
Maison >Périphériques technologiques >IA >LeCun profondément déçu par la fraude des licornes autonomes
LeCun profondément déçu par la fraude des licornes autonomes

- PHPzavant
- 2023-10-06 14:33:021319parcourir
Pensez-vous qu'il s'agit d'une vidéo de conduite autonome ordinaire ?
 Images
Images
Ce contenu doit être réécrit en chinois sans changer le sens original
Aucune seule image n'est "réelle".
 Photos
Photos
Différentes conditions routières, diverses conditions météorologiques et plus de 20 situations peuvent être simulées, et l'effet est comme la réalité.
 Photos
Photos
Le modèle mondial a encore fait un excellent travail ! LeCun a retweeté cela avec enthousiasme après l'avoir vu.
 Photos
Photos
Selon les effets ci-dessus, ceci est apporté par la dernière version de GAIA-1
L'ampleur de ce projet a atteint 9 milliards de paramètres Grâce à 4700 heures de formation vidéo de conduite, il a réussi. la vidéo d'entrée, l'avantage le plus direct de la génération de vidéos de conduite autonome à partir de texte ou d'opérations est qu'elle peut mieux prédire les événements futurs et que plus de 20 scénarios peuvent être simulés, améliorant ainsi encore la sécurité de la conduite autonome et réduisant les coûts.
Photos Notre équipe créative a déclaré sans détour que cela changerait complètement les règles du jeu de la conduite autonome !
Notre équipe créative a déclaré sans détour que cela changerait complètement les règles du jeu de la conduite autonome !
Alors, comment GAIA-1 est-il implémenté ?
Plus l'échelle est grande, mieux c'est
GAIA-1 est un modèle mondial génératif avec plusieurs modes
En exploitant la vidéo, le texte et les actions comme entrées, le système peut générer des vidéos de scènes de conduite réalistes et contrôler de manière autonome un contrôle précis du véhicule. caractéristiques du comportement et de la scène
Les vidéos peuvent être générées en utilisant uniquement des invites textuelles
Images  Son principe de modèle est similaire aux grands modèles de langage, c'est-à-dire en prédisant le prochain jeton
Son principe de modèle est similaire aux grands modèles de langage, c'est-à-dire en prédisant le prochain jeton
Le modèle peut utiliser une représentation par quantification vectorielle Discrétisation les images vidéo, puis la prédiction des scènes futures est convertie en prédiction du prochain jeton de la séquence. Le modèle de diffusion est ensuite utilisé pour générer des vidéos de haute qualité à partir de l’espace linguistique du modèle mondial.
Les étapes spécifiques sont les suivantes :
Images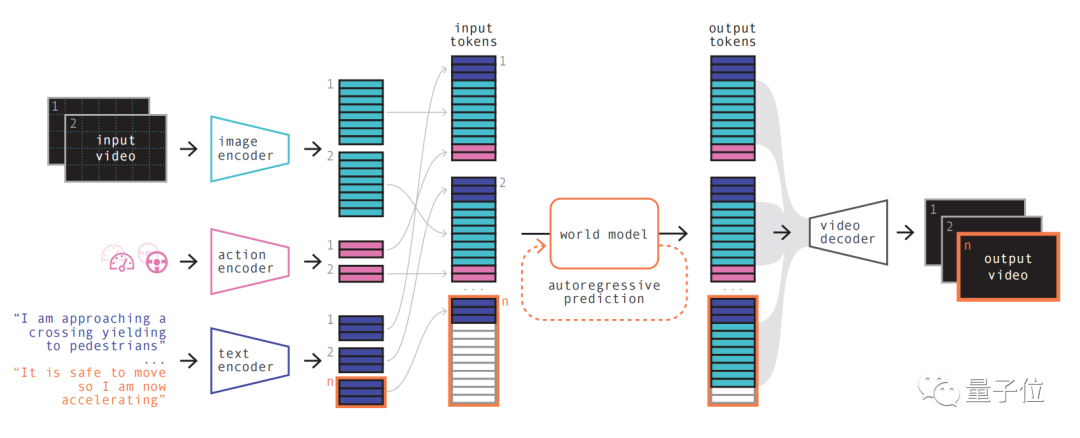 La première étape est simple à comprendre, qui consiste à recoder, organiser et combiner diverses entrées.
