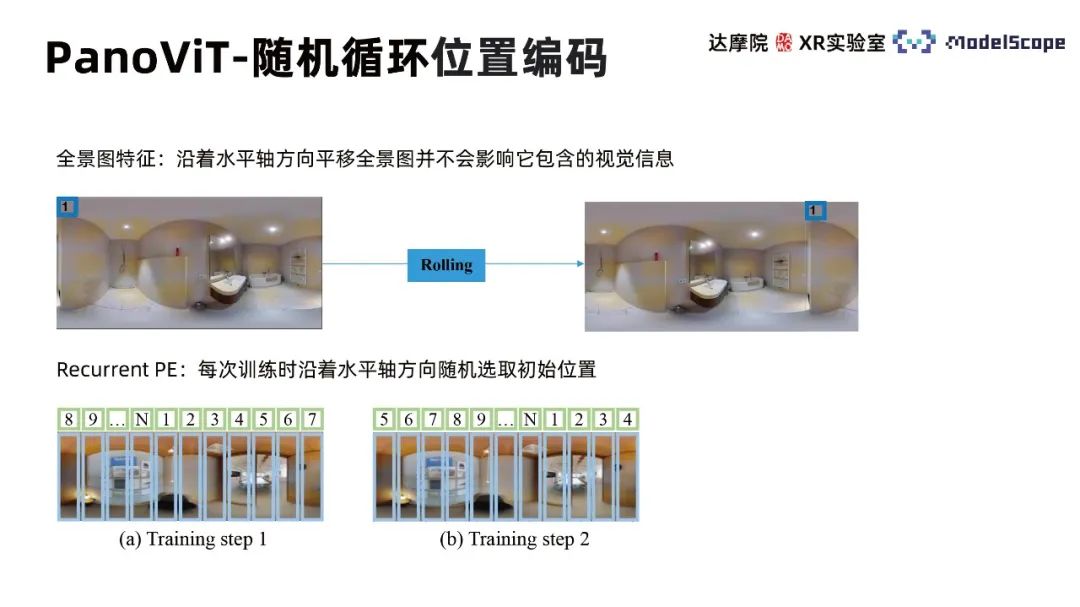
L'encodage de position cyclique aléatoire (Recurrent Position Embedding) prend en compte que le déplacement horizontal du panorama ne modifie pas les caractéristiques des informations visuelles de l'image, donc la position initiale est sélectionnée aléatoirement le long de l'axe horizontal lors de chaque entraînement, ce qui fait que le processus d'entraînement accorde plus d'attention à la position relative entre les différents patchs plutôt qu'à la position absolue.
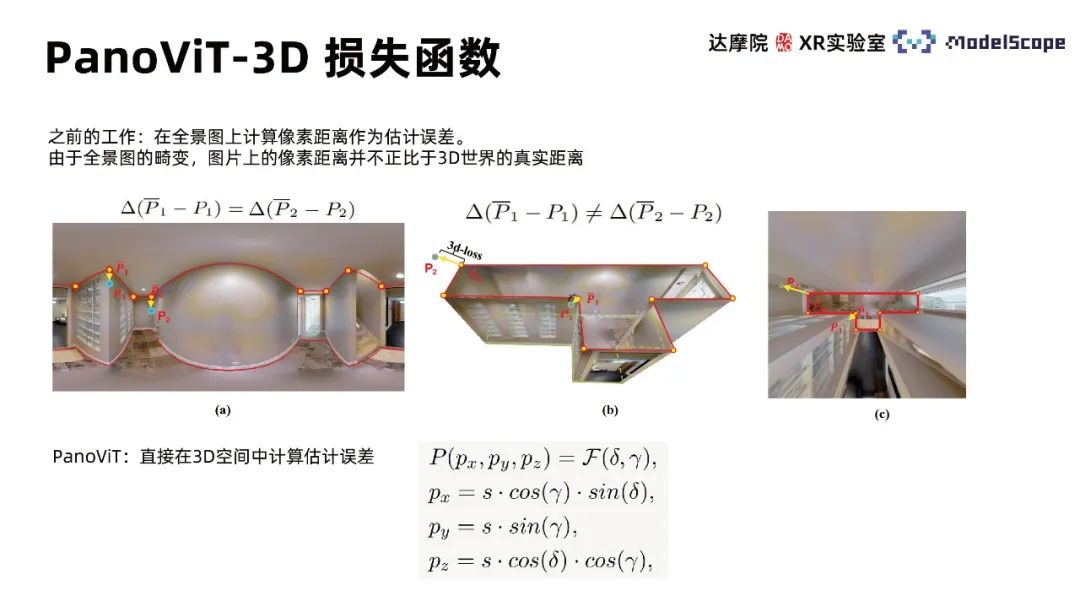
③ Informations géométriques du panorama
La pleine utilisation des informations géométriques dans le panorama peut aider à améliorer les performances des tâches d'estimation du cadre intérieur. Le module d'amélioration des limites du modèle PanoViT met l'accent sur la façon d'utiliser les informations sur les limites dans le panorama, et la perte 3D aide à réduire l'impact de la distorsion du panorama.