La première étape est simple à comprendre, qui consiste à recoder, organiser et combiner diverses entrées.
En utilisant des encodeurs spécialisés pour encoder diverses entrées et projeter différentes entrées dans une représentation partagée. Les encodeurs texte et vidéo séparent et intègrent les entrées, tandis que les représentations opérationnelles sont projetées individuellement dans une représentation partagée
Ces représentations codées sont temporellement cohérentes.
Après l'arrangement, l'élément clé du modèle mondial apparaît.
En tant que transformateur autorégressif, il peut prédire le prochain ensemble de jetons d'image dans la séquence. Et il prend non seulement en compte le jeton d'image précédent, mais prend également en compte les informations contextuelles du texte et de l'opération.
Le contenu généré par le modèle maintient non seulement la cohérence de l'image, mais est également cohérent avec le texte et les actions prédits.
L'équipe a introduit que la taille du modèle mondial dans GAIA-1 est de 6,5 milliards de paramètres et a été formée sur cela. 64 A100 pendant 15 jours.
Enfin, utilisez le modèle de décodeur vidéo et de diffusion vidéo pour reconvertir ces jetons en vidéos.
L'importance de cette étape est de garantir la qualité sémantique, la précision de l'image et la cohérence temporelle de la vidéo
Le décodeur vidéo de GAIA-1 a une échelle de 2,6 milliards de paramètres et a été entraîné pendant 15 jours à l'aide de 32 A100.
Il convient de mentionner que GAIA-1 est non seulement similaire au principe des modèles de langage à grande échelle, mais montre également les caractéristiques d'une qualité de génération améliorée à mesure que l'échelle du modèle s'étend
Photos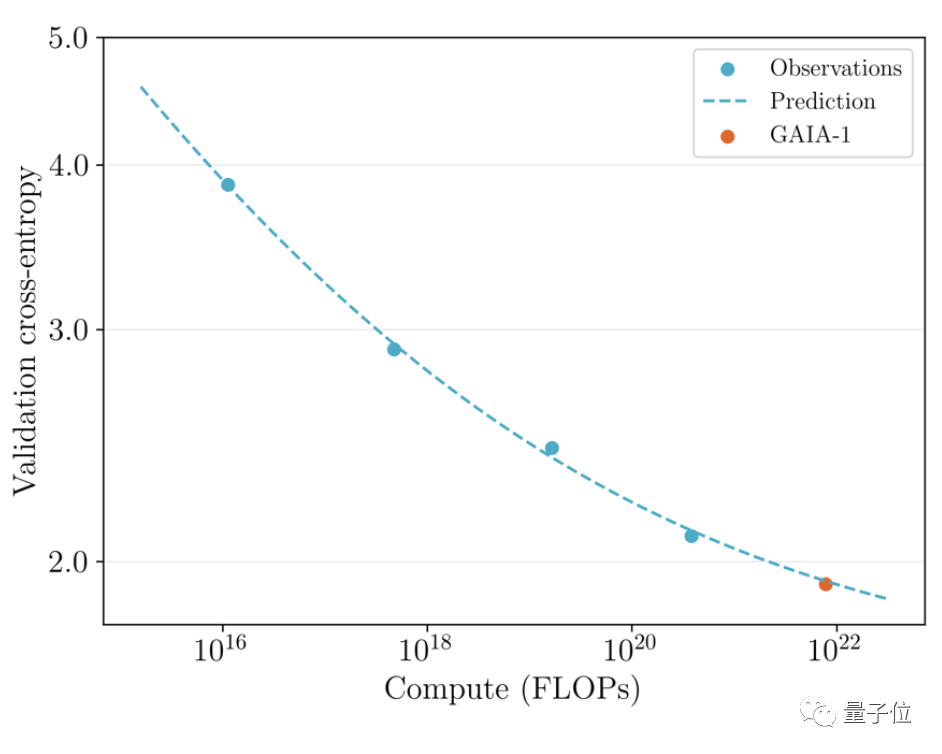 L'équipe a examiné le précédemment publié en juin La première version et le dernier effet ont été comparés
L'équipe a examiné le précédemment publié en juin La première version et le dernier effet ont été comparés
Ce dernier est 480 fois plus grand que le premier.
Vous pouvez intuitivement voir que les détails et la résolution de la vidéo ont été considérablement améliorés.
Photos Du point de vue de l'application pratique, l'émergence de GAIA-1 a également eu un certain impact. Son équipe créative a déclaré que cela changerait les règles de la conduite autonome
Du point de vue de l'application pratique, l'émergence de GAIA-1 a également eu un certain impact. Son équipe créative a déclaré que cela changerait les règles de la conduite autonome
 Photos
Photos
Les raisons peuvent être expliquées sous trois aspects :
- Sécurité
- Données de formation complètes
- Scénario longue traîne
Tout d'abord, en termes de sécurité, le modèle mondial peut simuler l'avenir, donner à l'IA la capacité de prendre vos propres décisions, ce qui est essentiel à la sécurité de la conduite autonome.
Deuxièmement, les données d'entraînement sont également très importantes pour la conduite autonome. Les données générées sont plus sécurisées, plus rentables et infiniment évolutives.
L'IA générative peut résoudre l'un des défis des scénarios à longue traîne auxquels est confrontée la conduite autonome. Il peut gérer davantage de scénarios extrêmes, comme rencontrer des piétons traversant la route par temps de brouillard. Cela améliorera encore les capacités de conduite autonome
Qui est Wayve ?
GAIA-1 a été développé par la startup britannique de conduite autonome Wayve
Wayve a été fondée en 2017. Parmi les investisseurs figurent Microsoft et d'autres, et sa valorisation a atteint la licorne.
Les fondateurs sont Alex Kendall et Amar Shah, tous deux titulaires d'un doctorat en machine learning de l'université de Cambridge
 Photos
Photos
Sur le plan technique, comme Tesla, Wayve prône l'utilisation de caméras. Solution purement visuelle, il ont abandonné très tôt les cartes de haute précision et ont suivi résolument la voie de la « perception en temps réel ».
Il n'y a pas si longtemps, un autre grand modèle LINGO-1 publié par l'équipe a également attiré l'attention
Ce modèle de conduite autonome peut générer des explications en temps réel pendant la conduite, améliorant ainsi encore l'interprétabilité du modèle
En mars de cette année, Bill Gates a également fait un essai routier avec la voiture autonome de Wayve.
 Photos
Photos
Adresse papier : https://www.php.cn/link/1f8c4b6a0115a4617e285b4494126fbf
Lien de référence :
[1]https://www.php.cn/link/8 5dca1d 270f7f9aef00c9d372f114482 [2]https://www.php.cn/link/a4c22565dfafb162a17a7c357ca9e0be
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- En débloquant la bonne combinaison de CNN et Transformer, ByteDance propose un transformateur visuel efficace de nouvelle génération
- L'activité de construction automobile de Foxconn a obtenu de premiers résultats et remporté d'importantes commandes de la chaîne d'approvisionnement de Tesla
- Un article pour comprendre la perception lidar et fusion visuelle de la conduite autonome
- Le robot humanoïde Tesla Optimus entre dans les magasins nord-américains pour aider à stimuler les ventes de voitures
- Nouvelle mise à niveau ! La caméra Kandao QooCam 3 sera officiellement lancée le 7 septembre, apportant une nouvelle expérience de vision panoramique !