Le module d'amélioration des limites prend en compte les caractéristiques linéaires des lignes de mur dans la tâche de détection des lignes de mur. Les informations sur les lignes dans l'image sont d'une importance primordiale, il est donc nécessaire de mettre en évidence les informations de limite afin que le réseau puisse. comprendre la répartition des lignes dans l'image. Utilisez la méthode d'amélioration des limites dans le domaine fréquentiel pour mettre en évidence les informations sur les limites du panorama, obtenez la représentation du domaine fréquentiel de l'image basée sur une transformée de Fourier rapide, utilisez un masque pour échantillonner dans l'espace du domaine fréquentiel et retransformez-vous en l'image avec la limite mise en évidence. informations basées sur la transformée de Fourier inverse. Le cœur du module réside dans la conception du masque, étant donné que la limite correspond aux informations haute fréquence, le masque sélectionne d'abord un filtre passe-haut et échantillonne différentes directions du domaine fréquentiel en fonction des différentes directions des différentes lignes. Cette méthode est plus simple à mettre en œuvre et plus efficace que la méthode LSD traditionnelle. 
Des travaux antérieurs ont calculé la distance en pixels sur le panorama comme une erreur d'estimation En raison de la distorsion du panorama, la distance en pixels sur l'image n'est pas proportionnelle à la distance réelle dans le monde 3D. PanoViT utilise une fonction de perte 3D pour calculer l'erreur d'estimation directement dans l'espace 3D.
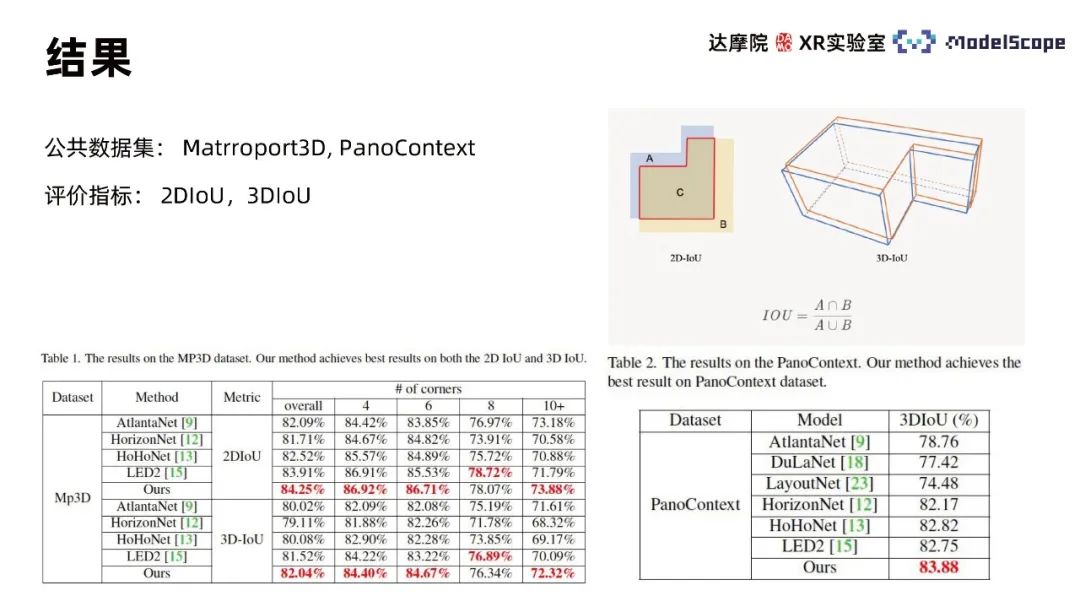
2. Modéliser les résultats
Utiliser les ensembles de données publiques Martroport3D et PanoContext pour mener des expériences, en utilisant 2DIoU et 3DIoU comme indicateurs d'évaluation et en comparant avec la méthode SOTA. Les résultats montrent que les indicateurs d'évaluation du modèle de PanoViT sur les deux ensembles de données ont fondamentalement atteint le niveau optimal et ne sont que légèrement inférieurs à LED2 sur des indicateurs spécifiques. En comparant les résultats de visualisation du modèle avec Hohonet, nous pouvons constater que PanoViT peut identifier avec précision la direction des lignes de murs dans des scènes complexes. En comparant les modules PE récurrent, amélioration des limites et perte 3D dans des expériences d'ablation, l'efficacité de ces modules peut être vérifiée. des panoramas ont été collectés. L'ensemble de données d'images panoramiques auto-construit contient diverses scènes d'intérieur complexes et est annoté sur la base de règles personnalisées. 5 053 images ont été sélectionnées comme ensemble de données de test. Les performances du modèle PanoViT et de la méthode du modèle SOTA ont été testées sur l'ensemble de données auto-construit, et il a été constaté qu'à mesure que la quantité de données augmente, les performances du modèle PanoViT s'améliorent considérablement.
3. Comment utiliser
- dans ModelScope Ouvrez le site officiel de modelscope : https://modelscope.cn/home.
- Recherchez « estimation du cadre intérieur panoramique ».
- Cliquez sur Utilisation rapide-Utilisation de l'environnement en ligne-Expérience rapide pour ouvrir le bloc-notes.
- Entrez l'exemple de code de la page d'accueil, téléchargez une image panoramique 1024*512, modifiez le chemin de chargement de l'image et exécutez pour afficher les résultats de prédiction de la ligne de mur.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!